Memorystore for Redis のパフォーマンスを調整する際のベスト プラクティス
Google Cloud Japan Team
※この投稿は米国時間 2020 年 5 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
Redis は最も一般的なオープンソースのインメモリ データストアで、データベース、キャッシュ、メッセージ ブローカーとして使用されます。統合されたオプションである Memorystore for Redis を使用して Google Cloud 上で Redis を実行するにあたっては、いくつかのデプロイ シナリオがあります。Memorystore for Redis を使用すると、管理コストをかけずに Redis のメリットを享受できます。
本番環境にリリースする前には、システムに対して特定のワークロードの特性に応じたベンチマークを実施することが重要です。これは、システムがマネージド サービスに依存している場合でも同様です。ここでは、Memorystore for Redis のパフォーマンスを測定する方法と、パフォーマンスを調整する際のベスト プラクティスについてご説明します。Memorystore for Redis のパフォーマンスに影響を与える要因を理解し、適切に調整を行う方法を知ることで、アプリケーションの安定性を保つことが可能です。
Cloud Memorystore のベンチマーク
まず、ベンチマークの測定方法を見てみましょう。
ベンチマーク ツールを選択する
Memorystore for Redis のベンチマークをテストする際に利用できるツールはいくつかあります。ツールの例を以下に示します。
●YCSB
このブログ投稿では、トラフィックとフィールドのパターンを柔軟に制御する機能があり、コミュニティ内での管理が行き届いている YCSB を使用します。
アプリケーションのトラフィック パターンを分析する
ベンチマーク ツールを構成する前に、実際のトラフィック パターンについて理解することが重要です。すでに Memorystore for Redis でテストするアプリケーションを実行していて、指標を利用できる場合は、最初にそれらの指標を分析することをおすすめします。Memorystore for Redis で新しいアプリケーションをデプロイする場合は、Cloud Monitoring を有効にすると、ステージング環境でアプリケーションの事前負荷テストを実施できます。
ベンチマーク ツールを構成するには、次の情報が必要です。
●各レコードのフィールド数
●レコード数
●各行のフィールドの長さ
●SET と GET の比率などの、クエリのパターン
●平常時とピーク時におけるスループット
実際のトラフィック パターンに基づいてベンチマーク ツールを構成する
特定のケースのパフォーマンス ベンチマークを実施する場合、実際のシステム上でのテーブルデータのパターン、クエリパターン、トラフィック パターンを考慮してベンチマークの内容を設計することが重要です。
ここでは、次の要件を想定しています。
●テーブルには、1 行あたり 2 つのフィールドがある
●フィールドの最大長は 1,000,000
●レコードの最大数は 1 億個
●GET と SET の比率(クエリパターン)は 7:3
●通常のトラフィックは 1,000 ops/sec、ピーク時のトラフィックは 20,000 ops/sec
YCSB は構成ファイルを使用してベンチマークのパターンを制御できます。こうした要件を使用した例を次に示します(各パラメータの詳細情報をご確認ください)。実際のシステムではさまざまなフィールド長がありますが、YCSB で使用できるのは固定された fieldlength のみです。そのため、fieldlength=1,000,000 と recordcount=100,000,000 を同時に構成すると、ベンチマーク データのサイズと実際のシステムでのサイズには大きな差異が出ます。
その場合、次の 2 つのテストを行います。
●fieldlength が実際のシステムと同じテスト
●recordcount が実際のシステムと同じテスト
このブログ投稿では、後者を使った例を示します。
テストパターンとアーキテクチャ
構成ファイルを準備したら、テストパターンやアーキテクチャなどのテストの条件を考慮します。
テストパターン
異なる条件下のインスタンスでパフォーマンスを比較する場合は、ターゲット状態を定義します。このブログ投稿では、容量ティアに基づいて、次の 3 つのパターンのメモリ容量をテストします。
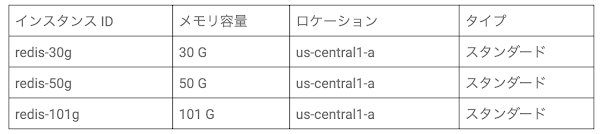
アーキテクチャ
ベンチマーク スクリプトを実行するには、VM を作成する必要があります。十分な数とマシンタイプを選択して、VM のリソースがベンチマークのボトルネックにならないようにしてください。ここでは Memorystore 自体のパフォーマンスを測定するので、ネットワーク レイテンシの影響を最低限に抑えるために、VM をターゲットの Memorystore と同じにします。アーキテクチャは次のようになります。
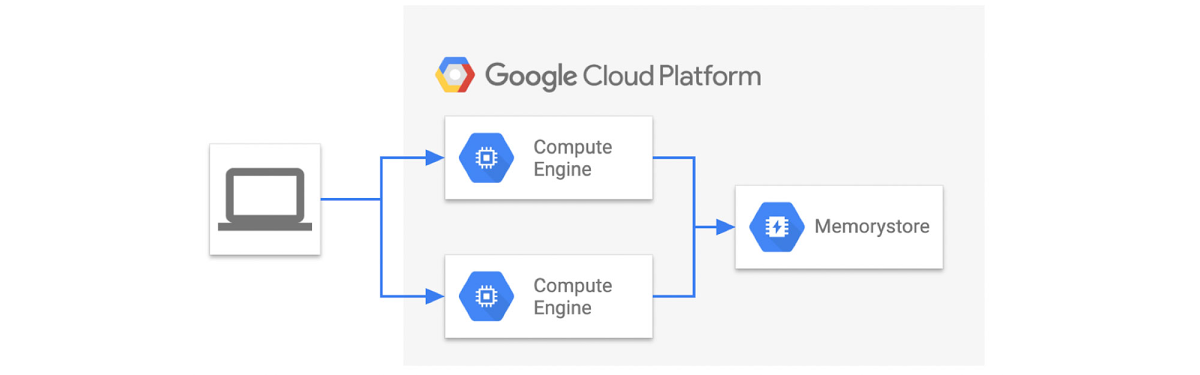
ベンチマーク ツールを実行する
これらを決定したら、ベンチマーク ツールを実行します。
スループット パターンを制御するためのランタイム オプション
クライアント スループットは、構成ファイルの operationcount パラメータと、-target <num> コマンドライン オプションの両方を使用することで制御できます。
YCSB の実行コマンドの例を次に示します。
パラメータ operationcount=3000 は構成ファイル内にあり、上記のコマンドを実行します。これは、YCSB が毎秒 10 個のリクエストを送信し、リクエストの合計数が 3,000 であることを意味します。つまり、YCSB は 300 秒間に 10 個のリクエストをスローするということです。
次のように、増分スループットでベンチマークを実施してください。1 回のベンチマーク実行時間は、外れ値の影響を軽減するために、やや長めにする必要があることに留意してください:
●クライアント スループットのパターン: 10、100、1,000、10,000、100,000
ベンチマーク データの読み込み
ベンチマークを実施する前に、テスト対象の Memorystore インスタンスにデータを読み込む必要があります。データを読み込む YCSB コマンドの例を次に示します。
ベンチマークの実施
データの読み込みとコマンドの選択が完了したので、ベンチマーク テストを実施できます。読み込む量に従って、YCSB を実行するためのプロセスの数とインスタンスを調整します。パフォーマンスに発生するボトルネックを特定するには、複数の指標を確認する必要があります。一般的に、次の指標を調べます。
レイテンシ
YCSB は、READ(GET) や UPDATE(SET) などのオペレーションごとに平均、最小、最大、95 パーセンタイル、99 パーセンタイルといった、レイテンシの統計情報を出力します。レイテンシの指標では、顧客のサービスレベル契約(SLA)によって、95 パーセンタイルか 99 パーセンタイルのどちらかを使用することをおすすめします。
スループット
YCSB が出力するオペレーション全体のスループットを使用できます。
リソースの使用状況の指標
リソースの使用状況の指標(CPU 使用率、メモリ使用量、ネットワークの入出力バイト、キャッシュ ヒット率など)は、Cloud Monitoring で確認できます。
