Spanner カラム型エンジン: 運用データの次世代分析を強化
Jagan R. Athreya
Group Product Manager
Alan Jin
Software Engineer
※この投稿は米国時間 2025 年 8 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
長年にわたり、組織はオンライン トランザクション処理(OLTP)と分析クエリ処理のワークロードの違いに悩まされてきました。Spanner などの OLTP システムは、大量の低レイテンシ トランザクション向けに最適化されており、個々のレコードへのアクセスに効率的な行指向のストレージを使用します。一方、分析ワークロードでは、大規模なデータセット全体にわたる迅速な集計とスキャンが必要です。これらのタスクは従来、カラム型ストレージとトランザクション システムからの受信データ パイプラインを使用する個別のデータ ウェアハウスによって処理されてきました。OLTP ワークフローと分析ワークフローを分離すると、定期的なデータ転送が必要になるため、データが古くなったり、ETL パイプラインが複雑になったり、運用上のオーバーヘッドが発生したりすることがよくあります。
そこでこのたび、Spanner カラム型エンジンを発表いたします。これにより、Spanner データベースで直接新しい分析機能を利用できるようになります。AlloyDB のカラム型エンジンが PostgreSQL の分析を強化したように、Spanner の新しいカラム型エンジンでは、Spanner のグローバルな整合性、高可用性、強力なトランザクション保証を維持しながら、膨大な量の運用データをリアルタイムで分析できます。トランザクション ワークロードに影響を与えることもありません。
Spanner のカラム型エンジンの機能により、Verisoul.ai などの組織は、大量のトランザクション システムと高速分析を組み合わせる際に通常発生するデータサイロの問題を解消しています。「不正行為をリアルタイムで検出することは、私たちが行っていることの半分にすぎません。お客様に『なぜ』不正行為が起こったのかを示すことで、お客様はより迅速に行動し、信頼を測定可能な ROI に変えることができます」と、偽のユーザーと不正行為を阻止する ML プラットフォームである Verisoul.ai の創業者である Raine Scott 氏と Niel Ketkar 氏は述べています。「Spanner の新しいカラム型エンジンにより、高速なトランザクション書き込みと豊富な分析を 1 か所で実行できます。データのコピーやレプリケーションの遅延がなくなるため、お客様は即座に回答を得られます。」
カラム型ストレージとベクトル化実行
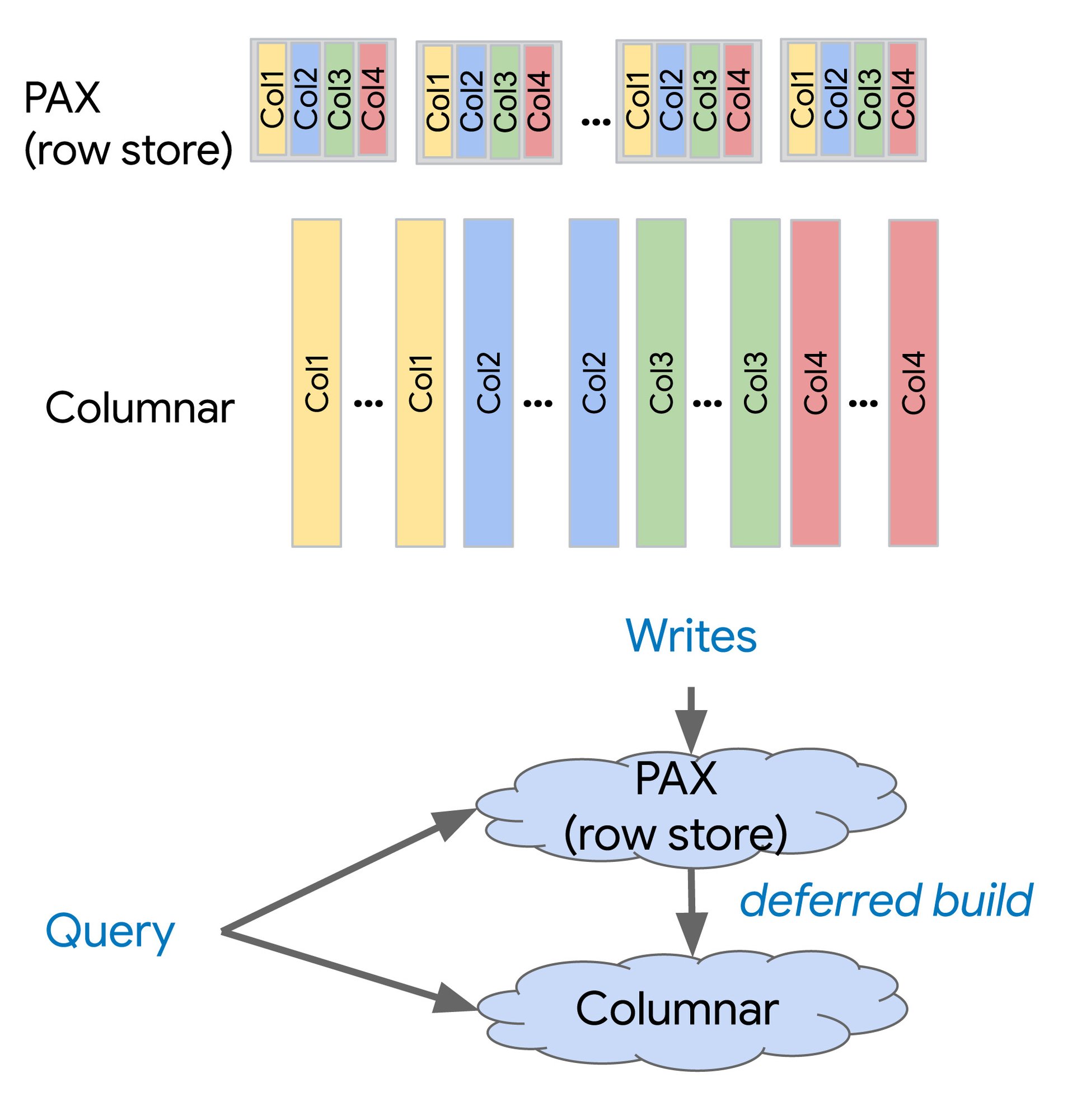
図: Spanner カラム型エンジンのアーキテクチャ
Spanner カラム型エンジンの核となるのは、カラム型ストレージとベクトル化されたクエリ実行を組み合わせた革新的なアーキテクチャです。
Spanner のカラム型ストレージ: ハイブリッド アーキテクチャ
従来の行指向ストレージでは、行全体が連続して保存されますが、カラム型ストレージでは、データが列ごとに保存されます。カラム型ストレージには次のようなメリットがあります。
-
I/O の削減: 分析クエリは、一度にアクセスする列が少ないことがよくあります。カラム型ストレージでは、ディスクから読み取る必要があるのは関連する列のみであるため、I/O オペレーションが大幅に削減されます。
