Bigtable を使った Google による広告のパーソナライズのスケーリング
Google Cloud Japan Team
※この投稿は米国時間 2022 年 9 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
Cloud Bigtable は、Google Cloud で広く使われている人気の Key-Value データベースです。このサービスは、スケーリングの弾力性、コスト効率、卓越したパフォーマンス特性、可用性 99.999% の SLA を提供します。その結果、大規模な導入が進み、何千ものお客様が Bigtable を信頼してさまざまなミッション クリティカルなワークロードを実行しています。
Bigtable は、15 年以上にわたって Google の本番環境で使われ続けています。10 エクサバイト以上のデータを管理下に置き、ピーク時には毎秒 50 億以上のリクエストを処理しており、Google で最も大型の半構造化データ ストレージ サービスの一つにあたります。
Google での Bigtable の主なユースケースの一つは、広告のパーソナライズです。この投稿では、広告のパーソナライズに関して Bigtable が果たす中心的な役割について説明します。
広告のパーソナライズ
広告のパーソナライズは、注目のトピックや関連のある広告コンテンツを提示することで、ユーザー エクスペリエンスを改善することを目指します。たとえば、私は YouTube でパン作りの動画をよく視聴します。広告設定で「広告のカスタマイズ」が有効になっている場合、私が興味のあるトピックはパン作りで、パン作りグッズに関連した広告コンテンツに関心を示しうることが、閲覧履歴から YouTube に伝達される可能性があります。
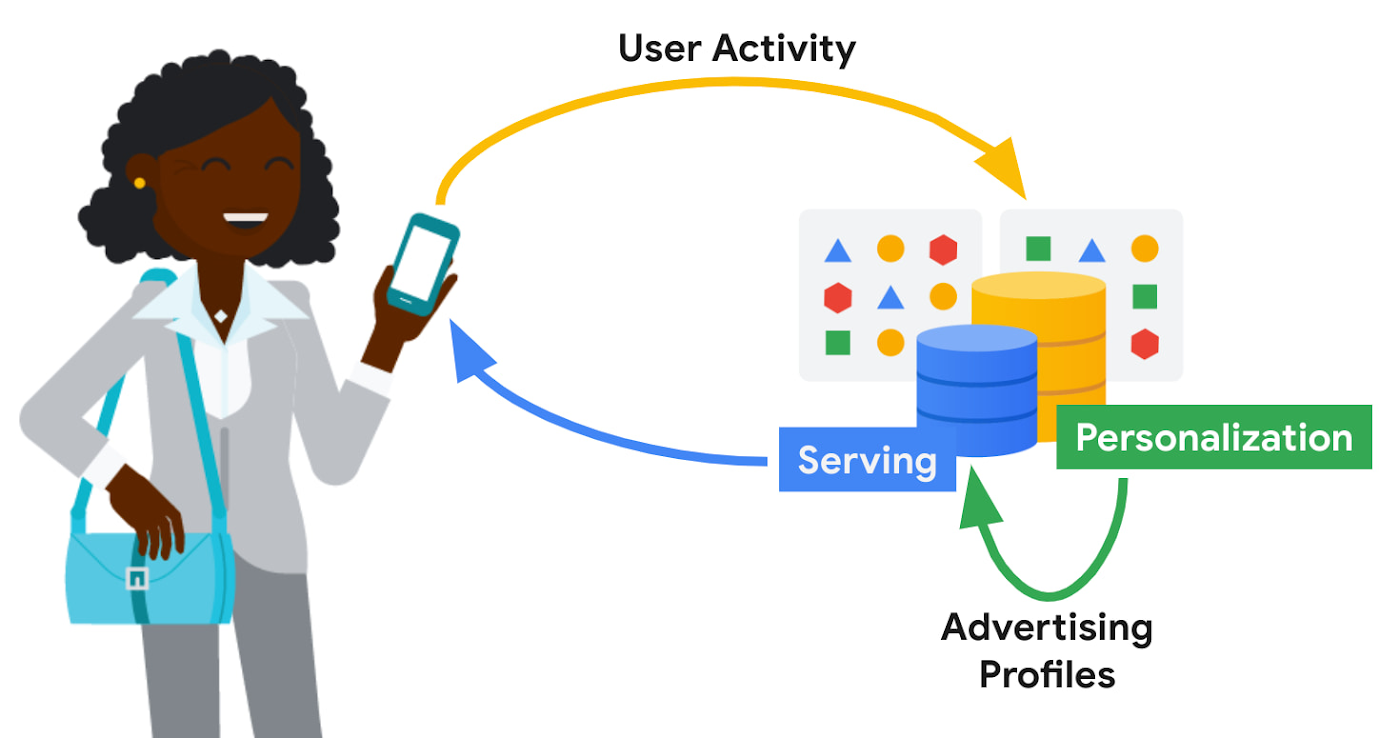
広告のパーソナライズには、ユーザーデータの処理と保持を厳密に制御して適時にパーソナライズするために、ほぼリアルタイムでの大規模なデータ処理が求められます。どの広告コンテンツを取得して提供するかを決定する時間枠が短いため、高いシステム可用性と、サービス提供における低いレイテンシが必要です。最適とはいえないサービス提供の決定(汎用的な広告コンテンツへのフォールバックなど)は、ユーザー エクスペリエンスに影響を与える可能性があります。経済面では、広告のインフラストラクチャにかかる費用を可能な限り抑えることが求められます。
Google の広告パーソナライズ プラットフォームは、広告コンテンツの関連付けとランク付けのための機械学習モデルを開発してデプロイするフレームワークを提供します。このプラットフォームでは、リアルタイムとバッチの両方のパーソナライズがサポートされています。Bigtable を使って構築されているため、他の Google プロダクトは、プライバシー規定とポリシーを遵守しつつパーソナライズに必要なデータソースに安全にアクセスできます。その間、どのデータを Google に提供するかというユーザーの決定は常に尊重されます。
広告プロファイルなどのパーソナライズ パイプラインからの出力は、その後の使用に備えて Bigtable に保存されます。広告配信スタックがこれらの広告プロファイルを取得して、次の広告配信の決定に活用します。
パーソナライズ プラットフォームのストレージ要件には、以下があります。
バッチおよびリアルタイムに近いパーソナライズのための、非常に高いスループットでのアクセス
広告配信において重要なパスでの読み込みのための、低レイテンシ(99 パーセンタイルで 20 ミリ秒未満)の検索
パーソナライズの遅延を低減するための、広告モデルの高速(数秒程度)の増分更新
Bigtable
オフラインでのパーソナライズのための低コスト、高スループットのデータアクセスだけでなく、オンライン データ処理向けの一貫した低レイテンシのアクセスもサポートする Bigtable の汎用性は、まさに広告ワークロードに最適です。
