一般提供が開始された BigQuery の Spark プロシージャ機能を使用して分析を統一する
Google Cloud Japan Team
※この投稿は米国時間 2024 年 3 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery は、標準 SQL による大量のデータ処理や、BigQuery ML、リモート関数、ベクトル検索などの高度な機能を提供する、スケーラビリティに優れた高性能な SQL エンジンを搭載しています。しかし、場合によってはオープンソースの Apache Spark の専門知識や既存の Spark ベースのビジネス ロジックを活用して、BigQuery のデータ処理を SQL 以外にも拡張する必要が生じることがあります。たとえば、複雑な JSON 処理やグラフデータ処理にコミュニティ パッケージを使用する場合や、BigQuery に移行する前に Spark で記述したコードを使用する場合です。これまでは、BigQuery から離れて別の API を有効化したり、他のユーザー インターフェース(UI)を使用したり、さまざまな権限を管理したりしなければならず、BigQuery 以外の SKU の料金を支払う必要がありました。
これらの課題に対処するため、Google は BigQuery のデータ処理を Apache Spark に拡張する統合されたエクスペリエンスを開発し、本日、BigQuery の Apache Spark ストアド プロシージャ機能の一般提供(GA)を開始したことをお知らせいたします。Spark ベースのデータ処理によるクエリ拡張を考えている BigQuery ユーザーは、BigQuery API を使用して Spark ストアド プロシージャを作成して実行できるようになりました。これにより、管理、セキュリティ、課金を含め、Spark と BigQuery が単一のエクスペリエンスの下に統合されます。Spark プロシージャは、PySpark、Scala、Java コードを使用してサポートされています。
インターネットと AI テクノロジーのプロバイダであり、BigQuery のお客様でもある DeNA は、次のように述べています。
「BigQuery Spark ストアド プロシージャは、Spark と BigQuery 間で統一された API、ガバナンス、課金により、スムーズなエクスペリエンスを提供するため、当社の Spark の専門知識とコミュニティ パッケージを BigQuery での高度なデータ処理にシームレスに利用できるようになりました。」- 株式会社ディー・エヌ・エー(DeNA)、データ統括部統括部長 グループエグゼクティブ 加茂雄亮氏
この統合されたエクスペリエンスにおける重要な側面の一部を見ていきましょう。
BigQuery Studio で PySpark コードの開発、テスト、デプロイを行う
BigQuery Studio は、すべてのデータ実務者のための単一の統合インターフェースで、PySpark コードを開発、テスト、デプロイするための Python エディタも含まれています。プロシージャは、他のオプションとともに IN / OUT パラメータを使用して構成できます。Spark 接続を作成後、UI 内でコードを繰り返しテストできます。デバッグやトラブルシューティングのために、BigQuery コンソールは基礎となる Spark ジョブからのログメッセージを取り込み、同じコンテキスト内で表示します。Spark のエキスパートは、Spark パラメータをプロシージャに渡すことで、Spark の実行を調整することもできます。
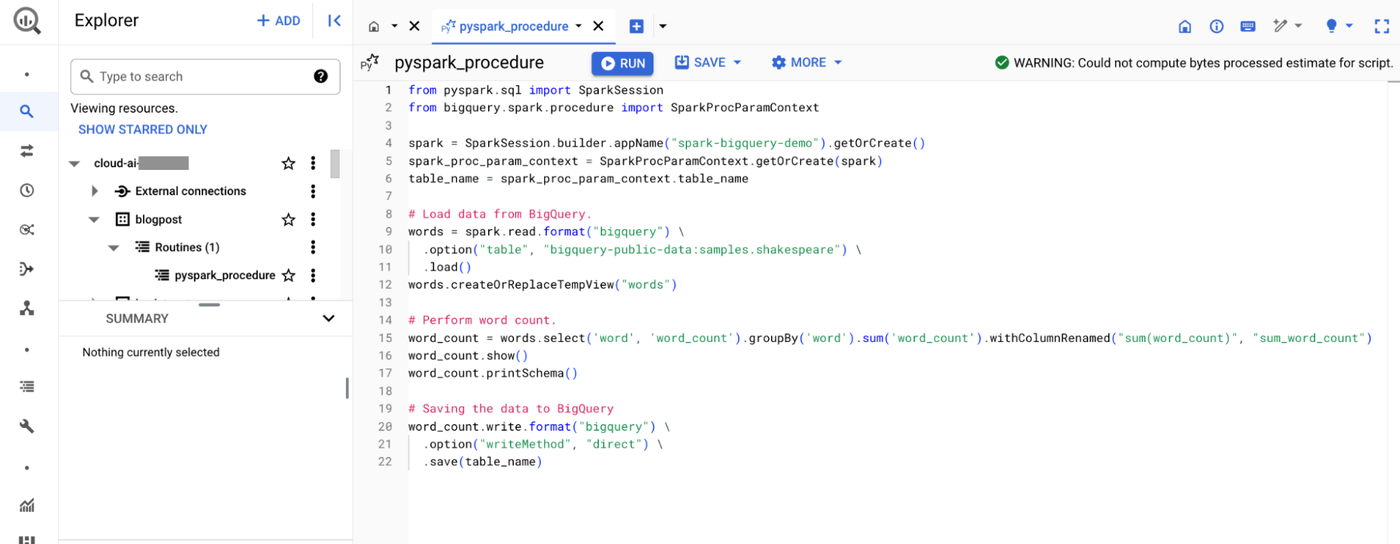
BigQuery Studio の Python エディタで PySpark プロシージャを作成する
テストが完了すると、プロシージャは BigQuery データセット内に保存され、プロシージャへのアクセスは SQL プロシージャと同様に管理できます。
高度なユースケース向けの拡張
Apache Spark の大きなメリットの一つは、コミュニティやサードパーティのパッケージを幅広く活用できることです。BigQuery の Spark ストアド プロシージャは、コードの実行に必要なパッケージをインストールするように構成できます。
高度なユースケースでは、Google Cloud Storage バケットに保存されたコードや、Container Registry または Artifact Registry で利用可能なカスタム コンテナ イメージをインポートすることもできます。
顧客管理の暗号鍵(CMEK)や既存のサービス アカウントの使用など、高度なセキュリティや認証のオプションもサポートされています。
BigQuery の課金によるサーバーレス実行
このリリースにより、BigQuery API 内で Spark のメリットを享受できるようになり、料金は BigQuery にのみ反映されます。これは、サーバーレスで自動スケーリングの Spark を可能にする、業界トップクラスのサーバーレス Spark エンジンによって実現されています。ただし、この新しい機能を利用する際、Dataproc API を有効にする必要はなく、Dataproc の料金は発生しません。Spark プロシージャの使用量は、Enterprise エディション(EE)従量課金制(PAYG)の SKU 料金設定を使用して課金されます。この機能は、オンデマンド モデルを含むすべての BigQuery エディションで利用可能です。EE PAYG SKU の Spark プロシージャは、エディションに関係なく課金されます。詳しくは、BigQuery 料金をご覧ください。
次のステップ
Apache Spark ストアド プロシージャの詳細については、BigQuery ドキュメントをご覧ください。


