ストリーミング分析と AI による異常検出
Google Cloud Japan Team
※この投稿は米国時間 2020 年 8 月 11 日に、Google Cloud blog に投稿されたものの抄訳です。
デジタル トランスフォーメーション文化が進展する中で組織が成功を収めるには、すばやく異常を検出して対応する能力が必要不可欠です。Google Cloud を使用するお客様は、高度な人工知能と機械学習(AI / ML)機能をエンタープライズ クラスのストリーミング分析プラットフォームと組み合わせて使用することで、そうした能力を強化できます。私たちは、このような高速データ処理と高度な分析の組み合わせをリアルタイム AI と呼んでいます。リアルタイム AI はビジネスのさまざまな分野に応用できます。たとえば、異常検出、動画分析、予測などが含まれます。
この投稿では、ログファイル内の異常を検出するためのリアルタイム AI のパターンを紹介します。私たちはネットワーク ログから特徴を抽出および分析することにより、電気通信企業(電話会社)が異常検出のためのストリーミング分析パイプラインを構築するサポートをしました。また、組織のリアルタイムのニーズに合わせてこのパターンを調整する方法についても説明します。
異常検出がどれほどビジネスに役立つかを理解する
異常検出により、企業は膨大な量のデータ ストリーム内から異常なパターンを発見できるだけでなく、予測することもできます。有用な分析情報をもたらす行動パターンは、自身が所有するデータの中に存在します。これは、積極的な購買行動を特定したい大規模小売業者、不正行為を検知したい金融サービス業者、あるいは潜在的な脅威を発見して軽減したい電話会社など、あらゆる企業に当てはまります。
セキュリティ ユースケースでリアルタイム異常検出を実現する
電話会社にとって、ワイヤレス ネットワークをセキュリティ脅威から保護することは非常に重要です。2022 年までに、モバイルデータのトラフィックは 46% の複合年間成長率で増加し、全世界で 1 か月あたり 77.5 エクサバイトに達すると予想されています。このデータ量の爆発的増加により、未知のソースからの攻撃のリスクが高まります。そこで、電話会社は脅威を検出するための新しい方法(機械学習の手法の使用など)を模索しています。
多くのお客様が使用している主要な手法として、シグネチャベースのパターンがあります。シグネチャ ベースのパターンでは、悪意のあるオブジェクトから抽出されたシグネチャのリポジトリと照合することによって、ネットワーク トラフィックが調査されます。この手法は既知の脅威に対しては効果的ですが、新しい攻撃の場合にはパターンまたはシグネチャを利用できないため、発見するのが困難です。このブログでは、機械学習ベースのネットワーク異常検出ソリューションを構築する方法を説明するにあたり、次の重要な要素を取り上げます。
- 本番環境のボリュームをシミュレートするための、Dataflow と Pub/Sub を使用した合成データの生成。
- 特徴とリアルタイム予測の Dataflow を使用した抽出。
- BigQuery ML の組み込みの K 平均法クラスタリング モデルを使用した、データのトレーニングと正規化。
- Dataflow と Cloud DLP を使用した、機密データの匿名化。
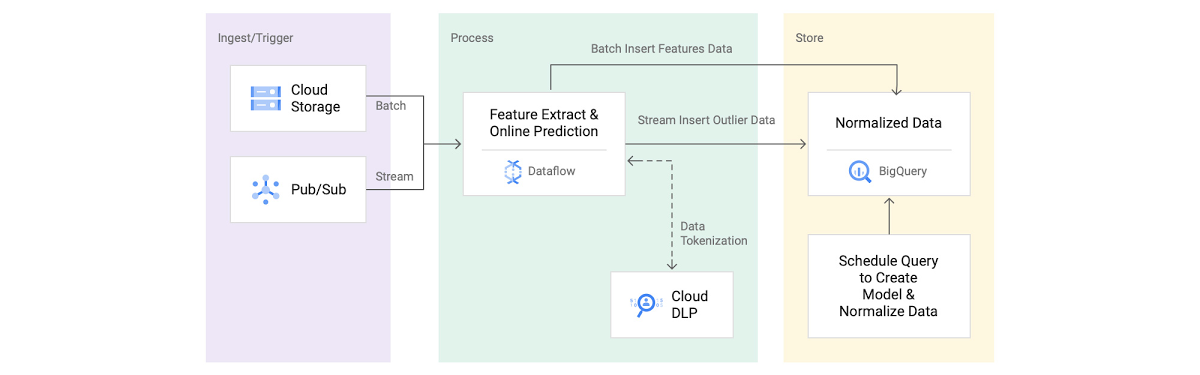
Dataflow と Pub/Sub を使用して合成 NetFlow ログを生成する
まずは合成データの生成から始めましょう。図 1 の「取り込み / トリガー」セクションに対応します。例示のために、ここではオープンソースのデータ ジェネレータ パイプラインを使用して NetFlow ログをシミュレートしました。
