Machine learning patterns with Apache Beam and the Dataflow Runner, part I
Reza Rokni
Dataflow Product Manager
Ahmet Altay
Software Engineer, Dataflow engineering team
Note: Since this blog, Dataflow ML now natively supports local and remote inference with batch and streaming pipelines, as well as data preprocessing and postprocessing. It utilizes the core patterns and best practices described in this blog, and supports model handlers including PyTorch, scikit-learn, TensorFlow, ONNX, TensorRT, and Vertex AI.
Over the years, businesses have increasingly used Dataflow for its ability to pre-process stream and/or batch data for machine learning. Some success stories include Harambee, Monzo, Dow Jones, and Fluidly.
A growing number of other customers are using machine learning inference in Dataflow pipelines to extract insights from data. Customers have the choice of either using ML models loaded into the Dataflow pipeline itself, or calling ML APIs provided by Google Cloud.
As these use cases develop, there are some common patterns being established which will be explored in this series of blog posts. In part I of this series, we’ll explore the process of providing a model with data and extracting the resulting output, specifically:
Local/remote inference efficiency patterns
Multi-model inference pipelines
Although the programming language used throughout this blog is Python, many of the general design patterns will be relevant for other languages supported by Apache Beam pipelines. This also holds true for the ML framework; here we are using TensorFlow but many of the patterns will be useful for other frameworks like PyTorch and XGBoost. At its core, this is about delivering data to a model transform and the post processing of that data downstream.
To make the patterns more concrete for the local model use case, we will make use of the open source "Text-to-Text Transfer Transformer” (T5) model which was published in “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”. The paper presents a large-scale empirical survey to determine which transfer learning techniques for language modelling work best, and applies these insights at scale to produce a model that achieves state-of-the-art results on numerous NLP tasks.
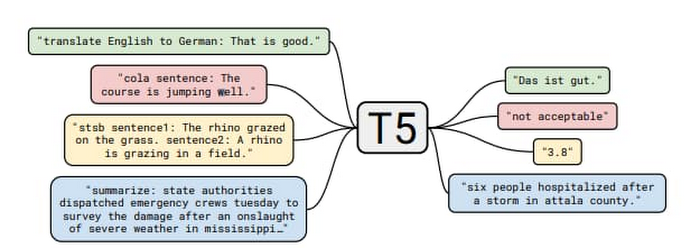
In the sample code, we made use of the "Closed-Book Question Answering" ability, as explained in the T5 blog;
"...In our Colab demo and follow-up paper, we trained T5 to answer trivia questions in a more difficult ‘closed-book’ setting, without access to any external knowledge. In other words, in order to answer a question T5 can only use knowledge stored in its parameters that it picked up during unsupervised pre-training. This can be considered a constrained form of open-domain question answering."
For example, we ask the question, "How many teeth does a human have?" and the model returns with “20 primary.” The model is well suited for our discussion, as in its largest incarnation it has over 11 billion parameters and is over 25 Gigabytes in size, which necessitates following the good practices described in this blog.
Setting up the T5 Model
There are several sizes of the T5 model, in this blog we will make use of small and XXL sizes. Given the very large memory footprint needed by the XXL mode (25 GB for the save model files), we recommend working with the small version of the model when exploring most of the code samples below. You can download instructions from the T5 team in this colab.
For the final code sample in this blog, you’ll need the XXL model, we recommend running that code via python command on a machine with 50+ GB of memory.
The default for the T5 model export is to have an inference batch size of 1. For our purposes, we’ll need this to be set to 10 by adding --batch_size=10 as seen in the code sample below.
Batching pattern
A pipeline can access a model either locally (internal to the pipeline) or remotely (external to the pipeline).
In Apache Beam, a data processing task is described by a pipeline, which represents a directed acyclic graph (DAG) of transformations (PTransforms) that operate on collections of data (PCollections). A pipeline can have multiple PTransforms, which can execute user code defined in do-functions (DoFn, pronounced as do-fun) on elements of a PCollection. This work will be distributed across workers by the Dataflow runner, scaling out resources as needed.
Inference calls are made within the DoFn. This can be through the use of functions that load models locally or via a remote call, for example via HTTP, to an external API endpoint. Both of these options require specific considerations in their deployment, and these patterns are explored below.
Inference flow
Before we outline the pattern, let's look at the various stages of making a call to an inference function within our DoFn.
Convert the raw data to the correct serialized format for the function we are calling.
Carry out any preprocessing required.
Call the inference function:
Once the model processes the raw data, the function returns with the serialized result.
Our DoFn can now deserialize the result ready for postprocessing.
The administration overhead of initializing the model in the local case, and the connection/auth establishment in the remote case, can become significant parts of the overall processing. It is possible to reduce this overhead by batching before calling the inference function. Batching allows us to amortize the admin costs across many elements, improving efficiency.
Below, we discuss several ways you can achieve batching with Apache Beam, as well as ready made implementations of these methods.