Memorystore のパフォーマンスを調整する際のベスト プラクティス
ベンチマークが完了したので、ベンチマークの結果を使用して Memorystore を調整します。
結果によっては、ボトルネックを取り除いて Memorystore インスタンスのパフォーマンスを改善する必要があるでしょう。Memorystore はフルマネージド サービスのため、多くのパラメータは事前に最適化されていますが、特定のユースケースに合わせて調整できる項目もあります。
最適化の共通項目には次のようなものがあります。
●データの保存の最適化
●メモリ管理
●クエリの最適化
●Memorystore のモニタリング
データの保存の最適化
データの保存方法を最適化すると、メモリ使用量を節約できるだけではなく、I/O とネットワーク帯域幅も低減できます。
データを圧縮する
多くの場合、データを圧縮することでメモリ使用量とネットワーク帯域幅を大幅に削減できます。
使用ツールとして、レイテンシの影響を受けやすい場合は Snappy および LZO、圧縮率を最大化する場合は GZIP をおすすめします。詳細をご確認ください。
JSON から MessagePack へ
Msgpack とプロトコル バッファにあるスキーマは、JSON に似ていますが、JSON よりコンパクトです。Lua スクリプトでは MessagePack がサポートされています。
ハッシュデータ構造を使用する
ハッシュデータ構造でメモリ使用量を低減できます。たとえば、クエリ SET “date:20200501” “hoge” でデータが保存されているとします。このように連続した日付をキーとするデータが多くある場合、データを HSET “month:202005” “01” “hoge” として保存することで、ディクショナリのエンコードで必要なメモリ使用量を節約できることがあります。ただし、hash-map-ziplist-entries の値が大きすぎると、CPU 使用率が高くなることに注意してください。詳しくは、こちらをご覧ください。
インスタンスのサイズを小さくする
Memorystore の最大メモリ容量は 300 GB です。ただし、データが 100 GB 以上になると、単一インスタンスで処理できなくなり、CPU にボトルネックが発生してパフォーマンスが低下することがあります。このような場合は、少ないメモリ容量のインスタンスを複数作成して分散させ、アプリケーション側のキーを使用してアクセスポイントを変更することをおすすめします。
メモリ管理
メモリを効果的に使用することは、パフォーマンス調整という観点だけではなく、メモリ不足(OOM)などのエラーを発生させることなく Memorystore インスタンスの実行を安定させるためにも重要です。メモリ管理には、いくつかの手法を使用できます。
エビクション ポリシーを設定する
エビクション ポリシーは、Memorystore インスタンスのメモリがいっぱいになった場合にデータを削除するルールです。こうしたパラメータを適切に指定することで、キャッシュ ヒット率を高めることができます。エビクション ポリシーには、次の 3 つのグループがあります。
●Noeviction: より多くのデータを挿入しようとしているときにメモリが上限に達すると、エラーを返します。
●Allkeys-XXX: 選択されたデータを、すべてのキーから削除します。XXX は、削除対象のデータを選択するアルゴリズムの名前です。
●Volatile-XXX: 選択されたデータを、「expire」フィールドセットを持つすべてのキーから削除します。XXX は、削除対象のデータを選択するアルゴリズムの名前です。
