Dataproc Metastore: アルファ版テスト用にフルマネージドの Hive メタストアの利用が可能に

Google Cloud Japan Team
※この投稿は米国時間 2020 年 7 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
本日は、Google Cloud のスマート アナリティクス プラットフォーム向けの新しいデータレイク ビルディング ブロック、Dataproc Metastore をご紹介します。Dataproc Metastore は高可用性と自動修復機能を備えたオープンソースのフルマネージド Apache Hive メタストア サービスで、このサービスを利用すれば、Google Cloud 上にデータレイクを構築しているユーザーにとってメタデータの技術的な管理が容易になります。Dataproc Metastore を使えば、次のようなユースケースで完全なサーバーレス オプションを選択できるようになります。
- Apache Spark、Apache Hive、Presto などのオープンソース エンジンで実行しているさまざまな Dataproc エフェメラル クラスタ間で共有できる一元化メタデータ リポジトリ
- Data Fusion を使うオープンソース テーブルとコーディング不要な ETL / ELT 間でのメタデータのブリッジ
- Google Cloud 全体にわたるオープンソース テーブルの統合ビュー(Dataproc のようなクラウド ネイティブなサービスと Google Cloud で提供されている他のさまざまなオープンソース ベースのパートナー サービスとの相互運用性を実現)
Dataproc Metastore の使用を今すぐ開始するには、こちらから、Google Cloud のアルファ版プログラムに参加してください。
Hive メタストアを使うメリット
Dataproc を使うメリットは何と言っても、完全構成済みかつ自動スケーリングの Hadoop および Spark クラスタを約 90 秒で作成できるという点です。このようにすばやく作成できるうえ、コンピューティング プラットフォームが柔軟なことから、クラスタ作成とジョブ処理を 1 つのエンティティとして扱うことが可能になります。ジョブが完了すると、クラスタを終了できるので、ジョブの実行に必要な Dataproc リソースに対してのみ料金が発生します。ただし、こうしたジョブで作成したテーブルに関する情報(メタデータ)は、クラスタとともに破棄できるものであるとは限りません。ジョブ間のテーブル情報を保存しておいたり、他のクラスタや処理エンジンにメタデータを使ったりする場合も考えられます。
データレイクでオープンソース テクノロジーを使用している場合、信頼できるメタストアとしてビッグデータの処理用に Hive メタストアをすでに利用したことがあるかもしれません。Hive メタストアは、オープンソースのデータシステムがデータ構造を共有するために使用するメカニズムとして標準化されています。次の図は、Hive メタストアを中心にすでに構築されているエコシステムの一部を示しています。
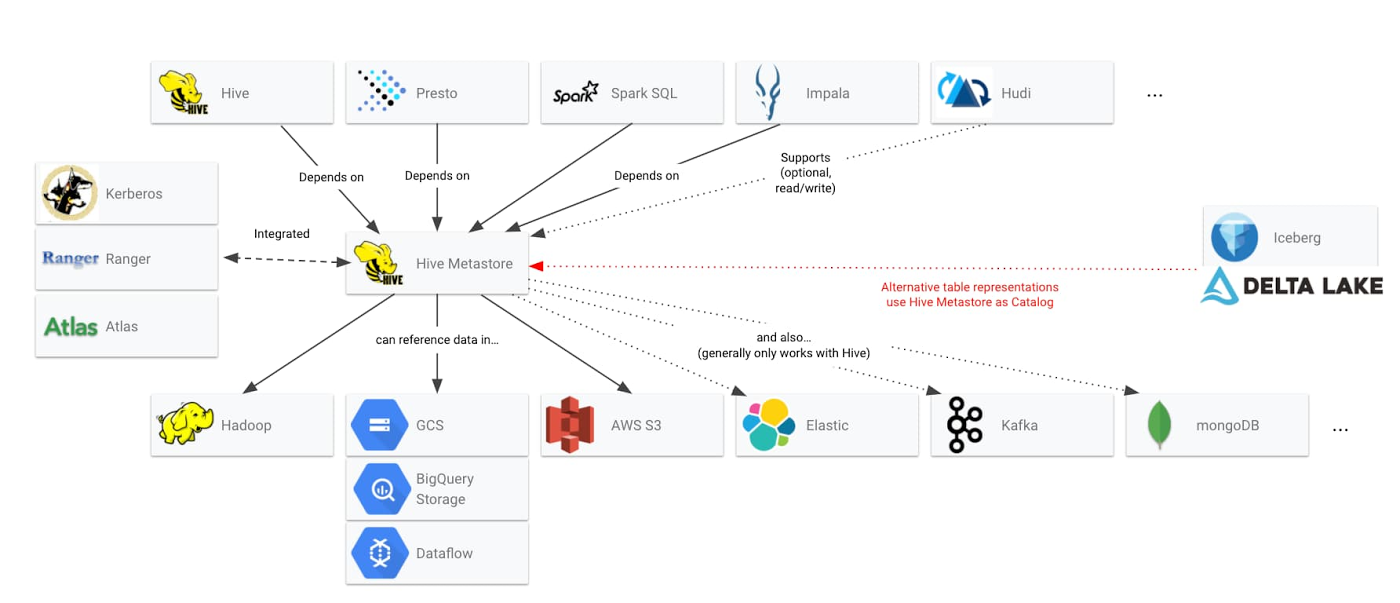
しかしながら、Google Cloud 上でデータレイクを実行する必要のあるユーザーの場合、これと同じ Hive メタストアでは移行への妨げになってしまいかねません。最近では Dataproc のユーザーの皆様は、Cloud SQL を使って Hive メタデータをクラスタ外に保存することが多いようです。しかしこれにはいくつか問題があります。
- RDBMS Cloud SQL インスタンスを自分で管理してトラブルシューティングする必要があります。
