BigQuery のインデックスが列情報に対応し、クエリのパフォーマンスが飛躍的に向上
Huong Phan
Engineering Lead, BigQuery Search
HP Truong
Software Engineer, BigQuery Search
※この投稿は米国時間 2025 年 5 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery では、検索クエリやルックアップ クエリの実行時に、無関係のファイルをあらかじめ除外することで、パフォーマンスを最適化しています。ただし、クエリ パフォーマンスをさらに最適化するために、検索インデックスに列情報を追加する必要があることもあります。Google はこのたび、インデックスに列情報を追加する新機能を発表しました。これにより、BigQuery において列内で検索対象データを見つけられるようになり、検索クエリの速度が向上し、費用の削減につながります。
BigQuery は、テーブルデータを 1 つ以上の物理ファイルに配置します。各ファイルには N 行が格納されます。このデータはカラム形式で保存されます。つまり、列ごとに専用のファイル ブロックがあります。詳しくは、BigQuery のストレージの仕組みに関するブログ記事をご覧ください。デフォルトの検索インデックスはファイルレベルです。つまり、データトークンから、そのデータトークンを含む全ファイルへのマッピングが維持されます。この仕組みにより、クエリ実行時にスキャン対象を関連ファイルのみに絞ることができ、検索空間を減らせます。このファイルレベルのインデックス方式は、検索対象のトークンが少数のファイルにのみ含まれる場合に効果的です。しかし、検索対象のトークンが特定の列においては少数である一方、他の列には多く存在するため、ほとんどのファイルでトークンが確認されるケースでは、このファイルレベルの方法ではそれほど効果があがりません。
例として、Title と Content という 2 列がある TechArticles という名前の単純なテーブルに、技術記事を保存している場合を考えてみましょう。ここでは、以下のようにデータが 4 つのファイルに分散していると仮定します。

目標は、Google Cloud Logging に関する記事を検索することです。次のことに注意してください。
-
「google」、「cloud」、「logging」というトークンはすべてのファイルに含まれます。
-
これらの 3 つのトークンが「Title」列にもあるのは、1 つ目のファイルだけです。
-
つまり、3 つのトークンの組み合わせは全体的に遍在していますが、「Title」列で見ると、ごく一部のファイルに限られています。
