Pub/Sub Lite 用 Apache Spark Structured Streaming コネクタのご紹介
Google Cloud Japan Team
※この投稿は米国時間 2021 年 3 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
このたび、Pub/Sub Lite から Apache Spark にメッセージのストリームを読み込むためのオープンソース コネクタをリリースしましたのでお知らせいたします。Pub/Sub Lite はスケーラブルなマネージド メッセージング サービスで、GCP 上で Spark を使用する方に費用を大幅に抑えた取り込みソリューションを提供します。このコネクタにより、exactly-once 保証1 と 100 ミリ秒以下の処理レイテンシを備えた Structured Streaming の処理エンジンの再生可能なソースとして Pub/Sub Lite を使用できます。このコネクタは、Dataproc、Databricks、手動でインストールした Spark を含むすべての Apache Spark 2.4.X ディストリビューションで機能します。
Pub/Sub Lite とは
Pub/Sub Lite は最近リリースされた水平スケーリングが可能なメッセージング サービスで、独立したアプリケーション間で非同期にメッセージを送受信できます。パブリッシャー アプリケーションが Pub/Sub Lite トピックにメッセージをパブリッシュし、サブスクライバー アプリケーション(Apache Spark など)がトピックからメッセージを読み取ります。
Pub/Sub Lite はゾーンサービスです。インターネット上のどこからでも Pub/Sub Lite に接続できますが、パブリッシャー アプリケーションとサブスクライバー アプリケーションを接続先のトピックと同じゾーンで実行することで、ネットワークの下り(外向き)費用とレイテンシが最小限に抑えられます。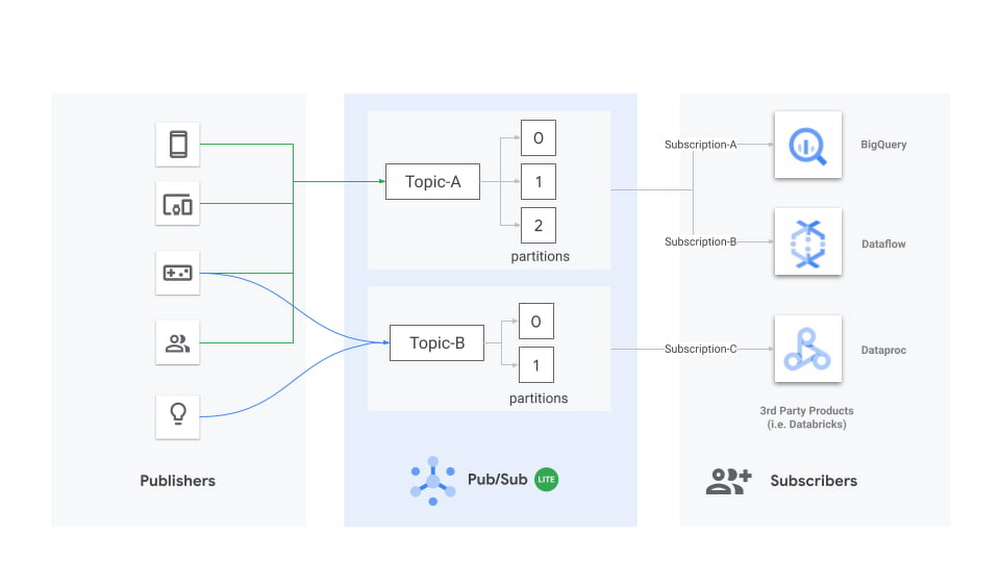
