独自の生成 AI chatbot を BigQuery から直接構築する
Wissem Khlifi
Senior Data Analytics & AI Specialist Lead
Firat Tekiner
Product Management
※この投稿は米国時間 2024 年 6 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
昨今の組織は、顧客情報、財務記録、オペレーション ログなどの豊富なデータにアクセスでき、それらを活用して新しい生成 AI ソリューションを構築することを目指しています。しかし、それを実現するには以下のように数多くの課題があります。
-
LLM の構築とトレーニングには、高度な技術的専門知識と多くの計算リソースが必要です。多くのチームは、環境を管理するために多数の異なるフレームワークとアプリケーション スタックを使用する必要があります。
-
データ ガバナンスとデータ品質に関する課題があります。非マネージド データストアやキュレートされていないデータストアからデータが頻繁に取得されるため、これらのアプリケーションを本番環境へ移行することが難しくなっています。結局のところ、LLM の質はトレーニングに使用されたデータの質によって決まります。
-
LLM が回答にたどり着く過程を把握するのが困難であるため、ソリューションの信頼性と説明責任に関する懸念が生じる可能性があります。モデルにフィードするデータを理解していれば、モデルの出力に対する信頼度と理解が高まります。自分が十分に理解しているデータ、つまり自社のデータレイクとデータ ウェアハウスを使用して、同じ処理を行うことを想像してみてください。そうすると、AI アプリケーションでも同様のルールを適用することで、データ品質を管理しやすくなることがわかるでしょう。
-
AI は、ユーモアや慣用表現など、人間の言語のニュアンスを理解できないことがあり、それが誤解につながる場合があります。グローバル企業の場合、社内 chatbot は複数の言語と文化的背景に対応できる必要があるため、導入が複雑になる可能性があります。
BigQuery と Gemini モデルのメリット
このブログ記事では、DataSageGen というサンプル アプリケーションを構築する方法をご紹介します。DataSageGen は、以下を含むさまざまなソースからの情報にアクセスし、それらを処理するための専属ガイドとして設計された革新的な chatbot です。
-
データ プロダクトと AI プロダクトのドキュメント
-
ブログ投稿とホワイト ペーパー
-
コミュニティの知識
-
プロダクトとイベントに関する発表
DataSageGen は、質問するだけで関連情報をインテリジェントに検索し、簡潔でわかりやすい回答を提供します。
しかし、DataSageGen は単なる検索エンジンではありません。検索拡張生成(RAG)や BigQuery ML などの高度な手法を活用してクエリのコンテキストを理解し、最も関連性が高く、見識に富んだ回答を提供します。
以下はその仕組みの概要です。
-
ユーザー入力: chatbot のインターフェースから DataSageGen に質問します。
-
インテリジェントな検索: DataSageGen では、BigQuery、Vertex AI Search、RAG を組み合わせて使用し、ナレッジベースの最も関連性の高い情報を特定します。
-
プロンプトの拡張: ユーザーの質問は、chatbot の回答を導く追加のコンテキストと指示によって拡張されます。
-
モデルの推論: Vertex AI の優れた Gemini Pro モデルによって拡張プロンプトが処理されると、情報に富んだカスタマイズ済みの回答が生成されます。
-
回答の生成: DataSageGen は、明確かつ簡潔な回答を返します。