次のような DDL ステートメントを使用して、テーブルの両方の列を対象として検索インデックスを作成してみましょう。
CREATE SEARCH INDEX myIndex ON myDataset.TechArticles(Title, Content);検索インデックスに、データトークンとそれを含むデータファイルとのマッピングが、列情報なしで保存されます。インデックスは次のようになります(ここでは、「google」、「cloud」、「logging」の 3 つのトークンのみを抜き出して表示しています)。
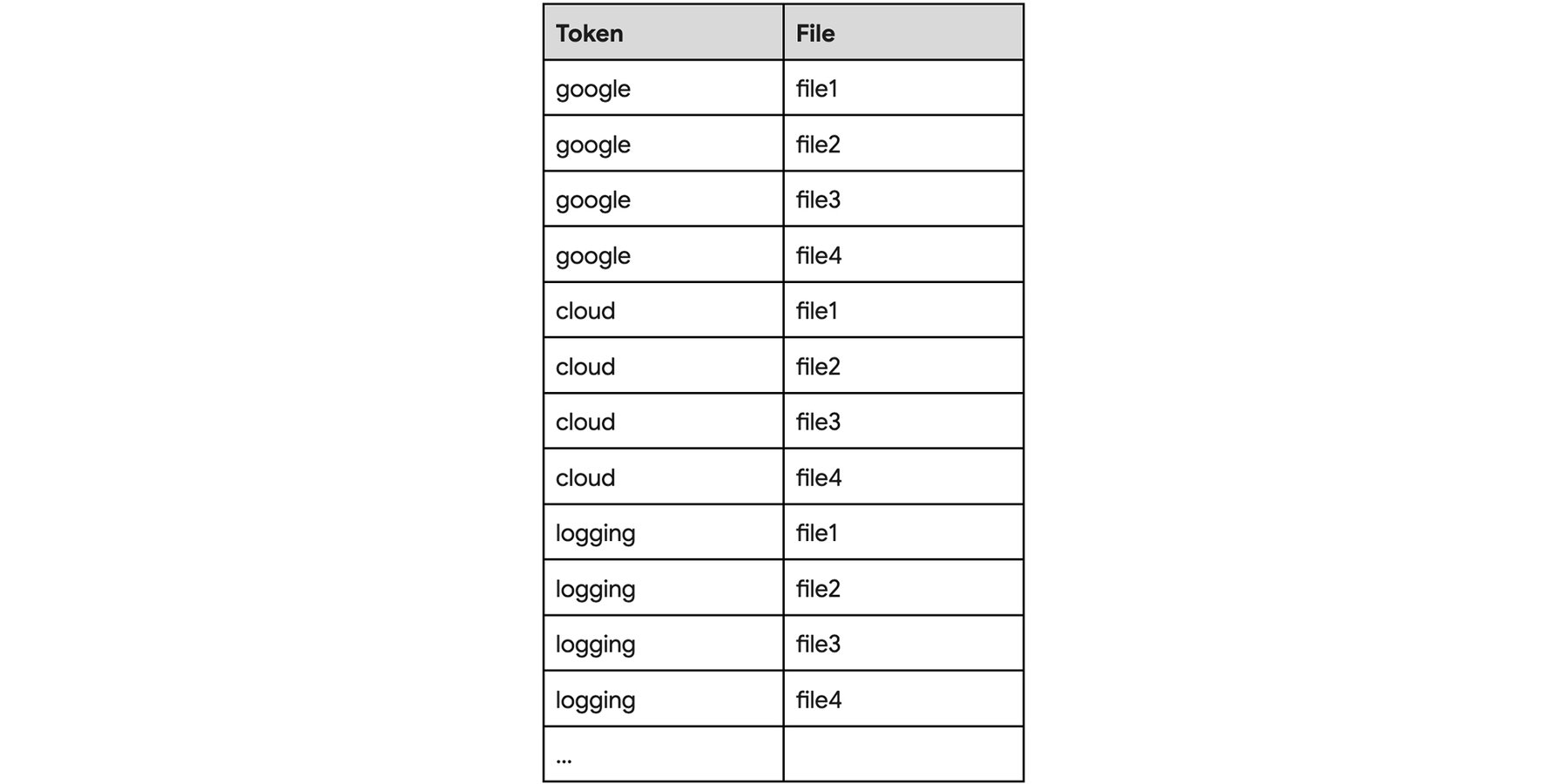
列情報のないインデックスに対して、通常のクエリ SELECT * FROM TechArticles WHERE SEARCH(Title, "Google Cloud Logging") を実行すると、4 つのファイルすべてをスキャンすることになり、不要な処理とレイテンシが生じます。
インデックスに列情報を含める
上記の問題に対応するため、BigQuery の新たなパブリック プレビュー機能として、インデックスに列情報を追加できるようになりました。これにより、検索トークンがすべてのファイルに遍在する場合でも、列内で検索対象データを見つけることが可能となります。
前の例に戻りましょう。次のように、粒度(granularity)として COLUMN(列)を指定し、インデックスを作成します。
CREATE SEARCH INDEX myIndex ON myDataset.TechArticles(Title, Content)
OPTIONS (default_index_column_granularity = 'COLUMN');これで、各データトークンの列情報がインデックスに格納されます。インデックスは次のようになります。
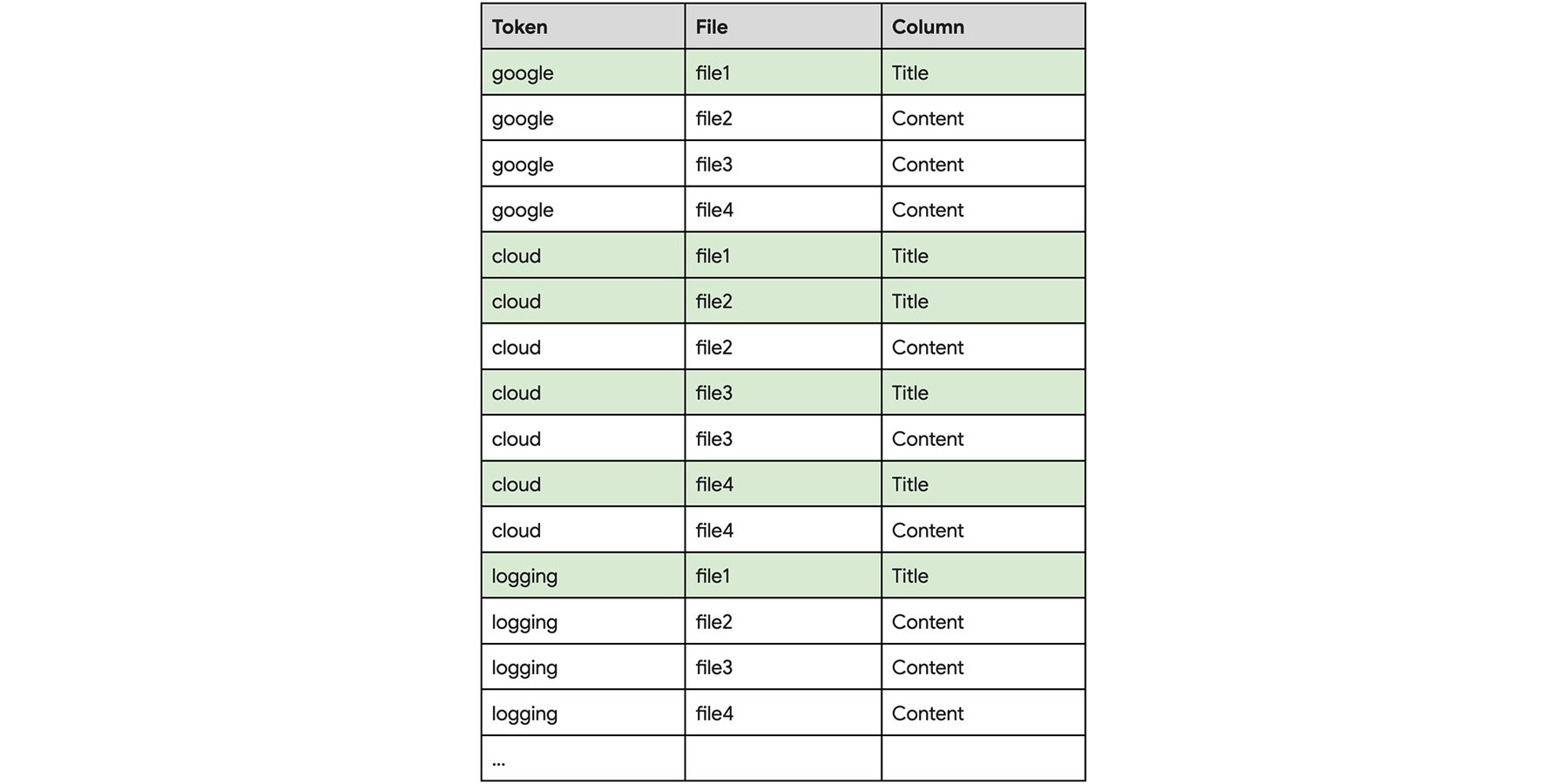
では、この列情報を含むインデックスに対して、上記と同じクエリ SELECT * FROM TechArticles WHERE SEARCH(Title, "Google Cloud Logging") を実行してみましょう。今度は、以下のすべてを満たす file1 のみがスキャンされるようになります。
-
Token='google' AND Column='Title' を満たすファイル(file1)
-
Token='cloud' AND Column='Title' を満たすファイル(file1、file2、file3、file4)
-
Token'='logging' AND Column='Title' を満たすファイル(file1)
パフォーマンスの改善効果を示すベンチマーク結果