Google 規模のパーソナライズには、非常に大規模なストレージ フットプリントが必要です。一定のパフォーマンスを保つために備わった Bigtable のスケーラビリティ、パフォーマンスの一貫性、コストの低さは、このようなパーソナライズ ワークロードの主な差別要因となっています。
データモデル
パーソナライズ プラットフォームは、Object ID をキーにシリアル化された protobufs として Bigtable にオブジェクトを保存します。一般的なデータサイズは 1 MB 未満で、サービス提供のレイテンシは 99 パーセンタイルで 20 ミリ秒未満です。
データは、データの各カテゴリに対応したコーパスとして整理されます。コーパスはレプリケートされた Bigtable にマッピングされます。
コーパス内で、データはデータの論理グループである DataType として整理されます。広告プロファイルの特徴、エンベディング、種類が DataType として保存され、Bigtable の列ファミリーにマッピングされます。DataType は、データおよびその所有権と来歴を示す追加メタデータの proto 構造を説明するスキーマで定義されます。SubType は Bigtable の列にマッピングされ、自由形式です。
データの各行は RowID によって一意に識別されます。RowID は Object ID に基づきます。パーソナライズ用の API は、RowID(行キー)、DataType(列ファミリー)、SubType(列パート)、Timestamp で個別の値を識別します。
一貫性
運用のデフォルトの整合性モードは、結果整合性です。このモードでは、ユーザーに最も近い Bigtable レプリカからのデータが取得され、中央値レイテンシとテール レイテンシが最も低くなります。
1 つの Bigtable レプリカの読み取りと書き込みには、整合性があります。リージョン内に Bigtable のレプリカが複数ある場合、リージョン間のトラフィックの溢れが発生しやすくなります。read-after-write の整合性を高めるため、パーソナライズ プラットフォームは行のアフィニティという概念を採用しています。リージョン内に複数のレプリカがある場合、Row ID のハッシュに基づいて、任意の行に 1 つのレプリカが優先して選択されます。
厳密な整合性が求められる検索の場合、プラットフォームはまず最も近いレプリカの読み込みを試み、各レプリカの最新の低ウォーターマーク(LWM)を返すよう Bigtable に要求します。最も近いレプリカが元々の書き込みが行われたレプリカの場合、またはレプリケーションが必要なタイムスタンプに追いついたことが LWM から示される場合、サービスは一貫した応答を返します。レプリケーションが追いついていない場合、サービスは 2 回目の検索を実行します。このときの対象は、元々書き込みが行われた Bigtable レプリカですが、そのレプリカが離れていてリクエストが遅くなる可能性があります。応答を待っている間、他のレプリカでレプリケーションが追いついた場合に備え、プラットフォームはこれらのレプリカにフェイルオーバー検索を実行することがあります。
Bigtable のレプリケーション
広告のパーソナライズ ワークロードでは、四大陸に分散する 20 以上のレプリカを含む Bigtable レプリケーション トポロジを使います。
レプリケーションは、広告配信の高可用性ニーズに対処するうえで効果的です。Bigtable のゾーンの各月の稼働率は 99.9% を超え、マルチクラスタ ルーティング ポリシーとレプリケーションを組み合わせると可用性は 99.999% を超えます。
世界中に広がるトポロジによって、ユーザーに近いデータ配置が可能になり、サービス提供のレイテンシを最小限に抑えられます。ただし、ネットワーク リンク費用やスループットの変動といった課題も付きものです。Bigtable では、最小全域木ベースのルーティング アルゴリズムと帯域幅を節約するプロキシ レプリカを採用して、ネットワーク費用を抑えています。
