Cloud Spanner のウォームアップ ツールとベンチマーク ツールでアプリケーションのリリースを簡単に
Google Cloud Japan Team
※この投稿は米国時間 2022 年 2 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
Cloud Spanner は無制限のスケーリング、強整合性、最大 99.999% の可用性を備えたフルマネージド リレーショナル データベースです。整合性、スケーリング、可用性の性能をデフォルトで実現するために、Cloud Spanner は自動でデータベースをシャーディングする組み込みメカニズムを備えており、透明性がありシームレスなエクスペリエンスを提供します。Spanner は分散型データベースで、データベースのサイズが大きくなると、データはスプリットというシャードに分割されます。個々のスプリットはそれぞれ独立した存在で、別のサーバーに割り当てられます。また、物理的に別の場所に配置される場合があります。詳しくは、データベースのスプリットをご覧ください。
Spanner は、負荷とサイズに基づいてデータを分割します。スプリットは、Spanner ノード間で動的に移動し、データベース全体の負荷を分散させます。Spanner に挿入されるデータが多いほど、より多くのスプリットが生成されます。
次の図には 4 つのノード(または 4,000 の処理ユニット)があり、インスタンス構成内の各ゾーンで 4 つのサーバー リソースの利用が可能です。Spanner にデータがないため、データの書き込みが開始すると、1 つのスプリットのリーダーが割り当てられている 1 つのサーバーにのみデータが書き込まれます。現在、Spanner はコールド状態です。
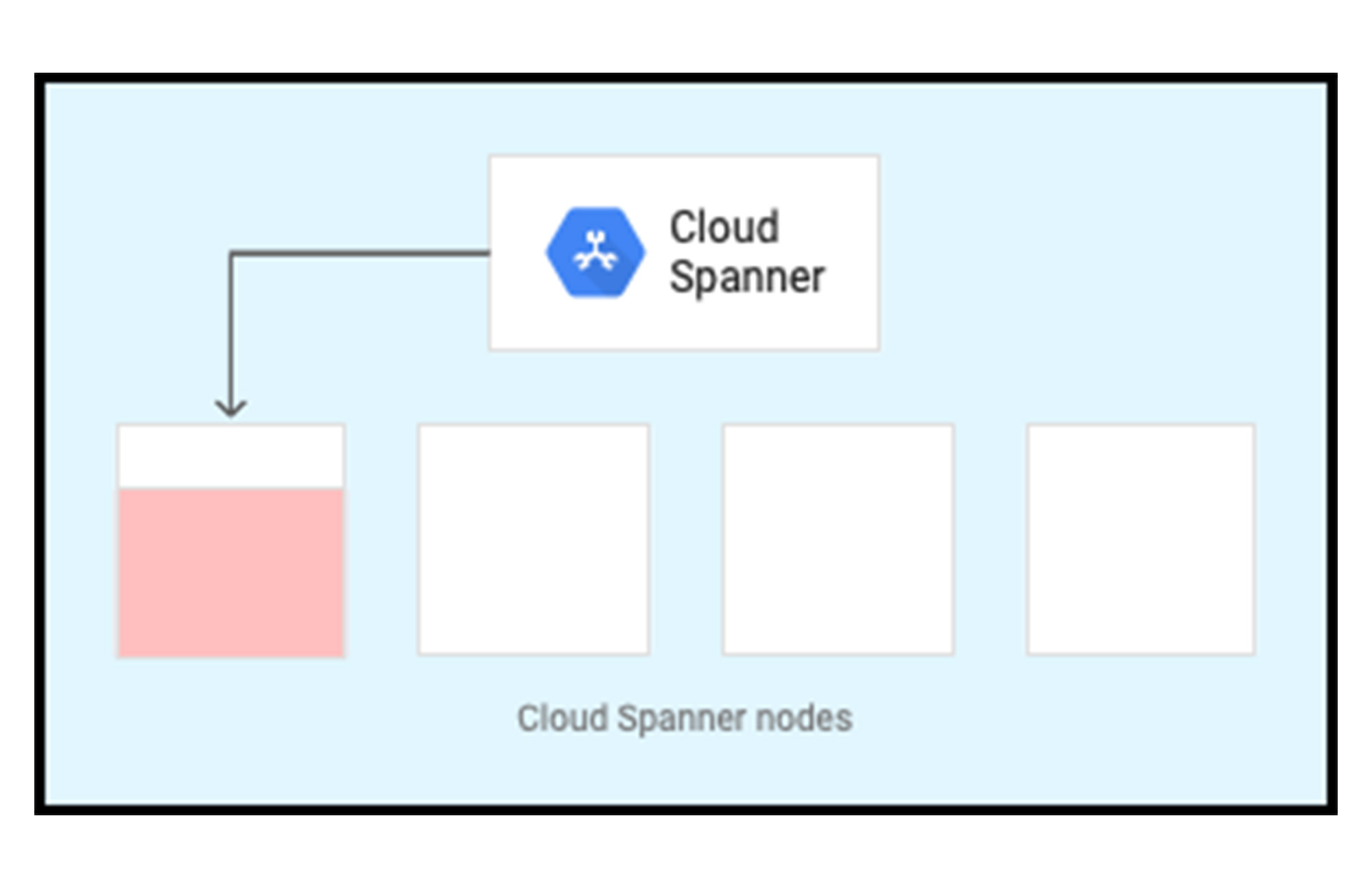
次の図では、スプリットが別のノードに移動しています。データがシステムに入力されると、Spanner はデータの分割を開始し、4 つのノード向けにプロビジョニングされたサーバー リソース全体に負荷を分散します。これで、Spanner がウォーム状態になりました。
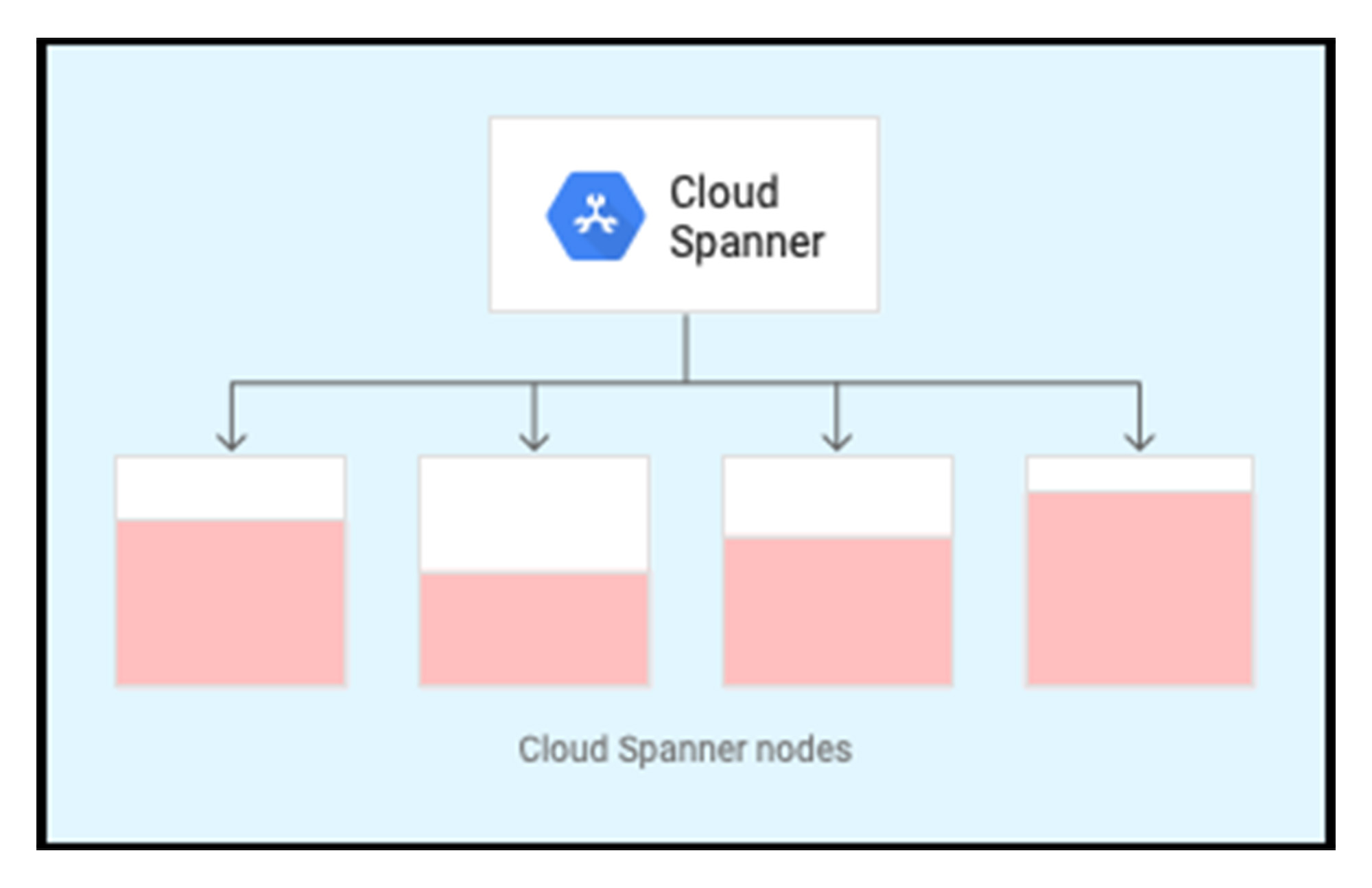
最高のパフォーマンス特性を実現するためには、Spanner がウォーム状態で、すべてのサーバー リソースにわたってスプリットが分散されているときに本番環境のアプリケーションを立ち上げることをおすすめします。
Cloud Spanner のウォームアップ
以下の手順は、データベースの準備を行うための 1 つの方法です。
本番環境のスキーマで Cloud Spanner のインスタンスとデータベースを作成します。均整のとれた状態でウォームアップするために、すべてのインデックスを含めることをおすすめします。
