分刻みで出荷を追跡: Mercado Libre が定刻配送のためにリアルタイム分析を活用している方法

Google Cloud Japan Team
※この投稿は米国時間 2022 年 8 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
Mercado Libre のデータドリブンな文化の原動力となっているのは、イテレーションとイノベーションです。最初の投稿では、ユーザーが独自のモデルとプロセスを構築できるデータ エコシステムを BigQuery と Looker を活用して作成する、継続的なインテリジェンス アプローチについて紹介しました。
このフレームワークを使用して、配送オペレーション チームは、輸送ネットワークのほぼリアルタイムでのデータのモニタリングと分析ができる新しいソリューションを構築し、データ アナリストが貴重な分析情報を作成、埋め込み、提供できるようにしました。
課題
配送オペレーションは e コマースの成功に不可欠です。Mercado Libre は複数の国、タイムゾーン、倉庫にまたがり、国内外の運送業者が関係しているため、そのプロセスは非常に複雑です。さらに、パンデミックの発生により注文が急増し、配送チームには、顧客が期待する 48 時間以内の配達というタイムラインを守りつつ、より多くの配送を行わなければならないという圧力が高まりました。
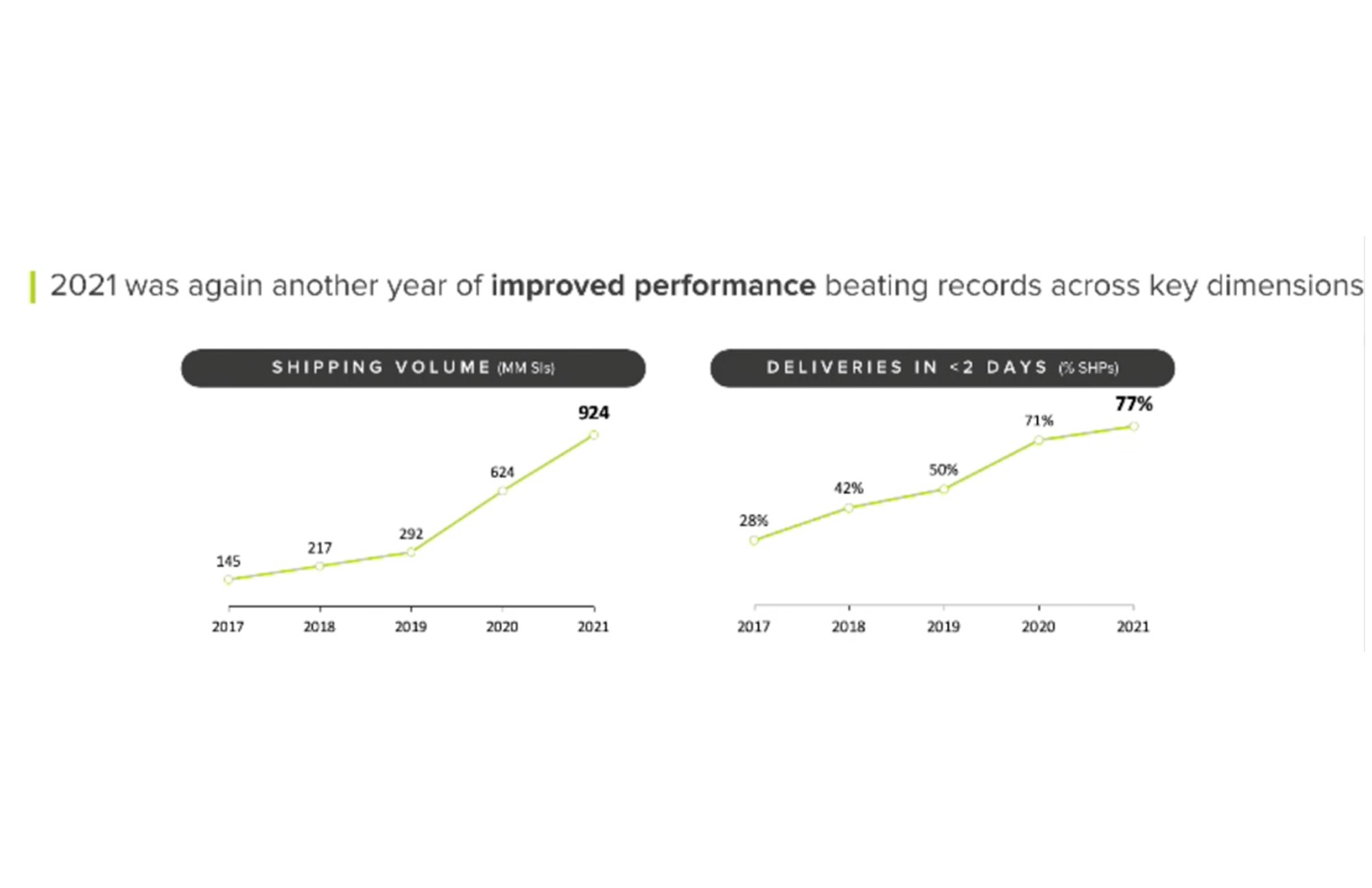