技術的なナレッジベースの役割を果たす chatbot の構築を検討しているなら、このようなソリューションから貴重な知見を得ることができます。そのため、企業データをエンタープライズ データ ウェアハウス(BigQuery など)や(Cloud Storage の)非構造化データから移動させることなく独自のナレッジベースを構築するために、これらの機能を活用できるように、詳細なステップを以下で説明します。
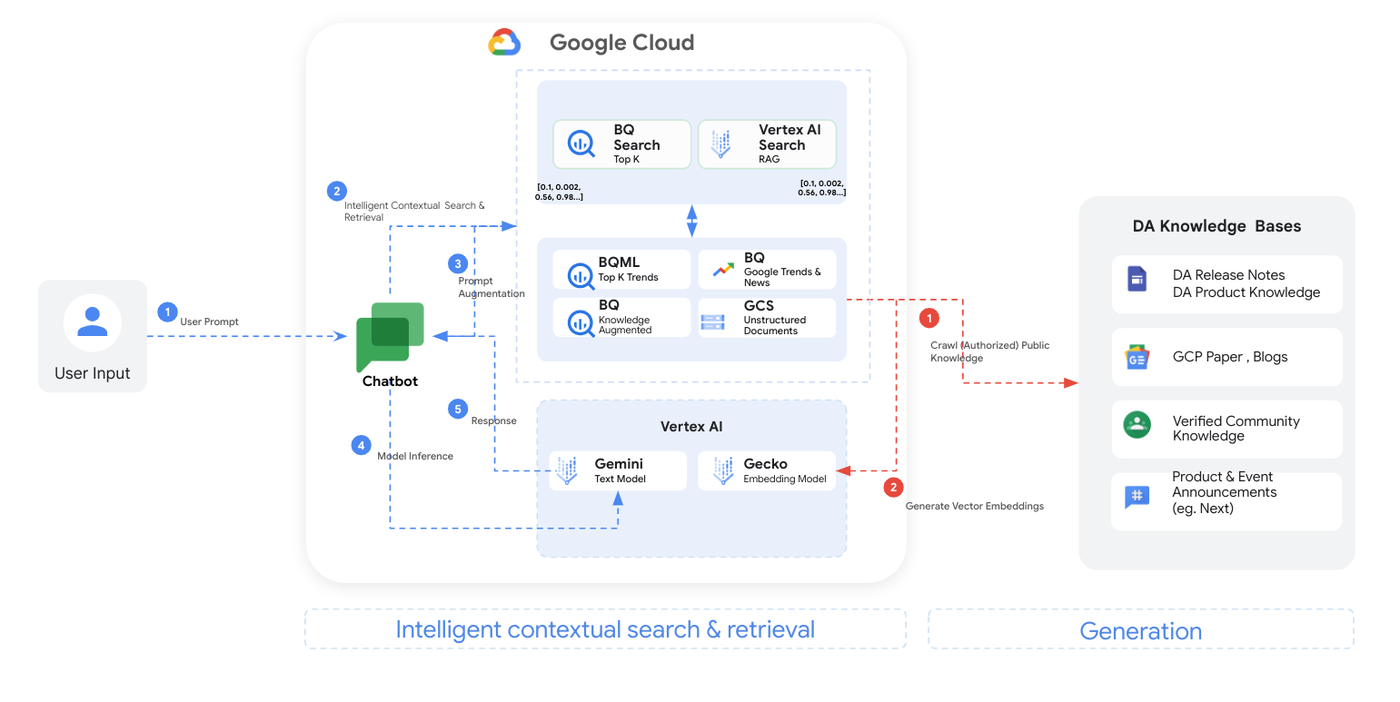
DataSageGen のデータ アーキテクチャを構築する
ステップ 1: ユーザー入力の収集
フローは、DataSageGen の chatbot インターフェースを介してユーザーの入力を取得することから始まります。「ユーザー プロンプト」と呼ばれるユーザーのクエリやコマンドは、Flask のリクエスト処理を使用してリクエスト ペイロードから抽出されます。このステップは、処理パイプライン全体の入力を決定するため非常に重要です。
クラスとメソッドの説明:
-
Flask グローバル リクエスト オブジェクト - 受信リクエストのデータを処理するために Flask アプリケーションで使用されるグローバル リクエスト オブジェクト。
-
request.json.get('question', '') - JSON 形式のリクエスト ペイロードから「question」キー値を抽出します。キーが存在しない場合のデフォルト設定は、空の文字列です。この方法によって入力処理の堅牢性が保証され、エラーがなくなります。
インテリジェントなコンテキスト検索:
ステップ 2: インテリジェントなコンテキスト検索
このステップでは、BigQuery ML を使用し、データトレンドに基づいて上位の検索結果を予測します。また、高度なテキスト分析(RAG)によってリリースノート、ホワイトペーパー、コミュニティの知識、お知らせを活用するために高度なテキスト分析(RAG)も基盤とします。その後、最適な回答を正確に特定するため、質問をセマンティック「エンベディング」に変換し、より深い意味を捉えます。これにより、技術データ分析クエリを用いて、最も関連性の高い最新の情報を取得できるようになります。以下はステップ 2 のより詳細な説明です。
-
BigQuery ML モデルに基づく BigQuery 検索 Top-K: 複数の項目のコンテキストとトレンドを考慮して、キュレーションされたデータセットに対するクエリを実行し、上位「K」件の結果を予測します。
-
Vertex AI Search: 関連する非構造化ドキュメントの検索とテキスト生成の組み合わせである、RAG を利用したデータ知識によって検索を拡張します。フローには、以下のような幅広い情報源が含まれます。
-
データと分析のリリースノートとプロダクトの知識: DataSageGen chatbot が参照できるプロダクトの最新情報と詳細情報の自動的かつ定期的なクロール。
-
Google Cloud のホワイトペーパーとブログ: Google Cloud Platform のデータと分析サービスに関連するインサイトと情報を提供する文書リソース。
-
確認済みのコミュニティの知識: クエリの回答や問題の解決に使用でき、ユーザーで構成されるデータと分析のコミュニティからの信頼できる情報。
-
データと分析に関するプロダクトとイベントの発表: DataSageGen chatbot が最新情報を提供するためにアクセスできる、データと分析に関する新しいプロダクトやイベントの情報。
このステップでは、「generate_text_embeddings」関数を使用して、ユーザーのクエリのセマンティック表現を生成します。この関数では、テキスト入力を密なベクトル(エンベディング)に変換して、入力の意味的なニュアンスを捉えます。このベクトル表現は、コンテキスト検索オペレーションに使用されます。
クラスとメソッドの説明:
-
「TextEmbeddingModel.from_pretrained("textembedding-gecko@001")」: テキストデータの大規模なコーパスで事前にトレーニングされた Vertex AI テキスト エンベディング モデルをインスタンス化します。このメソッドは、「textembedding-gecko@001」Vertex AI モデルを読み込み、エンベディングを生成する準備をします。コードのこの部分は、データの取り込みコンポーネントに含まれています。
「model.get_embeddings([sentences])」: 入力文のエンベディングを生成します。エンベディングは入力テキストの密なベクトル表現であり、意味の理解と比較を容易にします。
-
データと分析のトレンド テーブルから BigQuery ML を使用して、BigQuery ML でトレーニングされた ML モデルとともに「ML.PREDICT」関数を使用します。「ML.PREDICT」関数では、トレーニング済みのモデルを使用して、新しいデータに基づく予測を実行できます。このアプローチにより、BigQuery ML モデルをスコアリングに活用し、BigQuery を使用してデータと分析の Top-K のトレンドを直接検索できます。
ステップ 3: プロンプトの拡張
ユーザーから DataSageGen chatbot に渡されるプロンプトは、RAG の検索によって拡張されます。このステップでは、ユーザー エクスペリエンスを向上させるために、提供される回答をファインチューニングします。質問を受け、トーンに関する指示を追加し、禁止トピック(ヘイトスピーチ、暴力、機密性の高い個人情報など)のリストによってその質問を拡張します。これによって、chatbot の回答の有用性と一貫性が確保されます。
ユーザー プロンプトは、chatbot の回答生成をガイドするための構造化された指示と禁止フレーズのリストによって拡張されます。この拡張には、回答の形式設定方法や回避すべきトピックについてモデルに指示するコンテキストの追加が含まれ、ユーザーの期待とコンテンツ ガイドラインに沿った出力が保証されます。
クラスとメソッドの説明:
-
文字列操作: 構造化された指示と禁止フレーズ(「banned_phrases」)、および元のユーザー プロンプトを 1 つの拡張プロンプトに結合します。このプロセスで、モデルの拡張入力を準備します。
ステップ 4: モデルの推論
推論とチューニングされた回答を取得するために、拡張プロンプトは Vertex AI の Gemini Pro モデルに入力として渡されます。このステップでは、クエリの核心に迫ります。質問にガイダンスを追加し、Vertex AI の Gemini Pro モデルを活用します。回答を強化するために、最も関連性の高い背景情報のベクトル インデックスを検索します。このプロセスにより、複雑なデータ分析の質問に対して、より正確で情報に富んだ回答が得られるようになります。
このフェーズでは、拡張プロンプトを、推論のために Vertex AI でホストされている Gemini Pro モデルへの入力として利用します。また、クエリ エンベディングに基づき、Vertex AI ベクトル検索インデックスをクエリし、コンテキストに応じて関連性のあるドキュメントを探します。この強化されたコンテキストと、モデルの推論機能を組み合わせることで、微妙な違いを認識し、十分な情報に基づいた回答を生成できます。
クラスとメソッドの説明:
-
「aiplatform.MatchingEngineIndexEndpoint(index_endpoint_name)」: 特定の Matching Engine インデックス エンドポイントへの接続を初期化して、保存されたドキュメント内でのセマンティック検索オペレーションを可能にします。
-
「index_endpoint.find_neighbors(deployed_index_id, queries, num_neighbors)」: 指定されたインデックスからクエリ エンベディングの最近傍を検索し、コンテキストに応じて関連性のある情報を回答生成のために提供します。
-
「GenerativeModel("gemini-pro")」: 拡張プロンプトに基づくテキスト生成のために準備された「gemini-pro」生成モデルを読み込みます。このクラスは、Vertex AI の事前トレーニング済み ML モデルを使用するための機能をカプセル化して、一貫性があり、コンテキストに適したテキスト出力の生成を促進します。
ステップ 5: 回答の生成
Vertex AI の Gemini Pro モデルによって情報を処理した後に、DataSageGen chatbot がユーザーに返される回答を生成します。
最後のステップでは、Gemini Pro モデルが、Matching Engine インデックスから検索されたコンテキスト情報を含む拡張プロンプトを処理し、カスタマイズされた回答を生成します。この回答が形式設定され、ユーザーに返されると、対話ループが完了します。
クラスとメソッドの説明:
-
回答の提供: 生成された回答が、DataSagGen chatbot インターフェースを介してユーザーに返されます。このインターフェースはウェブ テクノロジーと、場合によっては Flask フレームワークを活用して、クライアントとサーバー間の通信を管理します。
DataSageGen をアプリケーションに変換する
最後のステップで、RAG を堅牢なウェブ アプリケーションへと変換します。Identity-Aware Proxy(IAP)によってアクセスを保護し、権限のあるユーザーのみが chatbot と対話できるようにします。HTTPS Cloud Load Balancing は、特に使用ピーク時やメンテナンスの時間枠中にトラフィックを効率的に分散させることで、パフォーマンスと信頼性を最適化します。Cloud Run は chatbot をホストし、需要に合わせてリソースを自動的にスケールしながらコストを最適化します。ロードバランサにより、このような予期しない問題に対処できます。
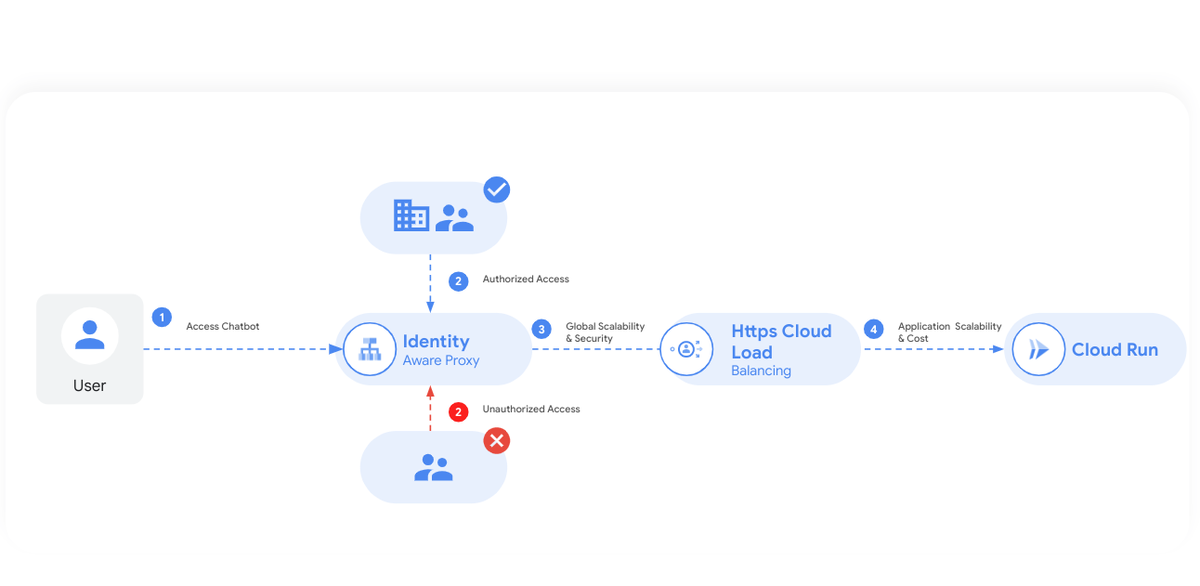
この画像は、セキュリティとスケーラビリティに重点を置いた、DataSageGen chatbot システムのアプリケーション インフラストラクチャ アーキテクチャの概要を示しています。これは、以下のようなさまざまな要素で構成されています。
1. ユーザー アクセス: ユーザーは、最初にウェブ インターフェースを介して DataSageGen chatbot にアクセスします。
2. Identity Aware Proxy(IAP): ユーザーが DataSageGen chatbot にアクセスしようとすると、IAP がゲートキーパーとして機能します。
-
承認済みのアクセス: (認証と認可を受けた)適切な認証情報を持つユーザーは、IAP で先に進むことを許可されます。
-
不正アクセス: 適切な認証情報を持たないユーザーはブロックされ、正当なユーザーのみが chatbot と対話できます。
HTTPS Cloud Load Balancing: IAP を通過すると、アーキテクチャでは HTTPS Cloud Load Balancing を使用して着信トラフィックを管理します。これにより、グローバルなスケーラビリティと 6 秒の高速フェイルオーバーが実現し、大量のリクエストを処理して、システムの一部で障害が発生した場合にはトラフィックを迅速に再転送できるようになります。
3. Cloud Run: これは、DataSageGen chatbot アプリケーションがホストされる最終ステップです。Cloud Run はアプリケーションのスケーラビリティを実現し、コストを効果的に管理します。受信リクエストに基づく自動スケーリングと、リクエストの処理中に使用されたコンピューティング リソースのみに対する課金が行われます。
全体として、DataSageGen chatbot アプリケーション アーキテクチャでは、IAP によるセキュアなアクセス制御、HTTPS Cloud Load Balancing による堅牢なトラフィック管理、Cloud Run による効率的なリソース使用とスケーラビリティが重視されています。
まとめ
知識ベースの chatbot は、従来の chatbot とは異なり、事前にプログラムされた回答を返すだけではありません。大規模言語モデル(LLM)を使用して、よくある質問、ヘルプ記事、商品カタログなどのナレッジベース全体を分析し、コンテキストに応じて自然で人間のような回答を生成します。これらの chatbot には、以下を含む非常に大きなメリットがあります。
-
知識と機能を 1 か所に集約できる。
-
コンテキストに応じた適切な回答が得られるため、チームが主要な業務により多くの時間を費やすことができる。
-
24 時間 365 日の多言語サポート: エージェントの待ち時間なし - 時間帯や言語に関係なく、顧客が即時にサポートを得ることができる。
-
人員を採用せずにサポートを拡張: 繰り返し実行されるクエリを自動化してエージェントの手間を省き、チケット バックログを解消できる。
-
将来を見据えたコンタクト センターの構築: 予期しないサポート量の急増にも簡単に対応できる。
-
短期間で簡単に利用開始: 技術的な専門知識が不要。ナレッジベースに接続すればすぐに使用できる。
ただし、生成 AI を活用して次世代の chatbot を構築するには以下が必要です。
-
ナレッジベースの準備: 情報が最新で、一貫性があり、テキストベースであることを確認します。
-
ガードレールの設定: bot が回答できる質問と、提供できる回答の種類を定義します。
これらの事項を考慮することで、知識ベースの chatbot はカスタマー サポートに変革をもたらし、エクスペリエンスと効率性の向上、およびビジネスの将来を見据えたソリューションを実現できます。
生成 AI の分野は急速に進化しており、chatbot ソリューションの継続的な適応と改良が必要です。DataSageGen アーキテクチャは、可能な限り最も正確で関連性の高い情報を提供して時間と労力を省き、セキュリティとスケーラビリティを考慮して構築されています。また、アクセス制御には Identity Aware Proxy(IAP)、効率的なトラフィック管理には HTTPS Cloud Load Balancing、費用対効果の高いスケーラビリティの確保には Cloud Run が使用されています。DataSageGen は、この複雑な分野に対する理解を深め、業務を効率的に進めていくことを目指すすべての人にとって貴重なツールであり、データ エンジニアやプロダクト マネージャーだけでなく、単純にデータと AI に興味があるユーザーにも価値をもたらします。
BigQuery の新しい RAG 機能およびベクトル検索機能の詳細については、こちらのドキュメントをご覧ください。こちらのチュートリアルを使用すると、Google の最高水準の AI モデルをデータに適用し、BigQuery からデータを移動することなく、モデルをデプロイし、ML ワークフローを運用化できます。独自のコーパスを使用したこのようなアプリケーションをデプロイする方法については、こちらの GitHub リポジトリをご覧ください。Gemini のような高度なモデルの可能性を引き出しつつ、エンドツーエンドのデータ分析や AI アプリケーションを BigQuery から直接構築する方法について説明したデモもご覧いただけます。
ー データ分析 / AI 担当シニアリード Wissem Khilfi
ー データ / AI 担当シニア スタッフ プロダクト マネージャー Firat Tekiner


