データのサイロ化解消によって、食料廃棄と食料不足を解決
Google Cloud Japan Team
※この投稿は米国時間 2020 年 12 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
X での壮大な試みの早期段階である Project Delta のチームとして、蔓延する食料廃棄と食料不足の問題を解決するための新しい技術を模索する一方で、私たちは Kroger と Feeding America と緊密に連携し、Google Cloud を使ってデータセットの変換と分析を行いました。
このブログでは、データのサイロ化を解消するための技術的な取り組みについてご紹介します(プロジェクト全体についての詳細は、こちらの投稿をご覧ください)。伝える内容に説得力を持たせるデータにするためには、まずデータにアクセスできる状態にし、データセットを結合できるように変換してフォーマットしてから、業界の専門家によるレビューを経て、基盤となる業界特有の関係性を浮き彫りにする必要があります。
データへのアプローチ: 共有データ群に対するフローを自動化する
米国の食料システムの大部分では、いまだに紙媒体の印刷物とスプレッドシートが使用されています。このような方法でデータをキャプチャ、分析、通信することで、ビジネスの速度と規模が徐々に上がっていったのは事実ですが、まず間違いなく限界があります。異なる組織が共同作業に目を向け、膨大な量のデータをリアルタムで共有するようになったため、メールでスプレッドシートをやり取りするだけではもはや不十分です。
Kroger は Feeding America の長年のパートナーです。この 2 つの組織は、40 年にわたって互いに力を合わせてきました。小売企業による全米規模の寄付プログラムの一環として、Kroger の店舗が食品を寄付用に定期的に取り分け、Feeding America メンバーのフードバンクが食品の受け取りを調整し、食料貯蔵所をとおしてそれぞれのコミュニティに配布します。
全社を挙げた「ゼロハンガー、ゼロウェイスト」(飢餓ゼロ、廃棄ゼロ)イニシアチブの一環として、Kroger は寄付と廃棄に関する膨大なデータベースをさらに有効活用したいと考えていました。2017 年、同社は業界でいち早く、2025 年までに 30 億食の寄附を行うと公表し、全米で 2,700 を超えるすべての店舗で、寄付を実行に移す機会をできるだけ多く見つけようとしていました。そのためには、店舗データに加え、Kroger の寄付パターンに関わるフードバンク パートナーの食料チャリティ データについてのより深いパターンを見い出す必要がありました。
データのサイロ化解消における初の小売企業パートナーとして、Kroger は日々のシュリンク データの共有を提案しました。シュリンクとは、欠損や損傷などの原因によって発生する、食料品店の在庫の損失です。顧客に向けて販売されないすべての商品はシュリンクとわかるように印が付けられ、寄付や動物の餌、堆肥、埋め立て処分用として取り分けられます。損失分のスキャンデータは、正式にログ記録されたシュリンクのサブセットを表します。Kroger はこの情報を社内の複数の部門で広く活用していますが、2 つの外部パートナーとの共同作業は今回が初めてでした。