Lite トピックは、事前に設定した数のパーティションで構成されます。各パーティションは、追記専用のタイムスタンプ付きメッセージログです。各メッセージは、メッセージ本文、ユーザー構成可能な event_timestamp、Pub/Sub Lite が着信メッセージを保存するタイミングに基づいて自動的に設定される publish_timestamp など、複数のフィールドを持つオブジェクトです。トピックの容量は、ユーザーが構成したスループット容量とストレージ容量で決まります。トピックの容量を構成するには、パーティションの数、各パーティションのストレージ容量とスループット容量、メッセージの保持期間など、いくつかのプロパティを考慮する必要があります。
Pub/Sub Lite の料金モデルは、トピックでプロビジョニングされるスループット容量とストレージ容量に基づいて構成されています。トラフィックのピークに対応するのに十分な容量をプロビジョニングするように計画してください。トピックのスループット容量とストレージ容量は、トラフィックの変化に応じて後で調整できます。Pub/Sub Lite のモニタリング指標を使用すれば、容量を増やす必要がある状態を簡単に検出できます。まず、バックログが予想外に増加しているときに通知するアラート ポリシーを作成します(subscription/backlog_quota_bytes は topic/storage_quota_byte_limit を十分に下回っている必要があります)。Pub/Sub Lite サービスでは、サブスクリプションがストレージ容量を超えると、最も古いメッセージが(メッセージ保持期間に関係なく)パーティションから削除されます。また、topic/publish_quota_utilization と topic/subscribe_quota_utilization のアラートを設定して、パブリッシュとサブスクライブのスループットが上限値を十分に下回るようにする必要があります。
