Compute Engine のベンチマーク レンダリング ソフトウェア

Google Cloud Japan Team
※この投稿は米国時間 2021 年 2 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
アニメーションや視覚効果スタジオなどのレンダリング ワークロードを定期的に行っているお客様は、プロジェクトを提供する納期を抱えています。納期が迫っている場合、クラウド リソースを活用して、レンダリング サーバーのフリートを一時的に拡張することで特定の期間内に作業を完了できます。このプロセスは、バースト レンダリングと呼ばれます。レンダリング ジョブを Google Cloud にデプロイする方法について詳しくは、ハイブリッド レンダー ファームの構築を参照してください。
クラウドのレンダリング パフォーマンスを測定する際、同じ数の CPU コア、プロセッサ周波数、メモリ、GPU を備えた仮想マシン(VM)を構築することにより、オンプレミスのレンダリング ワーカー構成を再現することがあります。これは出発点としては良いかもしれませんが、物理レンダー サーバーのパフォーマンスが、同様の構成のパブリック クラウドで実行されている VM と同等になることはめったにありません。オンプレミス ハードウェアとクラウド リソースの比較について詳しくは、オンプレミス ハードウェアから Google Cloud へのリソース マッピングの参照記事をご覧ください。
クラウドには、ワークロードに合わせてリソースを適切なサイズに設定できる柔軟性があります。特定の時間内または予算内でタスクを完了できるように、個々のリソースを定義できます。
ただし、新しい CPU や GPU プラットフォームが導入されたり、価格が変更されたりすると、この計算が複雑になることがあります。ワークロードが Google Cloud で利用可能な新しいプロダクトの恩恵を受けられるかどうかはどのように判断できるでしょうか?
この記事では、Compute Engine インスタンスでのさまざまなレンダリング ソフトウェアのパフォーマンスを調査します。Google Cloud では、すべての CPU と GPU プラットフォーム、すべてのマシンタイプ構成で人気のあるレンダリング ソフトウェアのベンチマークを実行して、それぞれのパフォーマンス指標を決定しました。使用したレンダリング ベンチマーク ソフトウェアは、さまざまなベンダーから無料で入手できます。また、以下の表で、使用したソフトウェアのリストを確認できます。それぞれの詳細については、ベンチマークの調査をご覧ください。
