オンデマンド バックアップ、エミュレート、開発が容易に -- Spanner の新機能
Google Cloud Japan Team
※この投稿は米国時間 2020 年 4 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
Google が Cloud Spanner を構築した背景には、リレーショナル セマンティクスを備えたスケーラブルなマルチバージョン データベースの必要性が Google 社内で高まっていた状況があります。今では、グローバルに分散され、強整合性を備えたデータベース サービスが必要なチームにとって無くてはならぬ機能の一つとなりました。今後も Spanner の新しいエンタープライズ機能をリリースしていく計画で、まずマネージド バックアップ / 復元機能の一般提供を開始しましたので、この機を借りてお知らせいたします。これにより高いビジネス継続性を実現し、管理オーバーヘッドを増やさずにデータ保護を追加できます。これは論理データの破損を招くユーザーエラーやアプリケーション エラーに対する保護機能で、リージョンまたはマルチリージョン構成で整合性のあるデータベース バックアップをオンデマンドで取得し、同じインスタンス構成で元のインスタンスや別のインスタンスに復元できるようになりました。こうした復元は、バックアップ データへのアクセスの TTFB(Time to First Byte、最初のバイトまでの時間)を短縮するように最適化されています。つまり障害発生後数分以内で、バックアップからテラバイトのデータにアクセスして復元できるということです。
Alphabet 傘下企業でライフ サイエンスとヘルスケアの組織である Verily は、COVID-19(新型コロナウイルス感染症)の検疫と検査へのアクセスを拡大するために、Project Baseline というCOVID-19 検査プログラムを立ち上げました。Verily は Spanner を利用し、需要に応じて Project Baseline アプリケーションを自動スケーリングして高可用性を実現しています。Spanner はスケール保証に加えて強力な外部整合性を提供し、最大 99.999% の月間稼働率 SLA を実現します。金融サービス、小売、ゲーム、テクノロジーなど、さまざまな業界の Google Cloud のお客様はワークロードに Spanner を活用することで、リレーショナル セマンティクス、アトミック トランザクション、強力な外部整合性などの要件と、迅速なスケーラビリティを両立させています。