Batching through Start/Finish bundle lifecycle events
When an Apache Beam runner executes pipelines, every DoFn instance processes zero or more “bundles'' of elements. We can use DoFn's life cycle events to initialize resources shared between bundles of work. The helper transform BatchElements leverages start_bundle and finish_bundle methods to regroup elements into batches of data, optimizing the batch size for amortized processing.
Pros: No shuffle step is required by the runner.
Cons: Bundle size is determined by the runner. In batch mode, bundles are large, but in stream mode bundles can be very small.
Note: BatchElements attempts to find optimal batch sizes based on runtime performance.
"This transform attempts to find the best batch size between the minimum and maximum parameters by profiling the time taken by (fused) downstream operations. For a fixed batch size, set the min and max to be equal." (Apache Beam documentation)
In the sample code we have elected to set both min and max for consistency.
In the example below, sample questions are created in a batch ready to send to the T5 model:
Batching through state and timers
The state and timer API is the primitives within Apache Beam which other higher level primitives like windows are built on. Some of the public batching mechanisms used for making calls to Google Cloud APIs like the Cloud Data Loss Prevention API via Dataflow templates, rely on this mechanism. The helper transform GroupIntoBatches leverages the state and timer API to group elements into batches of desired size. Additionally it is key-aware and will batch elements within a key.
Pros: Fine-grained control of the batch, including the ability to make data driven decisions.
Cons: Requires shuffle.
Combiners
Apache Beam Combiner API allows elements to be combined within a PCollection, with variants that work on the whole PCollection or on a per key basis. As Combine is a common transform, there are a lot of examples of its usage in the core documents.
Pros: Simple API
Cons: Requires shuffle. Coarse-grained control of the output.
With these techniques, we will now have a batch of data to use with the model, including the initialization cost, now amortized across the batch. There is more that can be done to make this work efficient, particularly for large models when dealing with local inference. In the next section we will explore inference patterns.
Remote/local inference
Now that we have a batch of data that we would like to send to a model for inference, the next step will depend on whether the inference will be local or remote.
Remote inference
In remote inference, a remote procedure call is made to a service outside of the Dataflow pipeline. For a custom built model, the model could be hosted, for example on a Kubernetes cluster or through a managed service such as Google Cloud AI Platform Prediction. For pre-built models which are provided as a service, the call will be to the service endpoint, for example Google Cloud Document AI. The major advantage of using remote inference is that we do not need to assign pipeline resources to loading the model, or take care of versions.
Factors to consider with remote calls:
Ensure that the total batch size is within the limits provided by the service.
Ensure that the endpoint being called is not overwhelmed, as Dataflow will spin up resources to deal with the incoming load. You can limit the total number of threads being used in the calls by several options:
In circumstances when remote inference is not possible, the pipeline will also need to deal with actions like loading the model and sharing that model across multiple threads. We’ll look at these patterns next.
Local inference
Local inference is carried out by loading the model into memory. This heavy initialization action, especially for larger models, can require more than just the Batching pattern to perform efficiently. As discussed before, the user code encapsulated in the DoFn is called against every input. It would be very inefficient, even with batching, to load the model on every invocation of the DoFn.process method.
In the ideal scenario the model lifecycle will follow this pattern:
Model is loaded into memory by the transformation used for prediction work.
Once loaded, the model serves data, until an external life cycle event forces a reload.
Part of the way we reach this pattern is to make use of the shared model pattern, described in detail below.
Singleton model (shared.py)
The shared model pattern allows all threads from a worker process to make use of a single model by having only one instance of the model loaded into memory per process. This pattern is common enough that the shared.py utility class has been made available in Apache Beam since version 2.24.0.
End-to-end local inference example with T5 model
In the below code example, we will apply both the batching pattern as well as the shared model pattern to create a pipeline that makes use of the T5 model to answer general knowledge questions for us.
In the case of the T5 model, the batch size we specified requires the array of data that we send to it to be exactly of length 10. For the batching, we will make use of the BatchElements utility class. An important consideration with BatchElements is that the batch size is a target, not a guarantee of size. For example, if we have 15 examples, then we might get two batches; one of 10 and one of 5. This is dealt with in the processing functions shown in the code.
Please note the inference call is done directly via model.signatures as a simple way to show the application of the shared.py pattern, which is to load a large object once and then reuse. (The code lab t5-trivia shows an example of wrapping the predict function).
Note: Determining the optimum batch size is very workload specific and would warrant an entire blog discussion on its own. Experimentation as always the key for understanding the optimum size/latency.
Note: If the object you are using for shared.py can not be safely called from multiple threads, you can make use of a locking mechanism. This will limit parallelism on the worker, but the trade off may still be useful depending on the size / initialization cost of loading the model.
Running the code sample will produce the following output (when using the small T5 model):
Worker thread/process control (advanced)
With most models, the techniques we have described so far will be enough to run an efficient pipeline. However, in the case of extremely large models like the T5 XXL, you will need to provide more hints to the runner to ensure that the workers have enough resources to load the model. We are working on improving this and we will remove the needs for these parameters eventually. But until then, use this if your models need it.