この需要増に伴い、フルフィルメント センターやクロスドッキング センターを拡大し、事業を展開する主要な国々でネットワーク(「メリネット」と称しています)のノード数を 2~3 倍に増やしました。現在、私たちはラテン アメリカで最も多数の電気自動車を保有する企業となっており、ブラジルとメキシコでは航空国内便を運営しています。
以前は複数のソースからのデータを扱い、API を使用しユースケースに応じてさまざまなプラットフォームにそのデータを取り込んでいました。リアルタイムのデータの消費やモニタリングには Kibana を使い、ビジネス分析用の履歴データは Teradata にパイプで渡していました。その結果、Kibana のリアルタイム データと Teradata の過去のデータは連携せず、並行して増大していました。一方では、オペレーション チームがリアルタイムのデータ ストリームをモニタリングに使用し、他方では、ビジネス アナリストがデータ ウェアハウスにある過去のデータを基にビジュアリゼーションを構築していました。
この方法は、次のような多くの問題を引き起こしました。
オペレーション チームには可視性がなく、ビジュアリゼーションを構築するためのサポートが必要でした。BI 専門チームがボトルネックになりました。
メンテナンスが必要とされ、システムのダウンタイムが発生しました。
並行するそれらのソリューションは管理されておらず(オペレーション チームは保存に Elastic データベースを使用し、属性と指標を処理していた)、バックアップは使いにくくデータは一定期間バインドされていました。