新しいマネージド バックアップ / 復元機能はクライアント ライブラリ、API、gcloud、Cloud Console でご利用いただけます。この機能を使用すると、データベースのサイズに関係なくデータベースのバックアップと復元を実行できます。この機能が実際どのように実装されているかを下図でご覧ください。
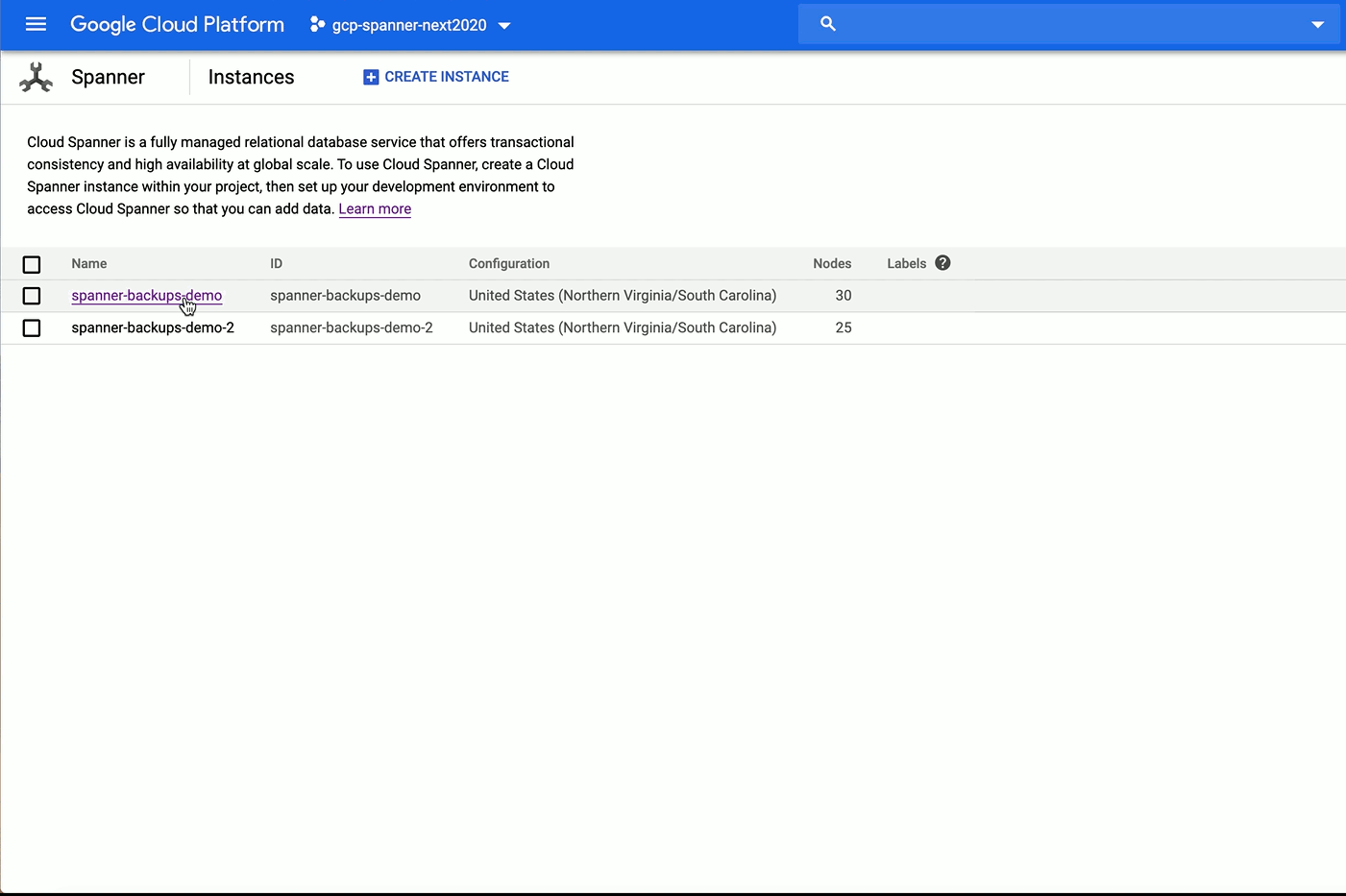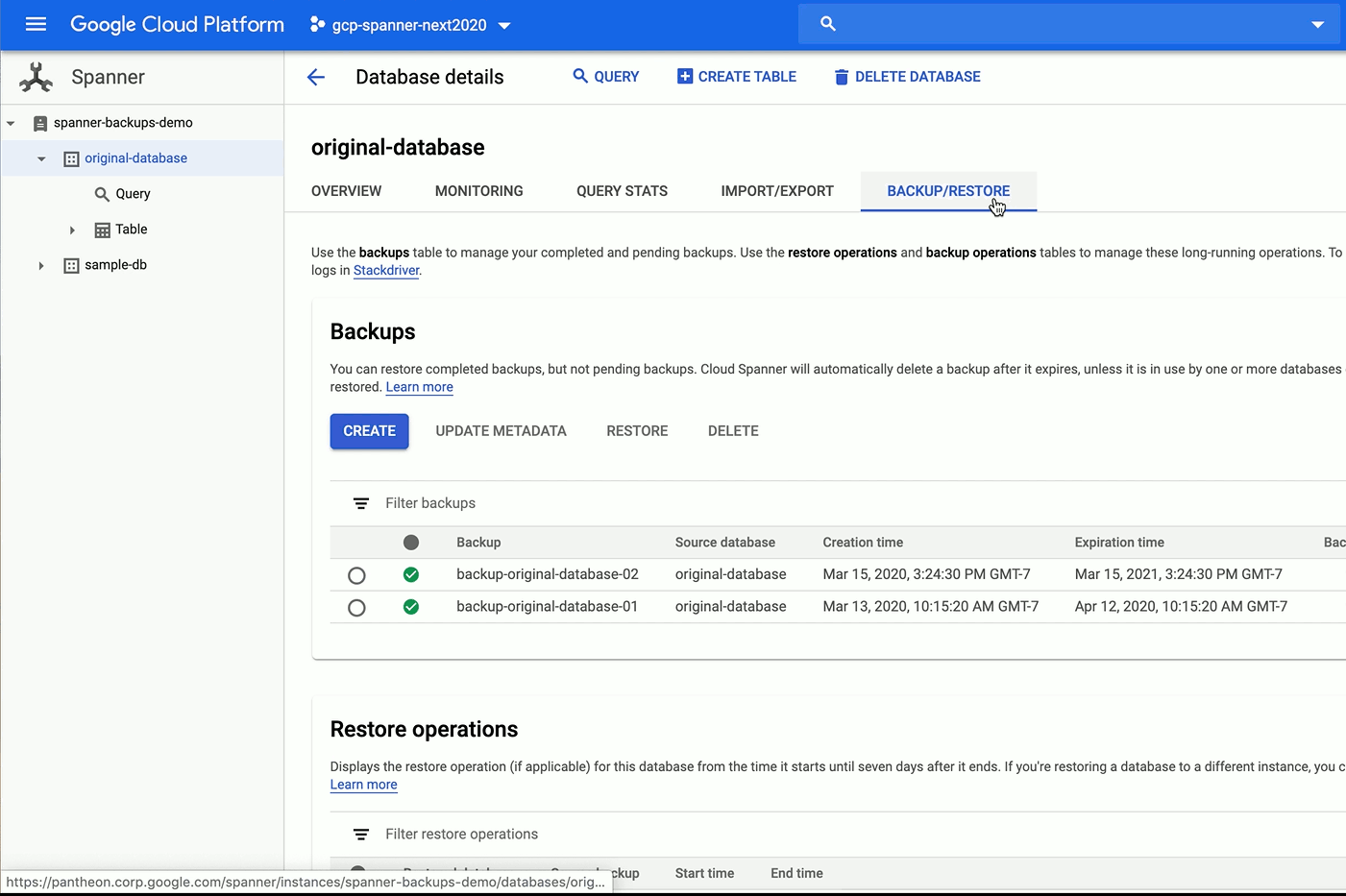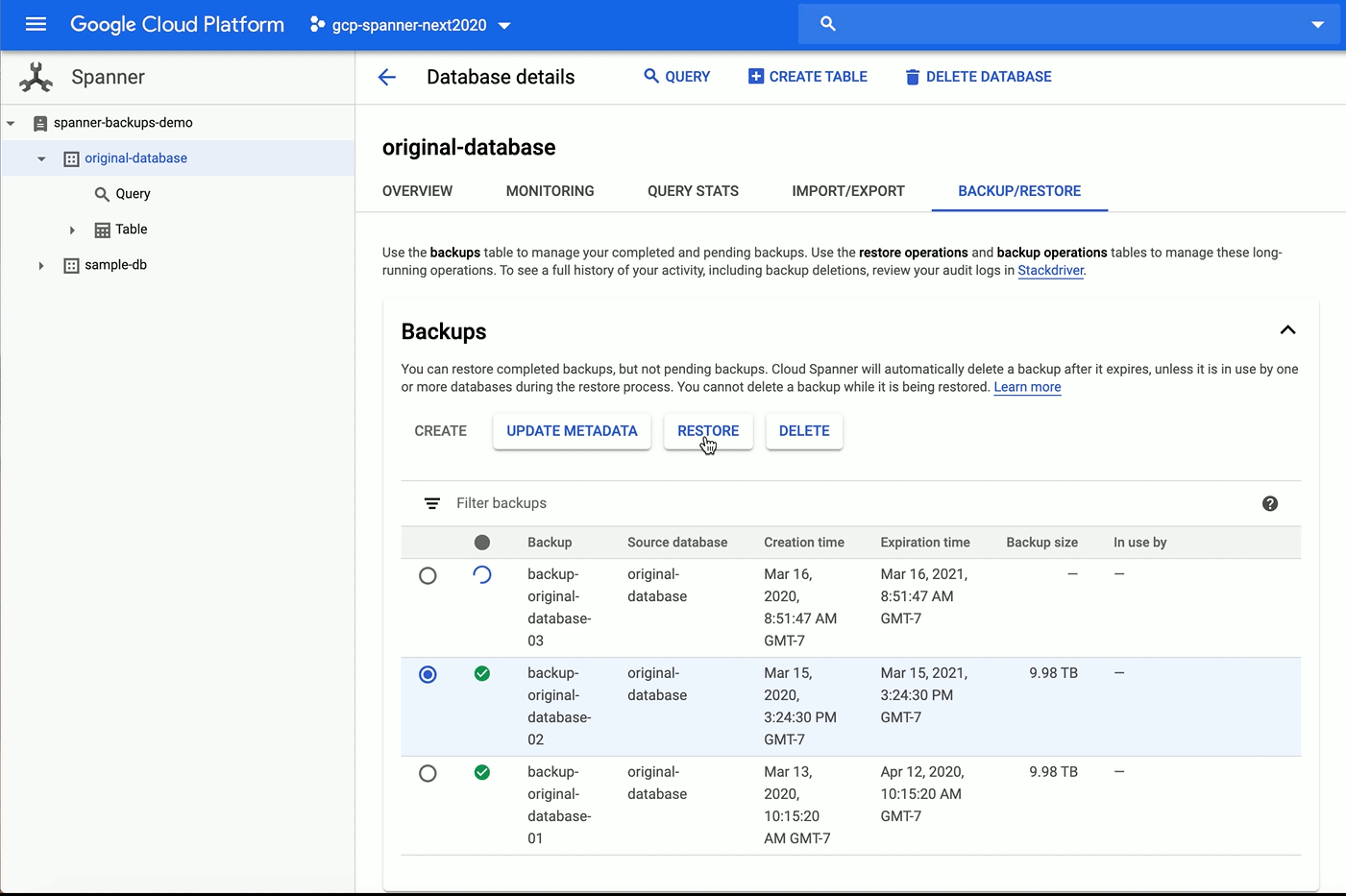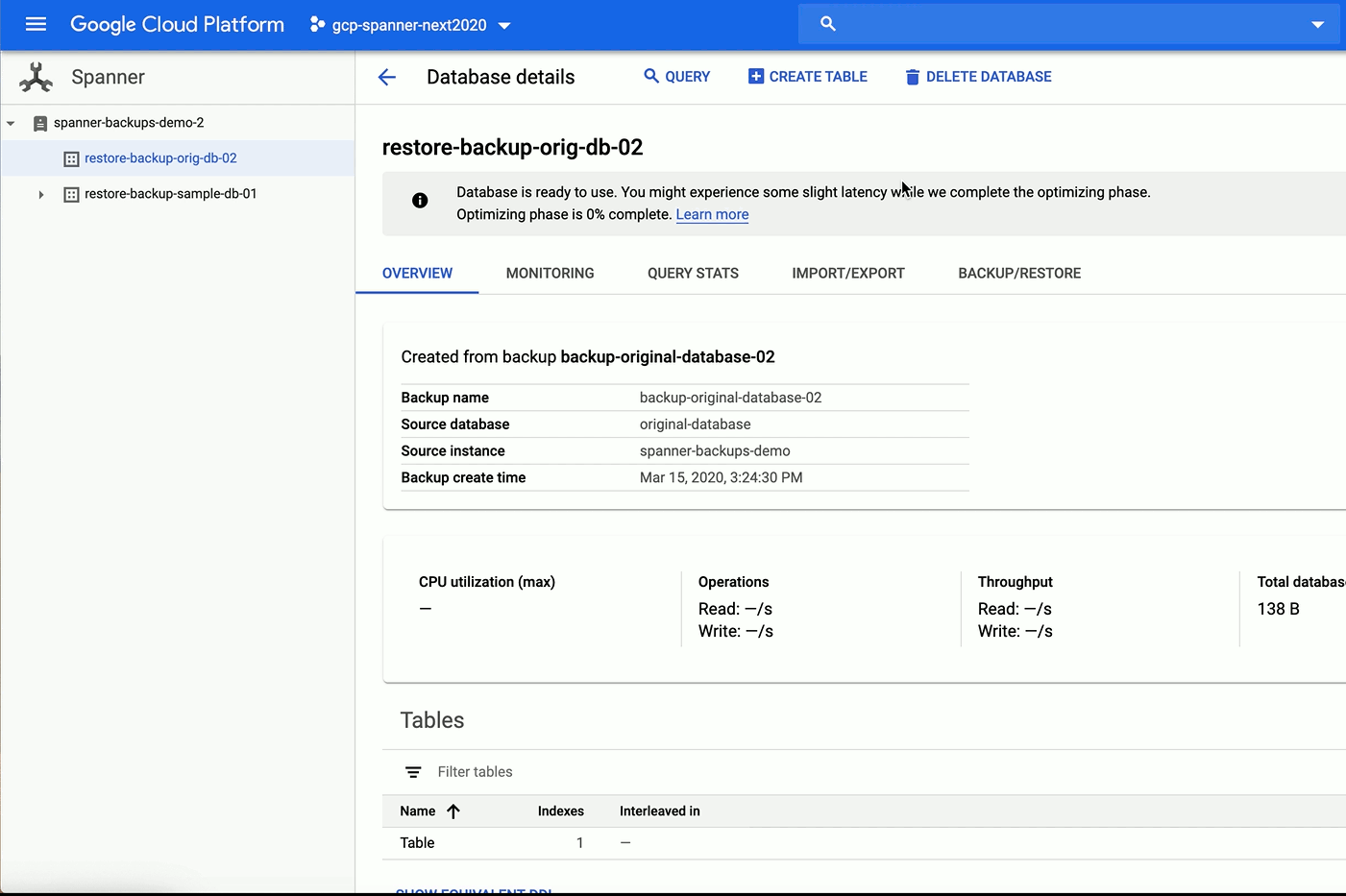
Spanner を使用したアプリケーションの開発エクスぺリエンスの信頼性、柔軟性、使いやすさをさらに強化する新機能も導入しています。そうした新機能の一部を以下にご紹介します。
Cloud Spanner Emulator は正確性テストに使用できます。Spanner Emulator はオフライン環境で実行し、Spanner API(REST と gRPC)と SQL レイヤのエミュレーションを提供します。アプリケーション開発コストの削減と、デベロッパーの生産性向上に役立ちます。