Kroger のゼロハンガー ゼロウェイスト リーダーシップ チームは、同社のビジネス インテリジェンス チームと IT チームと緊密に連携し、ハイブリッド マルチクラウド システムを主導しました。X チームに日々のデータ スナップショットを提供するうえで組織的、技術的に最も簡単な方法は、20 ある各営業店部門のデータファイルを添付したメールが夜間に送信されるように自動化することでした。
受信データの処理
データファイルが含まれているこれらのメールを受信したチームには、データ整形と分析のために、データを処理して読み込む手段が必要でした。X チームが選んだのは、スケーラビリティと速度に優れた、Google Cloud のエンタープライズ データ ウェアハウスである BigQuery です。
受信メールを保持して自動的に処理するため、チームは Cloud Storage バケットを設定しました。バケットに新しいファイルが追加されると、Pub/Sub 通知によって Cloud Functions の関数がトリガーされ、BigQuery にデータが自動的に読み込まれます。ルートバケット内の処理済みファイルは、BigQuery への読み込みが成功した場合は「完了」フォルダにアーカイブされ、なんらかの理由で失敗した場合は「エラー」フォルダにアーカイブされます。
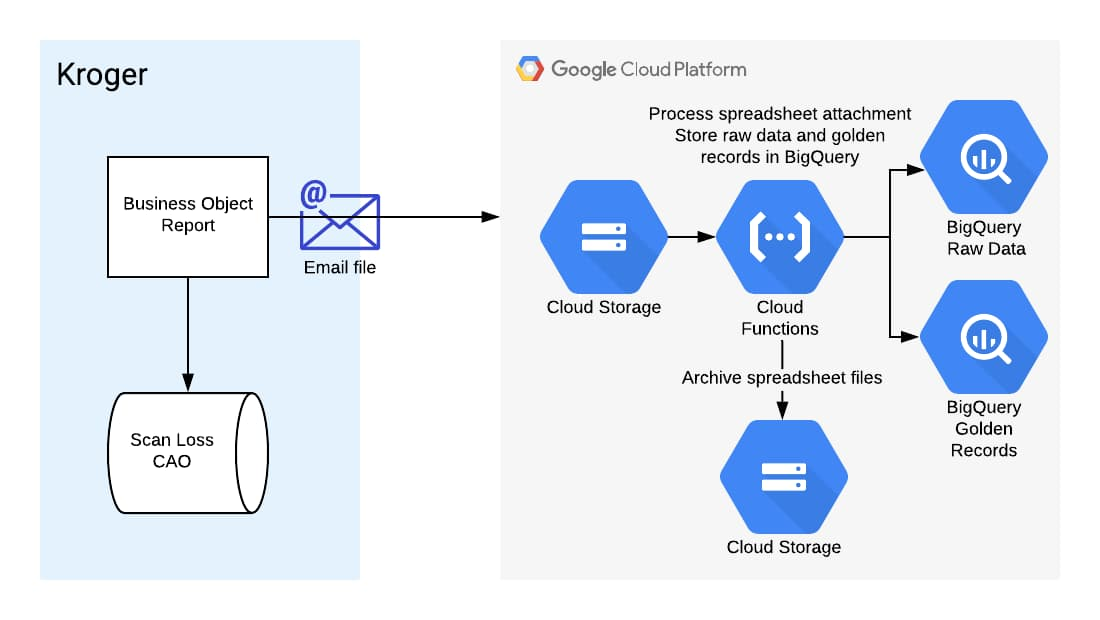
チームが実施した 2 つのステップ
トリガーと通知の設定: Pub/Sub 通知は、Cloud Console の Pub/Sub セクションから直接設定できます。適切なトピックが作成されました。次にチームは、新しいデータファイルが追加されると Pub/Sub トピックが呼び出されるように、Cloud Storage バケットを構成しました。これは、Cloud Shell のコマンドラインから行えます。
Cloud Functions の関数の設定: Pub/Sub によって、Cloud Functions の関数の呼び出しがトリガーされ、BigQuery へデータが移動されます。関数のコードは Cloud Source Repositories に格納されており、付随する SQL テンプレートを使って Python で記述されています。コードは、Pandas を使用してスプレッドシートをデータフレームに処理してから、BigQuery Python クライアント ライブラリを使用してデータフレームを BigQuery に書き込みます。
データの整合性の確保: 共通言語へのアプローチ
食品業界のシステムには、誰もが構築の基盤として活用できるオントロジーそしてセマンティックなインフラストラクチャである、標準化された共通言語が欠如していました。「食のインターネット」の取り組みを主導する、カリフォルニア大学デービス校の Matt Lange 教授は、医療制度をよく引き合いに出します。医療制度には、症状と疾病が明確に分類およびコード化され、医療セクター内でのあらゆる金銭のやり取りや運営に関するアクティビティの促進、情報提供、サポートを行う構造が整っているからです。食品業界にこのようなものは存在しません。
X チームが Feeding America と Kroger にデータ パイプラインを構築した後の最初のタスクは、食料の記述子の不一致を解消することでした。トマトに名前を付け、説明し、数量と場所を指定するにはどうすればよいでしょう?全関係者のすべてのデータセットにおいて、プラスチック容器に入ったトマトを一貫して表すにはどうすればよいでしょう?
