連携してより効率的に: Cloud Composer を使用した Data Fusion パイプラインのオーケストレーション
Google Cloud Japan Team
※この投稿は米国時間 2020 年 8 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
データ分析の世界では、データから意味のある分析情報を導き出すために ETL パイプラインや ELT パイプラインが利用されます。データ エンジニアや ETL デベロッパーは多くの場合、データ プラットフォームの一部として相互に依存するパイプラインを多数構築する必要がありますが、それらのパイプラインすべてをオーケストレート、管理、モニタリングするのは非常に困難になることがあります。
そこで朗報です。このたび、豊富な Cloud Data Fusion 演算子セットを使用して、Cloud Composer で Data Fusion パイプラインをオーケストレートおよび管理できるようになりました。
新しい Cloud Data Fusion 演算子を使用すると、大量のコードを記述しなくても、Cloud Composer から Cloud Data Fusion パイプラインを簡単に管理できるようになります。演算子にいくつかのパラメータを指定するだけでパイプラインをデプロイ、開始、停止できるため、ワークフローの正確性と効率性を確保しながらも時間を節約できます。
データ パイプラインの管理
Data Fusion は、オープンソースである CDAP プラットフォームをベースに構築された、Google Cloud のフルマネージドでクラウドネイティブなデータ統合サービスです。Data Fusion を使用すると、ユーザーは直感的なグラフィカル ユーザー インターフェースを介して ETL および ELT データ パイプラインを構築し、管理できます。コーディングの障壁を取り払うことで、データ アナリストやビジネス ユーザーでもデベロッパーに加わってデータを管理できるようになります。