注: レンダリング ソフトウェアのベンチマークは、本質的に、ソフトウェアに含まれているシーンデータと、ベンチマークの作成者が選択した設定に偏りやすいものです。クラウド リソースの柔軟性を活かす方法を十分に理解するためには、独自のクラウド環境内で独自のシーンデータを使ったベンチマークを実行することをおすすめします。
ベンチマークの概要
通常、レンダリング ベンチマーク ソフトウェアは、ベンチマークの実行に必要なすべてを含むスタンドアロンの実行可能ファイルとして提供されています。レンダリング ソフトウェア自体のライセンスフリー バージョン、レンダリングするシーン、サポート ファイルはすべて、インタラクティブに、またはコマンドラインから実行できる単一の実行可能ファイルにバンドルされています。
ベンチマークは、投稿されている他の結果と比較する際、構成のパフォーマンス能力を判断するのに役立ちます。Blender Benchmark などのベンチマーク ソフトウェアは、主な指標としてジョブの所要時間を使用し、構成に関係なく、ベンチマークごとに同じタスクを実行します。タスクの完了が速いほど、構成の評価は高くなります。
V-Ray Bench などの他のベンチマーク ソフトウェアは、一定の時間内にどれだけの作業を完了できるかを調べます。この時間内に完了したコンピューティングの量が、他のベンチマークと比較できるベンチマーク スコアになります。
ベンチマーク ソフトウェアは、ベースとしているレンダラの制限または機能の影響を受けます。たとえば、Octane や Redshift などのソフトウェアは、どちらも GPU ネイティブのレンダラであるため、CPU のみの構成を利用できません。Chaos Group の V-Ray は CPU と GPU の両方を利用できますが、アクセラレータに応じて異なるベンチマークを実行します。そのため、互いを比較できません。
今回は、次のレンダリング ベンチマークをテストしました。
インスタンス構成の選択
Google Cloud のインスタンスは、CPU、GPU、RAM、ディスクのほぼすべての組み合わせで構成できます。数多くの変数のパフォーマンスを測定するために、各コンポーネントの使用方法を定義し、一貫性を保つために必要に応じてその値を固定しました。たとえば、マシンタイプによって各 VM に割り当てるメモリの量を決定し、10 GB のブートディスクを使用して各マシンを作成しました。
CPU の数と種類
Google Cloud は、さまざまなメーカーの多数の CPU プラットフォームを提供しています。各プラットフォーム(コンソールとドキュメントではマシンタイプと呼ばれる)では、単一の vCPU から m2-megamem-416 まで、さまざまなオプションを用意しています。異なる世代の CPU を提供するプラットフォームもあります。また、新しい世代の CPU は市場に出ると、Google Cloud に導入されます。