Google 社内のテスト プロジェクトから、Google Cloud Logging データを含む 1 TB のテーブルを使って、次のクエリのパフォーマンスを測定しました。
SELECT COUNT(*)
FROM `dataset.log_1T`
WHERE SEARCH((logName, trace, labels, metadata), 'appengine');このベンチマーク用クエリに含まれるトークン「appengine」は、クエリのフィルタリングに使われる列にはほとんど含まれませんが、他の列では頻出します。以下に示すように、デフォルトの検索インデックスだけでも、検索空間が大幅に削減され、実行時間が半減するとともに、処理対象のバイト数とスロットの使用量が減りました。インデックスに列情報を追加することで、さらに大きな改善が見られています。

まとめると、列情報を含むインデックスには、次のような利点があります。
-
クエリのパフォーマンスの向上: インデックスに列情報を追加し、列内で検索対象データを見つけることで、クエリの実行速度が大幅に向上します。なかでも、列単位で見ると少数のファイルにしか含まれないようなトークンについては、大きな効果を発揮します。
-
費用効率の向上: 無関係のファイルをあらかじめ除外することで、処理が必要なバイト数やスロット時間が減り、費用効率が向上します。
この方法は、検索対象のトークンが特定の列では少数で、その他の列では多数ある場合に、特に効果的です。また、特定の列に基づいてデータをフィルタリングまたは集計することが多いような場合にも適しています。
ベスト プラクティスと使い方
BigQuery のインデックスに列情報を追加できるようになったことは大きな進歩であり、これにより、クエリのパフォーマンスおよび費用効率の向上が期待できます。
最良の結果を得るために、次のベスト プラクティスを参考にしてください。
-
影響の大きい列を特定: クエリパターンを分析して、フィルタや集計で頻繁に使用される列を特定します。このような列がある場合は、インデックス作成時に粒度として列を指定することで効果が得られる可能性があります。
-
パフォーマンスをモニタリング: クエリのパフォーマンスを継続的にモニタリングし、必要に応じてインデックス方法を調整します。
-
インデックス作成およびストレージの費用を考慮する: インデックスに列情報を追加すると、クエリのパフォーマンスは向上しますが、インデックス作成およびストレージの費用が増加する可能性があることにご注意ください。
利用を開始するには、インデックス作成時に列を粒度として指定するだけです。詳細については、CREATE SEARCH INDEX DDL ドキュメントをご覧ください。
-BigQuery 検索担当エンジニアリング リード、Huong Phan
-BigQuery 検索担当ソフトウェア エンジニア、HP Truong


