BigLake の Apache Iceberg サポートの提供開始を発表
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
Apache Iceberg は、データレイク構築を考えているお客様に人気なオープンソースのテーブル形式です。トランザクション DML、タイムトラベル、スキーマ進化、パフォーマンス最適化を可能にする高度なメタデータなど、エンタープライズ データ ウェアハウスにおける多くの機能を提供します。Iceberg のオープンな仕様により、お客様はオブジェクト ストアに保存されたデータの 1 つのコピーに対して複数のクエリエンジンを実行できます。拡大する投稿者コミュニティに支えられて、Apache Iceberg はデータレイクの事実上のオープン標準となりつつあります。Apache Iceberg はまた、ハイブリッド分析ワークロードやデータ交換のためのシステムのクラウド間での相互運用性をもたらしています。
今年初めに Google は、Google Cloud Storage にオープン ファイル形式(Parquet など)でデータを保存し、GCP とオープンソース クエリエンジンを安全で管理された、パフォーマンスに優れた方法で実行するストレージ エンジンである BigLake を発表しました。BigQuery と Spark といったオープンソースのフレームワークは、きめ細かなアクセス管理を利用してデータにアクセスできるようになりました。これにより、BigLake によるデータ ウェアハウスとデータレイクの統合が実現しました。このたび、このサポートが Apache Iceberg の形式にも拡大されたことをお知らせします。Iceberg の機能を利用して、BigLake を使ったネイティブな GCP インテグレーションのメリットを享受しつつ、オープン形式のデータレイクを構築していただけるようになりました。
「BigQuery 以外にも、当社のデータの大部分は GCS に保存されています。データレイクに Iceberg を活用することで、膨大なデータセットにおいて、効率的かつスケーラブルな方法でデータを利用することができました。BigLake とのインテグレーションにより、BigQuery の大規模なユーザーベースもデータを利用できるようになり、パワフルな UI のおかげで、データ活用はさらに簡単になりました。当社のお客様にも、GCS のデータ上であたかも最初から保存されていたかのように、BigQuery の恩恵の多くを享受できるのだということをおわかりいただけました。」 - Snap Inc.、データおよびインサイト担当シニア マネージャー Bo Chen 氏
BigLake のきめ細かなセキュリティ モデルで、安全で管理された Iceberg データレイクを構築
BigLake は、マルチ コンピューティングのアーキテクチャを実現します。BigQuery を使って、サポートされているオープンソースの分析エンジンで作成された Iceberg テーブルを読み込めます。
Spark でテーブルが作成されると、BigQuery で簡単にクエリを実行できます。
Apache Spark は、Iceberg に豊富なサポートを用意しています。お客様は Iceberg の DML、トランザクション、スキーマ進化などのコア機能を使用して、大規模な変換やデータ処理を実行できます。また、Dataproc(マネージド クラスタまたはサーバーレス)を使用して Spark を実行したり、BigQuery(ストアド プロシージャ)組み込みの Apache Spark のサポートを使用して、Google Cloud Storage でホストされている Iceberg テーブルを処理したりできます。Spark の選択にかかわらず、BigLake は自動的にエンドユーザーがこれらの Iceberg テーブルにクエリできるようにします。
管理者は、BigLake テーブルと同様、Iceberg テーブルも使用できます。基盤となる GCS バケットへのアクセスを、エンドユーザーに提供する必要はありません。エンドユーザーのアクセスは BigLake を通じて委任され、アクセス管理とガバナンスの簡素化が実現します。管理者は、行、列レベルのアクセス制御やデータ マスキングなどのきめ細かなアクセス ポリシーを使用して、Iceberg テーブルのセキュリティを強化し、既存の BigLake ガバナンス フレームワークを Iceberg テーブルに拡張できます。BigQuery は、Iceberg のメタデータをクエリ実行に利用します。これにより、エンドユーザーにパフォーマンスの高いクエリ エクスペリエンスを提供できます。