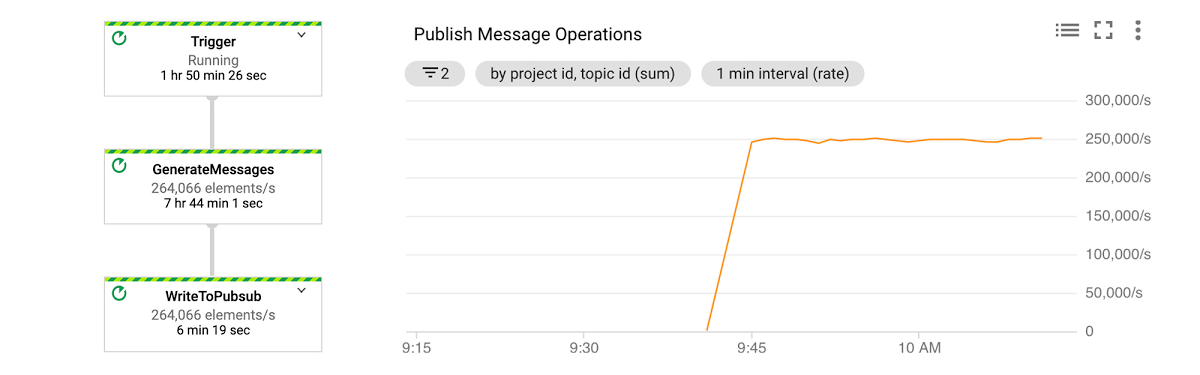
図 2 を見ると、シミュレートされたデータを処理するこのパイプラインが、毎秒 250k の要素をパブリッシュしていることがわかります。
Dataflow と Cloud DLP を使用して特徴を抽出し、機密データをトークン化する
私たちは、10 分間に 150 GB のデータを集約して取り込む異常検出パイプラインをオープンソース化しました。まず、宛先 IP のサブネットである dstSubnet を見つけます。次に、いくつかの基本的な特徴を抽出するため、宛先サブネットとサブスクライバー ID の両方でデータを集計します。このパイプラインは、Apache Beam 変換を使用して、最初に JSON メッセージを行タイプに変換し、次にスキーマを使用してデータを集計します。Beam スキーマ推論スニペットを使用した特徴抽出からわかるように、組み込みの Apache Beam Java SDK 集計変換(Min 関数、Max 関数、ApproximateUnique 関数など)を使用して、サンプルの特徴を抽出できます。
データセットの subscriberId 値には、IMSI 番号などの PII が含まれている場合があります。そこで、PII がプレーン テキストとして BigQuery に保存されることを避けるため、Cloud DLP を使用して IMSI 番号を匿名化しました。同じ CryptoKey を使用してデータの匿名化(トークン化)と再識別(トークン化解除)を行える確定的暗号化を選択しました。Cloud DLP サービスの呼び出し頻度を最小限に抑え、DLP メッセージ サイズ(0.5 MB)の制限内に収めるために、Apache Beam の State and Timer API を使用してマイクロバッチ アプローチを構築しました。こちらのサンプルコードは、バッチサイズとイベント時間トリガーに基づいてリクエストがどのようにバッファリングされ、発行されるかを示しています。データ ボリュームへの同時リクエストに対応するため、デフォルトの Cloud DLP API の割り当て上限を 1 分あたり 40,000 API 呼び出しに増やしました。
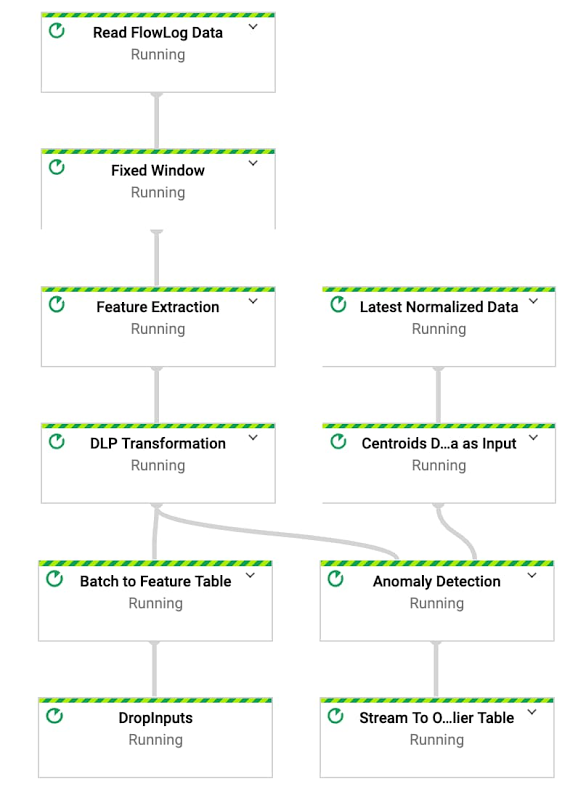
図 3: Dataflow の異常検出パイプライン
BigQuery ML を使用してデータをトレーニングおよび正規化する
次に、図 1 の「保存」コンポーネントに示されているように、BigQuery でデータをトレーニングおよび正規化します。大量の日次データ(20 TB)を処理するため、取り込み時間パーティション分割テーブルと、subscriberID および dstSubnet フィールドによるクラスタリングを使用しました。パーティション分割テーブルにデータを保存すると、日数(たとえば 10 日)とサブスクライバー グループ(たとえば組織 X のユーザー)のフィルタを使用して、トレーニング データを速やかに選択できます。
私たちは、BigQuery ML の K 平均法クラスタリング アルゴリズムを使用してモデルをトレーニングし、クラスタを作成しました。BigQuery ML では標準 SQL を使用してモデルをトレーニングできるので、モデルの作成とトレーニングのプロセス全体を自動化するために、ストアド プロシージャとスケジュールされたクエリを使用しました。テラバイト スケールのデータセットに対して、15 分未満で K 平均法クラスタリング モデルを作成できました。複数のクラスタサイズで実験した結果、モデル評価により 4 つのクラスタを使用することが示唆されました。次に、各クラスタの正規化された距離を見つけることにより、データを正規化しました。
Dataflow を使用してリアルタイムで外れ値を検出する