大量のトラフィックが見込まれるか、本番環境アプリケーションのレイテンシのために不可欠である重要なテーブル向けに負荷を生成します。
負荷に使用するテーブルの主キーが、本番環境のトラフィックに使用されたキーと同じキースペースにある(同じ統計特性を持つ)ことを確認します。
アプリケーションのリリースの 2 日前に負荷を実行します。また、想定されるピークの時間またはそれに近い時間帯で、1 時間にわたって負荷を実行することをおすすめします。この負荷により、Spanner は負荷に応じて分割を行い、複数のスプリットを生成します。
ウォームアップが完了した後は、パーティション化 DML を使用した行の削除をおすすめします。そうすることで、アプリケーションのリリースのために継続してスプリットが利用できます。テーブルまたはインデックスの削除はおすすめしません。
負荷の生成
負荷を作成する際は、以下のツールを使用して、単一テーブル向けにランダムデータおよび合成データの生成が可能です。ツールにおいては、データを生成するテーブルのスキーマが推測されます。お客様はツールを調整してデータのサイズ、列のサイズ、キー範囲、読み取りと書き込みの配分を再現できます。それにより、想定されるパフォーマンス値をリリース時に提供できるようになります。また、(想定される本番環境トラフィックの範囲で)適切なサイズの負荷を生成するためには、GKE クラスタからツールを実行することをおすすめします。
ネットワーク レイテンシを短縮するための最適な方法は、Spanner インスタンスに近いところに GKE クラスタを配置することです(可能であればリージョン インスタンスと同じリージョンか、マルチリージョン インスタンスのデフォルトのリーダー リージョンにします)。
Cloud Spanner の設定
GKE の設定
ツールの実行
Cloud Spanner データベース上に適切な負荷を作成するために、gke_load.yaml ファイルを編集して GKE クラスタ上のスレッド、オペレーション、Pod の数を更新し、Spanner リソースの情報を供給します。モニタリング
Cloud Console 上のスループットとレイテンシのグラフをモニタリングします。より多くのスプリットが作成されることで、ツールは徐々により高いスループットを生み出せるようになり、想定される本番環境でのピーク時のトラフィックに到達し維持できるようになります。
通常は最長でも最初の約 30 分で安定した P99 レイテンシを獲得し、約 1 時間で安定した P99.9 レイテンシを獲得します。スループットは、最長でも最初の 30 分で想定されるスループットに近づきます。
おすすめの使用例
スプリットはデータベースの使用量とスキーマに基づいて作成され、既存のデータベースを再利用することで新たなデータベースとは異なる特性を持つ場合があります。