SQL のように、データ エンティティを関連付けることができませんでした。
バランスを取る: リアルタイム データと過去のデータ
リアルタイム データと過去のデータ間をシームレスに移動できるようにする必要がありました。この必要に対応するため、Google Cloud を利用すれば一度に多くのユースケースを活用できることがわかったので、BigQuery にデータを移行することを決定しました。
リアルタイム データと過去のデータを BigQuery 内で統合してからは、ほぼリアルタイムで利用できるようにする必要があるデータセットとそうではないデータセットを選択できるようになりました。リアルタイムのログ可視化アプローチの代わりに、データ ストリームから異なる時間枠テーブルを持つ分析を使用することを評価しました。これにより、同じ送信元を使用しながら、ほぼリアルタイムのデータと過去のデータの両方を提供できるようになりました。
次に、SQL ベースの Looker の再利用可能モデリング言語である LookML を使ってデータをモデリングし、Looker ダッシュボードと Explore を使ってデータを消費しました。Looker はデータベースに直接クエリを実行するため、レポートは BigQuery に保存されているほぼリアルタイムのデータを反映したものになります。最後に、ほぼリアルタイムの可用性と全体の消費コストのバランスを取るために、主要なユースケースを状況ごとに分析し、リソースの使用量を最適化しました。
このソリューションにより、2 つの異なるツールを維持する必要がなくなり、よりスケーラブルなアーキテクチャを実現できました。GCP のサービスと BigQuery の使用により、ほぼリアルタイムでデータの可用性を確保する堅牢なデータ アーキテクチャを設計できました。
独自のデータ プロデューサー モデルでデータをストリーミング: API から BigQuery まで
新しいデータ ストリームを利用できるようにするために、「データ プロデューサー モデル」(Modelo Productor de Datos、略して MPD)と呼ばれるプロセスを設計しました。このプロセスでは、機能ビジネス チームが、データ ストリームを生成して「データ ドメイン」と呼ばれる関連情報資産として公開することを担当するデータ クリエイターの役割を果たすことができます。このプロセスによって、新しいデータが JSON 形式で取り込まれ、それが BigQuery にストリーミングされます。そして、その JSON を 3 階層の変換プロセスによって、パーティション化されたカラム型構造に変換します。
これらの新しいデータセットを Looker で探索できるようにするため、LookML の開発を加速し、開発者がパイプラインをより楽しみながら作成できるようになる Java ユーティリティ アプリを開発しました。
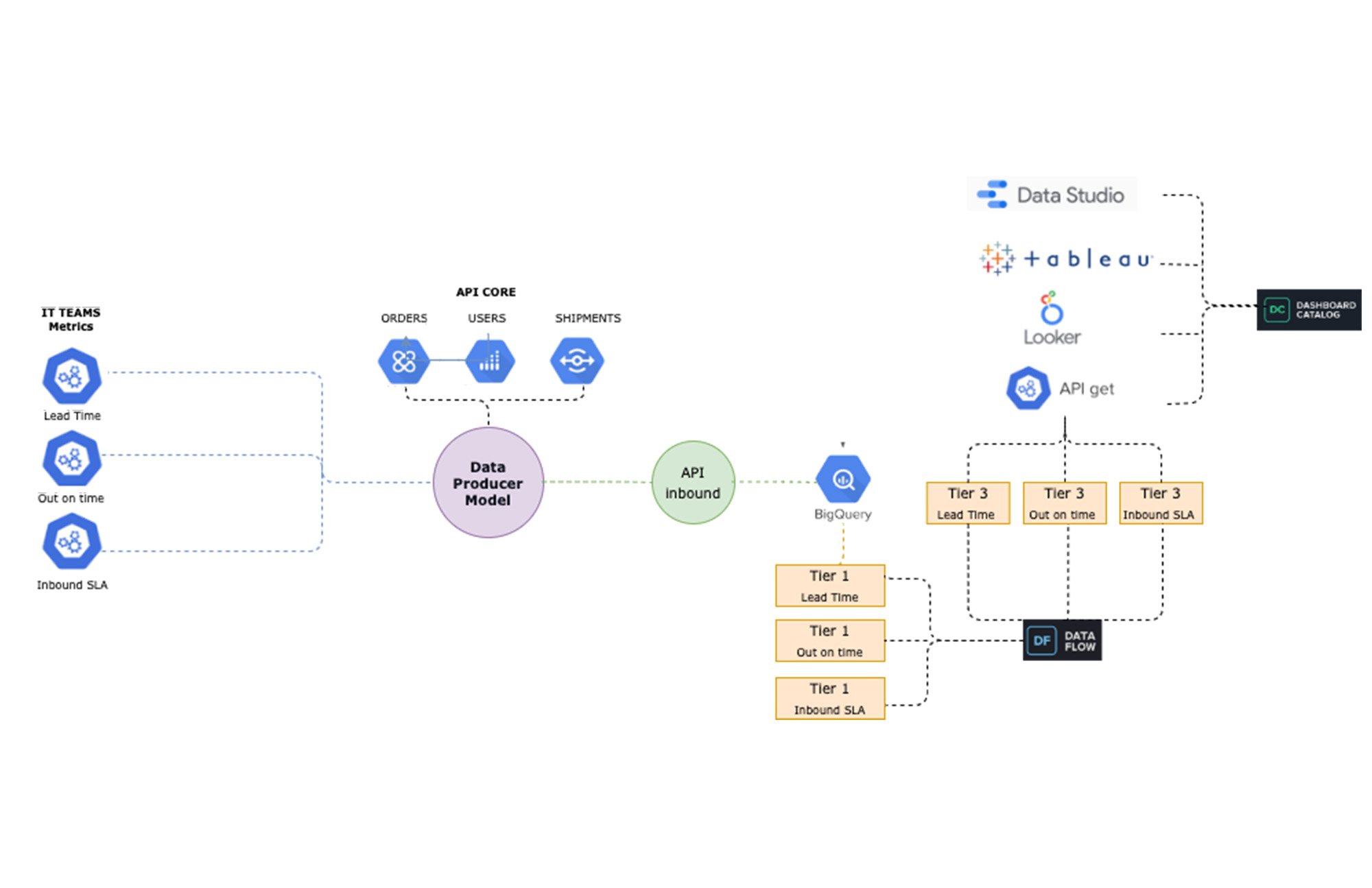
