AlloyDB for PostgreSQL の仕組み: カラム型エンジン

Google Cloud Japan Team
※この投稿は米国時間 2022 年 5 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
Google は最近、Google I/O にて AlloyDB for PostgreSQL を発表いたしました。これは、要求が厳しいエンタープライズ クラスのトランザクション / 分析ワークロードに使用できる、PostgreSQL 対応のフルマネージド データベースです。弾力性のあるストレージとコンピューティング、インテリジェントなキャッシュ、AI / ML による管理といったクラウドの優れた特徴を、PostgreSQL に統合できるようになります。さらに、AlloyDB は圧倒的なコスト パフォーマンスを実現します。パフォーマンス テストでは、標準の PostgreSQL と比較してトランザクション ワークロードで 4 倍以上、分析クエリで最大 100 倍も高速になるという結果が出ています。しかも AlloyDB は、シンプルで予測可能な料金体系となっています。AlloyDB はミッション クリティカルなアプリケーション向けに設計されており、広範なデータ保護と業界をリードする 99.99% の可用性 SLA(メンテナンスを含む)を提供します。
AlloyDB for PostgreSQL のパフォーマンスと可用性の向上は、複数の革新的な技術によって支えられています。「AlloyDB for PostgreSQL の仕組み」シリーズの第一弾では、AlloyDB のインテリジェント ストレージ レイヤについて説明しました。本日は、分析の高速化を可能にする AlloyDB のベクトル化カラム型実行エンジンについて取り上げます。
PostgreSQL とハイブリッド ワークロード パターン
PostgreSQL などの汎用データベースの多くは、さまざまなワークロードをサポートしています。このようなワークロードの一部は純粋にトランザクショナルな性質を持っています。以前の投稿で説明したとおり、インテリジェント ストレージ レイヤの貢献により、このようなワークロードに関する Google のパフォーマンス テストで AlloyDB が標準的 PostgreSQL の 4 倍以上も高速になりました。しかし PostgreSQL には豊富なクエリ機能もあり、多くのユーザーがアプリケーションの内部および外部でそれを活用しています。分析クエリ、つまり大量のデータに対するスキャン、結合、および集計を伴うクエリは、多くのリレーショナル データベース ワークロードの中核を占めています。これには次のものが含まれます。
エンドユーザーにサービスを提供するアプリケーション内部のクエリ。例: 複数の資産にわたる最近の売上に基づいて、特に人気がある商品を地域別に表示する e コマース アプリケーション
最新のデータにアクセスする必要があるリアルタイム ビジネス分析情報。例: ユーザーがカートに入れた商品、時間帯、および購買行動履歴に基づいて追加購入の提案を表示する、小売アプリケーション内のレコメンデーション エンジン
開発者やユーザーが質問の答えを得るためにデータベースに直接照会する必要があるアドホック クエリ。例: 規制当局向けに最近のトランザクションの監査を実施すること