- Hive サーバーは RDBMS から独立して管理されているため、受信接続のスケーラビリティの問題とデータベースのロックの問題が発生する可能性があります。
- CloudSQL インスタンスは、ダウンタイムがあるメンテナンスの時間枠においては単一障害点となり、継続処理が必要なデータレイクでは使うことができません。
- このアーキテクチャでは、各クラスタに JDBC への直接アクセスを提供しなければならないため、機密データを扱う際にセキュリティ リスクが生じる場合があります。
Hive メタストアをすべてのデータ処理ジョブのクリティカル パスで確実に使用できるようにするために、CloudSQL を使ったワークアラウンドよりもさらに進んで、負荷分散、自動スケーリングやインストール、また更新、テスト、バックアップなどの IaaS 高可用性レイヤの構築に多大な時間をかけるというオプションもあります。しかし、Dataproc Metastore では、この手間をすべて省き、これらをマネージド サービスの機能として提供しています。
企業のお客様から、Google Cloud のデータレイクでビジネス クリティカルなデータ ワークロードの実行を任せられる、Hive メタストアのマネージド サービスが欲しいという要望が寄せられていました。それだけでなく、多数のアプリケーションとの統合ポイントを保持し、クエリの最適化に必要なテーブルの統計情報を提供できるほか、Kerberos 認証をサポートし Apache Ranger や Apache Atlas などのツールに基づく既存のセキュリティ モデルを継続して使用できる、フルマネージドかつオープンソース ベースの Hive メタストア カタログを切望する声もありました。そのうえで、既存ソフトウェアの書き換えや、Hive メタストアの機能が制限される「互換」API が必要になる、新しいクライアント ライブラリは避けたいとのことでした。企業のお客様は、オープンソースの Hive メタストアのすべての機能を使用したいと考えているようです。
Dataproc Metastore チームはこうした要望をすべて聞き入れ、完全にサーバーレスな Hive メタストア サービスを提供できる運びとなりました。
Dataproc Metastore は、フルマネージドでスケーラビリティの高いデータ検出およびメタデータ管理サービスである、Google Cloud Data Catalog を補完するサービスです。Data Catalog では、シンプルで使いやすい検索インターフェースを使って、組織のあらゆるデータを迅速に検出、把握、管理できます。一方 Dataproc Metastore は、オープンソースのビッグデータの処理に技術的なメタデータの相互運用性を提供します。
Dataproc Metastore の一般的な使用例
一元化されたメタデータ リポジトリを使ってデータレイクを柔軟に分析
ドイツの卸売大手 METRO は e コマースのデータレイクを Google Cloud に移行したことで、日別のイベントをコンピューティング処理と照合できるようになり、インフラストラクチャの費用を 30% から 50% 削減できるようになりました。データレイクに関してこうした利点を得るには、ストレージとコンピューティングを分断することが重要です。コンピューティング クラスタからストレージ レイヤを切り離すことで、データレイクの柔軟性が改善されます。必要に応じてクラスタを増やしたり減らしたりできるだけでなく、vCPU、GPU、RAM などのクラスタ仕様を現在取り組んでいるジョブに合わせて調整できるようになります。
Dataproc ではこのような柔軟な対応を可能にする機能をすでにいくつか提供しています。