今回の調査は、N1、N2、N2D、E2、C2、M1、M2 の CPU プラットフォーム上で事前定義されたマシンタイプに限定しました。すべてのベンチマークは、事前定義された各マシンタイプに割り振られたデフォルトのメモリ量を使用して、最低 4 つの vCPU で実行しました。
GPU の数とタイプ
GPU による高速レンダラについては、Google Cloud で利用可能なすべての NVIDIA GPU のあらゆる組み合わせに対してベンチマークを実行しました。GPU レンダラのベンチマークを簡素化するために、事前定義された単一のマシンタイプである n1-standard-8 のみを使用しました。これは、ほとんどの GPU レンダラがレンダリングに CPU を利用しないためです(V-Ray ハイブリッド レンダリング機能は例外。この記事ではそのベンチマークを実施していません)。
すべての GPU が同じ機能を備えているわけではありません。一部の GPU は NVIDIA の RTX をサポートし、一部の GPU レンダラの特定のレイトレーシング操作を高速化することができます。また、他の GPU は NVLink を提供しています。より高速な GPU 間の帯域幅をサポートして、接続されているすべての GPU に対して統合されたメモリスペースを提供します。今回テストしたレンダリング ソフトウェアは、すべての GPU タイプで機能し、利用可能な場合は、このようなタイプの固有の機能を活用できます。
また、すべての GPU インスタンスに、NVIDIA のパブリック ダウンロード ドライバ ページと Google のパブリック クラウド バケットから入手できる NVIDIA ドライバ バージョン 460.32.03 をインストールしました。このドライバは CUDA Toolkit 11.2 を実行し、A100 の新しい Ampere アーキテクチャの機能をサポートします。
注: すべての GPU タイプがすべてのリージョンで利用できるわけではありません。Compute Engine の GPU で使用可能なリージョンとゾーンを確認するには、GPU のリージョンとゾーンの可用性をご覧ください。
ブートディスクのタイプとサイズ
今回使用したすべてのレンダリング ベンチマーク ソフトウェアは、数 GB 未満のディスクを使用しているため、各テスト インスタンスのブートディスクを可能な限り小さくしました。また、コストを最小限に抑えるために、すべての VM に 10 GB のブートディスク サイズを選択しました。このサイズのディスクのパフォーマンスは控えめですが、レンダリング ソフトウェアは通常、ベンチマークを実行する前にシーンデータをメモリに取り込むため、ディスク I/O はベンチマークにほとんど影響を与えません。
リージョン
すべてのベンチマークは、us-central1 で実行しました。リソースの可用性に基づいて、リージョン内のさまざまなゾーンにインスタンスを配置しました。
注: すべてのリソースタイプがすべてのリージョンで利用できるわけではありません。Compute Engine の CPU で使用可能なリージョンとゾーンを確認するには、使用可能なリージョンとゾーンをご覧ください。Compute Engine の GPU で使用可能なリージョンとゾーンを確認するには、GPU のリージョンとゾーンの可用性をご覧ください。
ベンチマーク コストの計算
この記事に記載している価格はすべて、ベンチマーク自体の所要時間のみについて、すべてのインスタンス リソース(CPU、GPU、メモリ、ディスク)を含めて計算されています。各インスタンスには、起動時間、ドライバとソフトウェアのインストール、ベンチマーク後のシャットダウン前のレイテンシが発生します。表示されているコストには、この余分な時間を追加していません。この時間は、イメージを作成するか、コンテナ内で実行することで削減できます。
価格は、us-central1 リージョンのリソースに基づき、執筆時点で最新のものであり、米ドルで表記されています。すべての価格はオンデマンド リソースのものです。ほとんどのレンダリングのお客様には、レンダリング ワークロードに最適な プリエンプティブル VM を使用することをおすすめしますが、この記事の目的としては、全体的なコストよりもリソース間の相対的な違いを確認することがより重要です。詳細については、Google Cloud 料金計算ツールをご覧ください。
各マシンタイプの 1 時間あたりのコストを算出するために、各構成のさまざまなリソースを合計しました。
個々のベンチマークのコストを算出するために、レンダリングの時間にこの 1 時間あたりのコストを掛けました。
コスト パフォーマンス インデックス
レンダリングにかかる時間に基づいたコストの計算に必要なものは、レンダリング時間を指標として使用するベンチマーク作業のみです。V-Ray や Octane などの他のベンチマークは、一定期間内に可能な計算量を測定することにより、スコアを計算します。これらのベンチマークの場合、各レンダリングのコスト パフォーマンス インデックス(CPI)を計算します。これは次のように表せます。
ここでは、価をスコアに、コストをリソースの 1 時間あたりのコストに置き換えます。
これにより、各インスタンス構成の価格とパフォーマンスの両方を表す単一の指標が得られます。
この方法で CPI を計算すると、単一のレンダラ内で結果を簡単に比較できます。同じベンチマークを実行している他の構成と比較する方法に比べて、結果の値自体は重要ではありません。
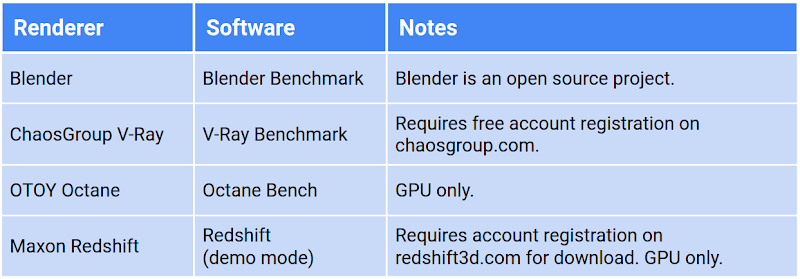
