Apache Beam と Dataflow ランナーによる機械学習のパターン(パート 1)
Google Cloud Japan Team
※この投稿は米国時間 2020 年 12 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
ここ数年間で、Dataflow の機械学習用ストリーム / バッチデータの前処理機能を利用する企業が増えています。成功事例としては、Harambee、Monzo、Dow Jones、Fluidly などがあります。
Dataflow パイプラインの機械学習推論を使用して、データからインサイトを抽出するお客様も増えています。Dataflow パイプラインそのものに読み込まれた ML モデルを使用するか、Google Cloud によって提供される ML API を呼び出すかを選択できます。
こうしたユースケースが増える中、いくつかの共通パターンが見られるようになったため、このブログ投稿シリーズで取り上げていきます。本シリーズのパート 1 では、モデルにデータを提供し、その結果としての出力を抽出するプロセスについて検討します。具体的には、以下の内容を取り上げます。
ローカル / リモートの推論効率パターン
バッチ化パターン
singleton モデルパターン
マルチモデル推論パイプライン
複数のモデルにデータを提供するデータ分岐
複数の分岐からの結果の結合
このブログ全体で使用しているプログラミング言語は Python ですが、一般的な設計パターンの多くは Apache Beam パイプラインでサポートされているほかの言語にも対応しています。この点は ML フレームワークについても同様です。ここでは TensorFlow を使用しますが、パターンの多くは PyTorch や XGBoost などのほかのフレームワークでも使用できます。このブログの中心テーマは、モデル変換へのデータの提供と、ダウンストリームでのそのデータの後処理です。
これらのパターンがローカルモデルのユースケースでより具体性をもつように、オープンソースの「Text-to-Text Transfer Transformer」(T5)モデルを使用します。このモデルは「Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer」で公開されたものです。この論文では、大規模な実証調査を提示して、最も優れた言語モデリングの転移学習テクニックを決定し、これらのインサイトを広範囲に適用して、多数の NLP タスクで最新の成果を上げることができるモデルを生み出しました。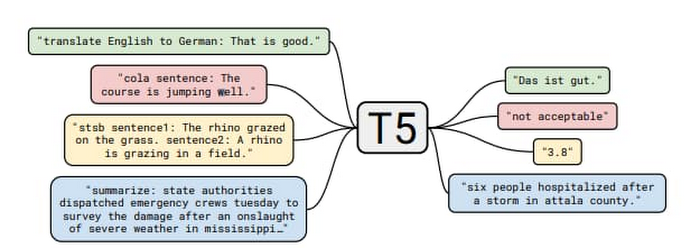
このサンプルコードでは、「クローズドブック型の質問応答」機能を利用しています。詳しくは、T5 のブログをご覧ください。
「Colab のデモとフォローアップの論文で、より困難な「クローズドブック型」の環境において、外部の知識に一切アクセスせずに雑学に関する質問に回答できるように、T5 をトレーニングしました。つまり、質問に回答するにあたり、T5 が使用できるのは教師なしの事前トレーニング中に収集したパラメータに保存されている知識のみであるということです。これは、オープン ドメインの質問応答に制約を加えた形とみなすことができます。」
たとえば、「人間には歯が何本あるか?」と質問すると、モデルからは「乳歯が 20 本」と返されます。このモデルは、最大で 110 億以上のパラメータを備え、サイズは 25 GB を超えるため、このブログで説明している推奨される手法に沿って行う必要があり、ここでの議論に最適です。
T5 モデルの設定
T5 モデルには複数のサイズがありますが、このブログではスモールと XXL を使用します。XXL モードでは非常に大きなメモリ フットプリント(モデルファイルの保存に 25 GB)が必要であることを考慮し、以下のコードサンプルの大部分では、スモールサイズのモデルを使用することをおすすめします。T5 チームによる手順は、この colab からダウンロードできます。
このブログの最後のコードサンプルでは XXL モデルが必要です。このコードは、50 GB 以上のメモリを備えたマシンで python コマンドを使用して実行することをおすすめします。