このようなさまざまなユースケースで優れた性能を発揮するように運用データベースを調整することは困難です。従来、この種のワークロードを持つユーザーはインデックスを作成し、スキーマを最適化することで、十分なクエリ パフォーマンスを確保する必要がありました。この方法では管理の複雑さが増すだけでなく、トランザクションのパフォーマンスにも影響が出る可能性があります。またクエリ パフォーマンスが低いと、開発者がエンドユーザーに提供できる機能が制限され、リアルタイム ビジネス分析情報の進歩が妨げられる可能性もあります。
AlloyDB が現状を改善します。カラム型エンジンを備えた AlloyDB は、分析クエリに関する Google のパフォーマンス テストで標準的 PostgreSQL に比べて最大 100 倍速い性能を記録しました。その際、スキーマの変更も、アプリケーションの変更も、ETL も必要ありませんでした。この技術は、頻繁に照会されるデータをメモリ内のカラム型形式で保持することにより、スキャン、結合、集計を高速化します。
AlloyDB に組み込まれた機械学習のおかげで、この技術をより容易に利用できるようになりました。AlloyDB は、データを自動的に行ベース形式とカラム型形式に分けて整理します。その際、ワークロードの学習に基づいて適切な列とテーブルを選択し、それらをカラム型形式に自動的に変換します。クエリ プランナーは、カラム型実行プランと行ベースの実行プランをスマートに使い分けることで、トランザクションのパフォーマンスを維持します。これにより、AlloyDB は管理オーバーヘッドを最小限に抑えながら、さまざまなクエリに対して優れたパフォーマンスを提供できます。
列指向のデータ表現の復習
従来型のデータベースは行指向であり、固定サイズのブロックにデータを格納します。この編成は、1 行全体の情報を調べる必要のあるアクセス パターンに最適です。たとえばアプリケーションで特定ユーザーに関する情報を検索する場合です。行指向のストレージは、この種のアクセス パターン向けに最適化されています。
分析クエリには、別のアクセス パターンが必要です。行指向のデータストアから分析クエリの答えを得るには、テーブル全体をスキャンして、テーブルに格納されたデータの大部分が質問の答えと無関係だとしても、すべての行のすべての列を読み取る必要があります。
列指向のデータ表現を使用すれば、単一の列に値をまとめて保持することで、分析の質問の答えが迅速に得られます。関連する列にアクセスを集中させることにより、列指向のデータベースは分析クエリにより速く応答できます。
AlloyDB のカラム型エンジン
Google は、特に BigQuery などのサービスを提供することで、大規模データ分析における長い革新の歴史を築いてきました。これらのサービスでは、最適化されたカラム型データ レイアウト、最先端のクエリ処理技術、およびハードウェア アクセラレーションなどを通して迅速かつ拡張可能なクエリ処理が可能です。
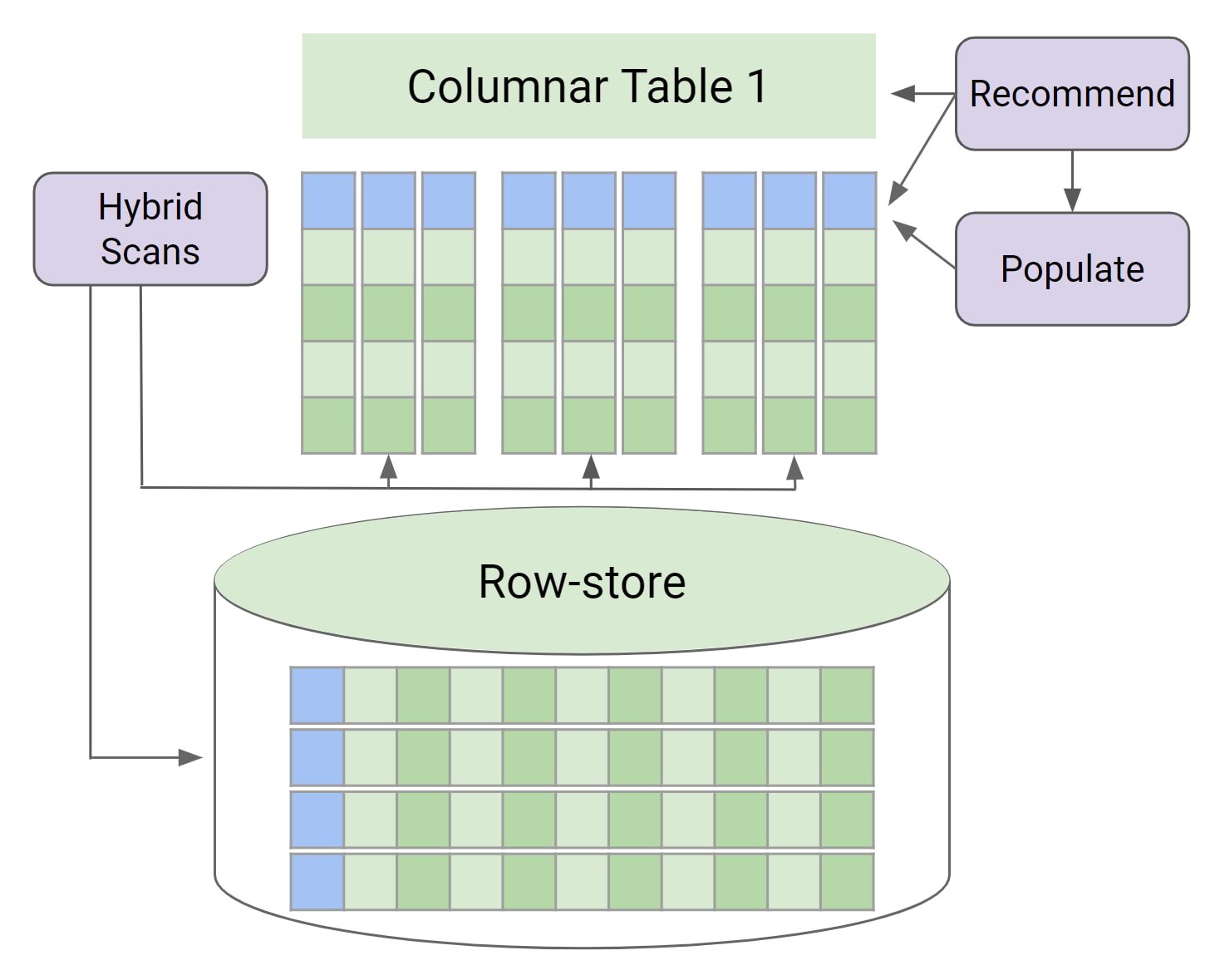
AlloyDB は、これと同じ技術的な進歩の一部を、PostgreSQL と互換性のある運用データベースに直接組み込んでいます。また、トランザクション処理用の行ベース形式と、カラム型形式のストレージおよび実行エンジンとを組み合わせて、両者のメリットを活用します。