たとえば、V-Ray ベンチマークをレンダリングする 3 つの異なる構成の CPI を調べます。
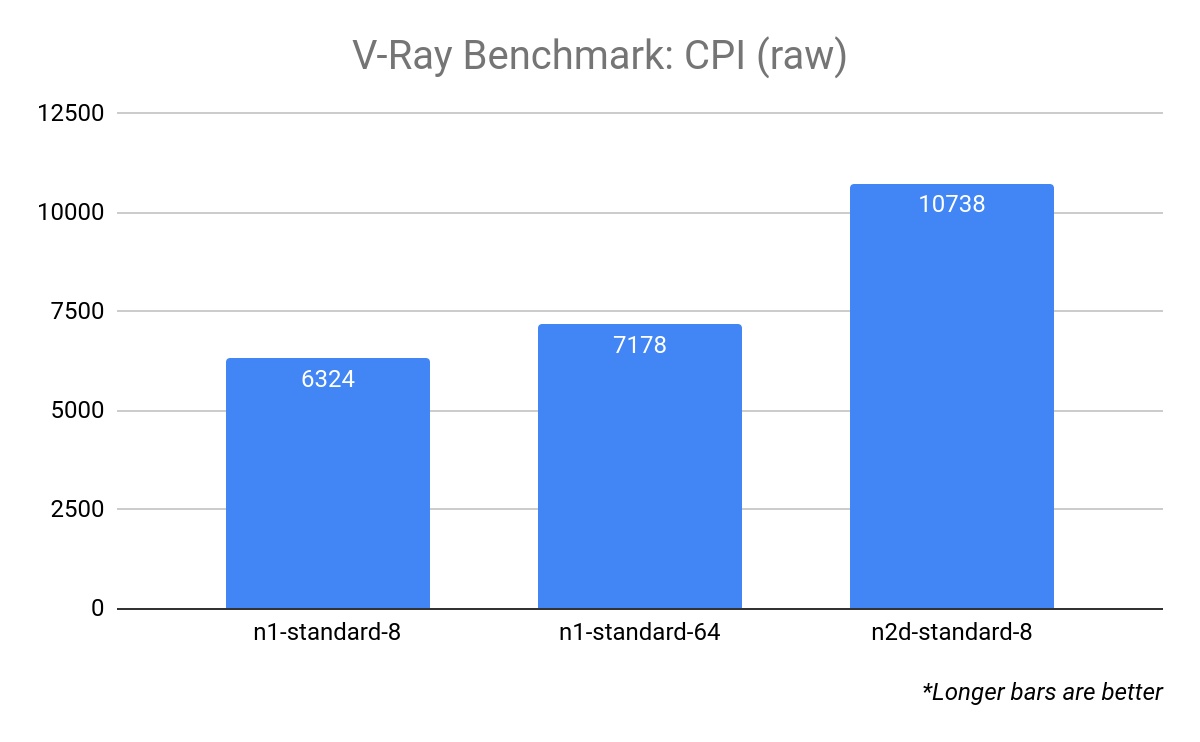
値を理解しやすくするために、ピボット ポイント、つまり CPI が 1.0 のターゲット リソースの構成を定義して値を正規化することができます。この例では、ターゲット リソースとして n1-standard-8 を使用します。
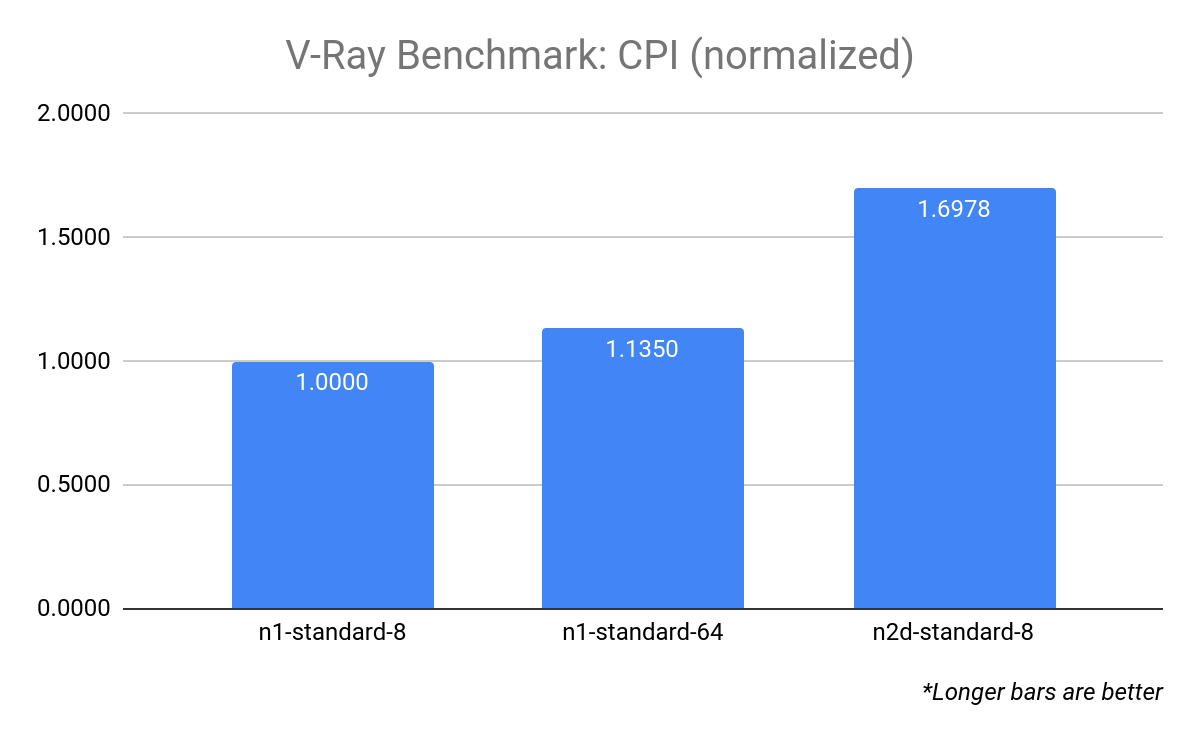
これにより、n2d-standard-8 の CPI が n1-standard-8 の CPI よりも約 70% 高いことがよくわかります。
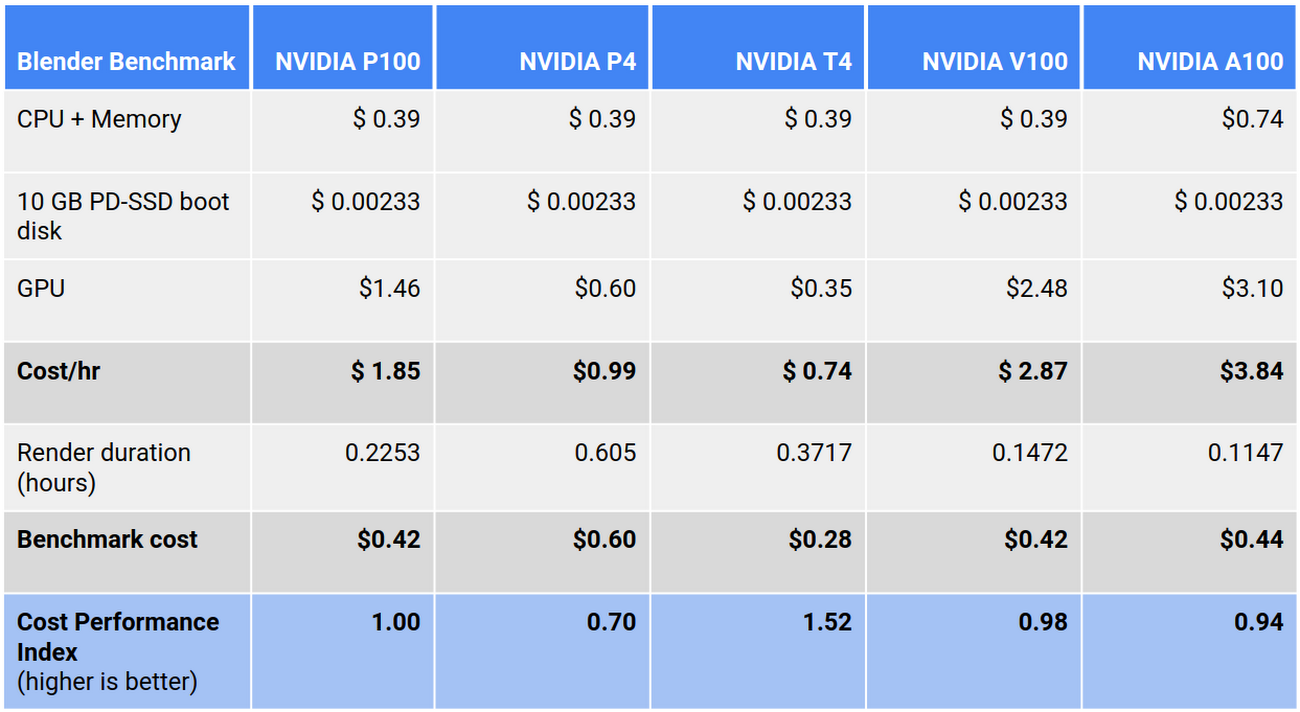
CPU ベンチマークでは、ターゲット リソースを n1-standard-8 として定義しました。GPU ベンチマークでは、ターゲット リソースを単一の NVIDIA P100 を備えた n1-standard-8 として定義しました。CPI が 1.0 より大きい場合は、ターゲット リソースと比較してコスト / パフォーマンスが優れていることを示し、CPI が 1.0 より小さい場合は、ターゲット リソースと比較してコスト / パフォーマンスが低いことを示します。
ターゲット リソースを使用して CPI を計算する式は、次のように表せます。
ベンチマークの調査セクションの CPI を使用します。
インスタンス構成の比較
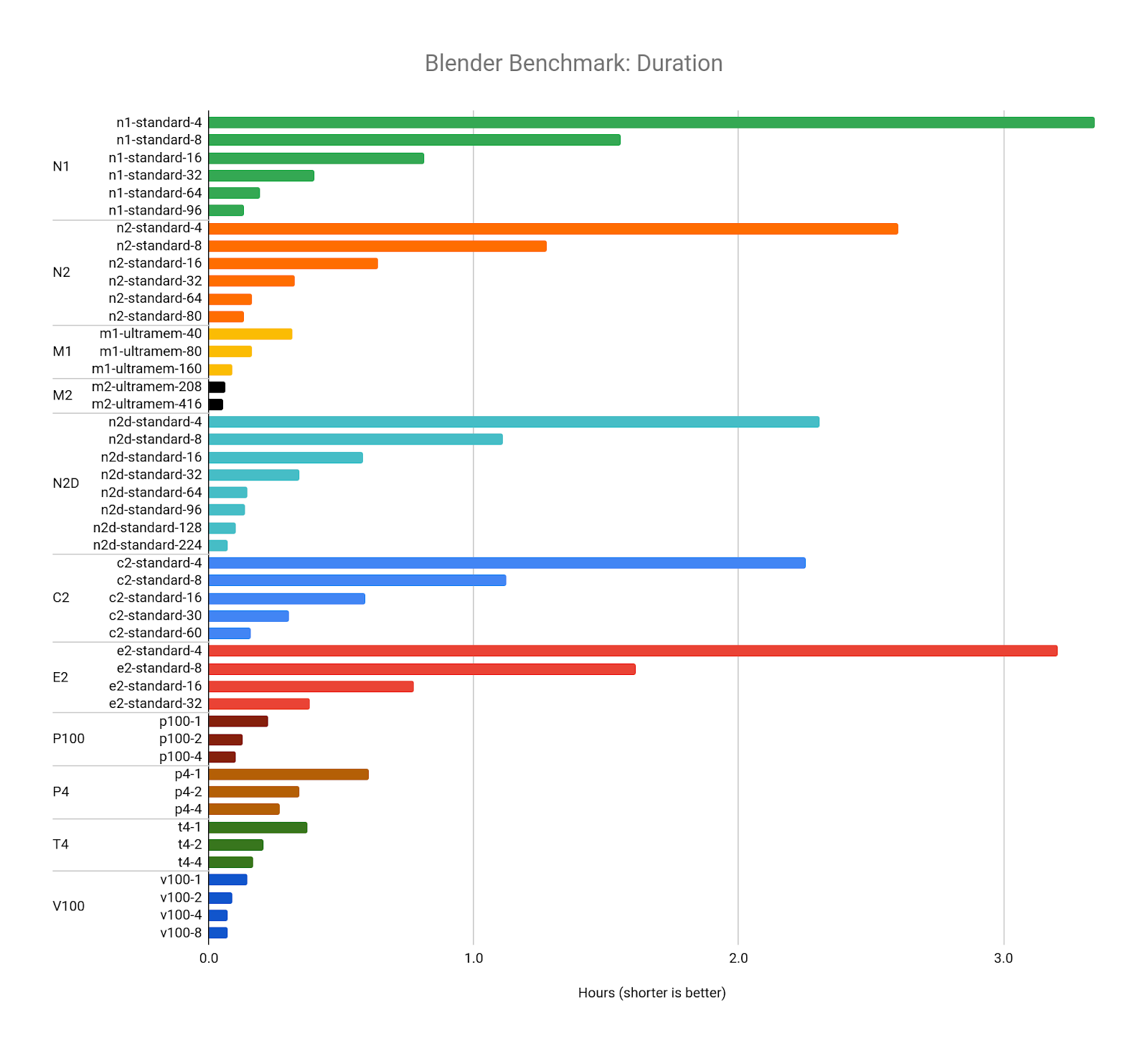
1 つ目のベンチマークでは、事前定義された N1 マシンタイプ構成間のパフォーマンスの違いを調査します。選択した 6 つの構成で Blender Benchmark を実行し、ベンチマークの実行にかかる時間とコスト(1 時間あたりのコスト × 時間)を比較すると、興味深い結果が得られます。
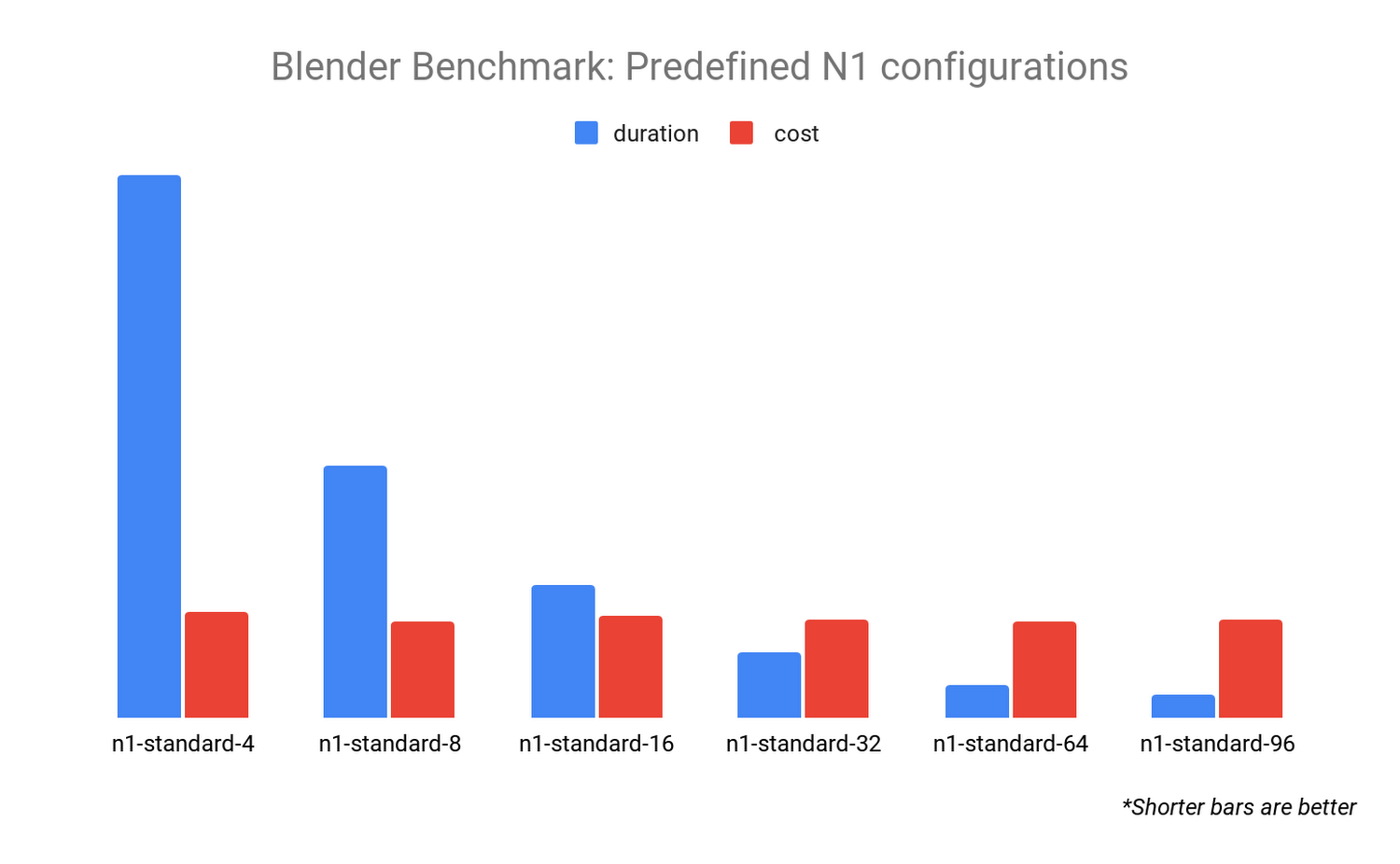
各ベンチマークのコストはほぼ同じですが、時間は大幅に異なります。これは、CPU リソースの数を増やすと、Blender レンダラが適切にスケールすることを示しています。Blender レンダラで結果をすばやく求める場合は、より多くの vCPU を備えた構成を選択するのが理にかなっています。
N1 CPU プラットフォームを他の CPU プラットフォームと比較すると、Blender のレンダリング ソフトウェアについてさらに詳しく知ることができます。16 個の vCPU を搭載したすべての CPU プラットフォームで Blender Benchmark を比較してみましょう。
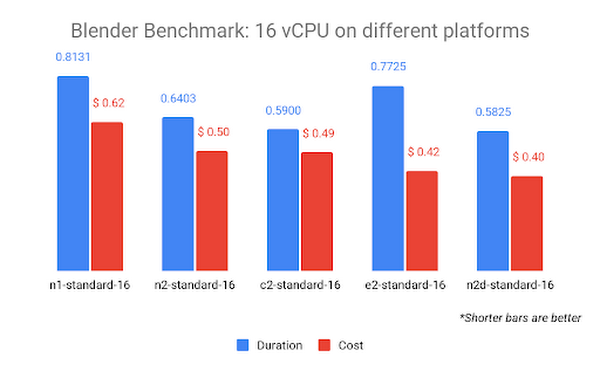
