BigQuery 最新情報: 時間単位のパーティショニング、テーブル ACL など
Google Cloud Japan Team
※この投稿は米国時間 2020 年 10 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud は、お客様最優先の考え方でデータ分析プロダクトの構築に投資しています。Google Cloud のエンタープライズ データ ウェアハウスである BigQuery からお客様がより多くの価値を得られるようにするための、最新の機能拡張とプロダクトの更新情報について Google Cloud のエンジニアリング チームからお知らせします。
より効率的なクエリの作成をサポートするため、BigQuery で SQL の新機能をリリースしました。新しいテーブル オペレーションを使用して、テーブルへの列の追加や内容の削除を簡単に行えるようになりました。また、新しいコマンドを使用した効率的な外部ストレージの読み取りと書き込み、新しい DATE 関数と STRING 関数の使用が可能になりました。これらの機能の詳細については、ユーザーを笑顔にする BigQuery の使いやすい SQL 新機能をご覧ください。
BigQuery に最近追加されたその他の機能と、それらを活用し、クエリの高速化、効率的なデータの整理と管理、コスト削減を行う方法については、続きをお読みください。
柔軟な時間単位を使用してパーティションを作成して高速で効率的なクエリを行う
データ戦略で重要なのは、データ ウェアハウスを高速化するための最適化と、不要なデータを検索する時間の削減です。明確なテーブル パーティショニングの定義と実装、クラスタリング戦略が出発点としておすすめです。
BigQuery でこのたび、時間単位のパーティショニングをご利用いただけるようになりました。これにより、パーティションをより細かく制御できるようになります。柔軟な時間単位(1 時間から 1 年の範囲)を使用して、時間ベースでデータを整理し、ユーザーによるデータの読み込みとクエリを最適化することができます。BigQuery の時間ベースのパーティショニングは、DATE と TIMESTAMP に加えて DATETIME データ型もサポートするようになりました。データ変換や TIMESTAMP 列の追加は必要ありません。簡単にグローバルなタイムスタンプ データを集計することができます。これらの更新により、BigQuery は同じ DATETIME データ型で異なる時間単位をサポートできるようになったので、非常に高速で効率的なクエリを柔軟に作成することが可能です。
時間単位のパーティショニングは標準 SQL DDL を使用して簡単に実装できます。たとえば、transaction_ts TIMESTAMP 列で時間単位で分割されている newtable という名前のテーブルを作成するには、TIMESTAMP_TRUNC を使用して次のような時間マークのタイムスタンプを記述することができます。
BigQuery の他のパーティショニング スキームと同様に、クエリのパフォーマンスを高速化するためにこれらの新しいパーティショニング スキームと一緒にクラスタリングを使用することができます。最大のメリットは、これらの新しいパーティショニング スキームは追加料金なしでお使いいただけるということです。料金はベースのBigQuery 料金に含まれています。これらの新しいパーティショニング スキームによりクエリ料金を下げることができ、従来のデータ ウェアハウスで使用できるパーティショニング スキームとの一致が可能になり移行が簡単になります。
時間単位のパーティショニングの実用例をデモ動画でご確認ください。また、詳細については BigQuery の ドキュメントをご覧ください。

INFORMATION_SCHEMA によるメタデータへの拡張されたアクセスの活用
Google Cloud のチームは、BigQuery データセット、テーブル、ビュー、ルーティン(ストアド プロシージャやユーザー定義関数)、スキーマ、ジョブ、スロットに関するリッチ メタデータを公開する場所と方法としてふさわしいのは、当然 BigQuery であると考えました。INFORMATION_SCHEMA ビューを使用して、データセット、テーブル、ビュー、ジョブ、予約、ストリーミング データに関するメタデータにアクセスできます。
このメタデータに関してよくある質問に対応する、簡単なコード スニペットを次に示します。
データセットに含まれるすべてのテーブルを確認するには?
このビューはどのように定義されたのですか?
INFORMATION_SCHEMA.JOBS_TIMELINE_BY_* ビューを使用して、現在実行中のジョブや完了したジョブについて過去 180 日間のタイムスライスごとにリアルタイムの BigQuery メタデータを取得することもできます。INFORMATION_SCHEMA ジョブのタイムライン ビューはリージョン化されています。そのため、次の例に示されているとおりに、クエリでリージョン修飾子を使用する必要があります。
任意の時点で何個のジョブが実行されていますか?
どのクエリが前日のスロット リソースを最も多く使用しましたか?
