Performance tuning best practices for Memorystore for Redis
Chie Hayashida
Strategic Cloud Engineer, Google Cloud
Redis is one of the most popular open source in-memory data stores, used as a database, cache and message broker. There are several deployment scenarios for running Redis on Google Cloud, with Memorystore for Redis our integrated option. Memorystore for Redis offers the benefits of Redis without the cost of managing it.
It’s important to benchmark the system and tune it according to your particular workload characteristics before you expose it in production, even if that system depends on a managed service. Here, we’ll cover how you can measure the performance of Memorystore for Redis, as well as performance tuning best practices. Once you understand the factors that affect the performance of Memorystore for Redis and how to tune it properly, you can keep your applications stable.
Benchmarking Cloud Memorystore
First, let’s look at how to measure the benchmark.
Choose a benchmark tool
There are a few tools available to conduct benchmark testing for Memorystore for Redis. The tools listed below are some examples.
In this blog post, we’ll use YCSB, because it has a feature to control traffic and field patterns flexibly, and is well-maintained in the community.
Analyze the traffic patterns of your application
Before configuring the benchmark tool, it’s important to understand what the traffic patterns look like in the real world. If you have been running the application to be tested on Memorystore for Redis already and have some metrics available, consider analyzing them first. If you are going to deploy a new application with Memorystore for Redis, you could conduct preliminary load testing against your application in a staging environment, with Cloud Monitoring enabled.
To configure the benchmark tool, you’ll need this information:
The number of fields in each record
The number of records
Field length in each row
Query patterns such as SET and GET ratio
Throughput in normal and peak times
Configure the benchmark tool based on the actual traffic patterns
When conducting performance benchmarks for specific cases, it’s important to design the content of the benchmark by considering table data patterns, query patterns, and traffic patterns of the actual system.
Here, we’ll assume the following requirements.
The table has two fields per row
The maximum length of a field is 1,000,000
The maximum number of records is 100 million
Query pattern of GET:SET is 7:3
Usual traffic is 1k ops/sec and peak traffic is 20k ops/sec
YCSB can control the benchmark pattern with the configuration file. Here’s an example using these requirements. (Check out detailed information about each parameter.)
The actual system contains various field lengths, but you can use only solid fieldlength with YCSB. So, configuring fieldlength=1,000,000 and recordcount=100,000,000 at the same time, the benchmark data size will be far from one of the actual systems.
In that case, run the following two tests:
The test in which fieldlength is the same as the actual system;
The test in which recordcount is the same as the actual system.
We will use the latter condition as an example for this blog post.
Test patterns and architecture
After preparing the configuration file, consider the test conditions, including test patterns and architecture.
Test patterns
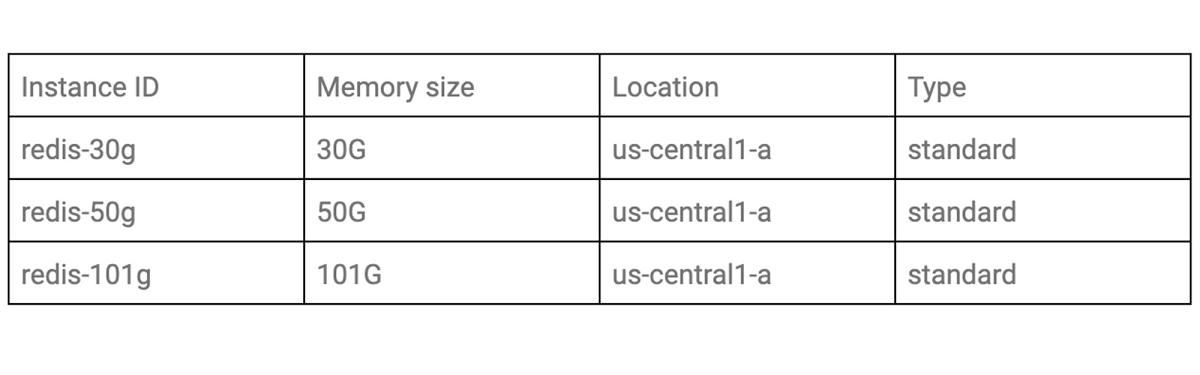
If you’d like to compare performance with instances under different conditions, you should define the target condition. In this blog post, we’ll test with the following three patterns of memory size according to capacity tier.