上のグラフはコスト順で、右側が最も低コストになっています。N2D CPU プラットフォーム(AMD EPYC Rome CPU)は、コストが最も低く、最短時間でベンチマークを完了します。つまり、Blender は AMD CPU でより効率的にレンダリングできる可能性を示しています。これは、ベンチマークの公開結果ページでも確認できます。C2 CPU プラットフォーム(Intel Cascade Lake CPU)は、3.9 GHz という最高の持続周波数で僅差の 2 位につけています。
注: 1 回のレンダリング テストでは少額の違いは些細なことのように思えるかもしれませんが、一般的なアニメーション機能の長さは 90 分(5,400 秒)で、24 フレーム/秒の場合、1 回の反復で約 130,000 フレームがレンダリングされることになります。一部の要素は、最終承認の前に数十回または数百回の反復になることもあります。つまり、この規模でのわずかな違いは、制作完了までのコストに大きな違いが出ることを意味します。
CPU と GPU の比較
Blender Benchmark を使用すると、同じシーンと指標を使用して CPU と GPU のパフォーマンスを比較できます。GPU レンダリングの利点は、以前の CPU の結果を単一の NVIDIA T4 GPU の結果と比較すると明らかになります。
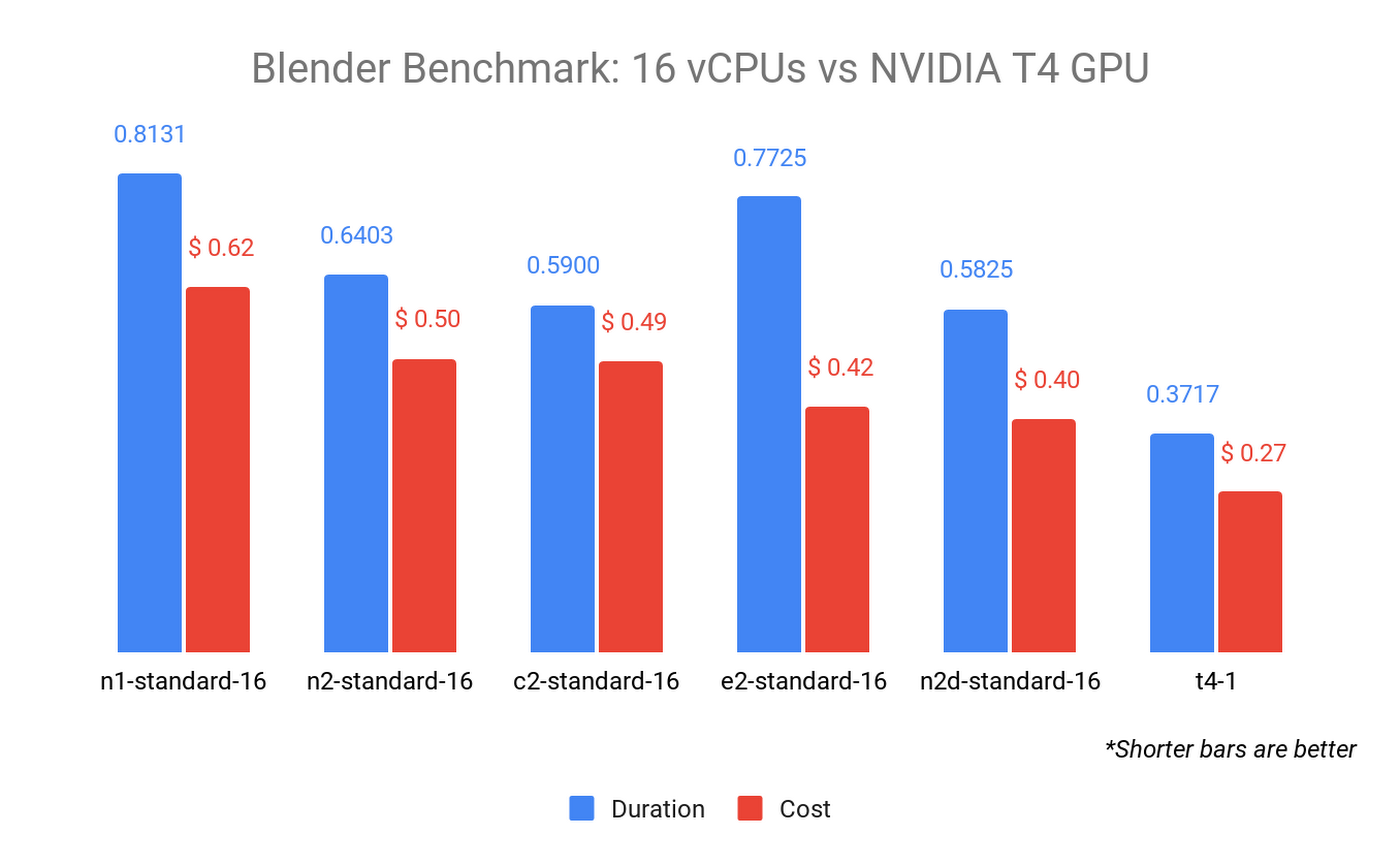
単一の NVIDIA T4 GPU が接続された n1-standard-8 で Blender Benchmark を GPU モードで実行すると、より高速かつ低コストです。すべての GPU タイプでベンチマークを実行すると、結果はコストと時間の両方で大きく異なる可能性があります。
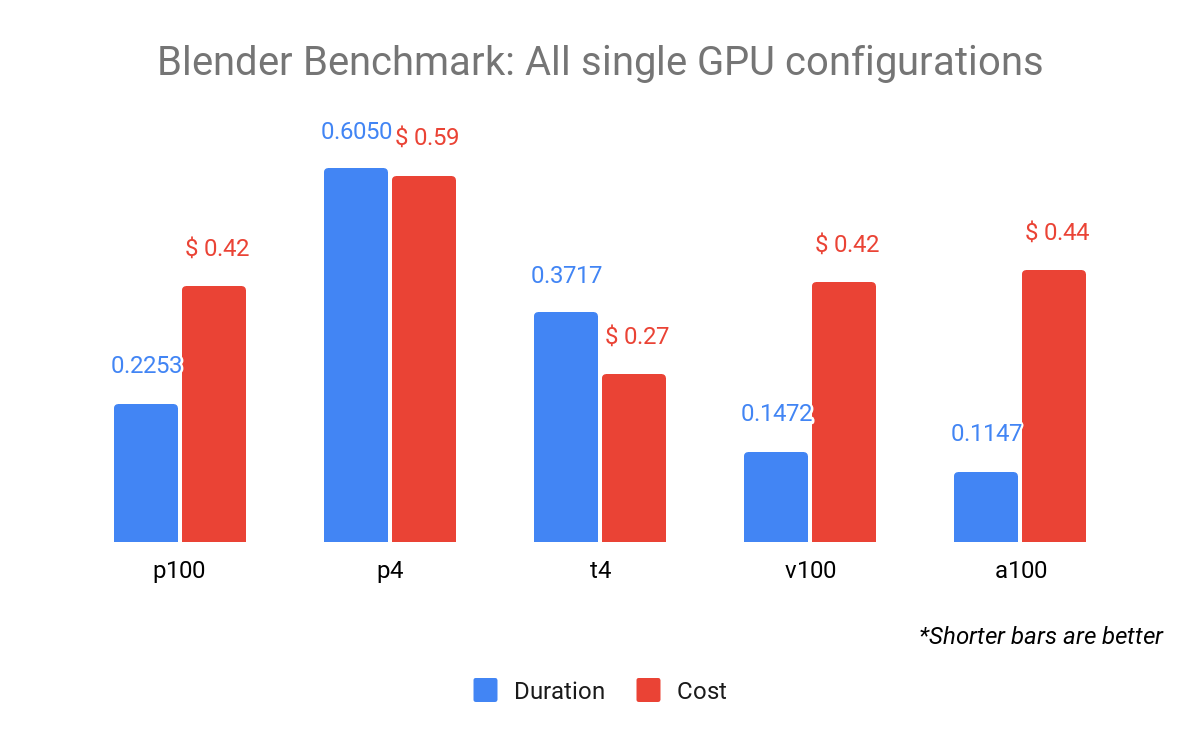
GPU パフォーマンス
一部の GPU 構成では、1 時間あたりのコストが高くなりますが、パフォーマンス仕様により、よりコストが低いリソースよりも優れたコスト パフォーマンスが得られます。
たとえば、NVIDIA Tesla A100(9.7 TFLOPS)の FP64 パフォーマンスは T4(0.25 TFLOPS)の FP64 パフォーマンスに比べて 38 倍高い一方、A100 のコストは約 9 倍になります。上の図では、P100、V100、A100 のコストはほぼ同じですが、A100 は P100 のほぼ 2 倍の速度でレンダリングを完了しました。
フリートで最も費用効果の高い GPU は NVIDIA T4 ですが、今回の特定のベンチマークでは P100、V100、A100 のパフォーマンスを上回りませんでした。
