Vodafone Hungary がデータ プラットフォームを Google Cloud に移行した方法
Google Cloud Japan Team
※この投稿は米国時間 2022 年 12 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
Vodafone は現在ハンガリーで第 2 位の規模を誇る大手電気通信事業者で、最近 UPC Hungary を買収し、従来のモバイル サービスの定額プランを拡大しました。この買収後、Vodafone Hungary は家庭やビジネスで利用する約 380 万人の登録者にサービスを提供しています。今回のストーリーでは、データと分析のプラットフォームを Google Cloud に移行したことで、Vodafone Hungary がどのようなメリットを得たかをご紹介します。
この買収をサポートするため、Vodafone Hungary は将来に対応できる IT アーキテクチャを構築するべく、多くの IT システムの変更が求められる大規模なビジネス トランスフォーメーションを実施しました。このビジネス トランスフォーメーションの目標は、ハンガリーのモバイル市場すべてのセグメントの顧客に将来性のあるサービスを提供することでした。そのなかで Vodafone の中核となる IT システムの変更から、新しいデータと分析環境を迅速かつ効果的な方法で構築するという課題が生じました。また、プロジェクト期間中に、以前のオンプレミス分析サービスからクラウドへデータを移行する必要もありました。これは、約 6 か月という非常に短い期間で既存のデータを移行し、新しいシステムからのデータとマージすることによって実現されました。プロジェクトの期間中、ソースシステムのデータ構造にいくつか変更があり、新システムの公開日までに分析側ではその変更に迅速に適応する必要がありました。
Google Cloud のデータと分析
この課題を解決するため、Vodafone Hungary は Google Cloud との連携を決めました。このパートナーシップの基礎となるのは、Data Fusion や BigQuery などの最先端の Google Cloud ソリューションを使用して、マルチベンダー プロジェクトに完全なメタデータドリブンの分析環境を実装することでした。Vodafone Hungary のデータ エンジニアリング チームは、Google Cloud ソリューションに関する十分な知識を得ることで、自社の長期的な取り組みをサポートすることができました。
このメタデータドリブンなフレームワークによって読み込まれたデータに基づいて、Vodafone Hungary は Google Cloud 上に高度なデータと分析サービスを構築しました。それが、同社をデータドリブンな企業に変貌させる後押しとなりました。
Google Cloud による支援を受けて会社全体のデータを分析することで、Vodafone は自社のビジネス像をより明確に把握するための知見を得ることができました。今では、あらゆるセグメントの顧客の全体像を把握しています。
こうしたコア KPI とともに、このデータと分析サービスを用いて構築された高度な分析とビッグデータのモデルを活用することで、以前よりもさらにパーソナライズしたサービスを顧客に提供できるようになりました。以前は、新しいデータをデータ ウェアハウスに送信するために、ビジネス申請者がプロジェクトを定義する必要がありました。新しいメタデータドリブンなフレームワークを使用すると、社内のデータ エンジニアリング チームが新しいシステムと新しいデータを非常に短時間(数日以内)でオンボーディングできるようになるため、BI 開発と意思決定プロセスを迅速化できます。
技術ソリューション
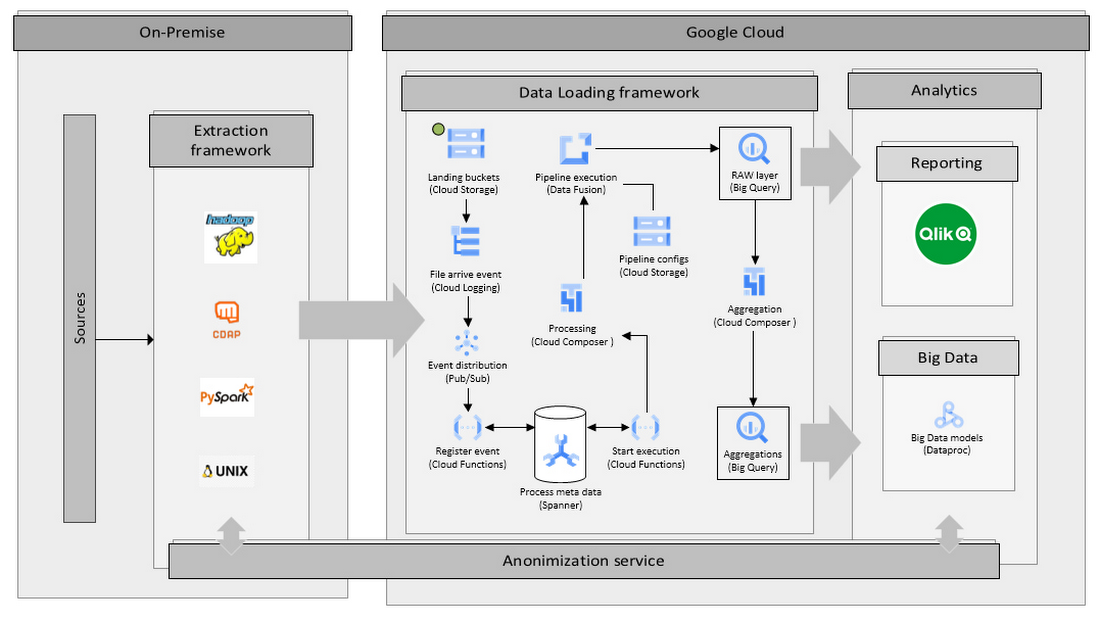