-
圧縮率の向上: 通常、1 つの列内のデータは同じデータ型であり、多くの場合、同様のストレージ パターンを示すため、圧縮率が大幅に向上します。つまり、より多くのデータをメモリに格納でき、読み取る必要があるバイト数が少なくなります。
-
効率的なスキャン: 列をスキャンするときに、連続する値をまとめて処理できるため、データ処理がより効率的になります。
Spanner カラム型エンジンは、既存の行指向ストレージにカラム形式を統合します。この統合されたトランザクション処理と分析処理の設計により、Spanner は OLTP パフォーマンスを維持しながら、ライブ運用データに対する分析クエリを最大 200 倍高速化できます。
ベクトル化実行: クエリを大幅に加速
カラム型ストレージを補完するために、カラム型エンジンは Spanner のベクトル化実行機能を利用します。従来のクエリエンジンはデータをタプル単位(行単位)で処理しますが、ベクトル化エンジンはデータを複数の行のバッチ(ベクトル)で処理します。このアプローチにより、以下を実現することで CPU 使用率が大幅に向上します。
-
関数呼び出しのオーバーヘッドの削減: ベクトル化エンジンでは、個々の行ごとに関数を呼び出すのではなく、バッチ全体に対して関数を 1 回呼び出すだけなので、オーバーヘッドが大幅に削減されます。
-
最適化されたメモリ アクセス: ベクトル化された処理では、キャッシュ フレンドリーなメモリ アクセス パターンになることが多く、パフォーマンスがさらに向上します。
カラム型ストレージとベクトル化実行を組み合わせることで、Spanner での分析クエリを桁違いに高速化し、グローバル規模のデータに関するリアルタイムの分析情報を得ることができます。
BigQuery でさらに向上: 連携クエリの高速化
Spanner のカラム型エンジンは、Google のデータクラウド エコシステムとの統合をさらに一歩進め、特に Spanner と BigQuery の統合を強化します。データ ウェアハウジングと分析に BigQuery を活用している企業にとって、クエリを Spanner に直接連携させることは常に価値のある機能です。Spanner のカラム型エンジンにより、オペレーション データの分析情報をより迅速に提供できるようになることで、この統合がさらに強力になります。
Data Boost は、分析ワークロード向けのフルマネージドで弾力的にスケーラブルな Spanner のコンピューティング サービスであり、この高速化を実現する最前線にあります。BigQuery が Spanner に対して連携クエリを発行し、そのクエリがカラム型スキャンとベクトル化実行の利点を活用できる場合、Data Boost は Spanner のカラム型エンジンを自動的に利用します。これには、次のような利点があります。
-
分析情報の迅速な取得: Spanner データを対象とする BigQuery から開始された複雑な分析クエリが大幅に高速化され、ほぼリアルタイムの運用データがより広範な分析環境に取り込まれます。
-
OLTP への影響を軽減: Data Boost は、分析ワークロードがプライマリ Spanner コンピューティング リソースからオフロードされるように支援し、トランザクション処理への影響を防止します。
-