T5 モデル エクスポートのデフォルトでは、推論バッチサイズは 1 です。ここでは、これを 10 に設定する必要があります。そのためには、以下のコードサンプルにあるように「--batch_size=10」を追加します。
バッチ化パターン
パイプラインは、ローカル(パイプラインに対して内部)またはリモート(パイプラインに対して外部)からモデルにアクセスできます。
Apache Beam ではデータ処理タスクはパイプラインによって記述され、データ コレクション(PCollection)で機能する変換(PTransform)を有向非巡回グラフ(DAG)で表します。1 つのパイプラインに複数の PTransform を含めることができ、それらは do 関数(DoFn、ドゥーファンと発音)で定義されているユーザーコードを PCollection の要素上で実行できます。この処理は Dataflow ランナーによってワーカー全体に分散され、必要に応じてリソースがスケールアウトされます。
推論呼び出しは DoFn 内で行われます。その際、モデルをローカルで、またはリモートコール(HTTP など)を介して外部の API エンドポイントに読み込む関数が使用されます。これらのオプションそれぞれについて導入時に考慮すべき点があります。これらのパターンについて、以下で検討します。
推論フロー
パターンの概要を説明する前に、DoFn 内で推論関数を呼び出す際のさまざまな段階について見ていきましょう。
元データを、呼び出す関数向けにシリアル化された正しい形式に変換する。
必要な前処理をすべて実行する。
推論関数を呼び出す。
ローカルモード:
1. 必要な初期化ステップをすべて実行する(モデルの読み込みなど)。
シリアル化されたデータで推論コードを呼び出す。
リモートモードでは、シリアル化されたデータが API エンドポイントに送られる。そこで接続の確立、認可フローの実行、最後にデータ ペイロードの送信が必要になる。
モデルが元データを処理すると、関数からシリアル化された結果が返される。
DoFn で、後処理に備えて結果をシリアル化解除できるようになる。
ローカルの場合はモデルの初期化、リモートの場合は接続および認証の確立という管理作業が、処理全体の大きな部分を占めることがあります。この作業は、推論関数を呼び出す前にバッチ化を行うことで削減できます。バッチ化により管理コストを多数の要素間で平均化できるため、効率が向上します。
以下で、Apache Beam でバッチ化を実行するいくつかの方法と、それらの実装例についてご紹介します。
開始 / 終了バンドルのライフサイクル イベントを介したバッチ化
Apache Beam ランナーがパイプラインを実行すると、すべての DoFn インスタンスがゼロまたはそれ以上の要素「バンドル」を処理します。DoFn のライフサイクル イベントを使用して、作業バンドル間で共有されているリソースを初期化できます。ヘルパー変換の BatchElements は、start_bundle および finish_bundle メソッドを利用して要素をデータのバッチに再編成し、平均化された処理向けにバッチサイズを最適化します。
長所: ランナーによるシャッフル ステップが不要。
短所: バンドルサイズがランナーによって決まる。バンドルモードでは大きいバンドルも、ストリーム モードでは非常に小さくなることがある。
注: BatchElements は、ランタイムのパフォーマンスに基づいて最適なバッチサイズの特定を試みます。
「この変換は(融合された)ダウンストリームのオペレーションにかかった時間をプロファイリングすることで、最小パラメータと最大パラメータの間の最適なバッチサイズの特定を試みます。バッチサイズを固定する場合は、最小と最大が等しくなるように設定してください。」(Apache Beam のドキュメント)
サンプルコードでは、一貫性を持たせるように最小と最大の両方を設定することにしました。
以下の例では T5 モデルへの送信に備えてサンプルの質問がバッチで作成されています。
state と timer を介したバッチ化
