TorchX を使用して、PyTorch アプリケーションを Batch で迅速にデプロイする
Google Cloud Japan Team
※この投稿は米国時間 2023 年 4 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
画像認識、言語処理、回帰分析など、何かしらの ML の取り組みを行う場合、迅速なプロトタイピングとデプロイが引き続き最も重要となります。そのようなコンピューティングにおいては、段階ごとに異なる CPU および GPU の要件があることが多いです。Google Cloud が導入した Batch は、先ほど説明したものを含むバッチ ワークロード向けに、インフラストラクチャ ライフサイクルの管理やキュー、スケジューリングを処理するフルマネージド サービスです。ML パイプラインのトレーニングと本番環境移行を高速な反復処理で加速できる、分散 PyTorch ワークロードを実行するように設計された TorchX と組み合わせることで、ML アプリケーションの開発のデベロッパー エクスペリエンスをさらに簡素化できます。
通常、ML デベロッパーはオープンソース ソフトウェア(OSS)を使用してカスタムのプラットフォームを構築します。あるいは、Vertex AI などのフルマネージド プラットフォームを活用してその複雑さを軽減する場合もあります。そして、柔軟性に関するニーズに応じて、どちらか片方がもう片方より好まれるということがあります。セルフ マネージドのリソースを使用する場合、トレーニングを開始する前に PyTorch ユーザーはいくつかの運用上の手順を完了する必要があります。そのような設定作業には、PyTorch や関連する torch パッケージを Docker コンテナに追加することなどがあります。パッケージには次のようなものがあります。
Pytorch DDP。フォールト トレランスや動的容量管理などの分散トレーニング機能を実現します
Torchserve。トレーニング済みの PyTorch モデルを簡単に、カスタムコードを記述することなく大規模かつ効率的にデプロイできるようにします
これらをひとつにまとめようとすると、設定作業、カスタムコードの記述、初期化の手順が必要になるでしょう。TorchX であれば、そのような設定作業をひとまとめにできます。TorchX では研究段階のプロトタイピングから本番環境までの移行を加速するため、開発をローカルでテストしてから、わずかなステップで環境をクラウドに複製できます。ハイパーパラメータ調整、継続的インテグレーションと継続的デプロイのためのツールのエコシステムが利用可能です。また、一般的な Python ツールを活用して途中断簡で簡単にデバッグを行うことが可能できます。また、Kubeflow や Airflow などの対応の ML パイプライン オーケストレータ内で、本番環境で使用できるアプリをパイプライン ステージに変換することもできます。
TorchX で Batch がサポートされるため、マネージドの手法で PyTorch ワークロードをバッチジョブとして Google Cloud Compute Engine VM インスタンス上で実行できます。また、GPU を必要に応じて活用することが可能です。この統合は、Batch の高度な機能と PyTorch ツールの広範なエコシステムを組み合わせるものです。
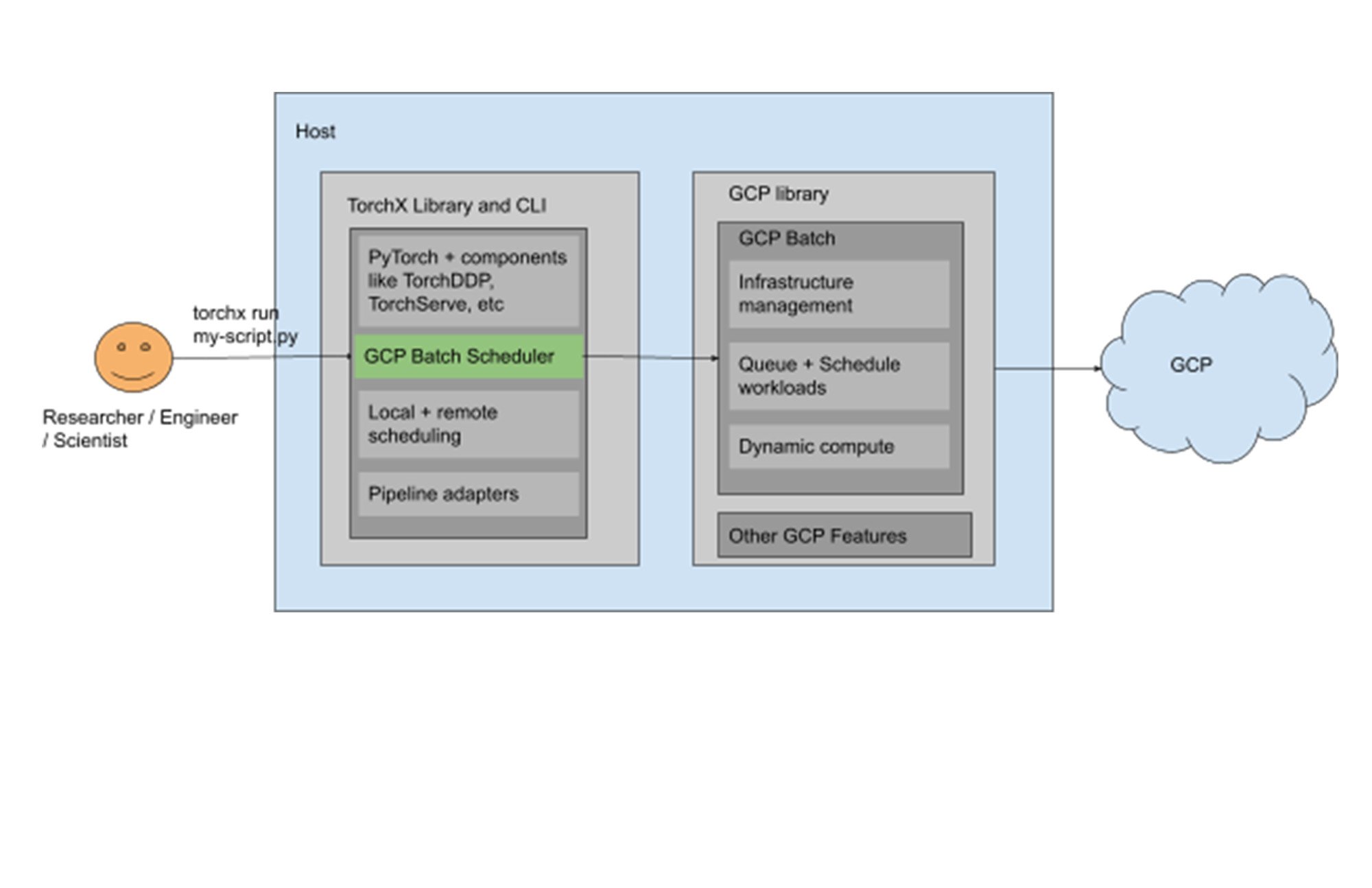
すべてを組み合わせる
これらのサービスに関する知識を踏まえたうえで、TorchX、Batch、NVIDIA A100 GPU を使用して、PyTorch フレームワークによるシンプルなモデルをトレーニングするサンプル アーキテクチャについて見てみましょう。
前提条件
Batch で必要な設定
有効化と設定作業を行い、Batch を使用するように Google Cloud プロジェクトを構成する必要があります。必要となる IAM 権限については、前提条件のドキュメントをご覧ください。