Pub/Sub Lite は、垂直スケーリングにより各パーティションのスループット容量を 1 MiB/秒単位で増やすことができます。トピック内のパーティションの数を増やすことも可能ですが、その場合、メッセージの順序は保持されません。コネクタ v0.1.0 では、再パーティショニング時に新しいサブスクリプションで再起動する必要がありますが、この制限はまもなく解除される予定です。今後、リリースノートを随時確認してください。Pub/Sub Lite の使用を始める際には、パーティションあたりのパブリッシュとサブスクライブのスループット容量の下限値をそれぞれ 4 MiB/秒と 8 MiB/秒に設定できるよう、パーティションの数を少しだけオーバー プロビジョニングしておくことをおすすめします。アプリケーション トラフィックが増加すると、Lite トピックを更新して、パブリッシュとサブスクライブの容量を、パーティションあたりそれぞれ 16 MiB/秒と 32 MiB/秒まで増やすことができます。パーティションのパブリッシュとサブスクライブのスループット容量は個別に調整できます。
アプリケーションが Pub/Sub Lite とやり取りする方法について詳しくは、メッセージのパブリッシュおよびサブスクライブ ガイドをご覧ください。
Pub/Sub Lite と Structured Streaming のアーキテクチャ
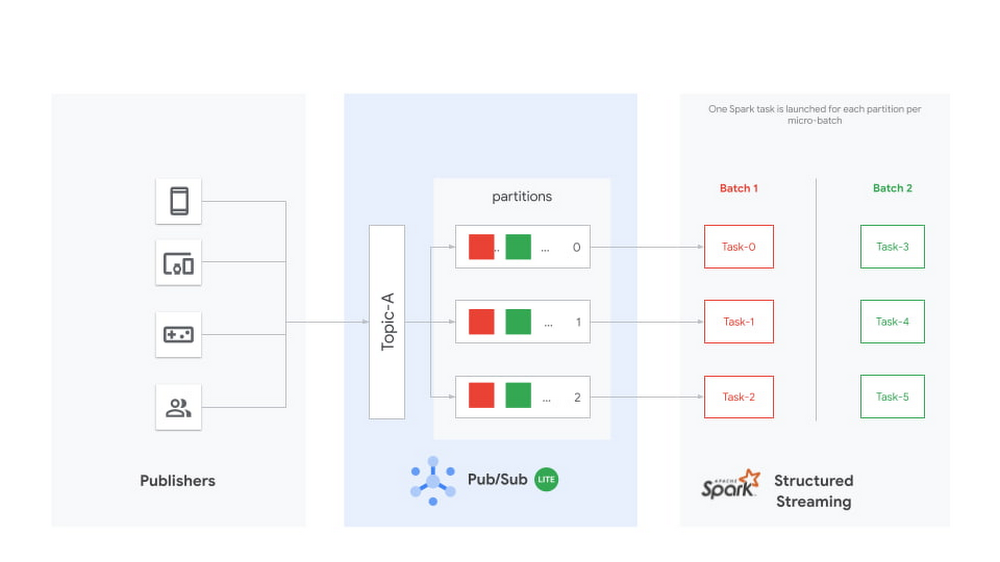
Pub/Sub Lite は、ストリーム処理システムの一部にすぎません。Pub/Sub Lite でメッセージの取り込みと配信の問題は解決されますが、これとは別にメッセージの処理に関するコンポーネントが必要になります。