Architecture
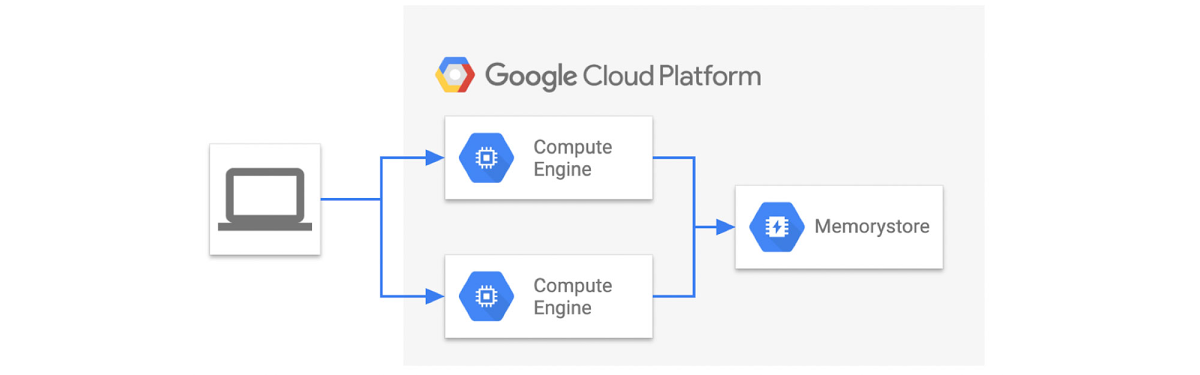
You need to create VMs to run the benchmark scripts. You should select a sufficient number and machine types so that VM resources don’t become a bottleneck when benchmarking. In this case, we'd like to measure the performance of Memorystore itself, so VMs should be in the same zone as the target Memorystore to minimize the effect of network latency. Here’s what that architecture looks like:
Run the benchmark tool
With these decisions made, it’s time to run the benchmark tool.
Runtime options to control the throughput pattern
You can control the client throughput by using both operationcount parameter in the configuration file, and the -target <num> command line option.
Here is an example of the execution command of YCSB:
The parameter operationcount=3000 is in the configuration file and running the above command. This means that YCSB sends 10 requests per second, and the number of total requests is 3,000. So YCSB throws 10 requests during 300sec.
You should run the benchmark with incremental throughput, as shown below. Note that a single benchmark run time should be somewhat longer in order to reduce the impact of outliers.:
Client throughput patterns: 10, 100, 1,000, 10,000, 100,000
Load benchmark data
Before running the benchmark, you’ll need to load data to the Memorystore instance that you’re testing. Here is the example of a YCSB command for loading data:
Run benchmark
Now that you have your data loaded and command chosen, you can run the benchmark test. Adjust the number of processes and instances to execute YCSB according to the load amount. In order to identify performance bottlenecks, you need to look at multiple metrics. Here are the typical indicators to investigate:
Latency
YCSB outputs latency statistics such as average, min, max, 95th and 99th percentile for each operation such as READ(GET) and UPDATE(SET). We recommend using 95th percentile or 99th percentile for the latency metrics, according to customer service-level agreement (SLA).
Throughput
You can use throughput for overall operation, which YCSB outputs.
Resource usage metrics
You can check resource usage metrics such as CPU utilization, memory usage, network bytes in/out, and cache-hit ratio using Cloud Monitoring.
Performance tuning best practices for Memorystore
Now that you’ve run your benchmarks, you should tune your Memorystore using the benchmark results.
Depending on your results, you may need to remove a bottleneck and improve performance of your Memorystore instance. Since Memorystore is a fully managed service, various parameters are optimized in advance, but there are still items that you can tune based on your particular use case.
There are a few common areas of optimization:
Data storing optimizations
Memory management
Query optimizations
Monitoring Memorystore
Data storing optimizations
Optimizing the way to store data not only saves memory usage, but also reduces I/O and network bandwidth.
Compress data
Compressing data often results in significant savings in memory usage and network bandwidth.
We recommend Snappy and LZO tools for latency-sensitive cases, and GZIP for maximum compression rate. Learn more details.
JSON to MessagePack
Msgpack and protocol buffers have schemas like JSON and are more compact than JSON. And Lua scripts has support for MessagePack.
Use Hash data structure
Hash data structure can reduce memory usage. For example, suppose you have data stored by the query SET “date:20200501” “hoge”. If you have a lot of data that’s keyed by such consecutive dates, you may be able to reduce the memory usage that dictionary encoding requires by storing it as HSET “month:202005” “01” “hoge”. But note that it can cause high CPU utilization when the value of hash-map-ziplist-entries is too high. See here for more details.