カラム型エンジンは、大量のカラム型データを効率的に処理する最新型のベクトル化クエリ処理エンジンです。その際、システム キャッシュと、今日の CPU から出されるベクトル処理命令を最適な形で利用します。
最新型ハードウェアの機能を利用することに加えて、カラム型エンジンには、クエリ処理をさらに高速化するためのアルゴリズム最適化がいくつか含まれています。最小値や最大値などの列固有のメタデータを利用してスキャンを高速化します。またスキャン結果を実体化することなく、該当する列に対して直接、集計などの他のオペレーションを実行できます。最後に、ハイブリッド実行は、カラム型クエリ処理技術と行指向のクエリ処理技術を状況に応じて適切に組み合わせます。
カラム型データ形式
カラム型エンジンは、列の内容および実行されるクエリ オペレーションの種類から学習することにより、各列のデータ形式とメタデータをインテリジェントに決定します。学習されたメタデータは、データ値の効率的なエンコードとクエリ処理の高速化に使用されます。たとえばフィルタで使われる列が、わずかな数の個別値を含む文字列である場合、カラム型エンジンは個別値のリストをメタデータとして生成することを決定する場合があります。これを使用すれば、等式フィルタも範囲ベースフィルタも高速化するでしょう。別の例として、カラム型エンジンは(特定の行範囲における)日付列の最小値と最大値をメタデータとして保持する場合があります。これを使用すれば、特定のフィルタ処理でその行範囲をスキップできる可能性があります。加えて、カラム型エンジンは圧縮技術を使用してメモリ使用を効率化し、クエリ処理を高速化することもできます。
クエリの高速化
カラム型エンジンはクエリを変換して、列とそのメタデータに対する一連のオペレーションに分けます。標準的なケースでは、最初にメタデータを検索することで、列値の配列に対する最も効率的なオペレーションの種類を決定します。このような列値に対するオペレーション(ベクトル化オペレーションと呼ばれる)は、最新型 CPU で利用可能なハードウェア加速ベクトル化(SIMD)命令を使って実行されるように設計されています。
またカラム型エンジンは、テーブル スキャンの結果を完全に実体化することなく、テーブル スキャン オペレーションを効率的に実行できます。たとえば、テーブル スキャン後に集計オペレーションを実行する必要がある場合、フィルタの評価結果を利用して、該当する列に対するベクトル化集計オペレーションを直接実行できます。結合オペレーションは、選択性に応じてブルーム フィルタを使用して透過的に高速化されます。この最適化では、ベクトル化フィルタリングの能力を利用して、結合オペレーションで処理される行数が削減されます。
このような最適化が単純なクエリにどのように適用されるかを見てみましょう。ここでは、スタースキーマ ベンチマークと同様のスキーマに基づいてテーブル スキャンを行います。このクエリは売上のリストをスキャンして、出荷モードと日付でフィルタリングします。下の図は、2 つのフィルタを使用するテーブル スキャンがどのように実行されるかを示しています。フィルタ lo_shipmode = ‘MAIL’ では、カラム型エンジンがまず列のメタデータを検査して、値 ‘MAIL’ がこのデータセット内に存在するかどうかを調べます。‘MAIL’ が存在する場合、カラム型エンジンは処理を進めて SIMD 命令を使って検索します。行を渡した結果のビットマップが、次のフィルタからの結果セットを使ってさらにフィルタリングされます。