Apache Spark は、バッチ処理システムとしてよく使用される、人気の高い処理フレームワークです。Spark 2.0 ではマイクロバッチ エンジンを使用したストリーミング処理が導入されました。Spark マイクロバッチ エンジンは、データ ストリームを小さなバッチジョブとして処理します。このジョブは、ストリーミング ソースから新しいデータを定期的に読み取り、それに対してクエリや計算を実行します。各マイクロバッチの期間は、トリガーを介して構成することで、それぞれが一定の間隔で実行されるようにすることができます。各 Spark ジョブのタスク数は、サブスクライブされた Pub/Sub Lite トピックのパーティション数と同じになります。各 Spark タスクがそれぞれ 1 つの Pub/Sub Lite パーティションから新しいデータを読み取り、それらを合わせてストリーミング DataFrame または Dataset を作成します。
Structure Streaming パイプラインごとに、独立した個別のサブスクリプションが必要になります。1 つのトピックに接続されたすべてのサブスクリプションで、そのトピックのサブスクライブ スループット容量が共有されることに注意してください。
このコネクタは、Spark の連続処理モード(試験運用中)もサポートしています。このモードでは、コネクタは各トピックのパーティションを Spark の長時間実行タスクにマッピングするように設計されています。ジョブが送信されると、Spark ドライバは、タスクごとにトピック内の別々のパーティションへのストリーミング接続が行われる、長時間実行タスクを作成するようにエグゼキュータに指示します。ただし、このモードはまだ本番環境で使用できる段階ではありません。サポートされるクエリは限定されていて、at-least-once 配信のみ保証されます。
Pub/Sub Lite と Spark Structured Streaming の併用
Spark を使用した Pub/Sub Lite でのデータのストリーム処理は、以下の Python スクリプトで示すように簡単です。Dataproc で完全な Java エンドツーエンド ワードカウント サンプルを実行するための詳細なガイドについては、GitHub の Readme をご参照ください。