完成した「MPD」ソリューションにより、最小限の手作業で BigQuery に異なるエンティティを作成できるようになりました。このプロセスを使用して、以下が自動化されています。
JSON のサンプルからの BigQuery でパーティション化されたカラム型テーブルの作成
別の GCP BigQuery プロジェクトでの承認済みビューの作成(管理目的)
Looker ビュー用の LookML コード生成
選択された時間枠でのジョブ オーケストレーション
このコードベースの段階的なアプローチを LookML で使用することで、CI プロセスの一環として Lams を使って LookML の構文を検証したり、本番環境に移る前に Spectacles を使ってすべての定義とデータをテストしたりするなど、ソフトウェア開発の DevsOps で従来使用されてきた手法を取り入れることができました。これらの原則をデータおよびビジネス インテリジェンスのパイプラインに適用することで、継続的なインテリジェンスのエコシステムが強化されました。Looker を使ってデータを探索し、ユーザーが簡単に独自のビジュアリゼーションを作成できるようになったことで、ビジネス全体で関係者とのエンゲージメントを強化できるようになりました。
新しいデータ アーキテクチャとプロセスを導入したことで、拡大し続ける配送オペレーションからの、増大し常に変化するデータに対応できるようになりました。さまざまなチームがシームレスにソリューションを開発し、サードパーティのテクノロジーを管理できるようになったことで、常に何が起きているかを把握し、さらに重要なこととして、必要なときにタイムリーな仕方で対応できるようになりました。
