GKE 上の Cloud TPU v5e で、費用対効果に優れた大規模な AI 推論を実現
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud TPU v5e は、大規模なモデルのトレーニングと推論に求められる費用対効果とパフォーマンスを実現する、専用の AI アクセラレータです。業界有数の Kubernetes サービスである Google Kubernetes Engine(GKE)上で稼働する Cloud TPU により、最高水準のトレーニング機能や推論機能を使用して、AI ワークロードの効率的かつ費用対効果の高いオーケストレーションを実現できます。GKE は、長年にわたり AI ワークロードの GPU のサポートを牽引してきました。今回、大規模な推論機能に対応する TPU v5e を追加して、このサポートをさらに拡大します。
MLPerf™ 3.1 の結果
9 月に発表したとおり、Google Cloud は MLPerf™ Inference 3.1 ベンチマークの結果を提出し、TPU v4 と比較して 1 ドル当たり 2.7 倍のパフォーマンス向上を達成しました。
MLPerf™ Inference 3.1 の提出結果では、高性能推論システムの Saxml と Google の AI コンパイラの XLAを使用して、60 億個のパラメータがある GPT-J LLM ベンチマークを実行したことを証明しました。その際に使用した主な最適化は以下のとおりです。
- XLA の最適化と Transformer 演算子の融合
- INT8 の精度によるトレーニング後重み量子化
- GSPMD を使用した 2×2 TPU ノードプール トポロジ全体にわたる高パフォーマンス シャーディング
- Saxml でのプレフィックス計算とデコードのバッチのバケット化された実行
- Saxml での動的バッチ処理
GKE クラスタ上で Cloud TPU v5e を実行した場合も同じパフォーマンスを実現しました。このことは、GKE 上の Cloud TPU によって、TPU の優れた費用対効果を維持しつつ、GKE のスケーラビリティ、オーケストレーション、運用上の利点を得ることが可能であることを示しています。
GKE と TPU で費用対効果を最大化する
本番環境に対応した、スケーラビリティの高いフォールト トレラントなマネージド アプリケーションを構築する際、GKE は TPU での推論にかかる総所有コスト(TCO)を減らすことにより、以下のような付加価値をもたらします。
- Kubernetes の標準プラットフォームで AI ワークロードを管理、デプロイできる。
- 自動スケーリングにより費用を最小限に抑え、ワークロードのニーズに合わせてリソースが自動的に調整されるようになる。GKE では自動スケーリングを使用して、トラフィックに応じて TPU ノードプールを自動的にスケールアップ、スケールダウンすることができるため、費用対効果が高まり、推論の自動化が改善されます。