データ アーキテクチャの簡素化: 複雑な ETL パイプラインでデータを複製する必要がなく、Spanner のトランザクション整合性と BigQuery の分析能力という両方のメリットを得られます。
この統合により、データ アナリストやデータ サイエンティストは、Spanner のライブ運用データを BigQuery の他のデータセットと組み合わせて、より豊富でタイムリーな分析情報の取得と意思決定を実現できます。
カラム型エンジンの活用: 分析クエリの高速化
Spanner のカラム型エンジンで大幅な高速化が期待できるクエリの例をいくつか見てみましょう。分析ワークロードやグラフ ワークロードで一般的なこれらのタイプのクエリは、カラム型スキャンとベクトル化された処理のメリットを享受できます。
シナリオ: 大規模な e コマース データベースを前提とします。デモ用に、TPC-H ベンチマークと同じスキーマを使用します。
クエリ 1: 特定の年の割引が適用された出荷による収益
SQL
高速化: このクエリは、lineitem テーブルから l_shipdate、l_extendedprice、l_discount、l_quantity の列のみをスキャンすることで大きなメリットが得られます。ベクトル化実行では、日付、割引、数量のフィルタが迅速に適用され、条件を満たす行が特定されます。
クエリ 2: 割引対象外のアイテムの合計数量
SQL
高速化: このクエリは、lineitem テーブルから l_discount 列と l_quantity 列のみをスキャンすることで大きなメリットが得られます。ベクトル化実行により、等価フィルタ(l_discount = 0)が迅速に適用され、一致する行が特定されます。
クエリ 3: 特定の税率区分の商品数と割引額の範囲
SQL
高速化: このクエリは、lineitem テーブルから l_tax 列と l_discount 列のみをスキャンすることで大きなメリットが得られます。ベクトル化実行では、l_tax 列に IN フィルタが迅速に適用され、一致するすべての行が特定されます。
クエリ 4: Spanner Graph を使用してグラフ内のつながりが最も多い N を見つけるために、友達関係をスキャンする
GQL
高速化: このクエリは、サブグラフをスキャンし、グラフから関連する列のみを読み込むことで、大きなメリットが得られます。
クエリ 5: K 近傍法によるベクトル類似性検索を実行して、意味的に最も類似したエンベディング上位 10 件を取得する(再現率 100%)
GQL
高速化: このクエリは、連続して保存されたベクトル エンベディングをスキャンし、テーブルから関連する列のみを読み込むことで、大きなメリットが得られます。
今すぐ Spanner のカラム型エンジンを使い始めましょう。
Spanner のカラム型エンジンは、Spanner の基本的な強みを損なうことなく、運用データからより迅速かつ詳細なリアルタイムの分析情報を引き出したいと考えている企業向けに設計されています。これにより、デベロッパーとデータ アナリストの両方に新たな可能性が切り開かれることをとても嬉しく思います。Spanner のカラム型エンジンをぜひ真っ先にお試しください。Spanner カラム型エンジンのプレビュー版へのアクセスをリクエストするには、今すぐご登録ください。皆様がどのようなものを構築されるか楽しみにしております。
-グループ プロダクト マネージャー、Jagan R. Athreya
-ソフトウェア エンジニア、Alan Jin

