Announcing the public preview of BigQuery change data capture (CDC)
Nick Orlove
BigQuery Product Manager
Anastasia Han
BigQuery Software Engineer
As a famous Greek philosopher once said, “the only constant in life is change,” whether that’s the passing of the seasons, pop culture trends, or your business and the data you use within it. Today, we’re announcing the public preview of BigQuery change data capture (CDC) to meet the evolving demands of your business. This capability joins our existing Datastream for BigQuery solution, which helps you to seamlessly replicate data from relational databases such as MySQL, PostgreSQL, AlloyDB, and Oracle, directly into BigQuery.
Overview
BigQuery first supported data mutations back in 2016 with the introduction of DML statements. Since then, we’ve introduced a host of new DML enhancements, such as increased scalability, improved performance, multi-statement transactions, support of procedural language scripting, etc. Through DML statements, you can orchestrate everything from ELT event post-processing, ensure compliance under GDPR’s right to be forgotten, data wrangling, or even the replication of classically transactional systems into BigQuery. While it’s functionally possible to orchestrate these complex DML pipelines within BigQuery, more often than not, it involves multi-step data replication via temporary tables, periodically running complex DML statements, and/or highly customized application monitoring. While viable, this method isn’t the most user-friendly or aligned with BigQuery’s mission to be a fully-managed enterprise data warehouse.
To solve these problems, BigQuery now supports Change Data Capture (CDC) natively inside the data warehouse.
Thanks to BigQuery’s native CDC support, customers can directly replicate insert, update, and/or delete changes from source systems into BigQuery without complex DML MERGE-based ETL pipelines. Customers like DaVita, a leader in kidney care, sees value in leveraging this new capability as it provides accelerated access to transactional data within their BigQuery data warehouse.
“From our testing, BigQuery CDC will enable upserts and efficient query execution without a significant increase in data ingestion time. The low latency helps us effectively manage BQ resources and keep associated costs low. It’s been a big step forward as we work to achieve our goal of near real-time data visualization in our dashboards and reports.” - Alan Cullop, Chief Information Officer, DaVita, Inc.

BigQuery CDC support is available through the BigQuery Storage Write API, BigQuery’s massively scalable and unified real-time data ingestion API. Using this API, you can stream UPSERTs and DELETEs directly into your BigQuery tables. This new end-to-end BigQuery change management functionality is made possible by combining new BigQuery capabilities of non-enforceable primary keys to keep track of unique records, a table’s allowable maximum staleness to tune performance/cost requirements, _CHANGE_TYPEs to dictate the type of operation performed, and _CHANGE_SEQUENCE_NUMBERs to dictate custom ordering.
To natively support CDC, BigQuery accepts a stream of mutations from a source system and continuously applies them to the underlying table. A customizable interval called “max_staleness” allows you to control the rate of applying these changes. max_staleness is a table setting, varying from 0 minutes to 24 hours, and can be thought of as the tolerance for how stale data can be when queried.
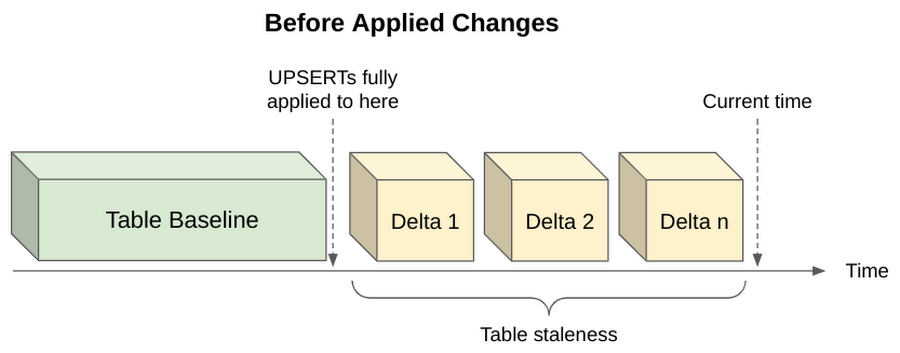

When querying a CDC table, BigQuery returns the result based on the value of max_staleness and the time at which the last apply job occurred. For applications with a low tolerance for staleness (i.e., order management systems), the max_staleness setting can be configured so that UPSERTs are applied at a more frequent basis to get the freshest query results. While this means data is more up to date, it can also mean higher costs as apply operations are completed more frequently and consume more compute resources. For other applications that may be more tolerant of staler data (i.e. dashboards), UPSERTs can be applied at a more intermittent frequency, thereby reducing background computational processing and consistently achieving high query performance.
Example
The best way to learn is often by doing, so let’s see BigQuery CDC in action. Suppose we have a media subscription business which maintains a customer dimension table containing important customer information such as the customer name, enrollment date, address, customer tier, and a list of their active subscriptions. As our customers' engagement and behaviors change over time, we want to ensure this data is available to our sales and support teams to ensure our customers receive the best level of service possible.
To get started, we’ll first create a table named “customer_records” through the below DDL statement. The DDL also specifies the table’s max_staleness to be 15 minutes, sets the primary key of our table to be the customer_ID field, and clusters the table by the same customer_ID.