state および timer API は Apache Beam のプリミティブで、window などのほかの高レベルなプリミティブのベースとなっています。Google Cloud API(Dataflow テンプレートを介した Cloud Data Loss Prevention API など)を呼び出すために使用される一部の公開バッチ化メカニズムは、このメカニズムを利用しています。ヘルパー変換の GroupIntoBatches は、state および timer API を利用して要素を目的のサイズのバッチにグループ化します。また、キーアウェアでもあり、1 つのキーの中の要素をバッチ化します。
長所: データドリブンの意思決定を含め、バッチの精密な制御が可能。
短所: シャッフルが必要。
Combine
Apache Beam の Combine API を使用すると、PCollection 内で要素を結合できます。そのバリアントは、PCollection 全体またはキー単位で機能します。Combine は一般的な変換であるため、主要なドキュメントにはその使用例が多数掲載されています。
長所: シンプルな API
短所: シャッフルが必要。出力の細かな制御ができない。
これらの手法により、モデルで使用するデータのバッチ(初期化コストを含む)を、バッチ全体で平均化できるようになりました。特に大きなモデルでローカルの推論を処理する場合は、この処理を効率的にするために実行できることがほかにもあります。次のセクションでは、推論パターンについて取り上げます。
リモート / ローカルの推論
推論のためにモデルに送信するデータのバッチは手に入りました。次のステップは、推論がローカルかリモートかによって決まります。
リモートの推論
リモートの推論では、Dataflow パイプライン外のサービスに対してリモート プロシージャ コールが行われます。カスタム開発のモデルの場合、例えば Kubernetes クラスタ上や、Google Cloud AI Platform Prediction などのマネージド サービスを介してモデルをホストできます。サービスとして提供されている事前構築済みのモデルの場合、Google Cloud Document AI などのサービス エンドポイントに対して呼び出しが行われます。リモートの推論を使用することの最大の利点は、モデルの読み込み時にパイプライン リソースを割り当てる必要がなく、バージョンを気にしなくてもいいことです。
リモート呼び出しに関する考慮事項:
合計バッチサイズが、サービスによって定められている制限内に収まるようにします。
Dataflow が受信負荷に対処するためのリソースを起動してしまうため、呼び出されるエンドポイントに大きな負担がかからないようにします。呼び出し内で使用されるスレッドの合計数を制限するには、いくつかのオプションがあります。
パイプラインのオプション内で max_num_workers 値を設定する。
必要に応じて、ワーカー プロセス / スレッド制御を利用する(詳細については、本ブログで後述)。
リモートの推論が不可能な状況では、モデルの読み込みや複数のスレッド間でのモデルの共有といった処理にもパイプラインが対処する必要があります。次に、これらのパターンについて見ていきます。
ローカルの推論
ローカルの推論は、モデルをメモリに読み込むことによって実行されます。この負荷の大きい初期化処理は、特に大きなモデルの場合、バッチ化パターンだけでは効率的に実行できません。前述したように、すべての入力に対して、DoFn にカプセル化されたユーザーコードが呼び出されます。バッチ化を行ったとしても、DoFn.process メソッドを呼び出すたびにモデルを読み込むことは、非常に非効率的です。
理想的なのは、モデルのライフサイクルが次のパターンに従うことです。
1.予測処理に使用された変換によって、モデルがメモリに読み込まれる。
2.読み込まれたら、外部のライフサイクル イベントによって再読み込みが強制されるまで、モデルがデータを処理する。
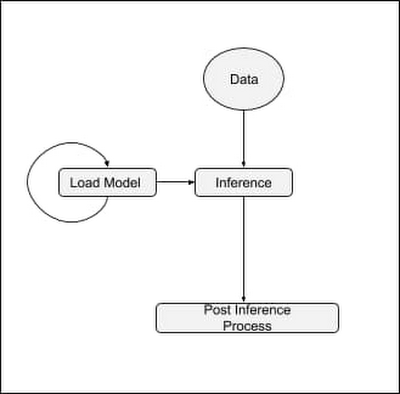
このパターンに達するには、共有モデルパターンを利用する必要があります。その詳細について、以下でご説明します。
singleton モデル(shared.py)
共有モデルパターンにより、ワーカー プロセスのすべてのスレッドで、モデル インスタンスをプロセスあたり 1 つのみメモリに読み込むことで、単一のモデルを利用できるようになります。このパターンは多用されるため、Apache Beam のバージョン 2.24.0 から shared.py でユーティリティ クラスが提供されるようになりました。