配送オペレーションの改善による成果:
今日、データは、以下のような重要なプロセスにおける意思決定の支援に活用されています。
運送業者の輸送能力の最適化
アウトバウンドのモニタリング
航空輸送能力のモニタリング
このデータドリブンなアプローチは、配送予定に従って時間どおりに荷物を受け取ることを期待するすべての人に、より質の高いサービスを提供するのに役立ちます。2022 年第 1 四半期には、配送品目の 79% を 48 時間以内に納品するなど、カバレッジとスピードの両方を向上させることができました。
ここからは、当社が日々の意思決定を支えるために利用しているデータ資産をご紹介します。
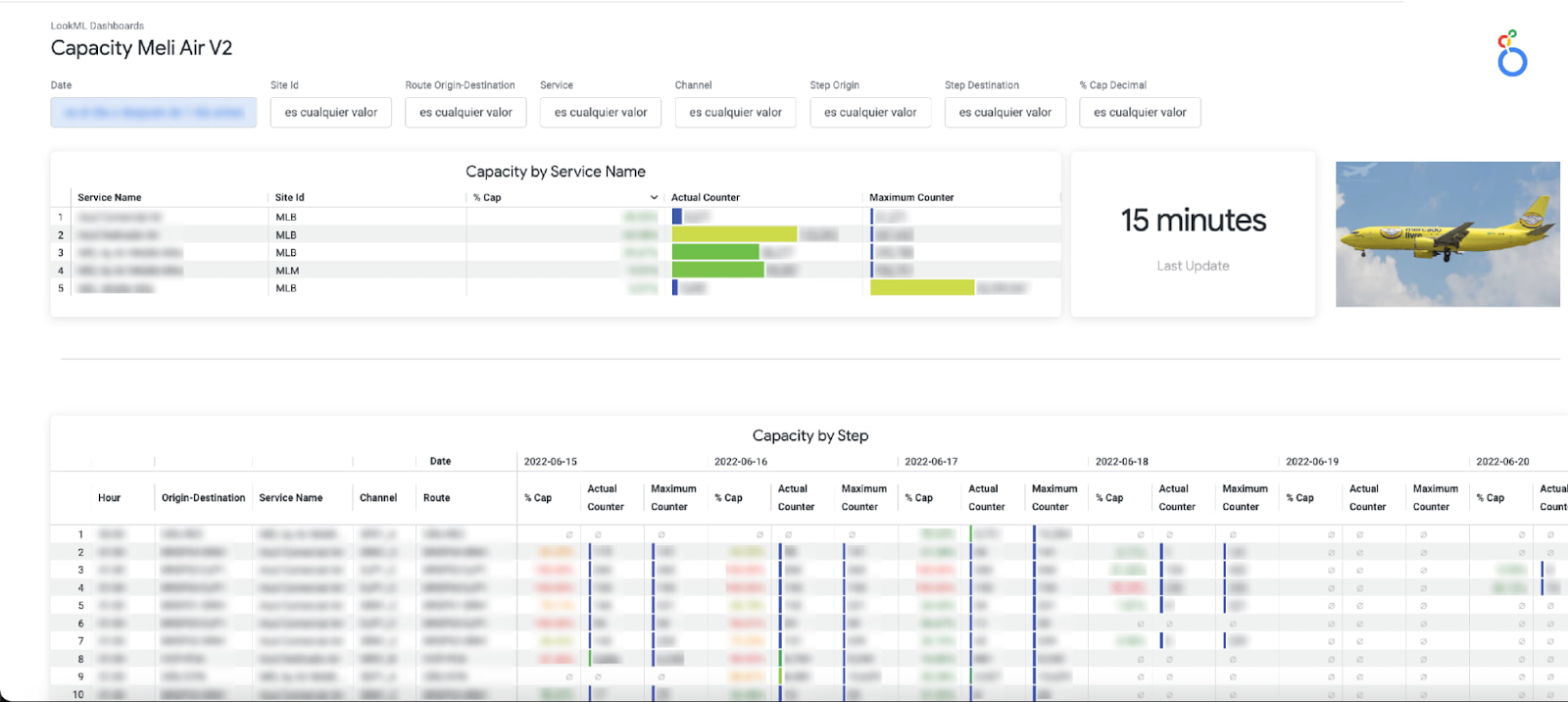
a. 運送業者の輸送能力: 各配送ゾーン全体で利用できるネットワーク輸送能力の使用率をモニタリングし、配送目標の達成が困難になっている場所をほぼリアルタイムで特定できます。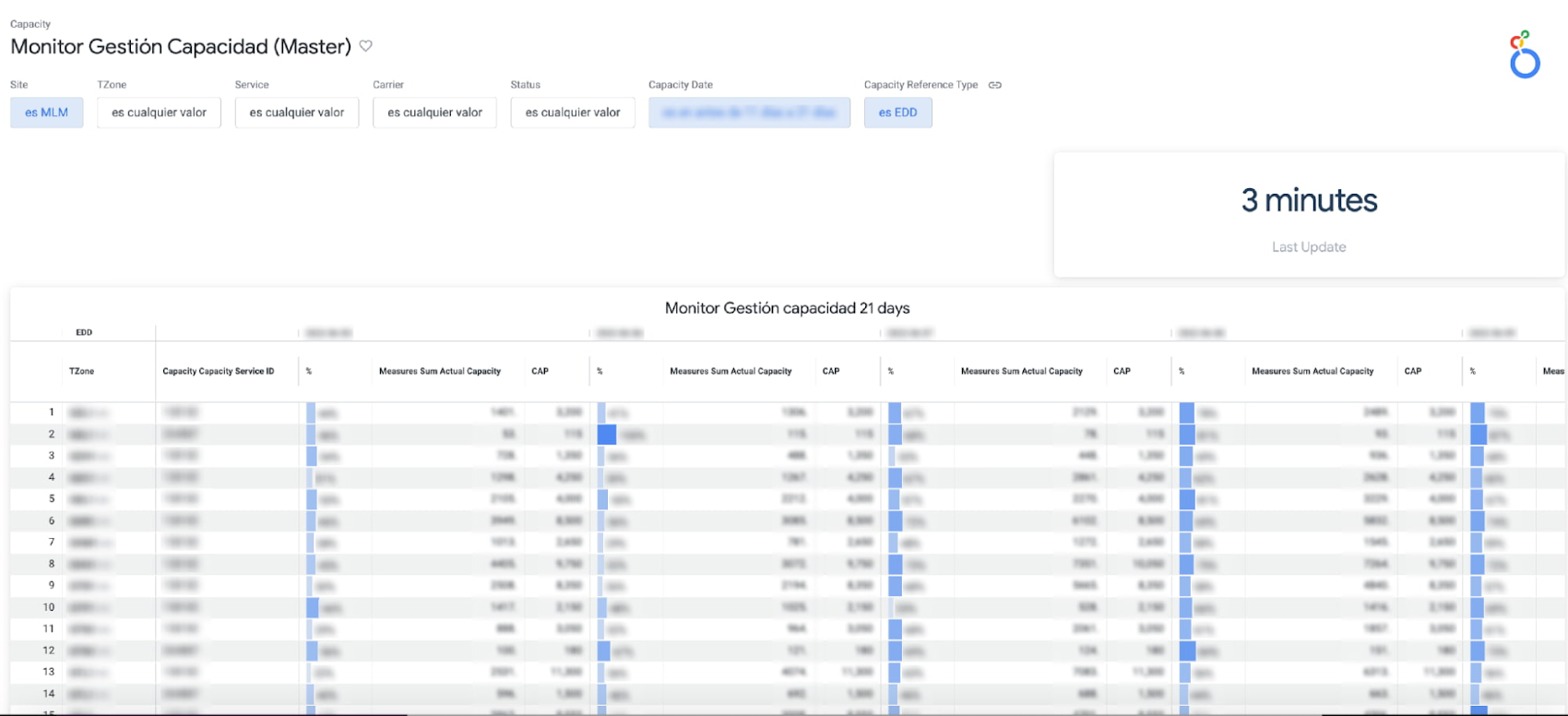
b. アウトバウンド プレイスのモニタリング: 特定の場所(販売者が荷物を受け取る物理的な地点)宛ての配送数を集約し、配送効率が低い場所を識別するとともに、個々の配送状況を調べることができます。
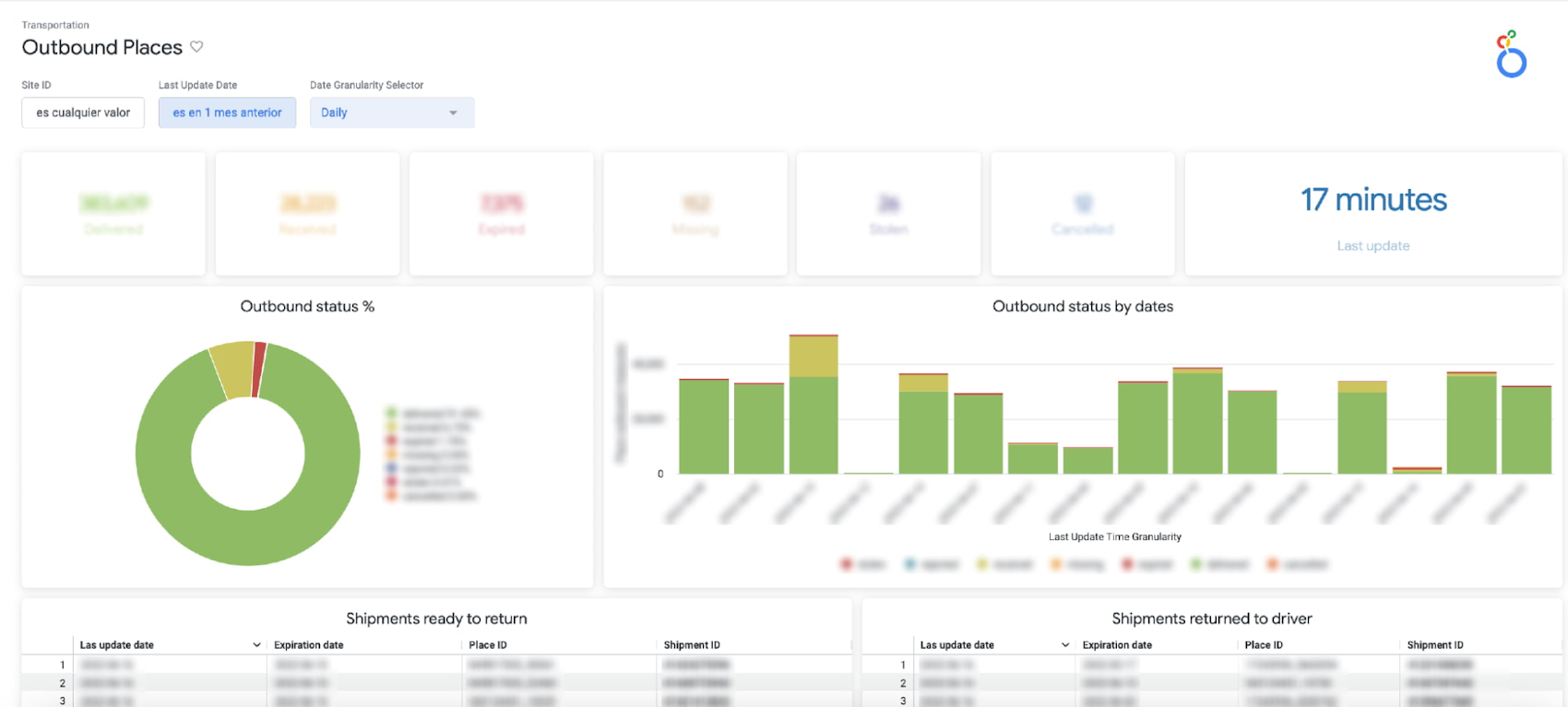