すべての GPU ベンチマーク(a2-highgpu-1g 構成を使用した A100 を除く)は、10 GB PD-SSD ブートディスクを備えた n1-standard-8 構成を使用しました。
また、複数の GPU が接続されているインスタンスで同じベンチマークを実行した場合の結果も確認できます。
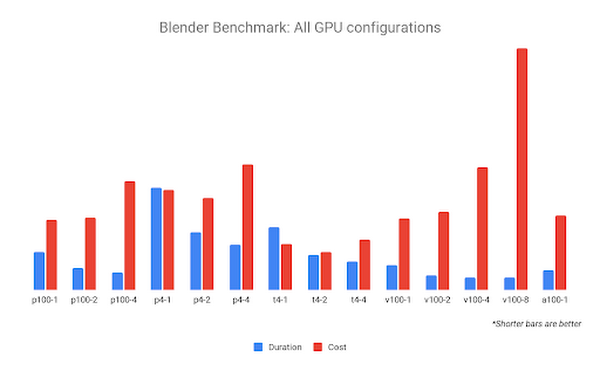
NVIDIA V100-8 構成は、ベンチマークを最速で完了する可能性がありますが、コストも最高になります。値が最も高い GPU 構成は 2x NVIDIA T4 GPU で、1x NVIDIA T4 GPU 構成よりも低いコストで十分な速度が出るようです。
最後に、すべての CPU と GPU の構成を比較します。Blender Benchmark は、スコアではなく時間を返すため、各ベンチマークのコストを使用して CPI を表すことができます。以下のグラフでは、ターゲット リソースとして n1-standard-8(1.0 の CPI)を使用し、それを他のすべての構成と比較しています。
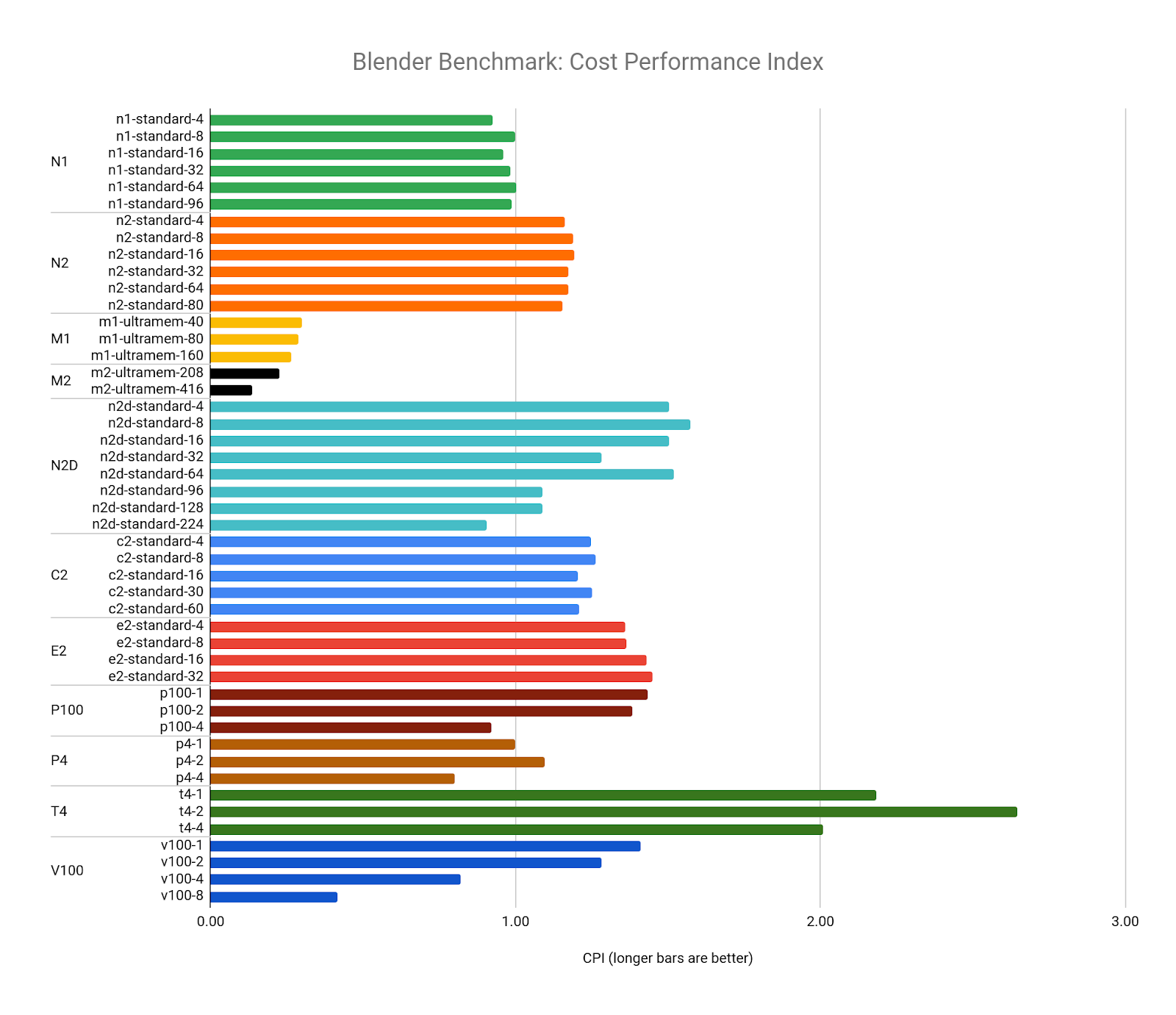
これにより、Blender Benchmark を実行するための値が最も高い構成は、GPU モードでベンチマークを実行する 2x NVIDIA T4 GPU 構成であることが確認できます。
収穫逓減
複数の GPU でのレンダリングは、単一の GPU よりも費用対効果が高い場合があります。一部のレンダラでは複数の GPU から得るパフォーマンスの向上が、コストの増加を上回ることがあり、その関係は線形になります。
複数の V100 を追加していくと、パフォーマンスの向上が低下し始めます。そのため、コストの増加を考慮したとき値も低下します。このようなパフォーマンス曲線の平坦化は、アムダールの法則の一例です。パフォーマンスを向上させるためにリソースを追加すると、パフォーマンスが向上することがありますが、あるポイントを過ぎると、パフォーマンスの収穫逓減が発生する傾向があります。多くのレンダラは 100% の並列化ができないため、リソースを追加しても直線的にパフォーマンスを向上させることはできません。
GPU リソースの場合と同様に、CPU リソース全体でも同じことが観察されます。この図では、N2D vCPU の数が増えるにつれて、ベンチマークのパフォーマンスの向上がどのように低下するかを観察しています。
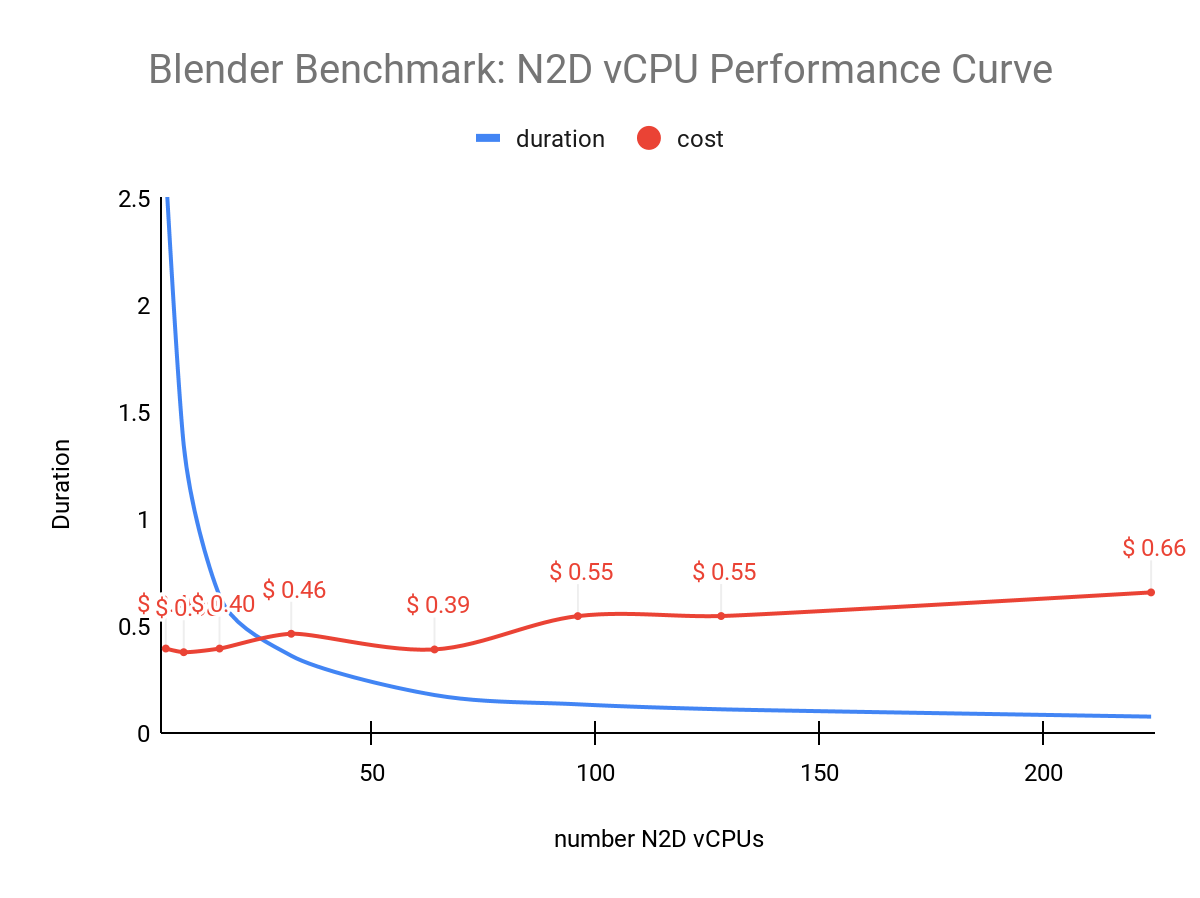
上の図は、パフォーマンスの向上が 64 vCPU を超えると低下し始め、驚くべきことに、コストが少し低下してから再び上昇することを示しています。
ベンチマークの実行
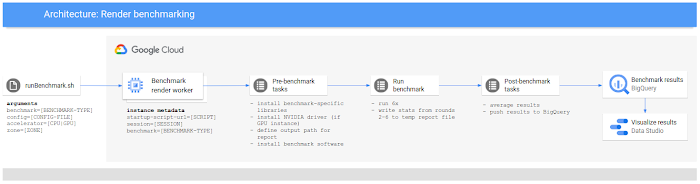