Spanner のオプティマイザーは確立されたヒューリスティクスとコストベースの最適化を組み合わせて、最適な CPU 使用率で低レイテンシ クエリを実行するための効率的なプランを作成します。新しくリリースされたクエリ オプティマイザーのバージョニングにより、Spanner はさらに効率的なクエリ実行プランを生成できるようになりました。ただし、小さなサブセットのクエリの場合、パフォーマンス プロファイルに変動が見られる可能性があります。クエリ オプティマイザーのバージョニングを使用すると、より綿密な制御が可能となり、特定のオプティマイザー バージョンでデータベース、アプリケーション、クエリを実行して最高のパフォーマンスを発揮できます。また、都合に合わせて新しいバージョンと以前のバージョンの切り替えもできます。
Spanner の外部キーを使用すると、異なるテーブルの列の間で参照整合性制約を定義できます。Spanner は無効なデータの追加を拒否することで参照整合性を確保します。外部キーのサポートが追加され、Spanner でテーブルデータを関連付ける方法が外部キーとインターリーブの 2 つになりました。インターリーブも参照整合性制約を提供しますが、主に役立つのは親子テーブルの間でデータを物理的に同じ場所に配置してクエリのパフォーマンスが改善する場合です。
ゲームや金融サービスなど、高パフォーマンスを要求するものが何であれ、C++ でアプリケーションを開発しているデベロッパー向けに、Spanner 用に C++ のイディオムをサポートするクライアント ライブラリの提供を開始しました。このライブラリは、セッション プール管理や再試行ロジックなどのベスト プラクティスが実装されているため、アプリケーション デベロッパーはこのようなタスクについて心配する必要がありません。
詳細
Spanner の利用を開始するには、インスタンスを作成するか、Spanner Qwiklabs でお試しください。Google Cloud は現在、Qwiklabs へのアクセスを含むトレーニングと認定資格への無料アクセスを 30 日間提供しています。2020 年 4 月 30 日より前に登録すると、無料でご利用を開始していただけます。
- By Google Cloud プロダクト マネージャー Vaibhav Govil


