NLP、BigQuery、エンベディングを使用したマルチモーダル検索ソリューション
Layolin Jesudhass
Global Generative AI Solutions Architect, Google
※この投稿は米国時間 2024 年 8 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
昨今のデジタル環境は、テキストだけでなく、画像や動画も含む膨大な量の情報を提供しています。従来の企業向け検索エンジンは主にテキストベースのクエリ用に設計されており、ビジュアル コンテンツの分析となると往々にして不十分でした。しかし、自然言語処理(NLP)とマルチモーダル エンベディングを組み合わせることで、新しい検索の時代が到来しつつあります。これにより、お客様はテキストベースのコンテンツと同じように、画像や動画、あるいはその中の情報を検索できるようになります。
このブログ記事では、テキスト検索を画像や動画、またはその両方で実行するデモを紹介します。このデモには、テキストを使用した画像の検索や、指定したクエリに基づく画像内のテキストの特定といった、クロスモーダルなセマンティック検索シナリオに特化したパワフルなマルチモーダル エンベディング モデルを使用しています。これらのタスクを実現するための鍵となるのが、マルチモーダル エンベディングです。
このデモでは、テキストから画像の検索、テキストから動画の検索、またこの両方を組み合わせた検索を行います
この仕組みを詳しく見ていきましょう。
画像、動画、テキストの統合検索ソリューション
このアーキテクチャは、メディア ファイルの保存に Google Cloud Storage を活用し、BigQuery のオブジェクト テーブルでこれらのファイルを参照します。マルチモーダル エンベディング モデルが画像と動画のセマンティック エンベディングを生成し、これらは BigQuery でインデックス化され、効率的な類似検索を可能にします。これにより、シームレスなクロスモーダル検索エクスペリエンスが実現します。