T5 モデルでのエンドツーエンドのローカルの推論の例
以下のコードサンプルでは、バッチ化パターンと共有モデルパターンの両方を適用し、T5 モデルを利用して一般知識に関する質問に回答するパイプラインを作成します。
T5 モデルの場合、ここで指定したバッチサイズでは、送信するデータ配列の長さをちょうど 10 にする必要があります。バッチ化には BatchElements ユーティリティ クラスを利用します。BatchElements に関して重要な点は、バッチサイズは目標であり、サイズの保証ではないということです。例えば、15 のサンプルがある場合、得られるバッチは 10 サンプルものと 5 サンプルのものの 2 つである可能性があります。これについては、コードに示されている処理関数で対処します。
推論呼び出しが直接 model.signatures を介して行われている点に注意してください。これは、大きなオブジェクトを一度読み込で再利用する shared.py パターンの使用法を簡単に例示するためです(Codelab t5-trivia は予測関数のラッピングの例を示しています)。
注: 最適なバッチサイズはワークロードによって大きく異なり、その判断についてだけで 1 本のブログ投稿に相当するテーマです。ほかのケースと同様、最適なサイズとレイテンシを把握するには、テストが重要です。
注: shared.py に使用しているオブジェクトを複数のスレッドから安全に呼び出せない場合は、ロッキング メカニズムを利用できます。これによってワーカーの並列性が制限されますが、モデルのサイズや読み込みの初期化コストによっては、それでも有益である場合があります。
コードサンプルを実行すると、以下が出力されます(スモールサイズの T5 モデルを使用した場合)。
ワーカー スレッド / プロセスの制御(上級)
ほとんどのモデルでは、ここまでに説明してきた手法で十分に効率的なパイプラインを実行できるでしょう。ただし、T5 XXL のように極端に大きなモデルの場合、ワーカーがモデルの読み込みに十分なリソースを利用できるように、ランナーにさらにヒントを提供する必要があります。Google ではこの改良に取り組んでおり、最終的にはこれらのパラメータの必要性をなくすことを目指しています。それまでの間は、モデルの必要性に応じてこれを使用してください。
単一のランナーで、1 つのワーカーにおいて多数のプロセスとスレッドを実行できます。以下の図を参照してください。

以下に詳細を示すパラメータは、Dataflow Runner v2 で使用できます。Runner v2 は現在、flag --experiments=use_runner_v2 を使用することで利用可能になります。

total_memory/num_proccesses が確実に大きなモデルをサポートできる比率になるようにするには、これらの値を以下のように設定する必要があります。
shared.py パターンを使用している場合、モデルはすべてのスレッドで共有されますが、プロセスでは共有されません。
shared.py パターンを使用せず、モデルが @setup DoFn などのライフサイクル イベント内で読み込まれた場合、number_of_worker_harness_threads を使用してワーカーのメモリに一致させます。
複数モデルの推論パイプライン
前のパターンのセットで、効率的な推論を可能にするためのメカニズムについて取り上げました。このセクションでは、単一のパイプライン内に複数の推論フローを作成する機能を活用できるファンクショナル パターンをいくつか見ていきます。
パイプラインの分岐
分岐を利用することで、PCollection のデータを別の変換に流すことができます。これにより単一のパイプラインで複数のモデルをサポートできるため、以下のような便利なタスクを実行できるようになります。
1 つのモデルの異なるバージョンを使用した A/B テスト。
異なるモデルで同じ元データから出力を行い、その出力を最終モデルにフィードする。
単一のデータソースを、別々のモデルの異なるユースケース向けに、複数のパイプラインを用意することなく、さまざまな方法でエンリッチ化およびシェイピングできるようにする。
Apache Beam には、推論パイプラインで簡単に分岐を作成するためのオプションが 2 つあります。1 つ目は、PCollection に複数の変換を適用する方法です。