テーブルを削除しただけのデータベースを再利用すると、関係のないスプリットが残る場合があり、予期せぬ動作の要因になることがあります。
ウォームアップのために既存のテーブルを再利用すると、ツールによってデータベースに書き込まれたランダムなデータを追跡します。推奨される方法の一つとして、gcsb で自動入力される null 許容の commit_timestamp 列を作成することが挙げられます。こうした行はウォームアップの後に削除される場合があり、commit_timestamp 列もウォームアップの後に削除される場合があります。
インデックスを含む完全な本番環境スキーマを持つデータベースを作成します。
注意: このツールは現在、こちらの機能をサポートしていません。
ウォームアップのツールは、本番環境ワークロードの代表となるようなデータを調整する機能を提供します。
すべての主キーは適切なスプリットを作成するために、本番環境のデータベースと同じキースペースにある必要があります。
列データでは、全体的な行の長さを本番環境の負荷と同等に保つようにサイズを構成することもできます。
ウォームアップを開始する前に、すべてのセカンダリ インデックス(インターリーブされたインデックスを含む)を作成することをおすすめします。また、インデックスはデータ負荷に基づいて自動で分割されます。適切なスプリットを得るためには、本番環境のワークロードと同じキースペースにあるインデックスの主キーを読み込むことが重要です。
インターリーブされたテーブルの場合は、ウォームアップの手順は子テーブルの使用量に応じて違ってくる場合があります。
子テーブルが親の単一行のもとで多数の行(1,000 以上)を保有することが見込まれる場合は、ウォームアップ処理の中で子テーブル内に(本番環境とおおよそ同程度の桁数の)行を追加することをおすすめします。
ただし、各親の行に数行しかない場合は、親のテーブルをウォームアップするだけで十分です。
ウォームアップの処理にかかる時間は数分ですが、場合によってはシステムを安定させるために最長で 1 時間かかることもあります。ウォームアップの処理は、少なくとも 1 時間は実行することをおすすめします。最大 50 ノードまでの Spanner インスタンスの場合は、ウォームアップして安定した QPS とレイテンシで実行できるまでに約 1 時間かかる場合があります。それより大きなインスタンスの場合は、インスタンスが 2 倍になるごとに 5~10 分ほど追加で時間がかかります。例: 50 ノードのインスタンスの場合は最大で 60 分、100 ノードの場合は約 70 分、1,000 ノードの場合は約 100 分かかることがあります。
また、推奨される CPU しきい値の範囲内で実行できるように、ウォームアップ ツールの構成を調整しておくことをおすすめします。
本番環境アプリケーションのリリース前には、ツールで作成された合成データを追跡し削除するようにしましょう。データはパーティション化 DMLを使用して削除できます。