c. 航空輸送能力のモニタリング: 各航路を運航する航空機の輸送能力の利用状況をモニタリングします。
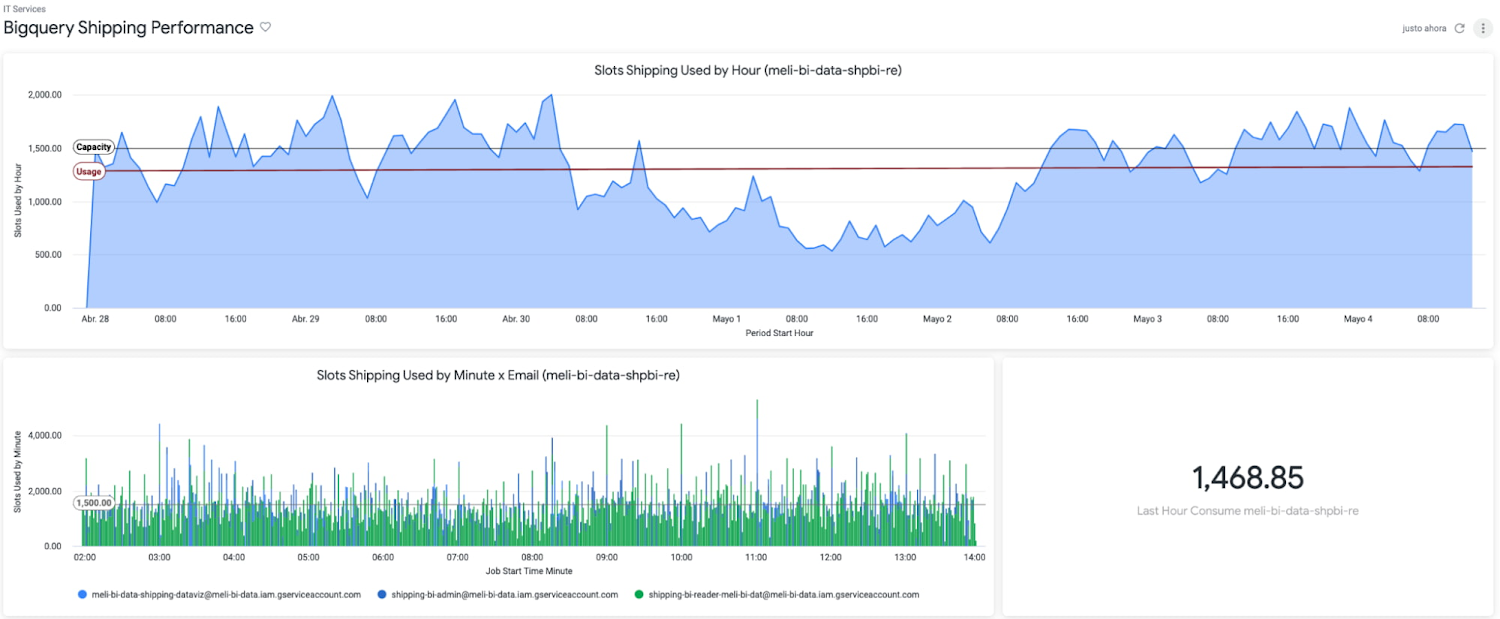
コストの計算
BigQuery と Looker の組み合わせにより、システム全体のコストとパフォーマンスという、以前には見えなかったものが見えるようになりました。従来、開発者は信頼性や稼働時間といった指標を重視し、関連するコストは考慮に入れませんでした。
BigQuery の情報スキーマ、Looker Blocks、BigQuery ログのエクスポートを利用することで、データ消費を詳細に追跡し、パフォーマンスの低い SQL やエラーを素早く検出し、使用量と費用の最適化調整を行えるようになりました。
これに基づいて、Looker Shipping Ops ダッシュボードでは 150 以上のクエリが同時に生成され、BigQuery と Looker のキャッシュ ポリシーを活用して最適化できるようになりました。
今後の課題
BigQuery と Looker を使用することで、データの可用性とデータ管理に関する多くの課題を解決できました。これには主要なものだけでも、ほぼリアルタイムのデータと過去の情報への単一ポイント アクセス、異なる国やタイムゾーン全体でのオペレーションや関係者のためのセルフサービス分析と調査、水平方向のスケーラビリティ(メンテナンス不要)、信頼性と稼働時間の保証(コストも考慮に入れる)などがあります。