2 つ目は、複数出力変換を使用する方法です。
T5 と分岐パターンの使用
T5 モデルには複数のバージョン(スモールと XXL)があるため、データを分岐させ、別々のモデルで推論を実行し、データをまとめて戻して結果を比較するテストを実行できます。
このテストにはより曖昧な形の質問を使用します。
「Where does the name {first name} come from({下の名前} という名前はどこから来たものですか).」
この質問の意図は、下の名前の由来を判断することです。これらの名前に関しては XXL モデルの方がスモールモデルよりも優れた結果を出すと想定しました。
この例を構築する前に、まず前のコードを改良し、2 つの異なる分岐の結果をまとめる方法を示す必要があります。前のコードの予測関数は、zip() を使用して質問と推論を統合することで変更できます。
パイプラインの構築
パイプラインのフローは以下のとおりです。
質問例を読み込む。
別々の分岐を介して、質問をスモールモデルと XXL モデルに送る。
質問をキーとして結果を結合する。
値を視覚的に比較できるように、シンプルな出力を提供する。
注: このコードサンプルを XXL モデルで directrunner を使用して実行する場合は、60 GB 以上のメモリを備えたマシンが必要です。もちろん、スモールから XXL までの間の任意のサイズのモデルでこのサンプルコードを実行しても構いません。その場合、このメモリ要件は緩和されます。
出力は以下のとおりです。
ご覧のように、大きな XXL モデルの方がスモールモデルよりもはるかに優れた結果となりました。パラメータが多い分、世界に関する知識をより多く保存できていることを考えれば理にかなっています。この結果は、https://arxiv.org/abs/2002.08910 の調査結果によって立証されています。
重要な点は、ダウンストリームで簡単に使用できる両方のモデルからの予測を含むタプルを利用できるようになったということです。
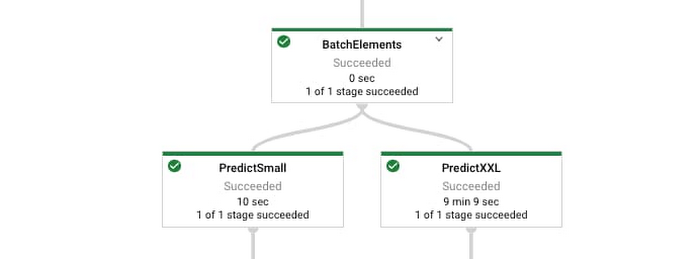
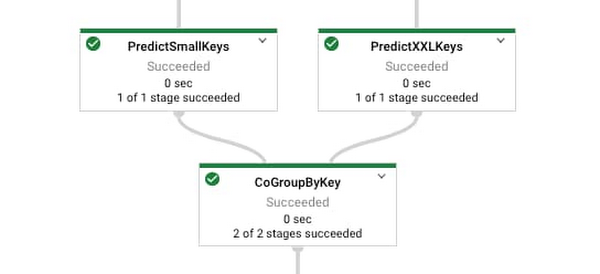
以下で、Dataflow ランナーで前述のコードを実行する際に生成されるグラフのようすを確認できます。
注: Dataflow ランナーでサンプルを実行する場合は、以下のように setup.py ファイルを install_requires パラメータで使用してください。tensorflow-text は重要です。前述のコードサンプルで直接使用されることはありませんが、T5 モデルではこのライブラリが必要なためです。
install_requires=['t5==0.7.1', 'tensorflow-text==2.3.0', 'tensorflow==2.3.1']
XXL モデルではメモリの多いマシンが必要になります。前述のパイプラインは、以下の構成で実行されました。
machine_type = custom-1-106496-ext
number_of_worker_harness_threads = 1
experiment = use_runner_v2
XXL モデルのサイズは 25 GB を超えるため、読み込み処理には 15 分以上かかります。この読み込み時間を短縮するには、カスタム コンテナを使用します。
XXL モデルによる予測は、CPU が 1 つの場合、何分間もかかることがあります。
バッチ化と分岐:
結果の結合:
まとめ
このブログでは、バッチ化や singleton モデルパターンなど、リモート / ローカルの推論呼び出しの実行パターンをいくつかご紹介しました。また、大きなモデルを扱う際の処理 / スレッドモデルについても取り上げました。最後に、複雑なパイプライン図を容易に作成し、より高度な推論パイプラインに使用する方法を簡単にご紹介しました。
詳しくは、Dataflow のドキュメントをご覧ください。
-シニア スタッフ デベロッパー アドボケイト Reza Rokni
-Dataflow エンジニアリング チーム ソフトウェア エンジニア Ahmet Altay
-Dataflow エンジニアリング チーム ソフトウェア エンジニア Valentyn Tymofieiev