すべての Data Fusion パイプラインを管理するには、困難が伴う場合があります。たとえば、パイプラインをトリガーする方法とタイミングを決定するのは、言うほど簡単なことではありません。また、パイプラインを定期的に実行するようにスケジュールしたいと思っても、ワークフローが他のシステムやプロセス、パイプラインに依存していてできない場合もあるでしょう。他の条件が満たされるまでパイプラインの実行を待機する必要がある場合もよくあります。たとえば、Pub/Sub メッセージの受信、バケットへのデータの到着、あるパイプラインが他のパイプラインで出力されるデータに依存している依存パイプラインなどです。
こうした課題を解決するのが Cloud Composer です。Google の Cloud Composer は、オープンソースの Apache Airflow に基づいて構築されたフルマネージド オーケストレーション サービスで、これを使用してデータ プラットフォーム全体でこれらのパイプラインを管理できます。Cloud Composer ワークフローを構成するには、Python で有向非巡回グラフ(DAG)を作成します。DAG は特定のワークフローのタスクのコレクションを記述しますが、タスクによって実際に行われる処理を決定するのが演算子です。演算子はテンプレートのようなもので、新しい Data Fusion 演算子を使用すると、パラメータをいくつか指定するだけで、ETL / ELT Data Fusion パイプラインを簡単にデプロイ、開始、停止できます。
では、Cloud Storage バケットにファイルが届くと Composer が Data Fusion パイプラインをトリガーするユースケースを見てみましょう。
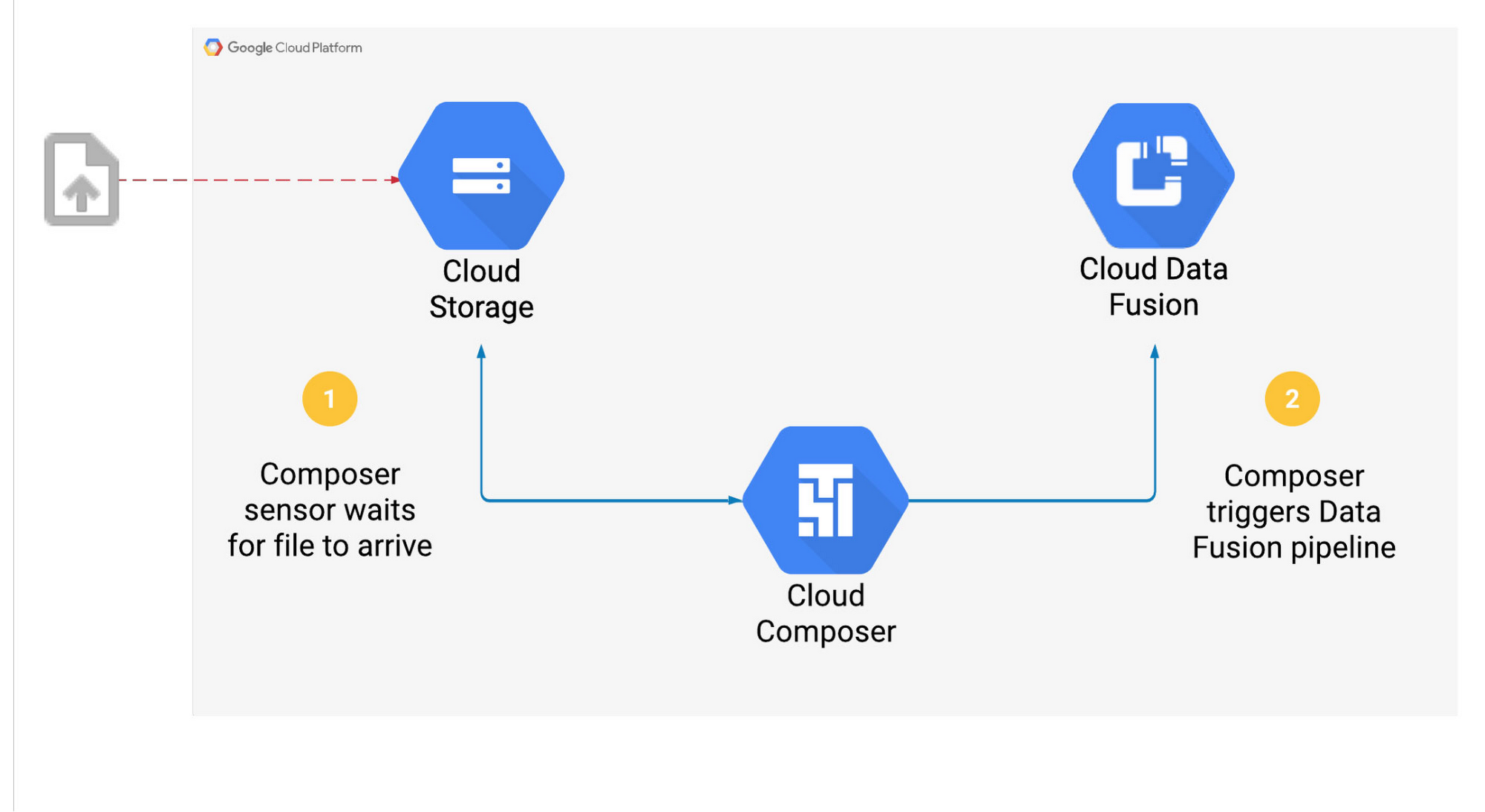
上記の手順は、Composer で一連のタスクとして実行されます。演算子がインスタンス化されると、それはワークフロー内の 1 つのタスクになります。ここでは CloudDataFusionStartPipeline 演算子を使用して、Data Fusion パイプラインを開始します。