A single runner is capable of running many processes and threads on a worker, as shown in the diagram below:

The parameters detailed below are those that can be used with the Dataflow Runner v2. Runner v2 is currently available using the flag --experiments=use_runner_v2.

To ensure that the total_memory/num processes are at a ratio that can support large models, these values will need to be set as follows:
If using the shared.py pattern, the model will be shared across all threads but not across processes.
If not using the shared.py pattern and the model is loaded, for example, within the @setup DoFn lifecycle event, then make use of number_of_worker_harness_threads to match the memory of the worker.
Multiple-model inference pipelines
In the previous set of patterns, we covered the mechanics of enabling efficient inference. In this section, we will look at some functional patterns which allow us to leverage the ability to create multiple inference flows within a single pipeline.
Pipeline branches
A branch allows us to flow the data in a PCollection to different transforms. This allows multiple models to be supported in a single pipeline, enabling useful tasks like:
A/B testing using different versions of a model.
Having different models produce output from the same raw data, with the outputs fed to a final model.
Allowing a single data source to be enriched and shaped in different ways for different use cases with separate models, without the need for multiple pipelines.
In Apache Beam, there are two easy options to create a branch in the inference pipeline. One is by applying multiple transformations to a PCollection:
The other uses multi-output transforms:
Using T5 and the branch pattern
As we have multiple versions of our T5 model (small and XXL), we can run some tests which branch the data, carry out inference on different models, and join the data back together to compare the results.
For this experiment, we will use a more ambiguous question of the form.
"Where does the name {first name} come from."
The intent of the question is to determine the origins of the first names. Our assumption is that the XXL model will do better with these names than the small model.
Before we build out the example, we first need to show how to enhance the previous code to give us a way to bring the results of two separate branches back together. Using the previous code, the predict function can be changed by merging the questions with the inferences via zip().
Building the pipeline
The pipeline flow is as follows:
Read in the example questions.
Send the questions to the small and XXL versions of the model via different branches.
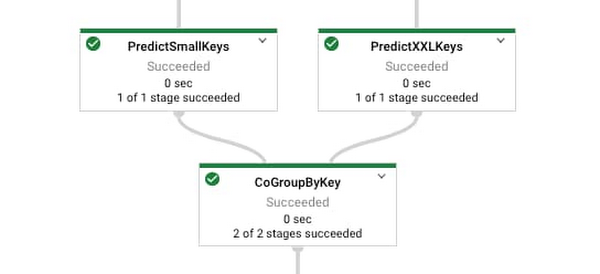
Join the results back together using the question as the key.
Provide simple output for visual comparison of the values.
Note: To run this code sample with the XXL model and the directrunner, you will need a machine with a minimum of 60GB of memory. You can also of course run this example code with any of the other sizes that fall between the small to XXL which will have a lower memory requirement.
The output is shown below.
As we can see, the larger XXL model did a lot better than the small version of the model. This makes sense as the additional parameters allow the model to store more world knowledge. This result is confirmed by findings of https://arxiv.org/abs/2002.08910".
Importantly, we now have a tuple which contains the predictions from both of the models which can be easily used downstream.
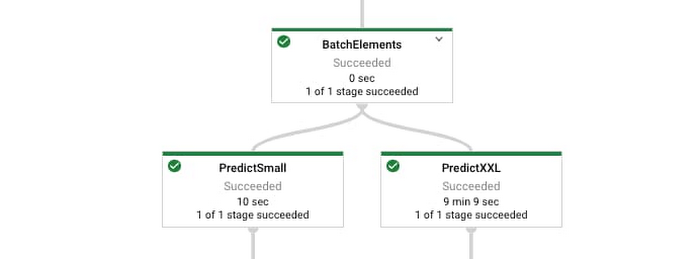
Below we can see the shape of the graph produced by the above code when run on the Dataflow Runner.
Note: To run the sample on the Dataflow runner, please make use of a setup.py file with the install_requires parameters as below, the tensorflow-text is important as the T5 model requires the library even though it is not used directly in the code samples above.
install_requires=['t5==0.7.1', 'tensorflow-text==2.3.0', 'tensorflow==2.3.1']
A high memory machine will be needed with the XXL model, the pipeline above was run with configuration:
machine_type = custom-1-106496-ext
number_of_worker_harness_threads = 1
experiment = use_runner_v2
As the XXL model is > 25 Gig in size, with the load operation taking more than 15 mins. To reduce this load time, use a custom container.
The predictions with the XXL model can take many minutes to complete on a CPU.
Batching and branching:
Joining the results:
Conclusion
In this blog, we covered some of the patterns for running remote/local inference calls, including; batching, the singleton model pattern, and understanding the processing/thread model for dealing with large models. Finally, we touched on how the easy creation of complex pipeline shapes can be used for more advanced inference pipelines.
To learn more, review the Dataflow documentation.