当然、上記のクエリを毎日実行し、結果をモニタリングするのは面倒です。そのため、BigQuery チームは新しくレポート テンプレート(詳しくは以降で説明)を作成し一般公開しました。
その他の例を参照して INFORMATION_SCHEMA の基礎を実践し、ドキュメントをご確認ください。
BigQuery のスロットとジョブの管理を効率化する
BigQuery 予約を使用している場合、各プロジェクトと各チームのスロット使用率のモニタリングは大変です。Google Cloud はこのたび、BigQuery システム テーブル レポートを発表しました。このソリューションは、BigQuery の基礎となる INFORMATION_SCHEMA ビューを利用して BigQuery 定額料金のスロットと予約状況をモニタリングできるようにすることを目的としています。これらのレポートにより、時間または日の単位でスロットと予約をモニタリングしてジョブの実行とエラーを確認することが簡単にできます。
新しいデータポータル ダッシュボード テンプレートで、これらのレポートの活用例をご確認ください。以下に例を示します。
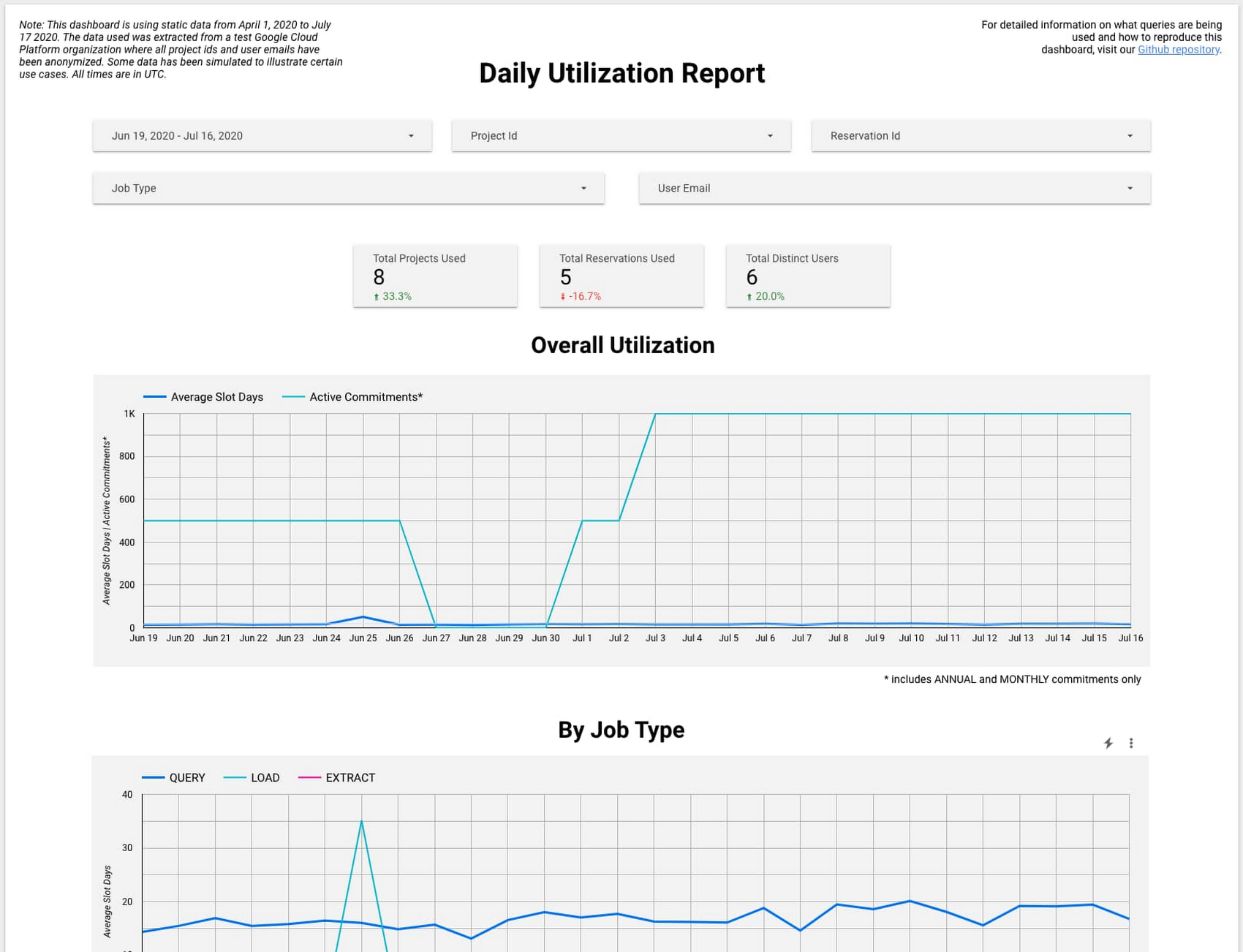
利用可能なすべての BigQuery システム テーブル レポートをご覧ください。また、Coursera では BigQuery の使用と予約の管理について詳しく学ぶことができます。
Google Cloud は、BigQuery スロットの管理を効率化することに加えて、ジョブの管理をより簡単にすることにも取り組んでいます。たとえば、1 つの簡単なステートメントでジョブを簡単にキャンセルする SQL を使えるようになりました。
プロシージャがすぐに返され、その後まもなく BigQuery によってジョブがキャンセルされます。
BigQuery ジョブを管理するすべての方法をドキュメントでご覧ください。
データ ガバナンスの進歩を活用して個々のテーブルのアクセスを管理する(列レベルの管理も近日提供予定)
今年導入したデータ クラスベース アクセス制御を強化する テーブル ACL の一般提供版をリリースし、Data Catalog に統合を追加しました。これらの新しい機能により、テーブルに個別の制御ができるようになり、Data Catalog のデータ ディクショナリでより簡単にデータの検索と共有ができるようになりました。
テーブル ACL により、特定のテーブルをクエリするためにデータセット全体にアクセスする必要がなくなりました。個々のテーブルに Identity and Access Management(IAM)ポリシーを設定するか、次の 3 つの簡単な方法のいずれかで表示することができます。
bq set-iam-policy コマンド(bq コマンドライン ツールのバージョン 2.0.50 以降)の使用
Google Cloud Console の使用
tables.setIamPolicy メソッドを呼び出す
たとえば、BigQuery データ閲覧者(roles/bigquery.dataViewer)のロールを使用すると、個々のテーブルに読み取りアクセス権を付与することが可能で、テーブルが属しているデータセットにユーザーがアクセスする必要はありません。さらに、特定のデータセットに BigQuery メタデータ閲覧者(roles/bigquery.metadataViewer)のロールまたは bigquery.tables.list 権限を付与することで、データセット内のどのテーブルにユーザーがアクセスできるかをユーザーに表示することができます。