まず、Spark Session オブジェクトをインスタンス化し、Pub/Sub Lite サブスクリプションから DataFrame を読み取ります。
次のスニペットは、ストリームを 2 秒単位のバッチの集まりとして処理し、結果のメッセージをターミナルに出力します。
実際には、このデータに対して変換を行います。それには、DataFrame のスキーマを考慮する必要があります。
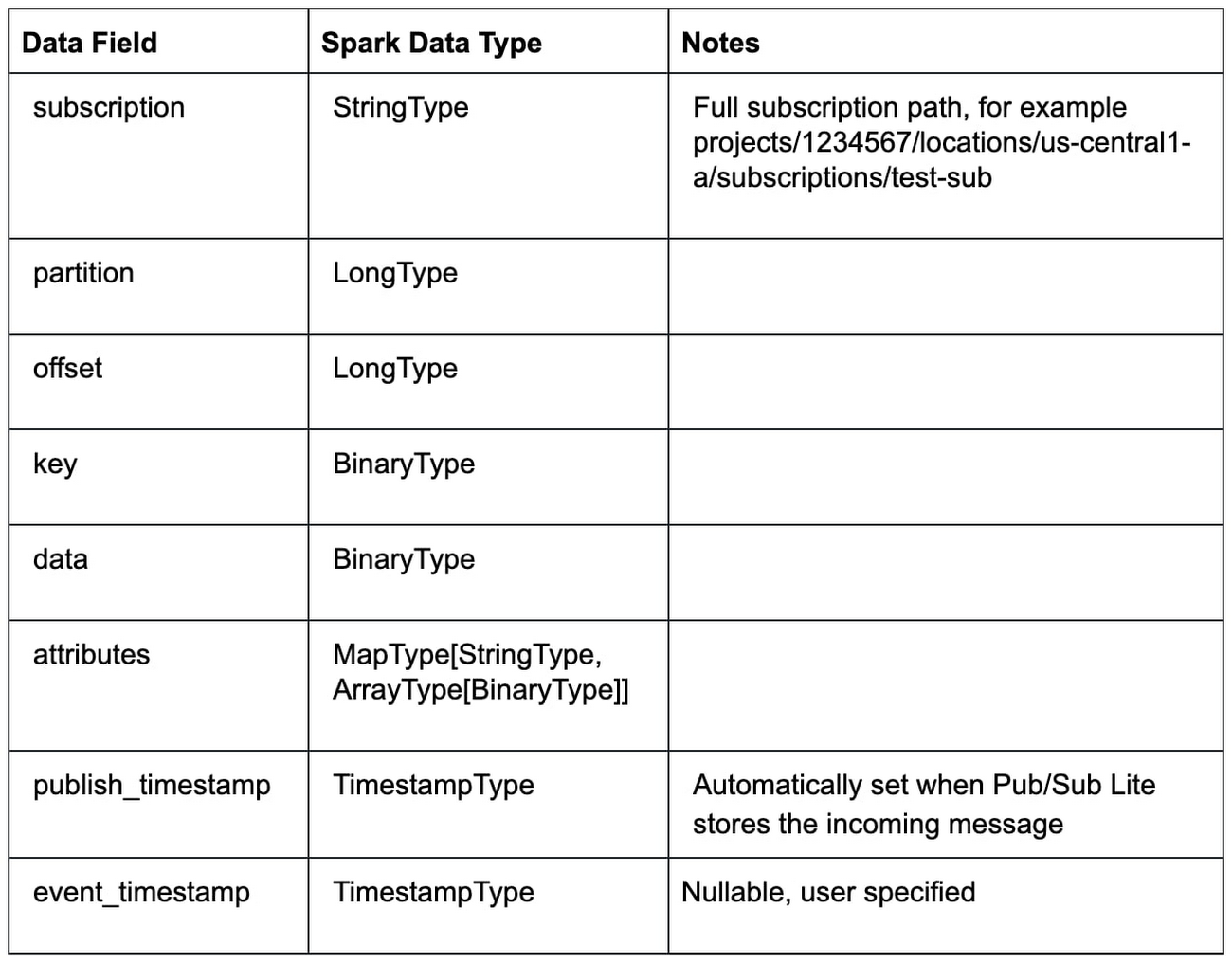
以下に BinaryType から StringType への一般的な変換を示します。
スループット パフォーマンスのベンチマーク
コネクタのスループット パフォーマンスと Pub/Sub Lite 自体のパフォーマンスを把握するために、Dataproc YARN クラスタでのパイプラインの例を調べました。この例では、パイプラインは Pub/Sub Lite からのバックログを使用し、それ以上の処理は行っていません。Dataproc YARN クラスタは、1 つのマスターノードと 2 つのワーカーノードで構成されています。すべてのノードは n1-standard-4 マシン(vCPU 4 個、メモリ 15 GB)で、メッセージはすべて 1 KiB です。Total spark process throughput(Spark 処理スループット合計)は processedRowsPerSecond を使用してバッチごとに計算され、Spark process throughput per partition(パーティションあたりの Spark 処理スループット)は Total spark process throughput をパーティション数で割って算出されました。
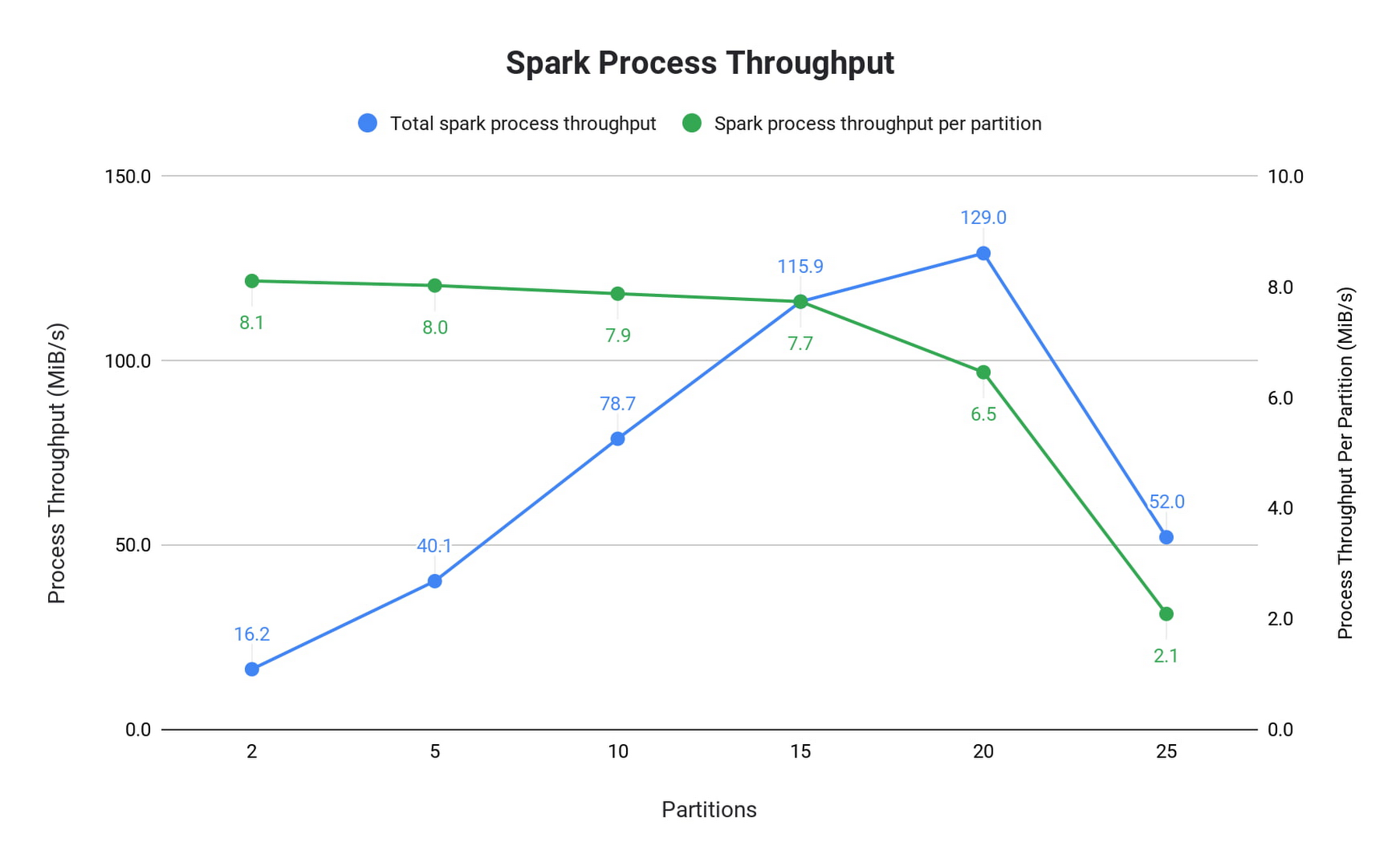