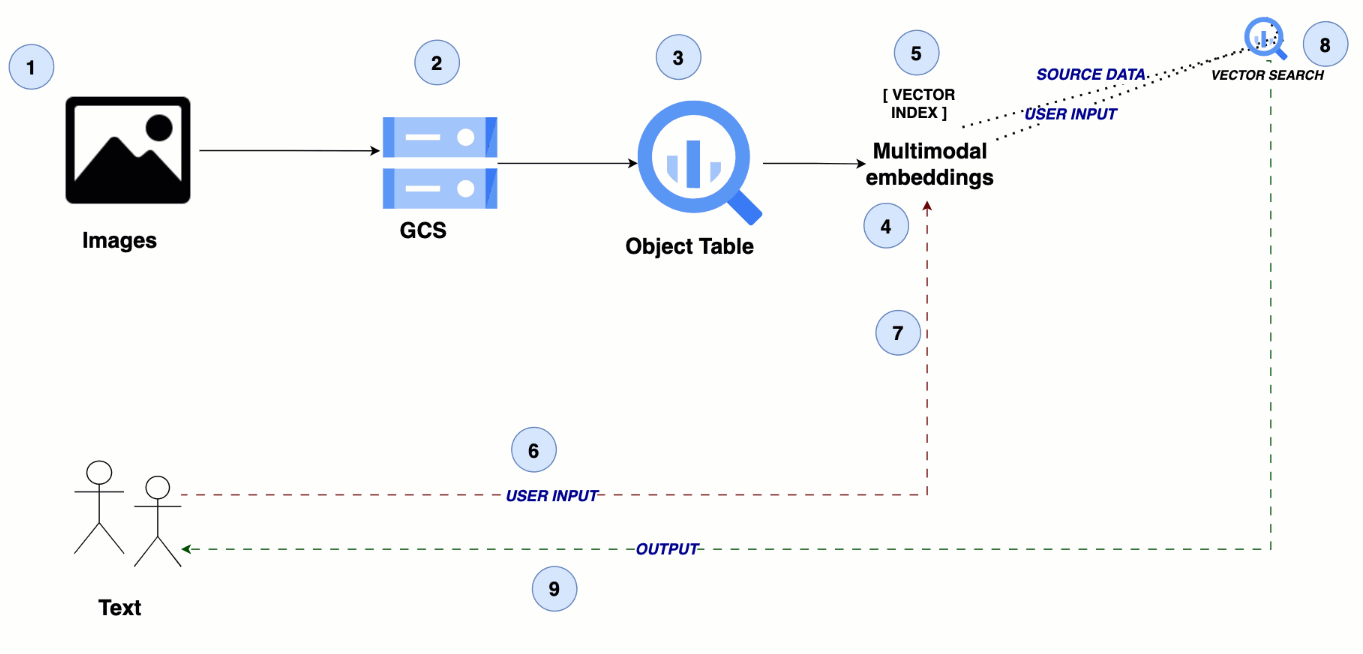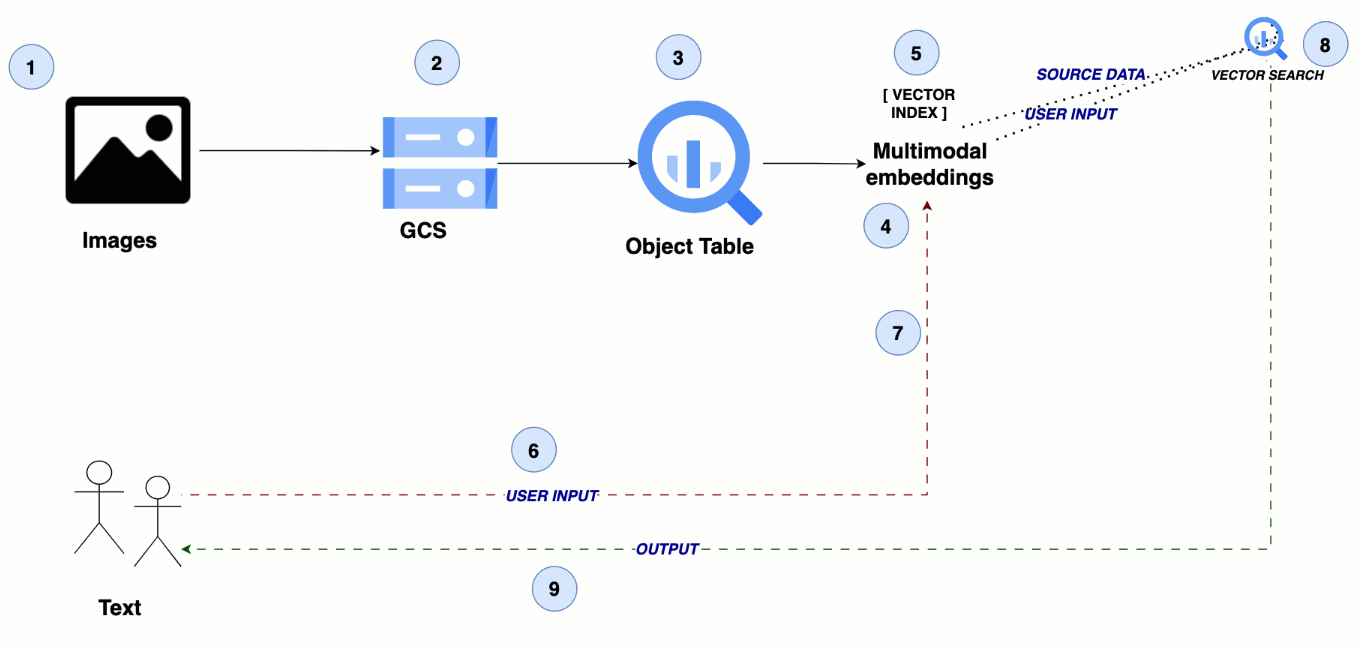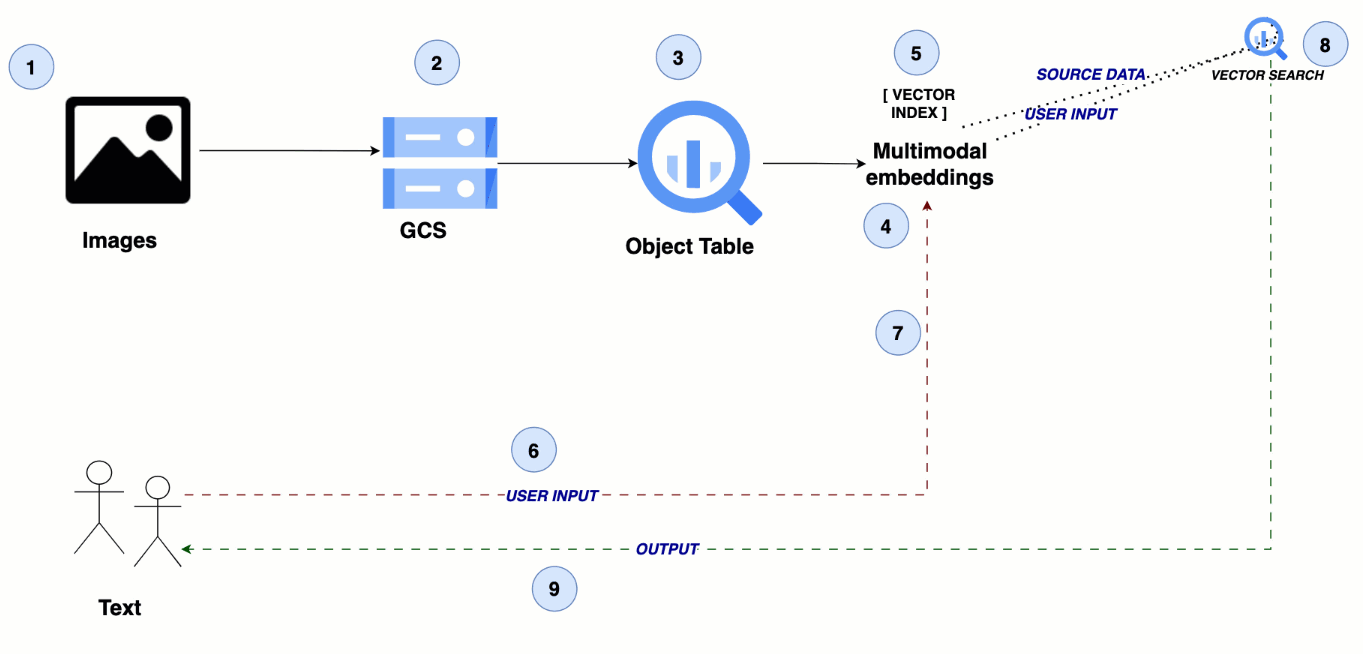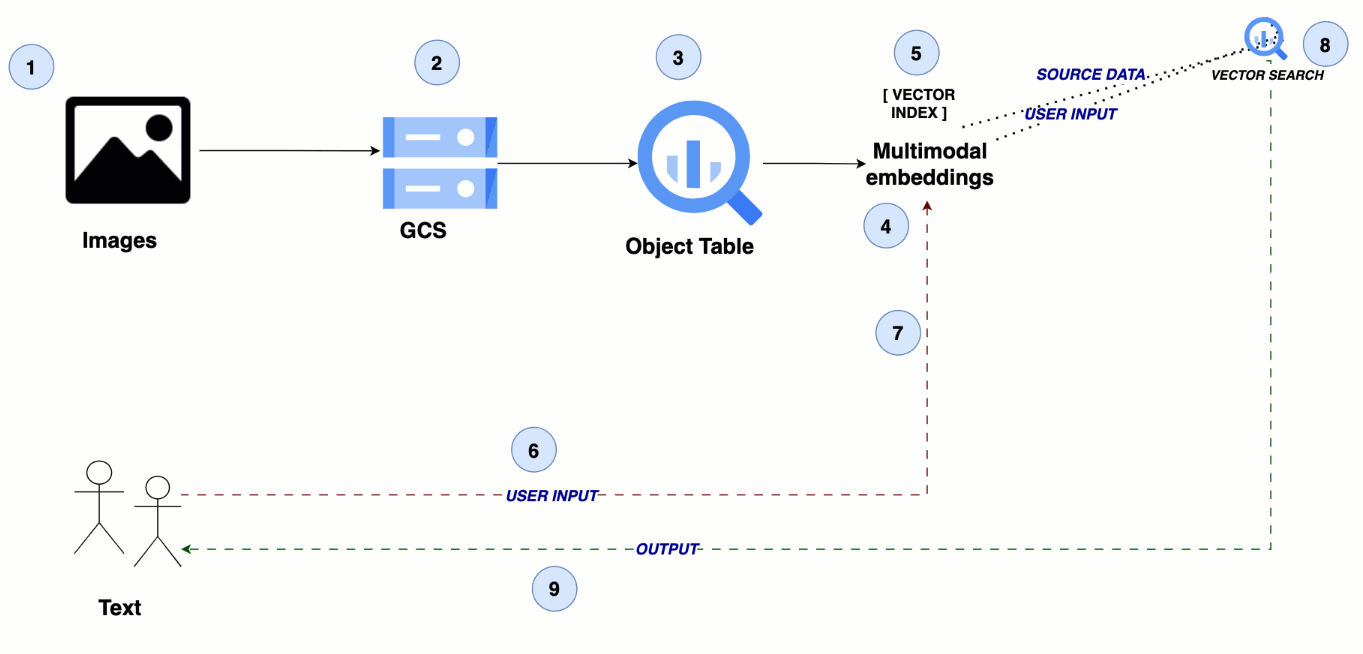
テキストからビジュアルへ: 画像と動画のマルチモーダル検索
同様のソリューションを実装するには、以下の手順に沿って進めます。
ステップ 1~2: 画像や動画データを Cloud Storage にアップロードする
すべての画像ファイルと動画ファイルを Cloud Storage バケットにアップロードします。デモ用に、Google 検索からダウンロードした画像と動画を GitHub で利用可能な形で用意しました。Cloud Storage バケットにアップロードする前に、必ず README.md ファイルを削除してください。
メディア ファイルの準備:
-
ご自身のデータを使用して、作業予定のすべての画像ファイルおよび動画ファイルを収集します。
-
ファイルは管理やアクセスがしやすいように整理し、適切に名前を付けます。
Cloud Storage へのデータ アップロード:
-
Cloud Storage バケットをまだ作成していない場合は、作成します。
-
メディア ファイルをバケットにアップロードします。Google Cloud コンソール、
gsutilコマンドライン ツール、または Cloud Storage API を使用できます。 -
ファイルが正しくアップロードされていることを確認し、ファイルが保存されているバケットの名前とパスをメモします(例:
gs://your-bucket-name/your-files)。
ステップ 3: BigQuery でオブジェクト テーブルを作成する
BigQuery でオブジェクト テーブルを作成し、Cloud Storage バケット内のソース画像ファイルと動画ファイルを参照できるようにします。オブジェクト テーブルは、Cloud Storage 内にある非構造化データ オブジェクトの読み取り専用テーブルです。BigQuery オブジェクト テーブルのその他のユースケースについては、こちらをご覧ください。
オブジェクト テーブルを作成する前に、こちらに記載されているように接続を確立します。接続のプリンシパルに「Vertex AI ユーザー」ロールが割り当てられていて、プロジェクトで Vertex AI API が有効になっていることを確認します。
リモート接続の作成
オブジェクト テーブルの作成
ステップ 4: マルチモーダル エンベディングを作成する
事前トレーニング済みのマルチモーダル エンベディング モデルを使用して、メディアデータのエンベディング(数値表現)を生成します。これらのエンベディングはコンテンツのセマンティック情報を捉え、効率的な類似検索を可能にします。
ステップ 5: BigQuery でベクトル インデックスを作成する
BigQuery でエンベディング用のベクトル インデックスを作成し、画像および動画データから生成されたエンベディングを効率的に保存してクエリを実行します。このインデックスは、後で類似検索を実行する際に不可欠です。
ステップ 6: ユーザーのクエリをテキスト入力として送信する
ユーザーのクエリは、「草を食べている象」のような簡単な自然言語でテキスト入力として送信されます。ユーザーがクエリを送信すると、システムはこのテキスト入力をエンベディングに変換します。これはメディアデータを処理したのと同様の方法です。
