Pub/Sub Group Kafka Connector の一般提供を開始: データ移動のドロップイン ソリューション
Google Cloud Japan Team
※この投稿は米国時間 2022 年 12 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
このたび Google Cloud は、Cloud Pub/Sub チームの積極的な支援のもと、Pub/Sub Group Kafka Connector の一般提供を開始いたしました。Connector(一つの JAR ファイルにパッケージ化)は、Apache 2.0 ライセンスに基づいた完全なオープンソースであり、Google の GitHub リポジトリでホストされています。パッケージ化されたバイナリは、GitHub と Maven Central で利用可能です。
Connector の JAR ファイルにパッケージ化されたソースとシンクのコネクタにより、既存の Apache Kafka デプロイメントを Pub/Sub または Pub/Sub Lite にわずか数ステップで接続できます。
データの移動を簡素化
クラウドに移行すると、Google Cloud にデプロイされたシステムとオンプレミスで実行中のシステムの同期状態を保つことが困難になる場合があります。シンクコネクタを使用すると、オンプレミスの Kafka クラスタから Pub/Sub または Pub/Sub Lite に簡単にデータをリレーできます。それにより、Google Cloud のさまざまなサービスと Google Cloud でホストされているお客様自身のアプリケーションにおいて、大規模なデータを利用することが可能になります。たとえば、Pub/Sub データを BigQuery に直接ストリーミングすることで、分析チームは BigQuery テーブルでワークロードを行うことができます。
オンプレミスの Kafka クラスタに関連付けられた既存の分析法がある場合は、ソースコネクタを使用することで、Google Cloud にデプロイされたマイクロサービスやお気に入りの Google Cloud サービスから任意の必要なデータを簡単に取得できます。これにより、オンプレミスと Google Cloud のデータソースの全体像を得られます。
Pub/Sub Group Kafka Connector は、Kafka Connect(Kafka とその他のシステム間で確実にデータをストリーミングするソリューションを開発、デプロイするためのフレームワーク)を使用して実装されています。Kafka Connect を使うことで、Pub/Sub または Pub/Sub Lite で使用できるコネクタの豊富なエコシステムが提供されます。Confluent Hub で好みのソースまたはディスティネーションのシステムを検索してください。
柔軟性とスケール
利用可能な構成オプションで、Kafka からのメッセージを Pub/Sub メッセージへ、またはその反対に変換する方法を正確に構成できます。また、どの Key-Value コンバータを使用するか指定することで、必要な Kafka のシリアル化形式を選択できます。メッセージの順序が重要なユースケースの場合は、シンクコネクタでは Kafka のレコードキーを Pub/Sub のメッセージである「ordering_key」として送信することで、順序付けられた Pub/Sub 配信の使用が可能になり、Pub/Sub Lite の順序保証との互換性を確保できます。ソースコネクタを使用して Kafka にデータを送信する際にメッセージの順序を維持するには、Kafka のレコードキーを目的のフィールドとして設定できます。