パーティションが 25 個の場合、ワーカーが過負荷になり、バッチごとの処理経過時間は最も遅いパーティションによって決定されるため、processedRowsPerSecond が大幅に低下しています。CPU 使用率を見ると、この低下が CPU 飽和と相関していることがわかります。
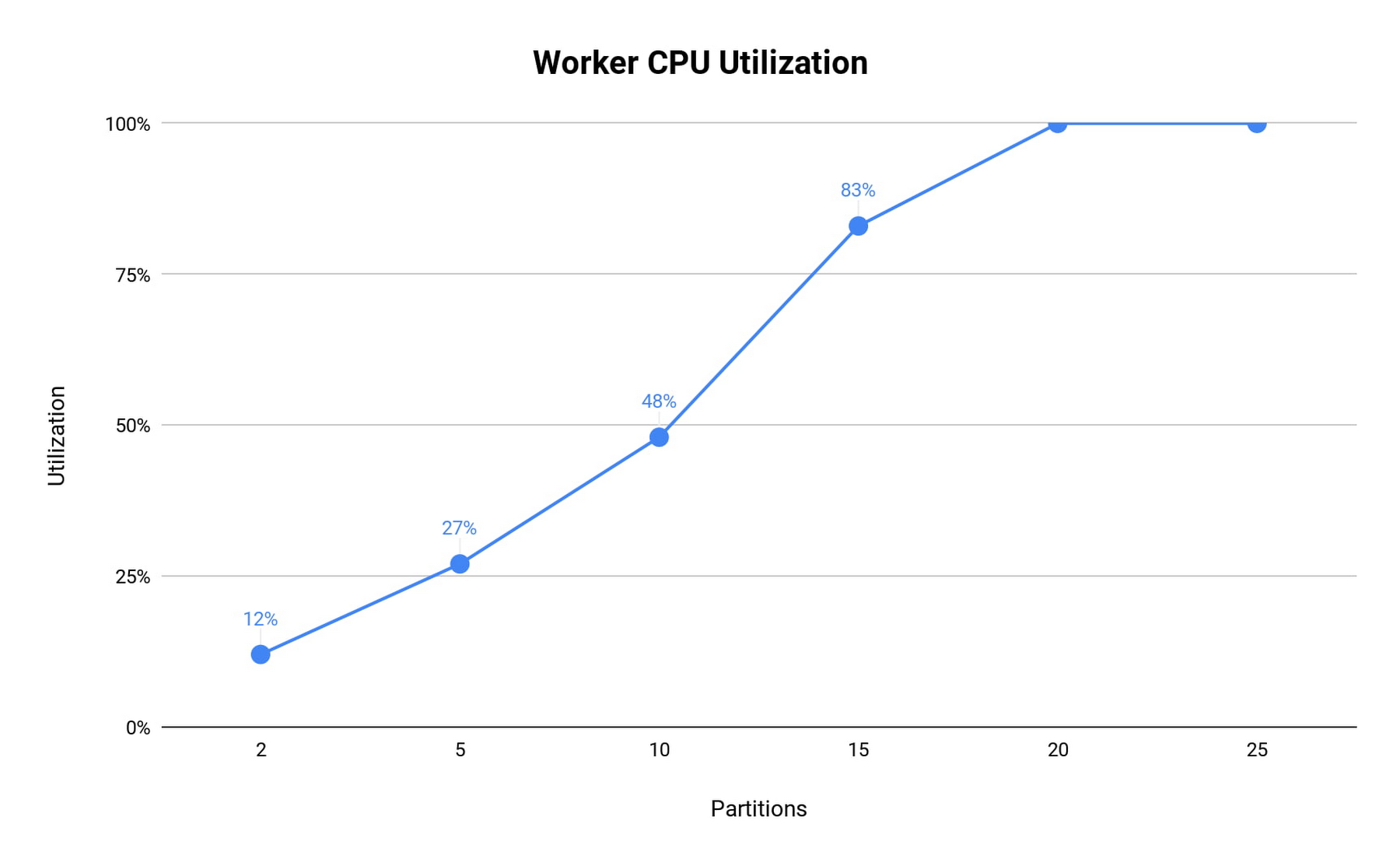
基本的な読み取り操作をベースラインとした場合、8 個の CPU を使用するクラスタのパーティション数は 12(それぞれ 8 MiB/秒のサブスクライブ スループット)にすることが推奨されています。これにより、1 つの n1-standard シリーズの vCPU で 12 MiB/秒の読み取りスループットを処理できるという大まかな法則が見えてきます。メッセージ処理が大幅に増加すると、この容量は減少します。
前述のベンチマークでは、メモリ割り当ては考慮されていません。実際には、トリガーの時間が長くなったりトラフィックが急上昇したりすると、マイクロバッチが大きくなり、より多くのメモリが必要になる場合があります。また、集約や拡張透かしなどの複雑なクエリには、より多くのメモリが必要になります。
次のステップ
以上で、Pub/Sub Lite がストリーミング アプリケーションに役立つサービスであることがおわかりいただけたかと思います。どうぞこの機会にコネクタと Pub/Sub Lite をお試しください。詳しい手順はこちらをご覧ください。フィードバックやバグレポートがございましたら、GitHub の問題として送信していただければ幸いです。また、このオープンソース プロジェクトへのコードの寄与もお待ちしております。
1. ソースとしての Pub/Sub Lite コネクタは、exactly-once 保証に対応しています。exactly-once 保証を確実にするには、べき等なシンクが必要です。
-ソフトウェア エンジニア、Michael Jiang
-Cloud Data Engineer、Sameer Farooqui

