What’s happening in BigQuery: Time unit partitioning, Table ACLs and more
Jenny Palomino
Technical Curriculum Developer
At Google Cloud, we’re invested in building data analytics products with a customer-first mindset. Our engineering team is thrilled to share recent feature enhancements and product updates that we’ve made to help you get even more value out of BigQuery, Google Cloud’s enterprise data warehouse.
To support you in writing more efficient queries, BigQuery released a whole new set of SQL features. You can now easily add columns to your tables or delete the contents using new table operations, efficiently read from and write to external storage with new commands, and leverage new DATE and STRING functions. Learn more about these features in Smile everyday with new user-friendly SQL capabilities in BigQuery.
Read on to learn about other exciting recent additions to BigQuery and how they can help you speed up queries, efficiently organize and manage your data, and lower your costs.
Create partitions using flexible time units for fast and efficient queries
A core part of any data strategy is how you optimize your data warehouse for speed while reducing the amount of time spent looking at data you don’t need. Defining and implementing a clear table partitioning and clustering strategy is a great place to start.
We’re excited to announce that now you have even more granular control over your partitions with time unit partitioning available in BigQuery. Using flexible units of time (ranging from an hour to a year), you can organize time-based data to optimize how your users load and query data. BigQuery time-based partitioning now also supports the DATETIME data type, in addition to DATE and TIMESTAMP. Now you can easily aggregate global timestamp data without the need to convert data or add additional TIMESTAMP columns. With these updates, BigQuery now supports different time units on the same DATETIME data type, giving you the flexibility to write extremely fast and efficient queries.
Time unit partitioning is easily implemented using standard SQL DDL. For example, you can create a table named newtable that is hourly partitioned by the transaction_ts TIMESTAMP column using TIMESTAMP_TRUNC to delineate the timestamp at the hour mark:
As with other partitioning schemes in BigQuery, you can use clustering along with these new partitioning schemes to speed up the performance of your queries. Best part—there is no additional cost for the use of these new partitioning schemes; it's included with the base BigQuery pricing. These new partitioning schemes can help you lower query costs and allow you to match partitioning schemes available in traditional data warehouses for ease of migration.
Check out the demo video to see time unit partitioning in action, and read more in the BigQuery documentation.

Take advantage of expanded access to metadata via INFORMATION_SCHEMA
When our team was deciding where and how to expose rich metadata about BigQuery datasets, tables, views, routines (stored procedures and user-defined functions), schemas, jobs, and slots, the natural answer was BigQuery itself. You can use the INFORMATION_SCHEMA views to access metadata on datasets, tables, views, jobs, reservations, and even streaming data!
Here are some quick code snippets of how people are asking questions of this metadata:
What are all the tables in my dataset?
How was this view defined again...?
You can also use INFORMATION_SCHEMA.JOBS_TIMELINE_BY_* views to retrieve real-time BigQuery metadata by timeslice for the previous 180 days of currently running and/or completed jobs. The INFORMATION_SCHEMA jobs timeline views are regionalized, so be sure to use a region qualifier in your queries, as shown in the examples below.
How many jobs are running at any given time?
Which queries used the most slot resources in the last day?
Of course, running the above query every day and monitoring the results can be tedious, which is why the BigQuery team created new publicly available report templates (more on that shortly).
Practice some INFORMATION_SCHEMA basics with more examples and browse the documentation.
Streamline the management of your BigQuery slots and jobs