1 つの組織内であっても同じものの呼び方が異なっていることや、違う表現方法を使っていることもあります。Feeding America は 200 もの独立したフードバンクの全米全土に広がるネットワークを抱え、そのすべてに独自の背景や慣習、互換性のない IT システムがあります。フードバンクからのデータレコードが示す意味を X チームが人として理解することはできても、これらのレコードをすべてのフードバンクで正確にリンクさせることはかなりの難題でした。たとえば、テキサスのような単純な州名でさえ、27 通りもの表記がありました。この現象はデータ全体で頻繁に見られました。たとえば、貯蔵設備では、冷蔵室を「REFR」とするフードバンクもあれば、「REFER」と表記するフードバンクもありました。
食料の所在地の正確な特定
食料を最も必要とする場所と余った食料をマッチングさせるというビジョンの下に、パートナーたちはすべてのデータレコードの位置情報の標準化を優先しました。生鮮食品の輸送には時間やコストがかかるだけでなく、温度管理が求められる場合もあるため、一定数量の食料を集荷する場所が最適な配送先の決定に直接影響を与えていました。
Feeding America メンバーのフードバンクからのレコードの多くは、スタッフ向けおよび手作業向けにわかりやすいタイトルがついていましたが、コンピュータが理解するには難しいものでした。たとえば、同じ店舗での集荷を 10 年続けている熟練ドライバーであれば「大通りの Kroger」からの寄付でも理解できますが、この記述子をデコードして、この店舗を「Store #123」と記載している、Kroger の寄付データレコードの記述と一致させる必要があります。
最初のステップは、Google Maps Platform を使用して、Kroger の 2,700 店舗の住所リストを基に一つ一つの店舗の場所 ID を特定することでした。Google Maps Platform には場所 ID があり、世界中の 2 億を超える場所を一意に特定できます。並行して、「アリゾナ、フリスコ大通りの Kroger」のようなフードバンクの場所に関する記述子も、Maps API の検索ベースのクエリ関数を使って場所 ID に変換しました。
その他にも、このデータに関する取り組みの最初のフェーズに参加しているフードバンクは、すべて合わせると 18,000 以上の食料貯蔵所を担当していました。パートナーたちは、システム全体の地理空間に潜む機会をくまなく模索することに意欲的で、これらの場所も含めることで同意しました。これによって、チームは Kroger の店舗から近くのフードバンク、そして食料貯蔵所への食料の動きを地図上で把握できるだけでなく、ネットワーク ルートを最適化する機会を幅広く探すことができました。これらの場所 ID は、共通言語の入手に役立ちました。