このような演算子を使用して DAG を簡素化します。Data Fusion や CDAP API を呼び出す Python コードを記述する代わりに、パイプラインの詳細を演算子に提供します。これにより、Cloud Composer ワークフローの複雑さを軽減し、信頼性を向上させることができます。
使ってみる: パイプラインのオーケストレーション
では、このような演算子を使用してパイプラインをオーケストレートすると、実際にはどのように動作するのでしょうか。次の例では、1 つのパイプラインを開始する方法を示します。ここで示す原則を拡張して、Cloud Composer からすべての Data Fusion パイプラインを開始、停止、デプロイできるようにするのは簡単です。
デプロイするパイプラインの準備が整った Data Fusion インスタンスがあると想定して、Cloud Storage バケットにファイルがあるか確認する Composer ワークフローを作成しましょう(注: Cloud Composer DAG に詳しくない方は、こちらの Airflow チュートリアルから始めてください)。また、新しい Data Fusion 演算子の 1 つを Cloud Composer DAG に追加します。これで、このファイルが届いたときにパイプラインをトリガーして新しいファイル名をランタイム引数として渡すことができます。
Cloud Composer ワークフローを開始して実際の動作を確認
1. Cloud Storage バケットにオブジェクトが存在するか確認する
GCSObjectExistenceSensor センサーを DAG に追加します。このタスクは、開始後、オブジェクトが Cloud Storage バケットにアップロードされるのを待機します。
2. Data Fusion パイプラインを開始する
CloudDataFusionStartPipelineOperator 演算子を使用して Data Fusion でデプロイされたパイプラインを開始します。Data Fusion でパイプラインが正常に開始されると、このタスクは完了したと見なされます。この演算子に必要なパラメータの詳細については、airflow のドキュメントをご覧ください。
3. ビットシフト演算子を使用してタスクフローの順序を設定する