私たちの取り組みの最後のステップは、外れ値の検出です。これは、図 1 のリファレンス アーキテクチャのステップ 4 に対応します。外れ値をリアルタイムで検出するため、特徴抽出に使用したのと同じパイプラインを拡張しました。まず、正規化されたデータを副入力としてパイプラインに供給します。パイプラインから取得できるデータを正規化したので、次に重心と入力ベクトルの間の距離を計算することにより、最も近い重心を見つけます。最後に、外れ値を見つけるため、最も近い重心から入力ベクトルがどれくらい離れているかを計算します。こちらの図に示されているように、距離が平均より標準偏差 3 分上にある場合、それらのデータポイントを外れ値として BigQuery テーブルに出力します。
モデルが正常に異常を検出できるかどうかをテストするために、外れ値メッセージを手動でパブリッシュしました。具体的には、サブスクライバー ID「000000000000000」で、通常のボリュームよりも多い送信(150,000 バイト)と受信(40,000 バイト)を使用しました。
次に、BigQuery で外れ値テーブルにクエリを実行して、選択された Cloud DLP 変換により、サブスクライバー ID が期待どおり匿名化された形式で保存されていることを確認できました。安全な Pub/Sub サブスクリプションで元のデータを取得するため、こちらのデータ再識別パイプラインを使用しました。図で示されているように、元の外れ値のサブスクライバー ID(00000000000000000)が正常に再識別されました。
分析情報を応用する
高度なリアルタイム パイプラインで検出された分析情報は、それによって組織内で可能になる改善と同じくらい貴重です。こうした分析情報を実用化するために、データ ストーリーテリング用のダッシュボード、例外ベースの管理用のアラート、プロセスの合理化または自動緩和用のアクションを有効にすることができます。異常検出では、検出された異常を Looker でダッシュボード ビジュアライゼーションとしてすぐに確認できます。また、異常の条件が満たされたときにアラートまたはアクションをトリガーするために使用できます。異常が検出された場合、アクションを使用してチケット発行システムでチケットを作成し、さらなる調査と追跡を行うことができます。
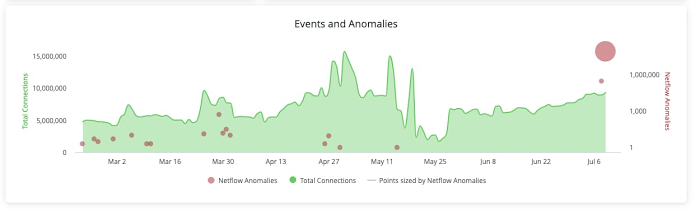
図 4: 外れ値をモニタリングしてアクションを実行する Looker ダッシュボード
まとめ
リアルタイム AI ソリューションは、最終目標(ビジネス目標の達成にどのように役立つか)を念頭に置きつつ、ニーズの変化に適応するための柔軟性(目標、知識、環境の変化に応じていかにすばやく進化するか)を兼ね備えたアプローチを取ることで、最大の効果を発揮します。Google Cloud はビジネスニーズをソリューションに転換するために必要なツールを提供します。未知の脅威をより効率的に検出したいセキュリティ チームや、ポジティブな購買傾向をより効率的に発見したい小売業者にもご利用いただけます。
このブログでは、Dataflow、BigQuery ML、Cloud DLP を使用して安全なリアルタイム異常検出ソリューションを構築する方法を紹介しました。異常の発見は、明確に定義された確率分布を使用していたとしても、攻撃ユースケースを解決するうえで完全に正確ではない場合があります。セキュリティ リスクを確実に検出するには、さらなる分析を行うことが重要です。お試しになる場合は、こちらの GitHub リポジトリにあるリファレンス実装をご覧ください。
-Google Cloud ソリューション アーキテクト Masud Hasan / Google Cloud ソリューション マネージャー Cody Irwin