ただし、フードバンクのデータを操作する場合、場所の標準化が Maps API のクエリほど単純であるとは限りません。さまざまなフードバンクが同じ供給者から食料を入手していても、その提供者はそれぞれのフードバンクのデータベースで異なる表記で記載されていることが珍しくないからです。入力ミスや不完全な住所などの原因で、Maps API が誤った場所を返すことや、結果が見つからない可能性もあります。チームはこれらのエントリを調整するため、一意の ID を割り当てる前に 2 つの場所が同じであるという信頼度を判断するアルゴリズムを作成しました。この広範な取り組みによって、供給者と食料貯蔵所を含む食料のチャリティ ネットワークの全体像が実現しました。
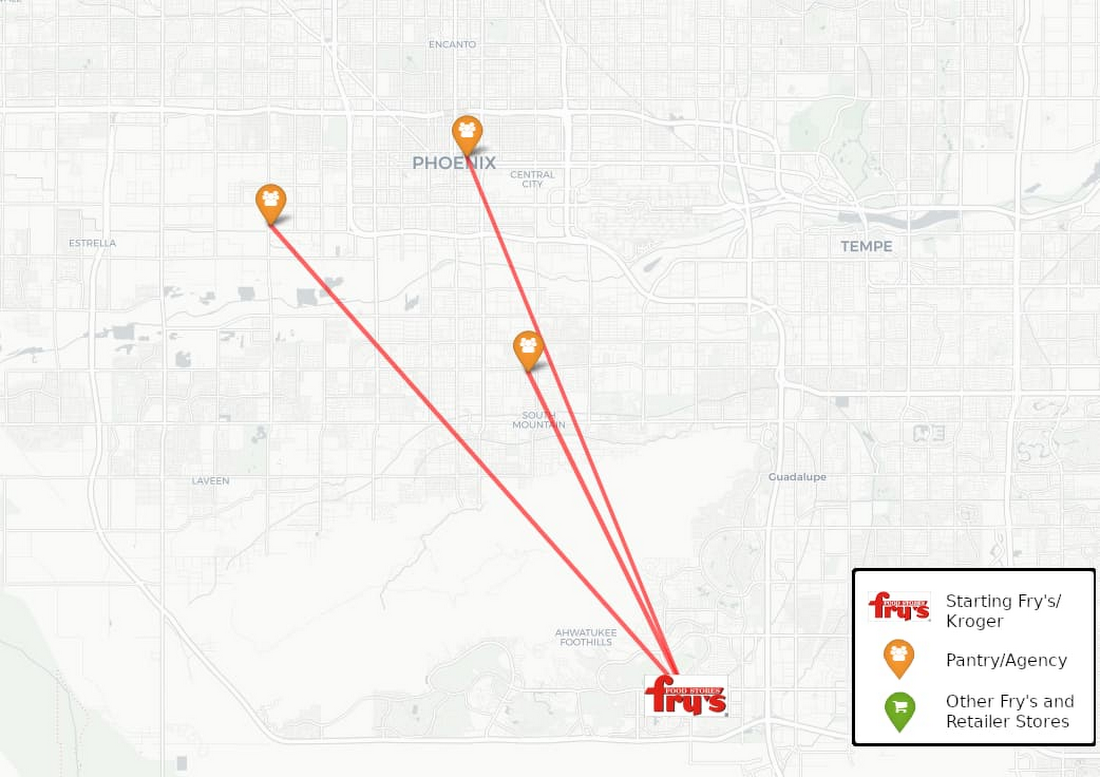
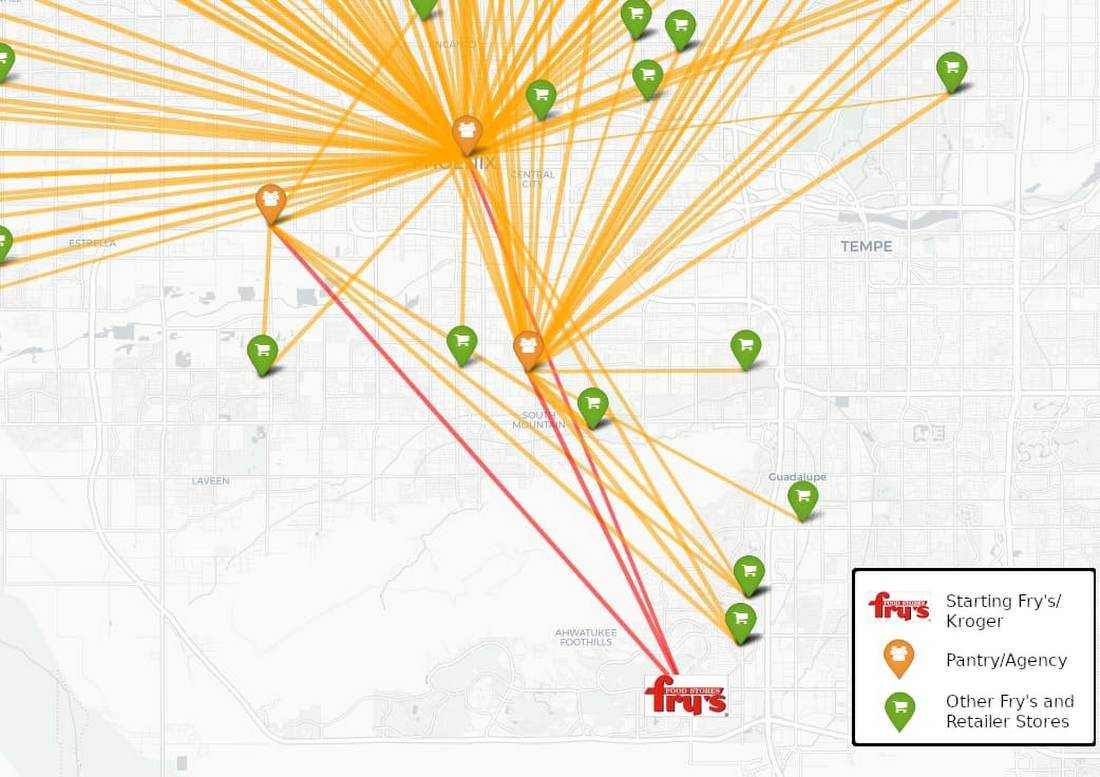
最後にパートナーたちは、食料不足が貧困、失業、人種や性別などのさまざまな人口動態変数によって形作られることを認識し、これも分析の対象とすることにしました。これらの変数を導入するため、チームは US Census API を使用して、約 600~3,000 人を含む調査地域の統計上の区域であるブロック グループをフードバンクと食料貯蔵所の場所ごとに見つけ出しました。これにより、州と国の数千ものデータセットを簡単に統合できるようになり、特定のコミュニティのニーズに潜む背景をより説得力を持って関係者に伝えられるようになりました。
地図を共有することで、人や物資を適切な場所に配置できます。食料システムにおける地図の場合、食料と付随して発生する輸送と人員をさらに効率的に活用できるようになりました。食糧システムのすべてのノードをマッピングすることは、今なお食料が豊富にあるものの均等に流通していないパンデミック禍において、かつてないほど重要性が高まっています。食料がある場所を把握することが、最初のステップです。
データの可視化: ストーリーを見い出して伝える
独立した 200 のフードバンクのネットワークの一部として、さらにそのフードバンクの一つ一つが何百もの食料貯蔵所のネットワークを持つ中、Feeding America の各メンバーは自分たちの担当範囲について説明することはできても、食料の米国中の動きをリアルタイムで追跡することはできませんでした。特定の木に集中しすぎると森の全体像を失ってしまう、というのはさまざまな業種や組織のネットワークに共通するテーマです。