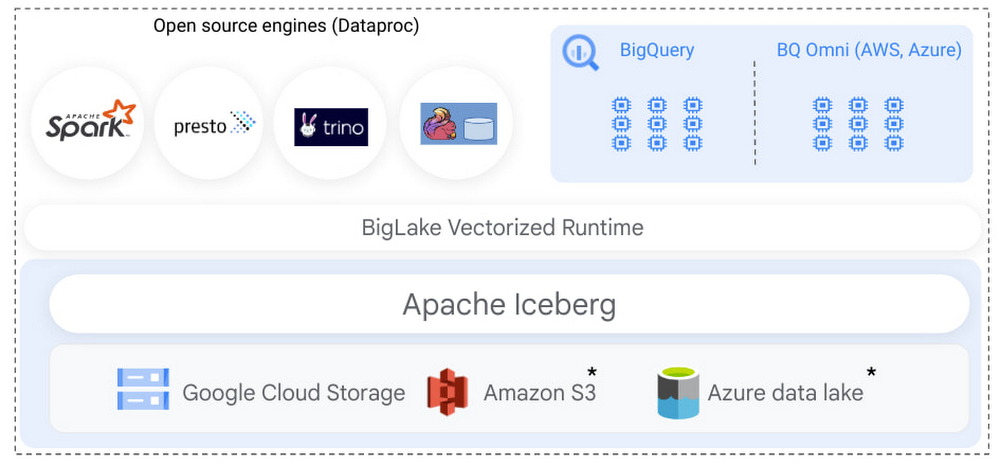
こうした一連の機能を利用すれば、Iceberg を使ってオブジェクト ストアにデータの単一コピーを保存し、BigQuery だけでなく Dataproc ワークロードも安全で管理された高パフォーマンスな方法で実行できます。データの複製やカスタム インフラストラクチャの記述は必要ありません。BigQuery ストレージと Google Cloud Storage にデータを保存している GCP のお客様向けに、BigLake はデータレイクとデータ ウェアハウスのワークロードのインテグレーションをさらに進めました。BigQuery ストレージと Google Cloud Storage 上の Iceberg テーブル間のデータを、直接クエリ、結合、保護、管理できます。今後数か月のうちに、Apache Iceberg は Amazon S3 と Azure data lake Gen 2 に拡張され、マルチクラウドにおける Iceberg データレイクの構築が可能になる予定です。
Iceberg ワークロードをネイティブ BigQuery と GCP インテグレーションにより差別化
Iceberg を Google Cloud 上で実行するメリットは、Iceberg のコア機能と BigLake のきめ細かいセキュリティ モデルの実現だけにとどまりません。BigQuery と GCP のネイティブなインテグレーションを活用することにより、お客様には、Google Cloud Storage のデータ上に作成された Iceberg のテーブル上で、BigQuery の差別化されたサービスをご利用いただけます。Iceberg のコンテキストに最も関連が深い主要なインテグレーションを、いくつかご紹介します。
Analytics Hub を使用して Iceberg データを安全に交換 - Iceberg はオープン標準として、さまざまなストレージ システムやクエリエンジンとのデータ交換のための相互運用性を提供します。Google Cloud では、Analytics Hub を使用して、パートナー、お客様、サプライヤーと BigQuery および BigLake のテーブルを共有できます。データをコピーする必要はありません。BigQuery テーブル同様、データ プロバイダは Iceberg のテーブルを Google Cloud Storage 上で共有するための共有データセットを作成できるようになりました。共有データのユーザーは、Iceberg と互換性があり、サポートされているクエリエンジンを使用してデータを消費できます。また、データの共有と消費に関するオープンで管理されたモデルを提供します。
BigQueryML を用いた Iceberg 上でのデータ サイエンス ワークロードの実行 - BigQueryML を使用して、Google Cloud Storage に保存されている Iceberg テーブルに機械学習ワークロードを拡張できるようになりました。これにより、BigQuery の外に保存されているデータでも、AI 価値を実現できます。
Cloud DLP による Iceberg 上の PII データの発見、検出、保護 - Cloud DLP を使用して、Iceberg テーブルに含まれる PII データ要素を特定、発見、保護できます。また、BigLake のきめ細かいセキュリティ モデルを使用してセンシティブ データを保護し、ワークロードのコンプライアンスにも対応できます。
使ってみる
Apache Iceberg の BigLake サポートについて詳しくは、こちらのデモ動画と、Iceberg で BigLake の構築を行っているお客様によるパネル ディスカッションをご覧ください。BigLake の Apache Iceberg サポートは現在プレビュー版です。ぜひご登録のうえ、お試しください。Apache Iceberg がお客様のデータ アーキテクチャの進化にどう役立つかについて詳しくは、Google の営業担当者にお問い合わせください。
- Google Cloud シニア プロダクト マネージャー Gaurav Saxena
- Google Cloud プリンシパル エンジニア Yuri Volobuev