Memorystore のデフォルトは volatile-lru です。エビクションおよびデータの TTL に合わせてデータ選択のアルゴリズムを変更してください。詳しくは、こちらをご覧ください。
メモリのデフラグメンテーション
メモリのデフラグメンテーションは、オペレーティング システムが割り当てたメモリページを、書き込みと削除のオペレーションが繰り返された後に Redis が最大限活用できない場合に発生します。このようなページが蓄積されるとシステムはメモリ不足に陥り、最終的に Redis サーバーがクラッシュする原因となります。
インスタンスが Redis バージョン 4.0 以上を実行している場合、インスタンスの activedefrag パラメータを有効にできます。Redis バージョン 5.0 の一部である Active Defrag 2 は、さらに優れた戦略を提供します。この機能は、CPU 使用率とのトレードオフになることに注意してください。詳しくは、こちらをご覧ください。
Redis のバージョンをアップグレードする
上述のとおり、activedefrag パラメータは Redis バージョン 4.0 以上でのみ使用でき、バージョン 5.0 ではより優れた戦略が提供されます。一般的に Redis の新しいバージョンでは、メモリ管理にとどまらず、さまざまなパフォーマンス最適化のメリットを得ることができます。Redis バージョン 3.2 をお使いの方は、バージョン 4.0 以上にアップグレードすることをおすすめします。
クエリの最適化
クエリの最適化はクライアント側で行うことができ、インスタンスに変更を加える必要もないため、Memorystore を使用する既存アプリケーションを最適化する最も簡単な方法となります。
クエリ最適化の効果は YCSB で調べることができないため、実際の環境でクエリを実行してレイテンシとスループットを確認してください。
パイプラインと mget / mset を使用する
複数のクエリが連続して実行されると、ラウンド トリップに起因するネットワーク トラフィックがボトルネックとなり、レイテンシが発生する原因となることがあります。このような場合は、パイプラインや、MSET / MGET のような集約コマンドの使用をおすすめします。
多くの要素で遅いコマンドの使用を避ける
遅いコマンドは slowlog コマンドでモニタリングできます。SORT、LREM、SUNION は多くのエレメントを使用するため、コンピューティング コストが高くなります。こうした遅いコマンドに問題があるかどうかを確認し、もし問題があれば、これらのオペレーションを減らすことをご検討ください。
Cloud Monitoring を使用した Memorystore のモニタリング
最後に、既存システムのパフォーマンス低下を予測できる、リソースのモニタリングについてご説明します。Memorystore のリソースのステータスは、Cloud Monitoring を使用してモニタリングできます。
デプロイする前に Memorystore に対してベンチマークを実施しても、本番環境での Memorystore のパフォーマンスは低下する可能性があります。これはシステムの成長や使用状況の変化など、さまざまな影響によって起こります。このようなパフォーマンス低下を初期段階で予測するために、リソースのステータスが特定のしきい値を超えるとアラートの送信やシステムのスケーリングを自動的に行うシステムを構築できます。
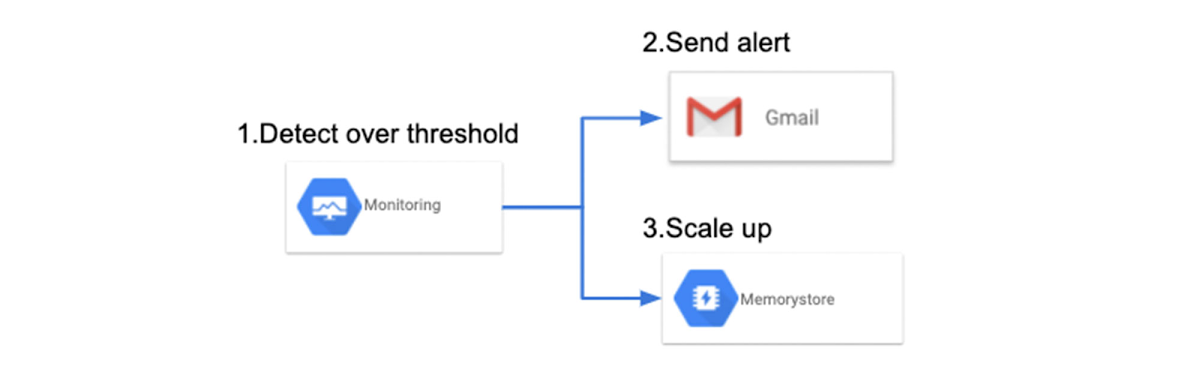
Google Cloud のエキスパートと連携して Memorystore のパフォーマンスを調整したいとお考えの方は、こちらから詳細についてお問い合わせください。
- By Chie Hayashida, Strategic Cloud Engineer, Google Cloud