- Cloud Storage コネクタ では、Cloud Storage を Hadoop 互換ファイル システム(HCFS)として使用してクラスタからデータを取り出せます。Hadoop 分散ファイル システム(HDFS)のデータに基づくジョブは、通常、ファイル接頭辞を少し変更するだけで Cloud Storage に変換できます(HDFS と Cloud Storage の詳細についてはこちらをご覧ください)。
- ワークフロー テンプレートは、ワークフローを管理、実行するための使いやすいメカニズムを提供します。マネージド クラスタで実行する一連のジョブを指定できます。このクラスタはオンデマンドで作成され、ジョブが終了すると削除されます。
- Dataproc Hub を使えば、管理者を必要とせず Dataproc クラスタを自動で生成、破棄できる、JupyterLab で事前構成された Spark 作業環境をデータ サイエンティスト、アナリスト、エンジニア向けに提供しやすくなります。
テーブルとスキーマを共有する必要があるクラスタでは、Dataproc Metastore により、柔軟なクラスタの実現がさらに簡単になりました。さまざまな形状、サイズ、処理エンジンのクラスタは、次のように Dataproc クラスタがサーバーレスの Dataproc Metastore エンドポイントを参照するようにするだけで、同じテーブルとメタデータを安全かつ効率的に共有できます。

Dataproc Metastore と Data Fusion によるコーディング不要なサーバーレス ETL / ELT
リアルタイム データを使用してカスタマー サービスやネットワークの最適化などを改善し、時間を節約して効果的に顧客にリーチできるという評価をお客様からいただいています。データ パイプラインを構築している企業は、フルマネージド、コーディング不要で、クラウド ネイティブなデータ統合サービスである Data Fusion を使用して簡単に各種ソースからデータを取り込んで統合できます。Data Fusion は Hive ソース プラグインを提供するオープンソースのコア(CDAP)で構築されています。このプラグインを使用すると、データ サイエンティストなどのデータレイク ユーザーは構造化された分析結果を Dataproc Metastore を使って共有し、ETL / ELT デベロッパーがデータレイクのパイプラインを管理、製品化するために使用できる共有リポジトリを提供できます。
以下は、Dataproc Metastore と Data Fusion を併用することでデータ パイプラインを管理するワークフローの一例です。これにより、サーバーの実行を心配せずに元の非構造化データから構造化データ ウェアハウスに移行できます。
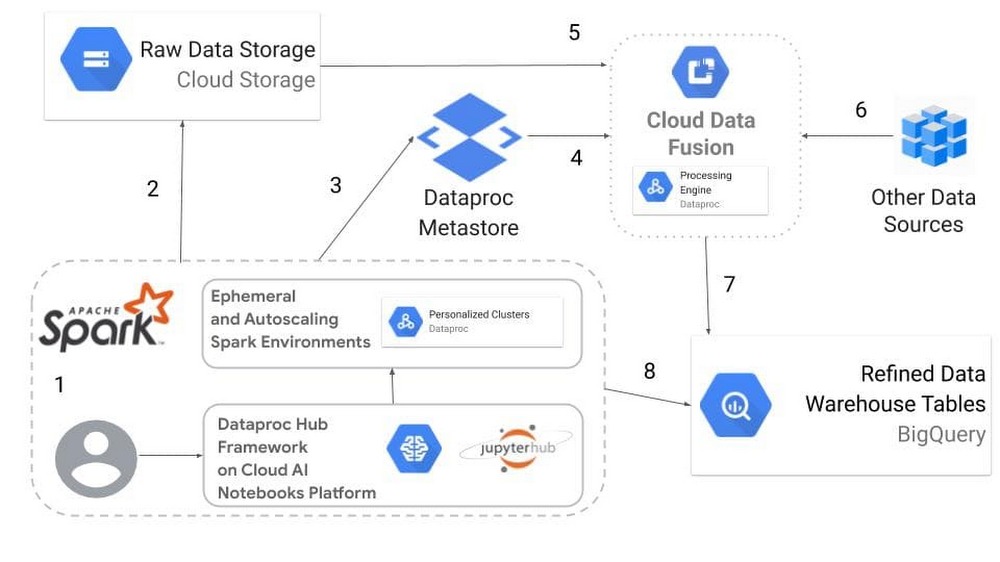
データ サイエンティスト、データ アナリスト、データ エンジニアは Dataproc Hub にログインし、Apache Spark 処理を基盤とした JupyterLab インターフェースを実行する、パーソナライズされた Dataproc クラスタを生成します。
Cloud Storage 上の元の非構造化データが分析、解釈、構造化されます。
Cloud Storage オブジェクトを構造化テーブルとして解釈する方法に関するメタデータが Dataproc Metastore に格納されるため、メタデータ情報を失うことなくパーソナライズされた Dataproc クラスタを終了できます。
Data Fusion の Hive コネクタは Dataproc Metastore で提供される Thrift URL を通じて、ノートブックで作成されたテーブルをデータソースとして使用します。
Data Fusion は Dataproc Metastore で提供される構造に従って Cloud Storage データを読み取ります。
データは他のデータソースとハーモナイズされ、データ ウェアハウス テーブルに取り込まれます。