If you’re using BigQuery reservations, monitoring the slot usage from each of your projects and teams can be challenging. We’re excited to announce BigQuery System Tables Reports, a solution that aims to help you monitor BigQuery flat-rate slot and reservation utilization by leveraging BigQuery’s underlying INFORMATION_SCHEMA views. These reports provide easy ways to monitor your slots and reservations by hour or day and review job execution and errors.
Check out the new Data Studio dashboard template to see these reports in action. Here’s a look at one option:
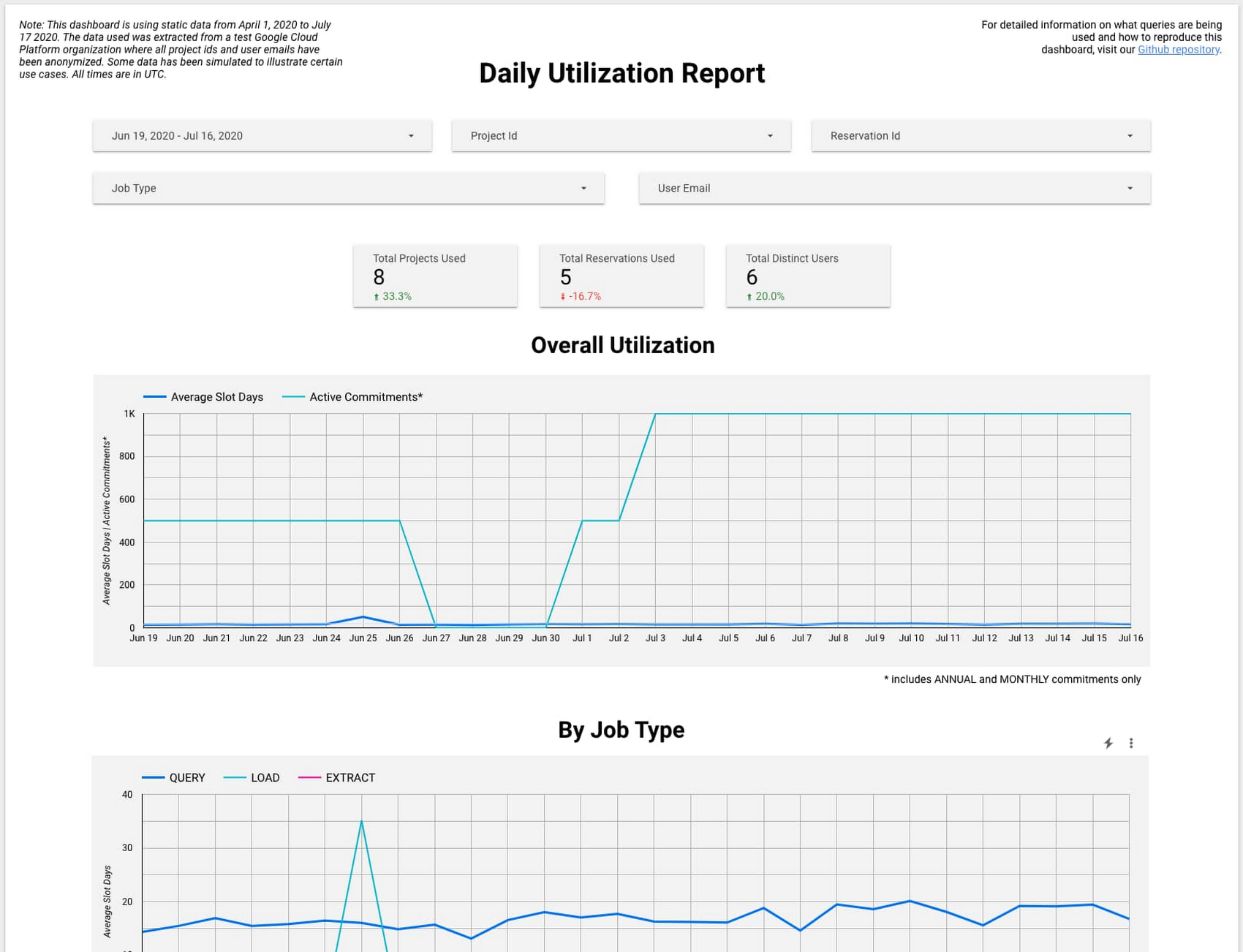
Explore all of the available BigQuery System Tables Reports, and learn more about managing BigQuery usage and reservations on Coursera.
In addition to streamlining the management of BigQuery slots, we’re also working on making it easier for you to manage your jobs. For example, you can now use SQL to easily cancel your jobs with one simple statement:
The procedure returns immediately, and BigQuery cancels the job shortly afterwards.
Review all of the ways that you can manage your BigQuery jobs in the documentation.
Leverage advances in data governance to manage access to individual tables (and columns soon!)
Building on the introduction of data class-based access controls earlier this year, we have now launched Table ACLs into GA and added integration into Data Catalog. These new features provide you with individualized control over your tables and allow you to find and share data more easily via a data dictionary in the Data Catalog.
With Table ACLs, you no longer need access to the entire dataset to query a specific table. You can now set an Identity and Access Management (IAM) policy on an individual table or view in one of three easy ways:
Using the
bq set-iam-policycommand (bqcommand-line tool version2.0.50or later)Using the Google Cloud Console
Calling the
tables.setIamPolicymethod
For example, using the role BigQuery Data Viewer (roles/bigquery.dataViewer), you can grant read access on an individual table, without the user needing access to the dataset the table belongs to. In addition, you can let users see which tables they have access to in a dataset by granting the role BigQuery Metadata Viewer (roles/bigquery.metadataViewer) or the bigquery.tables.list permission on a specific dataset.
And coming soon to GA is column-level security. With this feature (currently in beta), you will be able to restrict data access at the column level with just three steps:
Use Data Catalog to create and manage a taxonomy and policy tags for your data using best practices.
Use schema annotations to assign a policy tag to each column for which you want to control access.
Use Identity and Access Management (IAM) policies to restrict access to each policy tag. The policy will be in effect for each column belonging to the policy tag.
Both column-level and Table ACLs are exposed in Data Catalog searches.
Using policy-tag based search, you will be able to find specific data policed with column-level ACLs.
Data Catalog will also index all tables that you have access to (again, even if you don't have access to the surrounding dataset).
Learn more about these new features in the docs on Table ACLs and column-level security, and get hands-on practice with Data Catalog on Qwiklabs.
In case you missed it:
The BigQuery Simba ODBC driver now leverages the optimized, synchronous API: Jobs.Query, for the majority of BI and analytical queries. In addition, the BigQuery Simba ODBC and JDBC drivers both now auto-enable the high-throughput read API for all queries on anonymous tables (check out necessary criteria). To enable these improvements, install the latest Simba driver versions here.
Cloud Next OnAir ‘20 sessions included some great sessions on data analytics. Check them out to learn more about Best Practices from Experts to Maximize BigQuery Performance, Analytics in a Multi-Cloud World with BigQuery Omni, and Awesome New Features to Help You Manage BigQuery.
- Now in preview, the Cloud Console UI lets you opt in to search and autocomplete powered by Data Catalog. With this feature, you can search for all of your resources, even those outside your pinned projects. If you have a large number of resources, the overall performance of the Cloud Console is also improved with this option. Preview this feature by enabling it when prompted in the Cloud Console UI.

To keep up on what’s new with BigQuery, subscribe to our release notes. You can try BigQuery with no charge in our sandbox. Let us know how we can help.