広告のパーソナライズでは、Bigtable のレプリケーションの遅延を減らすことが、パーソナライズの遅延(ユーザーのアクションから、そのアクションが広告モデルに組み込まれてユーザーに関連広告が表示され始めるまでの時間)を減らすための鍵となります。レプリケーションは速い方が望ましいですが、レプリケーション トラフィックとサービス処理トラフィックのバランスをとり、低レイテンシのユーザーデータ処理がレプリケーション トラフィックの送受信フローによって阻害されないようにすることも大切です。グローバルなトラフィック フローを管理し、サービス トラフィックとレプリケーション トラフィックの優先度のバランスをとるために、Bigtable には複雑なフロー制御と優先度ブーストの仕組みが導入されています。
ワークロードの分離
任意のワークロード セットを特定のレプリカに固定することで、広告のパーソナライズのバッチ ワークロードはサービス ワークロードから分離されています。つまり、一部の Bigtable レプリカはパーソナライズ パイプラインのみを処理し、他のレプリカはユーザーデータの処理を行います。このモデルによって、サービス システムとオフラインのパーソナライズ パイプラインの間で継続的かつほぼリアルタイムのフィードバック ループが実現すると同時に、これら 2 つのワークロードの競合を回避できます。
Cloud Bigtable ユーザーの場合、AppProfiles とクラスタルーティング ポリシーを使えば、特定のレプリカにワークロードを制限して固定することによって簡易的な分離を実現できます。
データ所在地
デフォルトでは、世界中に分散していることも多いレプリカすべてにデータが複製されるため、一部のリージョンでのみアクセスされるデータの場合は、無駄が多くなります。そこで、アクセスの可能性が最も高いリージョンにデータを制限するリージョン指定によって、ストレージとレプリケーションの費用を抑えられます。また、特定の内容に関するデータを一定の地理的エリア内に物理的に保管することを定めた規制を遵守していることも重要です。
データのロケーションは、リクエストのアクセス場所によって暗黙的に決めることも、位置情報メタデータや他の製品シグナルを通じて決定することも可能です。あるユーザーのデータ ロケーションが決まると、読み取りリクエストの転送先の Bigtable レプリカを指す位置情報メタデータ テーブルに保存されます。ダウンタイムやサービス提供のパフォーマンス低下を生じさせることなく、行配置ポリシーに基づくデータ移行がバックグラウンドで行われます。
まとめ
この投稿では、広告のパーソナライズ用のユーザー インテントのモデル化という重要なユースケースをサポートするために、Google 内でどのように Bigtable を使っているかを説明しました。
この 10 年間、桁違いに拡大する Google のパーソナライズ ニーズに合わせて、Bigtable も拡張してきました。Bigtable は大規模なパーソナライズ ワークロード向けに、優れたパフォーマンス特性を備えた低コストのストレージを提供します。シンプルなユーザー構成で、グローバルなトラフィック フローをシームレスに処理します。低レイテンシのサービスと高スループットのバッチ演算の両方を簡単に処理できるので、ラムダスタイルのデータ処理パイプラインにうってつけです。
今後も、Bigtable をパーソナライズ ワークロードにさらに適した選択肢にするために、高水準の投資を続けてコストを抑え、パフォーマンスを改善し、新機能を追加していきます。
その他のリソース
Bigtable の利用を開始するには、Qwiklab でお試しください。製品について詳しくは、こちらをご覧ください。
謝辞
貴重なフィードバックと提案を提供してくれた Ashish Awasthi、Ashish Chopra、Jay Wylie、Phaneendhar Vemuru、Bora Beran、Elijah Lawal、Sean Rhee をはじめとする Google 社員に感謝します。
- Bigtable 担当エンジニアリング マネージャー、Sudarshan Kadambi
- 広告のパーソナライズ インフラストラクチャ担当エンジニアリング マネージャー、Haixia Zhao