一方、値 ‘MAIL’ が列メタデータに存在しない場合、カラム型エンジンは多数の値の検索をスキップできます。同様に、カラム型エンジンは lo_quantity 列上の最小 / 最大メタデータを使用し、その列に対する範囲フィルタに基づいて一部の行をスキップすることもできます。
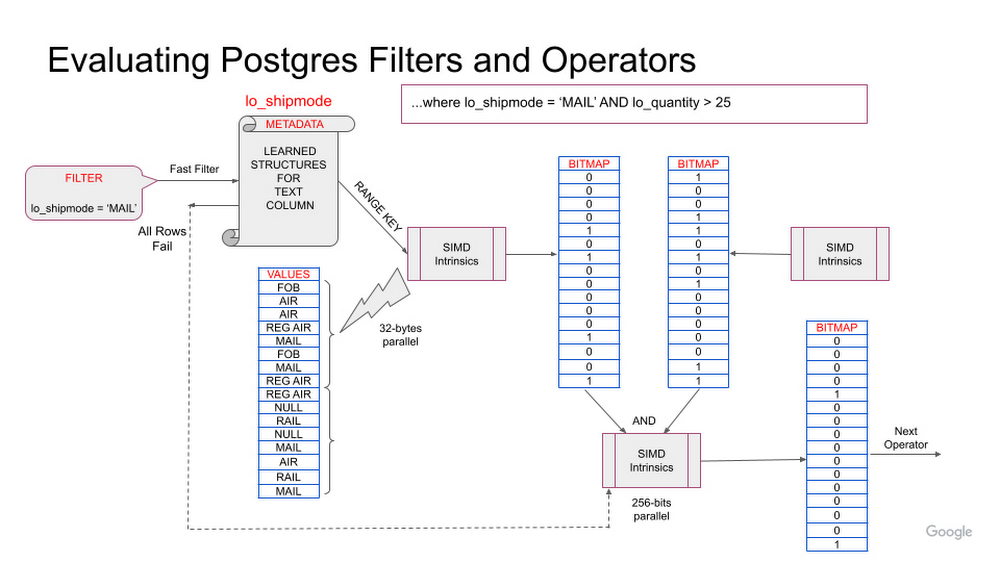
図 1: 2 つのフィルタを使用したテーブル スキャンを伴うクエリ オペレーションの例
自動的でインテリジェントなデータ取り込み
AlloyDB は、ワークロードが大きく変動してワークロード特性が時間とともに変化するような場合の自動化を念頭に設計されています。AlloyDB は機械学習(ML)技術と分析モデルを使用して、カラム型形式での保管に最も適したテーブル / 列をインテリジェントに選択します。このデータをメモリ内に自動的に維持するメカニズムもあります。また、列内の値とそれに対して実行されるクエリ オペレーションに基づき、カラム型データ表現に最も適した形式、および各列に最も役立つと予想されるメタデータを決定します。これにより、エンドユーザーはクエリの詳細を評価することなくカラム型技術をすぐに利用できます。言い換えると、クエリパターンが変化しても、カラム型エンジンはパフォーマンスを最適化し続けます。
クエリプランの実行
データが初めてメモリに読み込まれた後、AlloyDB はそのデータの変更をモニタリングして、それが自動的に更新されるようにします。データの変更状況および実行されるクエリ オペレーションに応じて、カラム型データに対してのみクエリを実行するのが適切な場合も、行指向データに対してのみクエリを実行するのが適切な場合も、あるいは 2 つの混合が適切な場合もあります。AlloyDB のクエリ プランナーは、クエリプラン内の各ノードに最適な実行モードを自動的に選択するコスト計算モデルを使用します。
クエリのパフォーマンス
一般的に、カラム型エンジンは分析クエリのパフォーマンスを大幅に向上させると予想されますが、向上の度合いは具体的なクエリによって異なります。 カラム型エンジンから最大の恩恵を受けるクエリは、「広い」テーブル(多くの分析ユースケースで一般的な、膨大な列数を持つテーブル)のほんのわずかな列にしかアクセスしない、選択的フィルタを使用するクエリです。選択的結合(特に小さなテーブルの結合)もまた、効率的なブルーム フィルタリングを通してカラム型エンジンから大きな恩恵を受けます。Google はこの分野の革新を継続し、カラム型エンジンがさまざまなクエリパターンのパフォーマンスに与える効果の幅を広げることを目指して、新しい機能を構築しようとしています。
上記の要因によってパフォーマンス向上の度合いがどのように異なるかを示す目的で、いくつかのサンプルクエリに対してカラム型エンジンを使用した場合 / 使用しない場合のパフォーマンスを比較しました。これらのクエリは、スタースキーマ ベンチマークに基づいており、16-vCPU AlloyDB インスタンス上でスケール係数 = 10 を使って実行されました。