チームはまず、フードバンクが食料を調達している場所を地図上で可視化しました。フードバンクは、寄付された食料を場所を問わず見つけることができ、受け取った食料の不足を補うために購入することもあります。つまり、適切な機会があれば遠方からであっても食料を入手できるということです。配送ルートの効率向上については、フードバンク間で何年も話し合いが行われてきました。しかし、それぞれのフードバンクは自分たちの状況しか把握できず、全国規模の物流ネットワークを最適化することはできません。
Feeding America と X チームは複数のフードバンクのデータのサイロ化を解消してから、協力して Looker でのフロー構築に取り組み始めました。たとえフードバンクの数が少なくても、ネットワークは非常に複雑です(下図を参照)。この可視化データは簡単に作成でき、各フードバンクが所有していたデータを表示できる一方で、森全体を見渡せます。
共同購入やルートの最適化によって、すべてのフードバンクの資金をさらに有効活用できる機会が生まれます。この図は見た目が雑然としていて、すぐに行動につながるとは言い切れません。しかし、Feeding America で全米規模のデータ ウェアハウスを構築するための賛同を集めるには、強力なツールでした。全米オフィスのリーダーやフードバンクの役員はこの可視化データを見て、その目的と潜在的なメリットをすぐに理解しました。
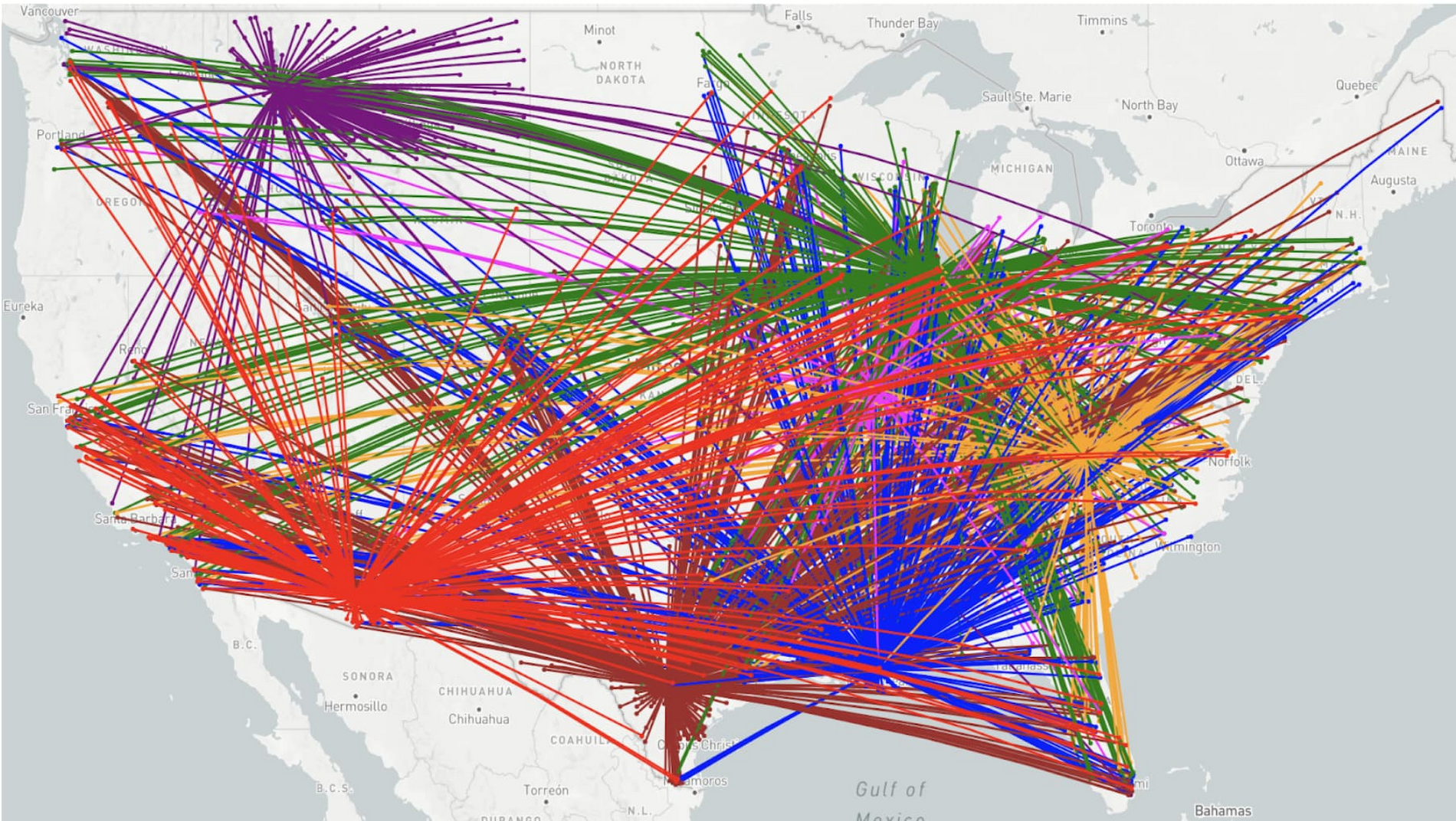
時系列に従った物理的なフローの追跡
Kroger と Feeding America がパートナーとなって以来 40 年以上が経過していますが、当初 Kroger には寄付する食料が店舗から集荷されてからどこに行くのかがわかりませんでした。数週間後に、フードバンクのパートナーから 100 パウンド回収したという確認の連絡が店舗に届くことはあっても、Kroger にはフードチェーン全体をとおして個々の食品を追跡する手段はありませんでした。
これらのフローを可視化するため、チームはまず Kroger の全店舗を、フードバンクの店舗の表記と一致させました。これにより、Kroger のデータから Store 123 の在庫レコードを追跡し、フードバンクが Store 123 から記録した寄付レコードと比較できるようになりました。