ステップ 7: ユーザークエリのテキスト エンベディングを作成する
同じマルチモーダル エンベディング モデルを使用して、ユーザークエリのテキスト エンベディングを作成できます。ユーザーのクエリを保存されたエンベディングと比較するために、まず同じマルチモーダル エンベディング モデルを使用してクエリ自体のエンベディングを生成します。
ステップ 8: 類似検索を実施する
ユーザーのクエリと画像や動画を含むソースデータとの間で、ベクトル検索を使用して類似検索が行われます。ステップ 4 で作成したベクトル インデックスを使用して、ユーザーのクエリに最も類似したメディア アイテムを見つけるための類似検索を実行します。この検索では、ユーザークエリのエンベディングとメディアデータのエンベディングを比較します。
ステップ 9: 画像や動画の検索結果をユーザーに返す
最後に、類似検索の結果がユーザーに提示されます。結果には、Cloud Storage バケットに保存されている最も類似した画像や動画の URI と、その類似性スコア(距離)が含まれます。これにより、ユーザーはクエリに関連するメディア アイテムを閲覧またはダウンロードできます。
マルチモーダル エンベディングで実現する次世代の検索
マルチモーダル エンベディングは画像と動画の両方のモダリティを扱えるため、ビジュアル コンテンツ全体にわたるパワフルな検索エクスペリエンスの構築が、わずか数ステップで実現できます。画像検索、動画検索、あるいは画像検索と動画検索を組み合わせたものなど、どのようなユースケースであっても、ユーザー エクスペリエンスを向上させ、コンテンツの発見を効率化する次世代の検索機能を活用できるようになります。
ー Google、生成 AI ソリューション アーキテクト、Layolin Jesudhass