Keep instance size small enough
The memory size of a Memorystore instance can be up to 300GB. However, data larger than 100GB may be too large for a single instance to handle, and performance may degrade due to a CPU bottleneck. In such cases, we recommend creating multiple instances with small amounts of memory, distributing them, and changing their access points using keys on the application side.
Memory management
Effective use of memory is important not only in terms of performance tuning, but also in order to keep your Memorystore instance running stably without errors such as out of memory (OOM). There are a few techniques you can use to manage memory:
Set eviction policies
Eviction policies are rules to evict data when the Memorystore instance memory is full. You can increase the cache hit ratio by specifying these parameters appropriately. There are the following three groups of eviction policies:
Noeviction: Returns an error if the memory limit has been reached when trying to insert more data
Allkeys-XXX: Evicts chosen data out of all keys. XXX is the algorithm name to select the data to be evicted.
Volatile-XXX: evicts chosen data out of all keys with an “expire” field set. XXX is the algorithm name to select the data to be evicted.
volatile-lru is the default for Memorystore. Change the algorithm of data selection for eviction and TTL of data. See here for more details.
Memory defragmentation
Memory fragmentation happens when the operating system allocates memory pages, which Redis cannot fully utilize after repeated write and delete operations. The accumulation of such pages can result in the system running out of memory and eventually causes the Redis server to crash.
If your instances run Redis version 4.0 or higher, you can turn on activedefrag parameter for your instance. Active Defrag 2 has a smarter strategy and is part of Redis version 5.0. Note that this feature is a tradeoff with CPU usage. See here for more details.
Upgrade Redis version
As we mentioned above, activedefrag parameter is only available in Redis version 4.0 or later, and version 5.0 has a better strategy. In general, with the newer version of Redis, you can reap the benefits of performance optimization in many ways, not just in memory management. If your Redis version is 3.2, consider upgrading to 4.0 or higher.
Query optimizations
Since query optimization can be performed on the client side and doesn’t involve any changes to the instance, it’s the easiest way to optimize an existing application that uses Memorystore.
Note that the effect of query optimization cannot be checked with YCSB, so run your query in your environment and check the latency and throughput.
Use pipelining and mget/mset
When multiple queries are executed in succession, network traffic caused by round trips can become a latency bottleneck. In such cases, using pipelining or aggregated commands such as MSET/MGET is recommended.
Avoid heavy commands on many elements
You can monitor slow commands using slowlog command. SORT, LREM, and SUNION, which use many elements, can be computationally expensive. Check if there are problems with these slow commands, and if there are, consider reducing these operations.
Monitoring Memorystore using Cloud Monitoring
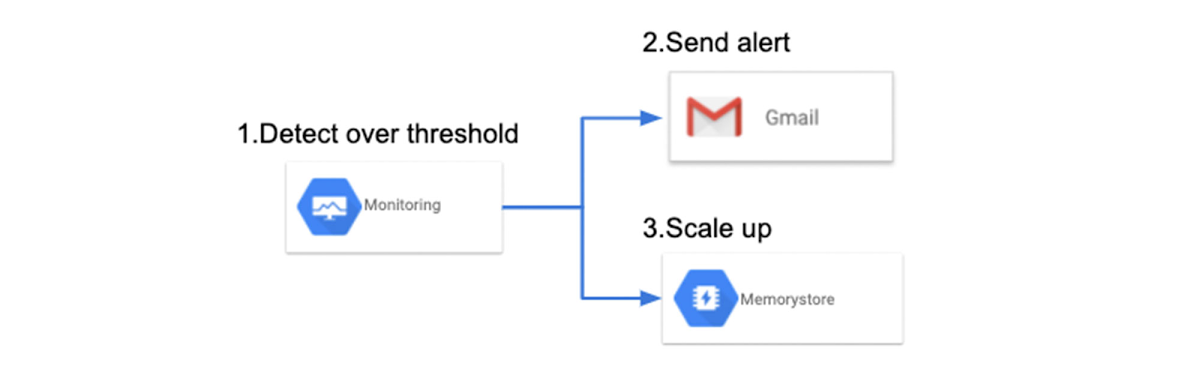
Finally, let’s discuss resource monitoring for predicting performance degradation of existing systems. You can monitor the resource status of Memorystore using Cloud Monitoring.
Even when you benchmark Memorystore before deploying, the performance of Memorystore in production may degrade due to various influences such as system growth and changes of usage trends. In order to predict such performance degradation at an early stage, you can create a system that will alert you or scale the system automatically, when the state of the resource exceeds a certain threshold.
If you would like to work with Google Cloud experts to tune your Memorystore performance, get in touch and learn more here.