精緻化されたデータテーブルは Google Cloud のサーバーレス データ ウェアハウスである BigQuery に書き込まれます。
BigQuery テーブルは Jupyter ノートブック上の Apache Spark で利用できるようになり、Apache Spark BigQuery Connector を使用したより詳細なデータレイク クエリと分析が可能になります。
パートナー エコシステムにより、マルチクラウドやハイブリッド データレイク全体で Dataproc Metastore のデプロイが加速
Google ではオープン クラウドに価値を置いており、Dataproc Metastore はオープンソース中心の主要パートナーを考慮して構築されています。Dataproc Metastore はオープンソースの Apache Hive Metastore と互換性があるため、メタデータの相互運用性を犠牲にせずに、Google Cloud パートナー サービスをハイブリッド データレイク アーキテクチャに統合できます。Google Cloud ネイティブ サービスとオープンソース アプリケーションは連動します。
Collibra が Dataproc Metastore でハイブリッド データレイクの可視性を提供
Dataproc Metastore と Collibra Data Catalog を統合すると、オンプレミスとクラウド データレイク全体にわたる完全なエンタープライズ規模の可視性が提供されます。Dataproc Metastore は Hive メタストアの上に構築されているため、Collibra は独自のデータ形式や API を心配することなく速やかに Dataproc Metastore に統合できました。Collibra で製品管理、カタログおよびリネージ担当バイス プレジデントを務める Chandra Papudesu 氏は、次のように述べています。「Dataproc Metastore はフルマネージドな Hive メタストアと、データセットの検出やガバナンスに関する Collibra レイヤを提供します。これは、厳格な社内外のコンプライアンス基準を満たすことを目指しているすべての企業にとって重要です。」
Qubole がデータレイク全体にわたるメタデータの単一ビューを提供
Qubole のオープン データレイク プラットフォームは継続的なデータ エンジニアリング、財務ガバナンス、分析、機械学習などのエンドツーエンドのデータレイク サービスを提供します。クラウドの管理はほとんど必要ありません。企業は Qubole を使用してマルチクラウド戦略を実施し続けているため、メタデータの一元的なビューでデータの検出とガバナンスを確保することが大切です。Qubole の製品管理ディレクターである Anita Thamas 氏は、次のように述べています。「Qubole の共同設立者は Apache Hive プロジェクトを指揮し、影響力のあるさまざまなプロジェクトや貢献者が世界中に生まれました。Qubole のプラットフォームは提供開始以来 Hive メタストアを使用しており、Google がオープン メタストア サービスを開始するようになった今、共同のお客様は機械学習、アドホック アプリケーション、ストリーミング分析アプリケーションを一元化するフルマネージドのメタデータ カタログをデプロイできる複数のオプションをご利用になれます。」
価格
アルファ版の間は、本サービスをテストするための料金は発生しません。ただし、NDA の下では、Dataproc Metastore の価値を評価するための暫定的な価格表を提供することができます。
Dataproc Metastore のアルファ版テスト プログラムに、ぜひお申し込みください。
- By プロダクト マネージャー Christopher Crosbie、テクニカル リーダー兼マネージャー Feng Lu

