Dataflow データ生成ツール、Flex テンプレートを使用した合成データの生成
Google Cloud Japan Team
※この投稿は米国時間 2020 年 8 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
1 秒あたりのクエリ(QPS)が非常に多い状態で合成データを生成するのは大変手間のかかる作業です。これには、開発者がマルチスレッド化した複雑なアプリケーションのインスタンスを複数ビルドして起動することが必要です。Google Cloud は、IT チームが評価時や新しいプラットフォームへの移行時にシステムの復元力を検証する際、このような合成データの生成が必要となることが非常に多いと理解しています。そこで、その手間を軽減して合成データの生成を容易にするパイプラインを構築することにしました。
このたび、Google Cloud Pub/Sub トピックに大量の JSON メッセージを無制限に公開できる、新しい Dataflow Flex テンプレート「ストリーミング データ生成ツール」がリリースされました。このブログ投稿では、そのユースケースとテンプレートの使用方法について簡単に説明します。
Flex テンプレート
ストリーミング データ生成ツール テンプレートの機能についての詳しい説明に入る前に、まずは Dataflow テンプレートの概要を見てみましょう。
Dataflow テンプレートの主な目的は、さまざまなチャネル(UI / CLI / REST API)で実行でき、さまざまなチームが使用できる再利用可能なアーティファクトの形式で Dataflow パイプラインをパッケージ化することです。初期バージョンのテンプレート(従来のテンプレートと呼びます)では、パイプラインが Google Cloud Storage にステージングされており、Google Cloud Console、gcloud コマンドライン ツール、または Cloud Scheduler や Cloud Functions などの他のクラウドネイティブ Google Cloud サービスから起動できました。
ただし、従来のテンプレートには次のような制限がありました。
- Dynamic DAG に対応していない
- ランタイム パラメータのサポートに不可欠な ValueProvider インターフェースが実装されていない I/O が多い
Flex テンプレートではこれらの制限が解消されています。Flex テンプレートは、アプリケーションの依存関係などの Dataflow パイプライン コードを Docker イメージとしてパッケージ化し、そのイメージを Google Container Registry(GCR)にステージングします。GCR イメージのパスとパラメータの詳細を参照するメタデータ仕様ファイルが作成され、Google Cloud Storage に保存されます。ユーザーは、さまざまなチャネル(UI、gcloud、REST)を介してその仕様ファイルを参照することで、パイプラインを呼び出すことができます。その背後では、Flex テンプレート ランチャー サービスが、ユーザーによって指定されたパラメータを使用して Docker コンテナを実行します。
ストリーミング データ生成ツールの概要
ストリーミング データ生成ツール テンプレートを使用すると、ユーザーが指定したスキーマに基づいて、指定されたレート(1 秒あたりのメッセージ数で測定)で Google Cloud Pub/Sub トピックに仮の JSON メッセージを公開できます。パイプラインで使用される JSON データ生成ツール ライブラリは、さまざまな faker 関数をサポートしており、これらをスキーマ フィールドに関連付けることができます。パイプラインはさまざまな構成パラメータをサポートしており、メッセージ スキーマの指定、1 秒あたりに公開されるメッセージ数(すなわちQPS)の指定、自動スケーリングの有効化などを行うことができます。パイプラインの手順を以下に示します。

パイプラインは、ストリーミング パイプラインの消費率を評価し、目的のパフォーマンスを満たすために必要なリソース(ワーカー数 / マシンタイプ)を判断することを主目的として使用します。
パイプラインの起動
パイプラインは Cloud Console、gcloud コマンドライン ツール、または REST API から起動できます。
Cloud Console からの起動:
1. Cloud Console の [Dataflow] ページに移動します。
2. [テンプレートからジョブを作成] をクリックします。

3. [Dataflow テンプレート] プルダウン メニューから [Streaming Data Generator] を選択します。
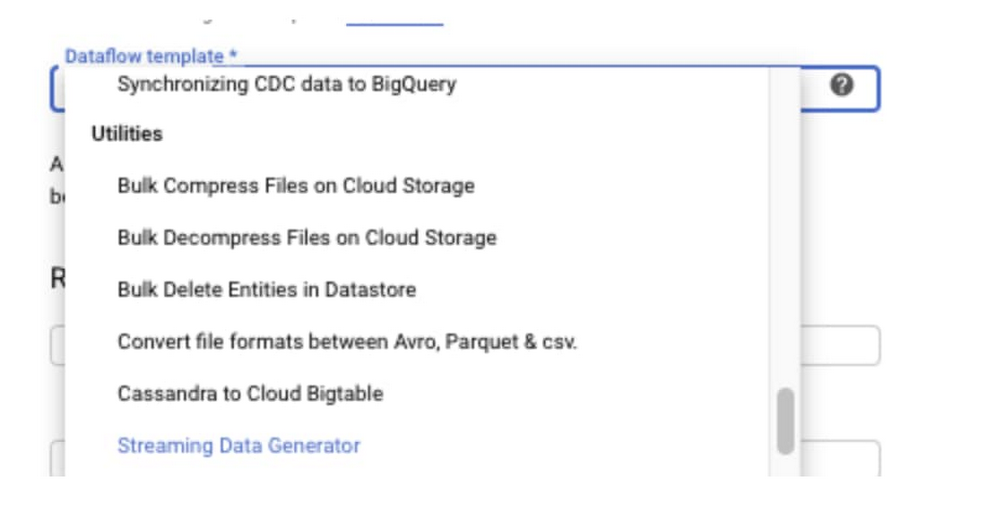
4. ジョブ名を入力します。
5. 次のように必要なパラメータを入力します。
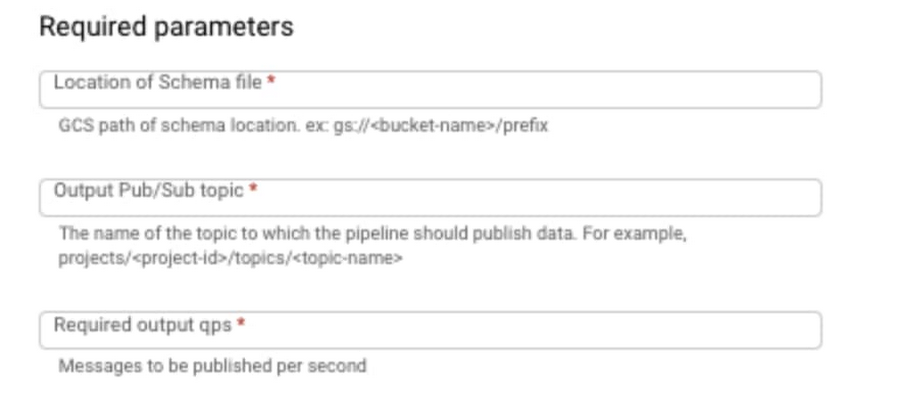
6. 必要に応じて、autoscalingAlgorithm や maxNumWorkers などのオプションのパラメータを入力します。
7. [ジョブを実行] をクリックします。
gcloud コマンドライン ツールを使用して起動するには、次のように入力します。
REST API を使用して起動するには:



