BigQuery の変更データ キャプチャ(CDC)の公開プレビュー版をリリース
Google Cloud Japan Team
※この投稿は米国時間 2023 年 4 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
有名なギリシャの哲学者曰く、「この世で唯一不変のものは、変化である。」季節の移り変わり、ポップ カルチャーのトレンド、ビジネスとその中で使用するデータもまた然りです。このたび、進化を続けるお客様のビジネスの需要に応える BigQuery 変更データ キャプチャ(CDC)の公開プレビュー版をリリースいたしました。この機能は Google の既存の Datastream for BigQuery ソリューションの一部であり、MySQL、PostgreSQL、AlloyDB、Oracle などのリレーショナル データベースから BigQuery に直接データをシームレスにレプリケートするのに役立ちます。
概要
BigQuery 初のデータ ミューテーション対応は、2016 年の DML ステートメントの導入です。以来、スケーラビリティの向上、パフォーマンスの改善、マルチステートメント トランザクション、手続き型言語スクリプトへの対応など、多くの新しい DML の機能拡張を導入してきました。DML ステートメントを通じて、ELT イベントの後処理、GDPR の忘れられる権利に基づくコンプライアンスの確保、データ ラングリング、従来型のトランザクション システムの BigQuery へのレプリケーションなど、あらゆる作業のオーケストレーションが可能です。このような複雑な DML パイプラインを BigQuery 内でオーケストレートすることは機能的には可能ですが、多くの場合、一時テーブルを介した多段階のデータ レプリケーション、複雑な DML ステートメントの定期実行、高度にカスタマイズされたアプリケーション モニタリングが必要となります。この方法は実行可能ではありますが、最も使いやすいわけではなく、フルマネージドのエンタープライズ データ ウェアハウスという BigQuery の使命とも合致しません。
こうした問題の解決に向けて、BigQuery ではデータ ウェアハウス内で変更データ キャプチャ(CDC)にネイティブに対応します。
BigQuery のネイティブな CDC への対応により、お客様は複雑な DML MERGE ベースの ETL パイプラインを使用しなくても、変更(挿入、更新、削除)をソースシステムから BigQuery に直接レプリケートすることが可能になります。腎臓病治療の先進企業である DaVita のようなお客様は、この新機能を活用することに価値を見いだしています。BigQuery データ ウェアハウス内のトランザクション データへの高速アクセスが可能になるためです。
「当社のテストからわかったことは、BigQuery CDC により、データの取り込み時間が大幅に増加することなく、アップサートや効率的なクエリ実行が可能になるということです。レイテンシが低いので、BQ リソースを効率的に管理し、関連費用を低く抑えることができます。ダッシュボードやレポートで準リアルタイムにデータを可視化するという当社の目標達成に向けた、大きな一歩です。」- DaVita, Inc.、最高情報責任者 Alan Cullop 氏

BigQuery で対応している CDC は、BigQuery の大規模でスケーラブルな統合型リアルタイム データ取り込み API である BigQuery Storage Write API を通じて利用できます。この API を使用すると、UPSERT や DELETE を BigQuery テーブルに直接ストリーミングできます。この新しいエンドツーエンドの BigQuery 変更管理機能は、BigQuery の新しい機能(一意のレコード追跡用の非強制的な主キー、パフォーマンス / 費用要件調整用のテーブルの許容可能な最長未更新期間、順に実行される操作タイプ指示用の _CHANGE_TYPE など)を組み合わせて使いやすくすることで実現しました。
CDC にネイティブに対応するために、BigQuery はソースシステムからミューテーションのストリームを受け入れ、基礎となるテーブルに継続的に適用します。「max_staleness」という値がカスタマイズ可能なオプションを使用すると、こうした変更をどのぐらいの間隔で適用するかを制御できます。max_staleness はテーブル設定であり、0 分~24 時間の間で変更できます。ここに指定した値が、クエリ時に許容される最長のデータ未更新期間になります。
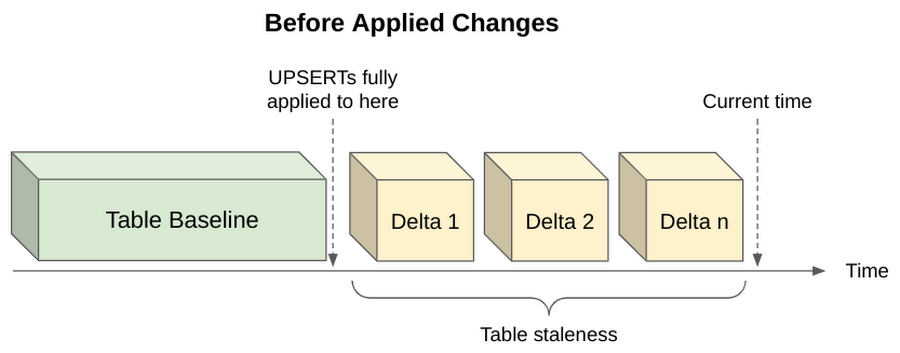

CDC テーブルにクエリを実行すると、max_staleness の値と、最後の適用ジョブが発生した時刻に基づいて、結果が返されます。未更新に対する許容度が低いアプリケーション(注文管理システムなど)では、UPSERT をより頻繁に適用するように max_staleness を構成することで、最も新鮮なクエリ結果を取得することができます。この場合、データの最新性は高まりますが、適用操作がより頻繁に完了し、より多くのコンピューティング リソースを消費するため、費用も高くなると考えられます。また、データが多少古くてもよいアプリケーション(ダッシュボードなど)では、UPSERT の適用間隔を広げることで、バックグラウンドのコンピューティング処理を減らし、常に高いクエリ性能を達成することができます。
例
多くの場合、何かを学習するための最善の方法は実際にやってみることです。BigQuery CDC の実用例を見てみましょう。たとえば、とあるメディア サブスクリプション ビジネスで、顧客ディメンション テーブルを維持しているとします。このテーブルには、顧客名、登録日、住所、顧客層、アクティブなサブスクリプションのリストなどの重要な顧客情報が含まれています。顧客のエンゲージメントや行動が時間とともに変化する中、このデータを営業チームやサポートチームが確実に利用できるようにし、顧客が可能な限り最高のサービスを受けられるようにする必要があります。
まず、以下の DDL ステートメントで「customer_records」という名前のテーブルを作成します。この DDL では、テーブルの max_staleness を 15 分に指定し、テーブルの主キーを customer_ID フィールドに設定し、同じ customer_ID でテーブルをクラスタリングします。
次に、Storage Write API を使ってデータを取り込みます。この例では、Python を使用するので、データをプロトコル バッファとしてストリーミングします。プロトコル バッファの使用法について簡単に復習するには、こちらのチュートリアルをご確認ください。
Python を使用するので、まず protobuf のメッセージを、proto2 形式の .proto ファイルを使用して作成したテーブルに合わせます。これを行うには、この sample_data.proto ファイルを開発環境にダウンロードし、以下のコマンドを実行することでプロトコル バッファの定義を更新します。
開発環境では、この CDC Python スクリプトのサンプルを使用して、いくつかの新しい顧客レコードのサンプルをこの new_customers.json ファイルから読み取り、customer_records テーブルに書き込むことによって挿入します。このコードでは、BigQuery Storage Write API を使用して、以下の例のように proto2 シリアル化バイトを serialzed_rows 繰り返しフィールドに追加することにより、行データ群をストリーミングします。
BigQuery では「max_staleness」値で定義された間隔内で少なくとも 1 回 UPSERT を適用します。そのため、Python スクリプトの実行後すぐにテーブルに対してクエリを実行すると、前にテーブルを構成したとおりに max_staleness の間隔(15 分)内でクエリを実行しているため、テーブルが空に見えることがあります。テーブルのデータがバックグラウンドで更新されるのを待つことも、テーブルの max_staleness 設定を変更することもできます。デモとして、以下の DDL でテーブルの max_staleness を更新します。
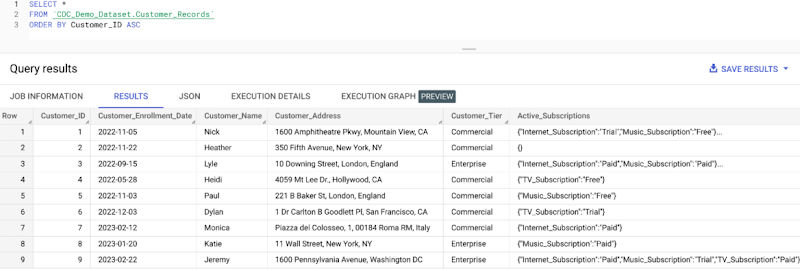
これで、テーブルに対してクエリを実行すると、Storage Write API から数行取り込まれたことが確認できます。
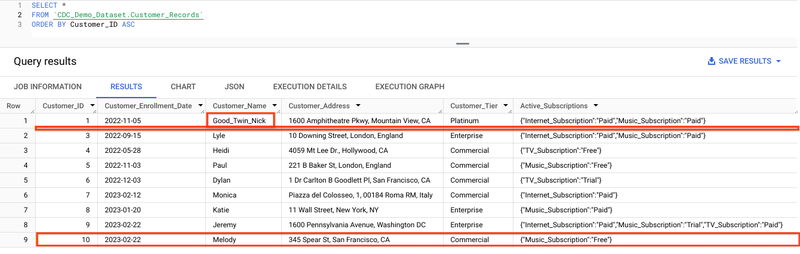
既存のデータが揃いました。ここで、複数の顧客がサブスクリプション アカウントの変更を開始したと仮定します。また、階層を Commercial から Enterprise に移動する顧客、住所を変更する顧客、新規参加する顧客、アカウントを閉鎖する顧客がいるとします。これらの UPSERT を、この modified_customers.json ファイルから読み込んで、BigQuery にストリーミングします。この新しい modified_customers ファイルをストリーミングするには、Python スクリプトの 119 行目をコメントアウトし、120 行目をコメント化解除して、スクリプトを再実行するだけです。
これで再びテーブルに対してクエリを行い、修正が反映されたことを確認できます。
モニタリングと管理
BigQuery CDC では変更の適用が裏で処理されるため、BigQuery CDC のモニタリングと管理は、自分で作成した DML を使用するやり方よりもかなり簡単です。テーブルの UPSERT の運用状況をモニタリングするには、BigQuery の「INFORMATION_SCHEMA.TABLES」ビューに対してクエリを行い、テーブルの UPSERT 最終適用時のタイムスタンプである「upsert_stream_apply_watermark」を取得します。
CDC の適用操作は BigQuery の分析料金モデルで課金されるため、コンピューティング費用をモニタリングすることも有益であると考えられます。BigQuery の予約料金モデルは、CDC 操作を頻繁に行うテーブルや、max_staleness を低く構成したテーブルに適していると考えられます。詳細は、BigQuery CDC のドキュメントに記載されています。
まとめ
企業が成長し、エキサイティングな分析ユースケースを採用するにつれ、データ ウェアハウスもビジネスニーズに適応し、現代において高まり続けるデータの速度、多様性、ボリューム、真実性、価値に対応する必要があります。そこで、変更データ キャプチャが必要になった場合は、BigQuery CDC をぜひお試しください。
また、CDC のユースケースでトランザクション データベースを BigQuery にレプリケートする場合は、Cloud Datastream をぜひご検討ください。Datastream for BigQuery 内に BigQuery CDC を統合し、リレーショナル データベースを BigQuery に直接シームレスにレプリケートすることで、フルマネージドかつサーバーレスな方法で、運用データに関する準リアルタイムのインサイトを把握できます。
- BigQuery プロダクト マネージャー Nick Orlove
- BigQuery ソフトウェア エンジニア Anastasia Han