このソリューションは、ビジネスの要件を満たすためにいくつかの技術的イノベーションを取り入れています。ローカルデータ抽出ソリューションは、CDAP パイプライン、PySpark ジョブ、Unix シェル スクリプトで記述された CDAP および Hadoop テクノロジーを基盤として構築されています。このレイヤでは、データベース抽出や異なるファイル形式を含むいくつかの形式で、システムが複数のソースからデータを取得します。毎日約 1,900 件の読み込みを管理する必要があり、ほとんどのデータは 5 時間以内に到着します。そのためフレームワークは、低ピーク時に予期しないコストを発生させることなく、高負荷ピークを処理できるスケーラビリティの高いシステムである必要があります。
収集後、抽出レイヤのデータは暗号化および匿名化された形式でクラウドに送信されます。クラウド内で、抽出されたデータは Google Cloud Storage バケットに格納されます。データがファイルに到達すると、ログシンク、Pub/Sub、Cloud Functions の関数、REST API を使用して、イベントベースで Data Fusion パイプラインがトリガーされます。データの読み込みがトリガーされると、Cloud Composer がメタデータドリブンでテンプレートベースの自動生成 DAG の実行を管理します。各データ パイプラインのサイズに適応しながら、低ピーク時の費用も制御するために、Data Fusion エフェメラル クラスタを選択しました。
有限責任の原則が重要です。各コンポーネントの責任範囲は比較的限られています。つまり、Cloud Functions の関数、DAG、パイプラインには、個別のタスクを完了するために必要な最小限の責任とロジックしか含まれていません。
このデータを元のレイヤに読み込むと、履歴集計レイヤを構築するために Data Fusion でいくつかのタスクがトリガーされます。Vodafone Hungary のデータチームは、これを利用して Qlik 環境(こちらも Google Cloud 環境で実行)で独自のレポートを作成し、Vodafone 標準のビッグデータ フレームワークを使用してビッグデータと高度な分析モデルを構築できます。
このアーキテクチャの最も重要な点は、スケジュールの設定とプロセスの実行を処理するカスタマイズされたトリガー機能です。このプロセスは 1 日に 1,900 件以上の DAG をトリガーしながら、同時に 1 日あたり 1 TB 前後の匿名化データを移動させ、処理します。
その後の進展
システムが安定すると、費用と効率レベルも考慮したプロセスの最適化が始まりました。Airflow 2 と Composer 2 がリリースされると、これらのシステムを使用するようアーキテクチャがアップグレードされました。新しいバージョンにアーキテクチャをアップグレードしたことで、パフォーマンスと管理しやすさが向上しました。今後も、Vodafone Hungary は Google サポートチームからの支援を受けながら、プロセス改善のためにさまざまな方法を模索していきます。
処理のスピードと効率性アップに向けて、最近 Vodafone Hungary は制御テーブルを Google Cloud Spanner に移行し、BigQuery にはビジネスデータのみを格納するようにしました。これにより、処理機能が大幅に向上しました。
分析の領域について、Vodafone Hungary はより高度で最先端のテクノロジーへの移行を計画しています。Auto ML や Vertex AI などの Google Cloud ネイティブの機械学習ツールを使用すれば、ビッグデータ チームのパフォーマンス向上が見込めます。こうしたツールは、ターゲット キャンペーンの有効性をさらに向上させ、高度なデータ分析のメリットをもたらします。
手始めに、BigQuery の無料トライアルと BigQuery の移行評価について確認することをおすすめします。
- Vodafone データ エンジニアリング担当シニア マネージャー Gergely Szalai 氏