この DAG を開始すると、最初に gcs_sensor タスクが実行され、このタスクが正常に完了した場合にのみ、start_pipeline タスクが実行されます。
4. DAG を Cloud Composer DAG バケットにアップロードしてワークフローを開始する
これで DAG が完了しました。Cloud Composer ランディング ページから DAG フォルダへのリンクをクリックして、DAG をアップロードします。
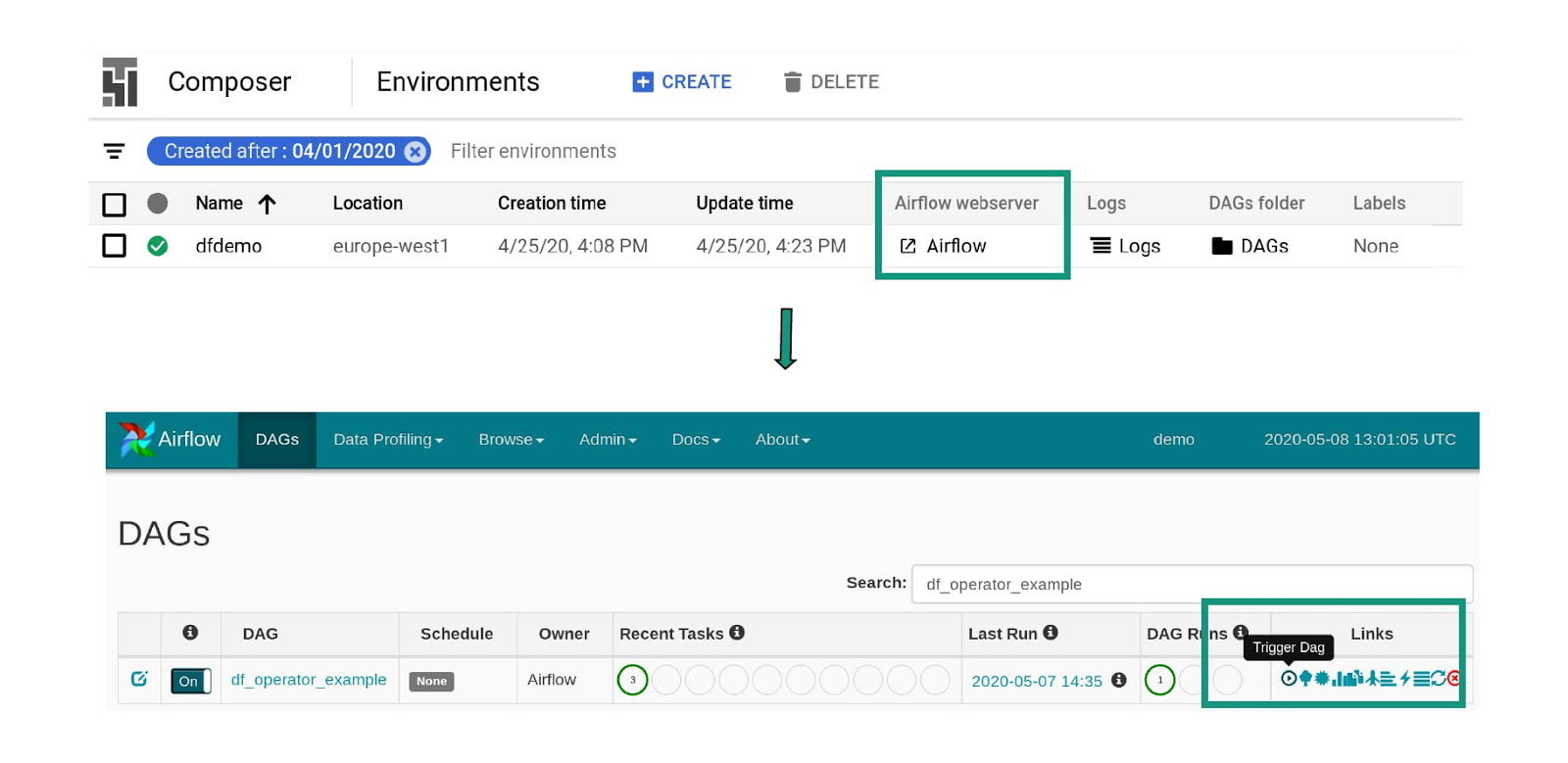
Airflow ウェブサーバーのリンクをクリックして Airflow UI を起動し、実行ボタンをクリックして DAG をトリガーします。
5. タスクを実行しています。ファイルがソースバケットにアップロードされると、Data Fusion パイプラインがトリガーされます。
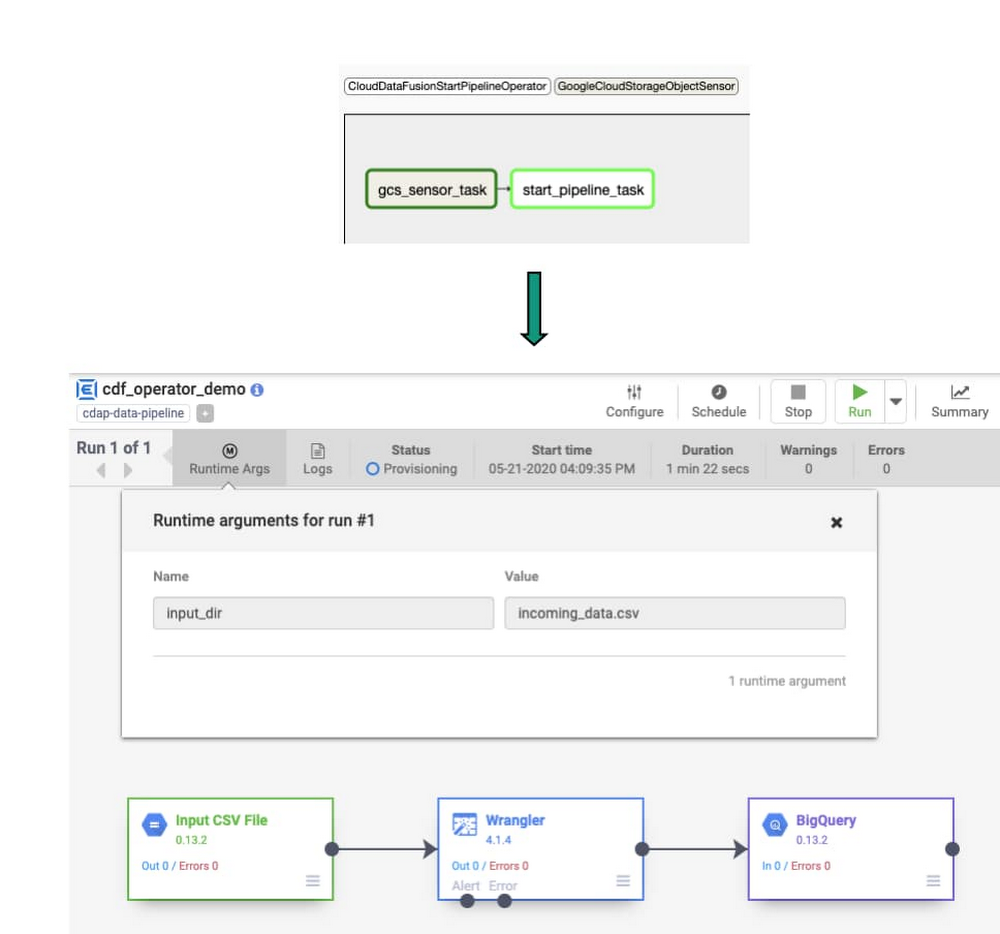
オペレーションとオーケストレーション
これで Python コードを記述して Data Fusion API を呼び出すテストを行う必要がなくなり、ワークフローの他の部分により多くの時間を費やせるようになります。これらの Data Fusion 演算子が Google Cloud ですでに利用可能な一連の演算子に追加されたことで、利便性がとても向上しました。Cloud Composer と Airflow は、BigQuery、Cloud Dataflow、Cloud Dataproc、Cloud Datastore、Cloud Storage、Cloud Pub/Sub の演算子もサポートしているため、データ プラットフォーム全体の統合を強化できます。
新しい Data Fusion 演算子を使用することで、Cloud Composer でよりシンプルで読みやすい DAG を簡単に作成できます。複雑さを軽減し、コーディングの障壁を取り除くと、組織のメンバーが ETL / ELT パイプラインを管理しやすくなります。これらの新しい演算子の詳細については、Airflow のドキュメントをご覧ください。
-戦略的クラウド エンジニア Rachael Deacon-Smith