TorchX で必要な設定
Google Cloud コンソールのプロジェクトから、Cloud Shell にアクセスするか、Compute Engine VM インスタンスに SSH 接続を行って、TorchX をインスタンスにインストールし、その後にインストールを確認します。Python をインストールしたら、次のコマンドを実行します。
モデルをトレーニングする
ユーザーとして行うことは、トレーニング スクリプトの記述のみです。Batch スケジューラを指定した状態で TorchX CLI を呼び出します。これにより、バッチ ライブラリが設定されて使用されるようになり、ジョブの実行が開始されます。このログはストリーミングで送り返すことができます。これは、トレーニング スクリプトとスケジューラ固有の設定の分離に役立ちます。
CLI にアクセスする
まず、Cloud Shell CLI にアクセスするか、TorchX をインストールした Compute Engine VM インスタンスへのログイン / SSH 接続を行います。プロジェクト内のすべての有効化された Cloud API にホストがアクセスできること、前提条件で説明されているように Batch API が有効化されていることを確認します。
Batch でジョブを開始する
TorchX CLI または API を使用して、TorchX アプリを Batch に送信できます。
TorchX では、テンプレート化されたアプリ仕様とも呼ばれる、さまざまな組み込みのコンポーネントが利用できます。すべての TorchX コンポーネントは Batch で実行できます。以下の例で、TorchX CLI からこれらのコンポーネントを開始する方法を説明します。
TorchX コンポーネントを Google Cloud Batch で実行するための構文。
スケジューラの構成オプションを使用して、Google Cloud プロジェクトの名前と場所を設定することもできます。デフォルトでは、Torchx は環境内の構成済みの Google Cloud プロジェクトを使用して、ロケーションとして us-central1 を使用します。
例:
python コードを実行するシンプルなジョブを開始する
分散トレーニング スクリプトを実行する
TorchX が、分散コンポーネントの実行時にデフォルトの torchx Docker イメージを起動します。world のサイズを計算するデフォルトの Docker イメージで利用できる分散トレーニング スクリプトを実行するには、次のようにします。
カスタムの Docker イメージ内部で分散スクリプトを実行する構文は次のとおりです。
TorchX では、ジョブのステータスの取得、ジョブの説明、ジョブのキャンセルができます。また、送信済みのすべてのジョブをそれぞれのステータスとともに一覧表示することもできます。
次のステップ
このブログでは、Batch を TorchX と組み合わせて活用し、PyTorch アプリケーションの開発とデプロイを迅速かつ大規模に行う手法について説明しました。まとめますと、PyTorch 開発のユーザー エクスペリエンスは以下により改善されます。
ローカル開発からクラウドへのリフト&シフト
マネージドのインフラストラクチャ ライフサイクルとワークロードのスケジューリング
Google Cloud が提供するスケーラブルなコンピューティング リソース
torch 関連の依存関係の Docker コンテナへの事前パッケージング
開始するにあたり必要となるコードの量の削減
torchelastic の活用によるフォールト トレラントで弾力性のある分散トレーニングの実現
MLOps、CI / CD、オブザーバビリティのための PyTorch エコシステムの容易な統合
これで開始する準備ができました。アプリケーションの例で、Batch で活用できるサンプルをご覧ください。
- プロダクト マネージャー Shamel Jacobs
- Meta、ソフトウェア エンジニア Priya Ramani 氏