ただし、適切な技術スタックとプロセスを導入することに加え、すべてのユーザーがこの管理され信頼できるデータを使用して意思決定を行えるようにする必要があります。ビジネス目標を達成し続けるには、データへのアクセスだけでなく、データに意味を与える定義へのアクセスも浸透させる必要があります。つまり、データ定義を社内のデータ カタログに組み込み、LookML の定義をデータポータルや Tableau、さらには Google スプレッドシートや Google スライドといった他のデータ可視化ツールに提供し、ユーザーが使い慣れたツールでデータを扱えるようにする必要があります。
私たちが「データ プロデューサー モデル(Modelo Productor de Datos、略して MPD)」と呼んでいる自社設計プロセスによって、新しいデータ ストリームを利用できるようにした方法について詳しくは、8 月 31 日のウェブキャストに登録のうえご参加ください。
新しいテクノロジーを学び、採用するのは挑戦となりますが、好奇心が旺盛で起業家精神にあふれた企業文化により、私たちはこの次なるフェーズへの取り組みを楽しみにしています。ユーザーも期待してくださっていることと思います。当社のチームが新しい挑戦に対応する準備ができているのか、新しいプロセスや設計を展開できるのかについては、次回の投稿で詳しくご説明します。
- Mercado Libre、データ & 分析シニア マネージャー Pablo Fernández Osorio 氏