そして、まもなく列レベルのセキュリティの一般提供が開始されます。この機能(現時点でベータ版)を使うと、次のわずか 3 ステップで列レベルでのデータアクセスを制限することができます。
1.Data Catalog を使用して、ベスト プラクティスに基づいてデータの分類とポリシータグを作成、管理します。
2.スキーマ アノテーションを使用して、アクセスを制限する列ごとにポリシータグを割り当てます。
3.Identity and Access Management(IAM)ポリシーを使用して、各ポリシータグへのアクセスを制限します。ポリシーは、ポリシータグに属する列ごとに有効です。
列レベル ACL とテーブル ACL の両方が Data Catalog の検索で表示されます。
ポリシータグ ベースの検索を使用すると、列レベル ACL が適用された特定のデータを検索できます。
Data Catalog は(データセット全体にアクセス権がない場合でも)アクセス権のあるすべてのテーブルをインデックス登録することができます。
これらの新しい機能の詳細は、テーブル ACL と列レベルのセキュリティに関するドキュメントでご覧いただけます。また、Qwiklabs の Data Catalog では実践演習も可能です。
その他の最新情報:
BigQuery Simba ODBC ドライバでは、最適化された同期 API である Jobs.Query を大多数の BI と分析クエリに活用しています。さらに、BigQuery Simba ODBC ドライバと JDBC ドライバの両方のドライバは、匿名テーブルのすべてのクエリについて高スループット読み取り API を自動的に有効にできるようになりました(必要な条件を確認してください)。これらの機能強化を有効にするには、最新の Simba ドライバ バージョンをこちらからインストールしてください。
Cloud Next OnAir ‘20 セッションにはデータ分析に関する充実した内容のセッションが含まれています。これらのセッションをチェックして、BigQuery のパフォーマンスを最大化するためのエキスパートによるベスト プラクティス、BigQuery Omni を使ったマルチクラウド環境における分析、BigQuery の管理に役立つ優れた新機能について詳しくご覧ください。
現在プレビュー中の Cloud Console UI で Data Catalog の検索とオートコンプリートをオプトインできます。この機能により、固定されたプロジェクト以外のリソースも含むすべてのリソースを検索することができます。多数のリソースがある場合、Cloud Console の全体のパフォーマンスもこのオプションを使用することで向上します。Cloud Console UI にメッセージが表示されたらこの機能を有効にしてプレビューすることができます。

BigQuery の最新情報を入手するには、リリースノートにご登録ください。Google Cloud のサンドボックスで BigQuery を無料でお試しいただけます。お気軽にお問い合わせください。
-テクニカル カリキュラム デベロッパー Jenny Palomino