例 1: 特定の割引と数量に限定して、売上から合計収益を取得します。このクエリには、選択性の高い(0.18%)フィルタおよび 1 つの列の集計が含まれています
117 倍の向上
例 2: 出荷モードごとに、割引と数量を特定範囲に限定して売上から合計収益を取得します。このクエリには、選択性が低い(13%)フィルタ、グループ化、および 1 つの列の集計が含まれています。
19 倍の向上
例 3: 割引と数量を特定範囲に限定して、特定の年における売上から合計収益を取得します。このクエリには、選択的結合(結合選択性 = 14%)が含まれ、カラム型エンジンはブルーム フィルタを使ってそれにアクセスします。
8 倍の向上
例 4: 割引と数量を特定範囲に限定して、特定の年またはそれ以前の売上から合計収益を取得します。このクエリには、選択性が非常に低い結合(結合選択性 = 90%)が含まれています。
2.6 倍の改善
これらの例で示したものと同じ結果が実際に得られるとは限りません。データセット、データベース構成、および実行されるクエリによって結果が変わる可能性があります。
クエリプランの例
カラム型エンジンを使って実行されるクエリのプランには追加的な統計情報が示されます。これは、クエリ実行を高速化するために起動されたさまざまなカラム型最適化を特定するのに役立ちます。
例 1 のクエリのプランの主要部分:
クエリプラン ノードについて:
Custom Scan: このノードは、列ストアにフィルタを適用するカラム型スキャンノードです。カラム型フィルタによって削除された 19959121 行と、カラム型エンジンによって集計された 21216 行が示されています。
Seq Scan: このノードは従来型の Postgres 行ストア シーケンシャル スキャンノードです。これは、クエリ プランナーが(このケースでは使用されなかった)ハイブリッド実行モードの使用を決定した場合にのみ呼び出されます。
Append: このノードは、カラム型スキャンノード(Custom Scan)からの結果と行ストア シーケンシャル スキャンノードからの結果を結合します。
まとめ
Google のパフォーマンス テストに基づくと、Google のカラム型エンジンを使用すれば従来型の PostgreSQL エンジンに比べて最大 100 倍も速く分析クエリを実行できます。このクエリ処理技術を使用し、運用データベースに対して直接、分析およびレポーティングを実行することにより、リアルタイム分析情報が得られます。ML を活用した自動データ取り込み / 管理機能を持つカラム型エンジンは、インスタンスごとに完全に透過的に、また最小限の管理オーバーヘッドでアプリケーションに合わせて自動的に最適化し、斬新な使いやすさときめ細かなパフォーマンスを提供します。
cloud.google.com/alloydb にアクセスして、ぜひ AlloyDB をお試しください。
この投稿と今後の投稿で紹介する AlloyDB の技術革新は、Google のエンジニアリング チームの多大な貢献により実現されました。
- AlloyDB for PostgreSQL 担当エンジニアリング ディレクター Sheshadri Ranganath