次に、フードバンクが受け取った食料の在庫全体での移動を追跡しました。とりわけ、生鮮食品や食料の寄付プログラムに関わるフードバンクは、安全に食べることができる食料であるかどうか確かめてから、効率良く輸送するためにまとめることがよくあります。たとえば、異なる店舗から収集したミックス ベジタブルの缶詰が 20 個があった場合、近くの食料貯蔵所用の食料のケースにまとめて入れられます。
この取り組みによって、Kroger は初めて自分たちの寄付がコミュニティ全体に届けられる方法を把握できるようになりました。ボランティアが Kroger の店舗で食品を回収し、寄付された品を分け、他の寄贈物とまた組み合わせて何百もの小さな食料貯蔵所に送られます。かなり小規模な寄付でさえも、コミュニティ全体から他の寄贈物と一緒に集められて大きな影響力を持つようになり、何百もの食料貯蔵所と配送地点に届けられます。

飢餓のような深刻かつ大規模な問題を解決するには、まずは新しい方法でデータを分析し、地理空間と時間の点からフローの現状を関係者に可視化することが第一歩となります。Kroger の 1 店舗だけでコミュニティ内の飢餓を解決することや、1 つの組織だけで米国中の飢餓を解決することはできません。さまざまな寄付が集まって、全体として成果を生み出すのです。データを適切に可視化することで、すでに実行に移されている取り組みに関する背景を伝え、ミッションに賛同する新たな参加者を迎えることができ、必要とされる時期と場所での行動を呼びかけることができます。
サイロ化したデータの実用化
関係者が複数いる大規模データのサイロ化を解消するにあたっては、予期せぬ展開があることを想定しておく必要があります。未加工で種類も異なるデータセットを統合し、大きな効果を引き出す分析にするまでの道のりが単純であることは、ほとんどありません。サイロからデータを取り出し、整合性をもたせ、ストーリーを伝えられるよう可視化する中でいくつかの障害を乗り越えなければなりませんが、その努力があなたのビジネスと業界を根本から良い方向に再構築するということを忘れないでください。
これらの取り組みの詳細や寄付に関する情報は、以下をご確認ください。
X および Google チームは、この記事にご協力いただいた Kroger、Feeding America、そのメンバーであるフードバンク、St. Mary's Food Bank に感謝の意を表します。
-Cloud Architect および X Alumnus 担当 Joe Intrakamhang
-データ サイエンティスト Mike Ryckman