Now, we’ll ingest some data via the Storage Write API. In this example, we’ll use Python, so we’ll stream data as protocol buffers. For a quick refresher on working with protocol buffers, here’s a great tutorial.
Using Python, we’ll first align our protobuf messages to the table we created using a .proto file in proto2 format. To follow along, download this sample_data.proto file to your developer environment, then run the following command within to update your protocol buffer definition:
Within your developer environment, use this sample CDC Python script to insert some new example customer records by reading from this new_customers.json file and writing into the customer_records table. This code uses the BigQuery Storage Write API to stream a batch of row data by appending proto2 serialized bytes to the serialzed_rows repeated field like the example below:
BigQuery applies UPSERTs at least once within the interval defined by the `max_staleness` value. So if you immediately query the table after the Python script executes, the table may appear empty because you are querying within the same 15 minute max_staleness window we configured our table for earlier. You could wait for your table’s data to be refreshed in the background or you can modify your table’s max_staleness setting. For demonstration purposes, we’ll update our table’s max_staleness with the following DDL:
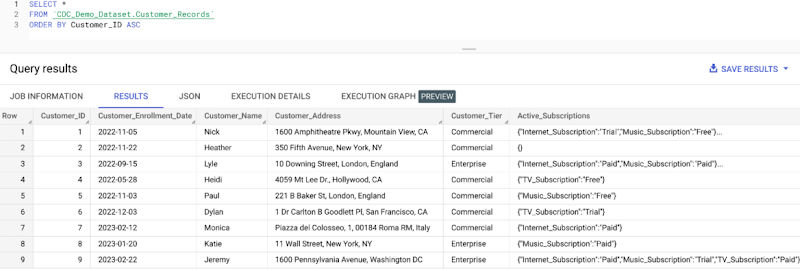
We can now query our table and see it has ingested a few rows from the Storage Write API.
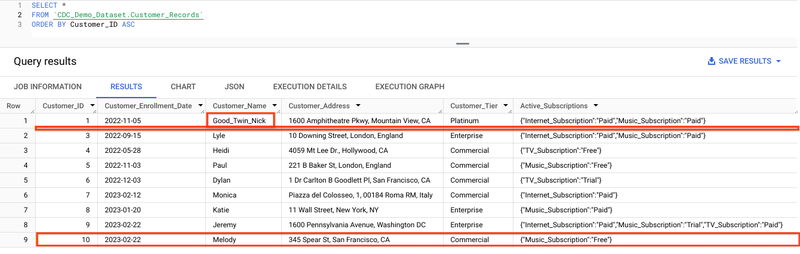
Now that we have some existing data, let’s assume our customers start changing their subscription accounts. Some customers move up from the Commercial to Enterprise tier, some change their address, new customers join, while others close their accounts. We’ll stream these UPSERTs to BigQuery by reading from this modified_customers1.json file. To stream this new modified_customers file, simply comment out line 119 from the Python script and uncomment line 120, then re-run the script.
We can now query our table again and see the modifications have taken effect.
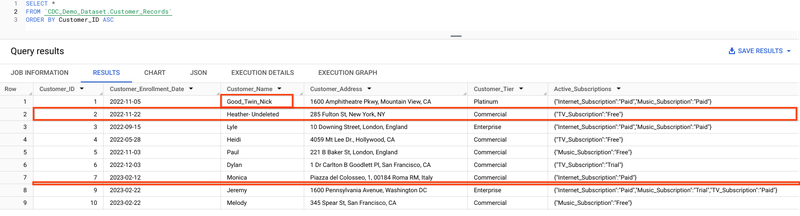
To demonstrate the use of _CHANGE_SEQUENCE_NUMBERs to provide custom ordering, we’ll stream a new set of upserts to BigQuery by reading from this modified_customers2.json file, then re-running the script.
When we query the table now, notice that Good_Twin_Nick was retained and Heather was undeleted.
Monitoring and management
Since BigQuery CDC handles applying changes behind the scenes, monitoring and management of BigQuery CDC is significantly easier than a built-it-yourself DML approach. To monitor your table’s UPSERT operational progress, you can query the BigQuery `INFORMATION_SCHEMA.TABLES` view to get the `upsert_stream_apply_watermark` timestamp, which is the timestamp at which your table’s UPSERTs have last been applied.
Because CDC apply operations are charged under BigQuery’s analysis pricing model, it may also be beneficial to monitor compute costs. BigQuery’s reservation pricing model may be better suited for tables with frequent CDC operations and/or tables configured with low max_staleness settings. Further details on this can be found within the BigQuery CDC documentation.
Conclusion
As enterprises grow and adopt exciting analytical use cases, your data warehouse must also adapt to your business needs and support the ever-increasing velocity, variety, volume, veracity, and value of data in the modern era. So if you have a requirement for Change Data Capture, give BigQuery CDC a try and embrace change.
Also, if your CDC use case involves replicating transactional databases into BigQuery, be sure to check out Cloud Datastream. We’ve integrated BigQuery CDC within Datastream for BigQuery to seamlessly replicate relational databases directly to BigQuery, so you can get near real-time insights on operational data in a fully managed and serverless manner.