- ワークロードに必要なコンピューティング リソースをプロビジョニングできる。GKE のノード自動プロビジョニング機能により、TPU のワークロード要件に基づいて TPU ノードプールを自動的にプロビジョニングすることが可能です。
- GKE 上の TPU VM ノードプールに対する組み込みの健全性モニタリングにより、アプリケーションの高可用性が確保される。TPU ノードが利用不可能になった場合、GKE はノードの自動修復を実行して中断を回避します。
- GKE のプロアクティブなメンテナンス イベント処理とワークロードの正常終了により、アップデートやハードウェア障害による中断が最小限に抑えられる。
- GKE の成熟した信頼性の高い指標とロギング機能により、TPU アプリケーションを完全に可視化できる。
GKE TPU 推論リファレンス アーキテクチャ
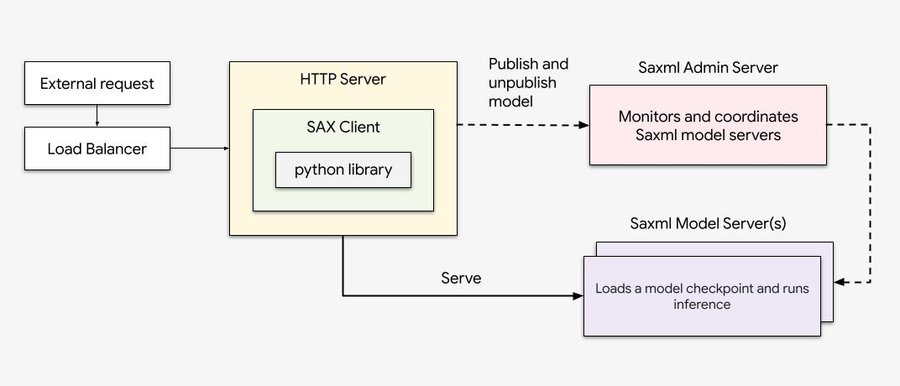
前述の利点をすべて活用できるよう、シングルホストの Saxml モデルサーバーで GPT-J 6B LLM モデルを使用して TPU 推論を実証する概念実証を作成しました。
下図: Saxml ワークフロー
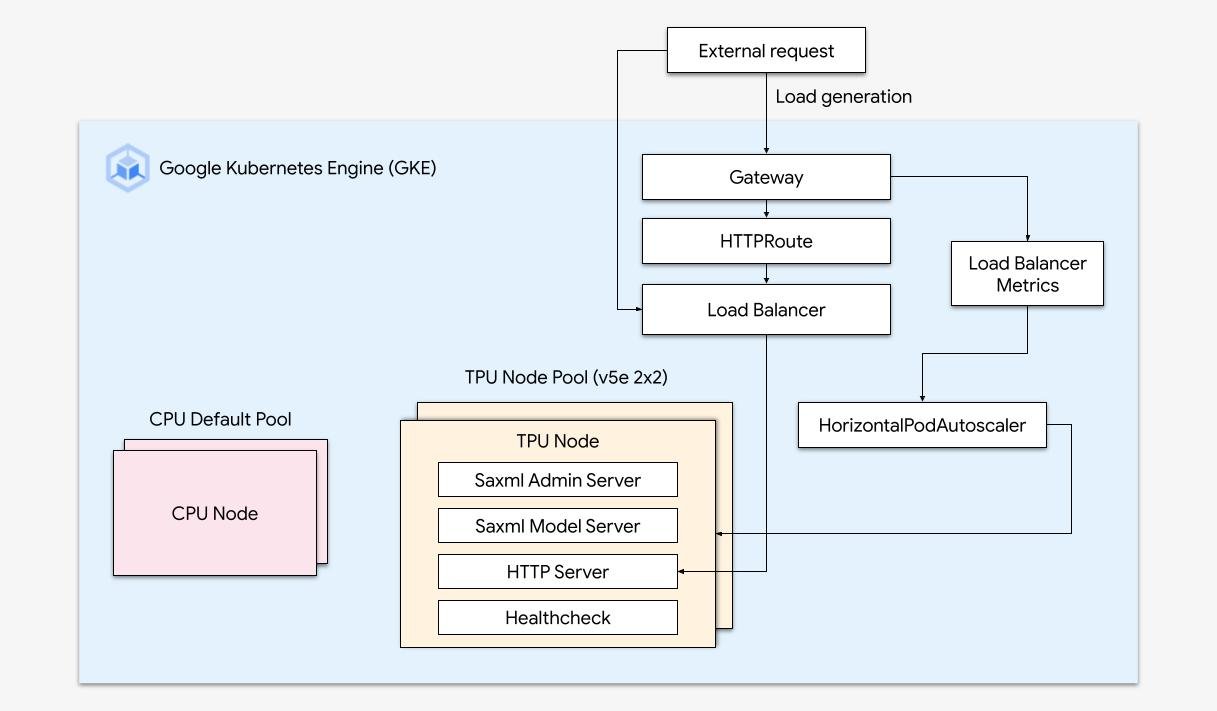
GKE クラスタを以下のアーキテクチャで作成しました。
- TPU v5e(2x2)ノードプールで GKE クラスタを作成しました。
- さまざまな HTTP エンドポイントを公開し、ヘルスチェックを提供する機能のある Gateway API を有効にしました。
- Saxml のフロントエンドとしてシンプルな HTTP サーバーを開発しました。このサーバーは、エンドユーザーからのリクエストを Saxml にプロキシします。
- Saxml Deployment と HTTP サーバーという 2 つのコンテナを提供する Kubernetes Deployment を開発しました。これにより、HTTP サーバーがサイドカーとして動作し、Saxml に比例してスケーリングされるようにできます。
- HTTP ルート、ヘルスチェック、K8s ロードバランサ ベースのバッキング サービスなど、Deployment に必要な Gateway API の構成を行いました。
- 最後に、ロードバランサへのトラフィックに基づいて、Deployment のレプリカ数を動的にスケーリングできる HorizontalPodAutoscaler を追加しました。
このリファレンス アーキテクチャは、GKE を使用して TPU v5e を運用する際、大規模な AI 推論に最適な費用対効果を実現する方法を示しています。以下のデモを参照して、クラスタの実例をご確認ください。
デモ

リファレンス アーキテクチャのその他の例や詳細については、Google の GitHub を参照してください。
デモをお試しになって、GKE での Saxml についてご不明な点がありましたら、コメントを残してください。皆様からのフィードバックをお待ちしています。
GKE での AI / ML ワークロードについて詳しくは、こちらをご覧ください。
-シニア ソフトウェア エンジニア David Porter
-ソフトウェア エンジニア Vivian Wu