また、Connector では、Pub/Sub と Pub/Sub Lite の高スループットのメッセージ機能を活用でき、ストリームのスループットに応じた動的なスケールアップまたはスケールダウンが可能です。これは、Kafka Connect クラスタを分散モードで実行することで実現できます。分散モードでは、Kafka Connect は複数のワーカー プロセスを個別のサーバーで実行します。それぞれが、ソースまたはシンクコネクタのタスクをホストできます。「tasks.max」の設定を 1 より大きく構成することで、Kafka Connect により、特定の Kafka のトピックに対して、複数のタスクにまたがる並列処理とシャードのリレー作業が可能になります。メッセージ スループットの増加にあわせて、Kafka Connect はより多くのタスクを生成し、同時実行数を増やすことで合計スループットを向上させます。
好ましいアプローチ
Kafka と Google Cloud 間でデータを送信する既存の方法と比較して、コネクタは変革であると言えます。
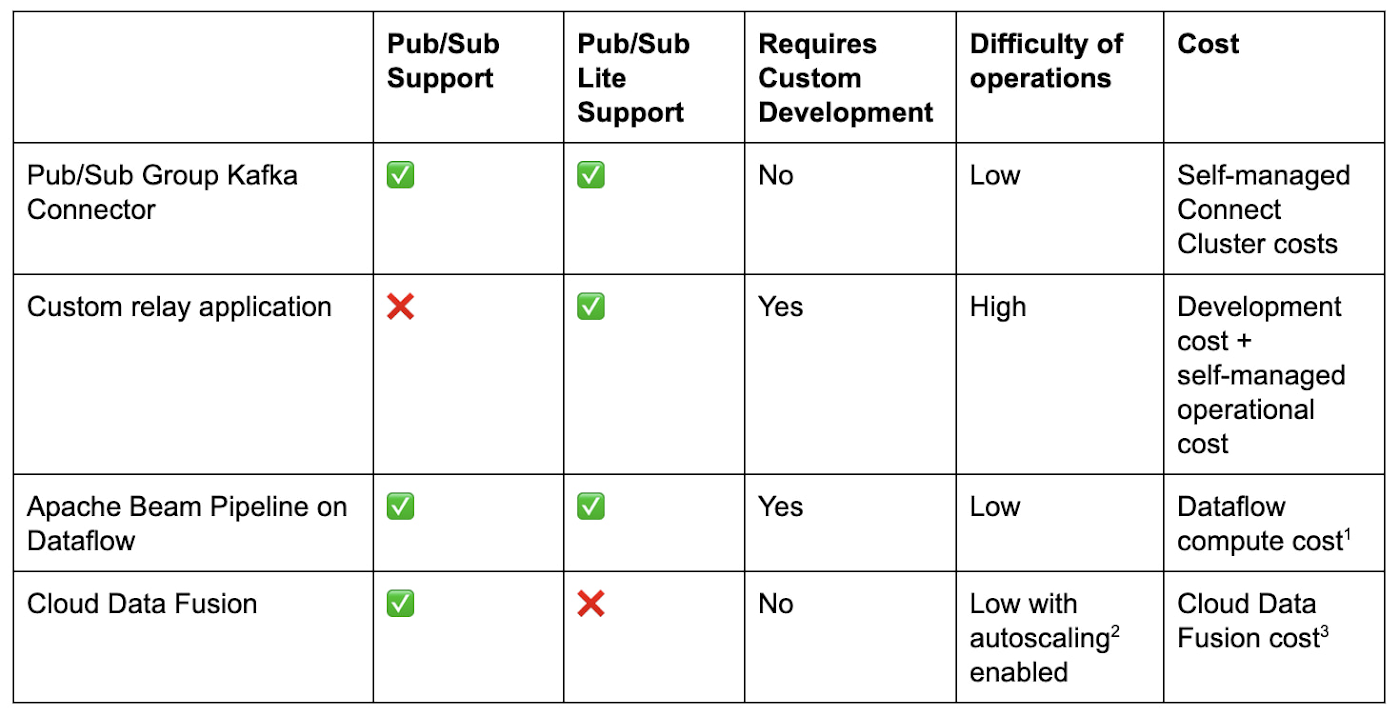
Kafka を Pub/Sub または Pub/Sub Lite に接続するためには、送信元からデータを読み取って、宛先のシステムに書き込むためのカスタムリレー アプリケーションを作成するという方法があります。Google Cloud では、Kafka の経験があり、Pub/Sub Lite への接続にご関心をお持ちのデベロッパー向けに、Kafka Shim Client を提供しています。Kafka Shim Client では、使い慣れた Kafka API を使用して、Pub/Sub Lite トピックからの消費および Pub/Sub Lite トピックへの生成タスクを簡単に作成できます。このアプローチにはいくつかデメリットがあります。開発に多大な労力を要する可能性があり、またすぐに使える水平方向のスケーリングがないため、高スループットのユースケースでは難しい場合があります。このカスタム ソリューションの運用方法をゼロから学習し、任意のモニタリングを追加することで、データがスムーズにリレーされるようにする必要もあります。代わりに、既存のフレームワークを使用して構築またはデプロイできるより簡単なオプションがあります。
Pub/Sub、Pub/Sub Lite、Kafka には、それぞれ Apache Beam との I/O コネクタがあります。KafkaIO を使用して Beam パイプラインを記述し、クラスタ Pub/Sub または Pub/Sub Lite 間でデータを移動できます。その後、Dataflow などの実行エンジンでパイプラインを実行できます。こうした作業を行うには、Beam のプログラミング モデルをある程度理解して、コードを記述することでパイプラインを作成し、場合によっては Dataflow のようなサポートされているランナーにアーキテクチャを拡張する必要があります。Dataflow で Beam のプログラミング モデルを使用することで、Kafka クラスタを Pub/Sub に接続しているストリームに対する変換処理や、複数のトピックに対するファンアウトのような複雑なトポロジの作成を柔軟に行うことができます。ただし、特に既存の Connect クラスタを使用するシンプルなデータ移動の場合、開発が不要で運用上のオーバーヘッドが少ない簡単な方法でコネクタを利用できます。
Cloud Data Fusion で Kafka と Pub/Sub 間のデータ インテグレーション パイプラインを設定する場合、3 つのプロダクトすべてをサポートするプラグインがあればコードは不要になります。どこかで実行しなければならない Beam パイプラインのように、Data Fusion パイプラインは Cloud Dataproc クラスタ上で実行する必要があります。これは、GUI でのドラッグ&ドロップ オプションを好み、Kafka クラスタを直接管理しないような、クラウドネイティブなデータ技術者に最も適した有効なオプションです。Kafka クラスタをすでに管理している場合は、ソース / シンクと Kafka クラスタ間の Kafka Connect クラスタに直接コネクタをデプロイして、より直接的に制御するネイティブ ソリューションを選択できます。
Pub/Sub コネクタを試してみるには、入門ガイドをご覧ください。
1. Dataflow のコンピューティング費用 2. 自動スケーリング 3. Cloud Data Fusion の費用