ピーク時のトラフィックを作成するために、スレッドと GKE Pod を調整することが前提条件となります。各実行の中でスレッドの数をスケーリングするのではなく、さらに GKE Pod を追加することでスループットをスケーリングし、各 Pod の CPU の競合を避けるようにします。
検証
Cloud Spanner のデータベースが本番環境アプリケーションの想定されるスループットを確実に実現できるように、ウォームアップの後に読み取りと書き込みのワークロードを実行します。このワークロードでは、必要に応じてさらなるスプリットを継続して作成します。そしてなによりも、アプリケーションのリリースのためにレイテンシとスループットに対する分析情報を提供してくれます。
既存のデータベースまたはテーブルの準備のために、この手順が活用される場合があります。お客様は、リリース前にスプリットされるテーブルに対して特定のキー範囲(config)を指定できます。
読み取り / 書き込みのトラフィックを生成するために、Spanner リソースの情報を提供する gke_run.yaml ファイルおよび、想定される読み取りと書き込みのトラフィックを編集します。また、設定では強力な読み取りおよびスナップショットの読み取りが構成でき、本番環境のワークロードに近い形で再現できます。
また、検証のための追加の相関する指標として、全テーブル スキャンのクエリは、少なくとも Spanner インスタンス内のノード数と同じだけ実行されている必要があります。クエリの実行を確認するために、Cloud Console で以下を実行し、プランを調べることができます。
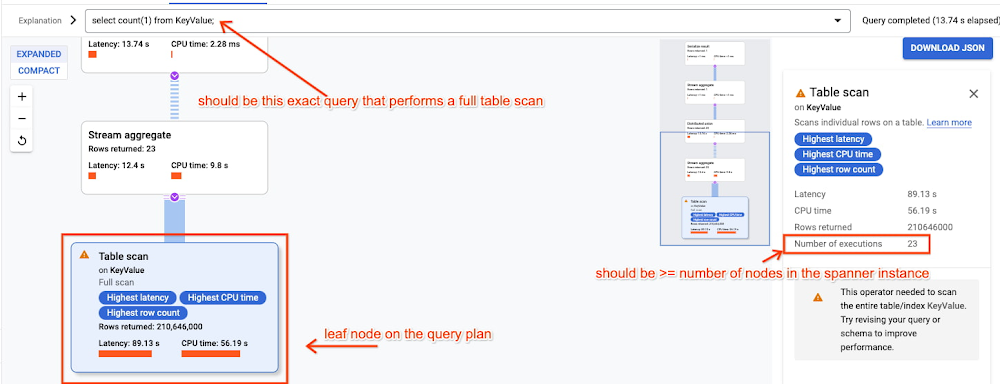
必要であれば、Cloud Spanner Key Visualizer を使用して、生成された読み取り / 書き込みのトラフィックでキーの配布を表示します。ウォームアップのために特定のキー範囲を構成する場合、キー範囲での読み取りまたは書き込みで一貫して高い数字が見られ、明るい帯として Key Visualizer に表示されます。インデックス登録済みの列に書き込みワークロードを構成する場合、インデックスに書き込みアクティビティが表示されます。
結論
Spanner は、分散型でグローバルにスケーラブルな SQL データベース サービスで、コンピューティングとストレージを切り離して、処理リソースをストレージとは別にスケールできます。分散型スケーリングが可能な Spanner のアーキテクチャは、オンライン ゲームのような予測不可能なワークロードに最適なソリューションです。こちらのホワイトペーパーで、Spanner を活用してグローバルなマルチプレーヤー ゲームを開発する方法をご確認ください。
- シニア ソフトウェア エンジニア Sneha Shah