正確で再現性のある結果を保証するために、Google Cloud のシンプルなコンポーネントを使用する、シンプルでプログラマティックかつ再現可能なテスト フレームワークを構築しました。PerfKit Benchmarker などの確立されたベンチマーク フレームワークを使用することもできました。
各構成の生のパフォーマンスを観察するために、Ubuntu 1804 を実行している新しいインスタンスで各ベンチマークを実行しました。それぞれのベンチマーク構成を 6 回続けて実行し、ローカル ディスクへのキャッシュ保存またはアセットの読み込みを考慮して最初のパスを破棄し、残りのパスの結果の平均値をとりました。もちろん、この方法は、ネットワーク トラフィック、キュー管理の読み込み、アセットの同期などを考慮する必要がある本番環境の現実を必ずしも反映しているわけではありません。
ベンチマーク ワークフローは次の図のようになりました。
ベンチマークの調査
ベンチマークを行ったレンダラにはすべて、独自の品質、機能、制限があります。ベンチマークの結果から、いくつかの興味深いデータが明らかになりました。その中には、特定のレンダラまたは構成に固有のものもあれば、すべてのレンダリング ソフトウェアに共通しているものもあります。
Blender Benchmark
Blender Benchmark は、今回実行したベンチマークの中で最も広範囲をテストしたベンチマークです。Blender のレンダラ(Cycles と呼ばれる)は、CPU と GPU の両方の構成で同じベンチマークを実行できる、今回のテストで唯一のレンダラであるため、完全に異なるアーキテクチャのパフォーマンスを比較できました。
Blender Benchmark は無料で利用できるオープンソースであるため、コードを変更して独自の設定を含めることや、シーンをレンダリングすることもできます。
Blender Benchmark には、レンダリングするためのさまざまなシーンが含まれています。今回の Blender Benchmark ではすべてにおいて、次のシーンをレンダリングしました。
bmw27
classroom
fishy_cat
koro
pavillon_barcelona
前述のシーンの詳細については、Blender デモファイルのページをご覧ください。
Blender Benchmark のダウンロード(この記事に使用したバージョンは 2.90)
ベンチマークの観察
Blender Cycles は、すべての CPU と GPU 構成においてリソースの増加とパフォーマンスの向上に一貫性があるように見えますが、前述のように、一部の構成では収穫逓減の影響を受けています。
次に、コストについて考えます。いくつかの例外を除いて、使用した vCPU または GPU の数に関係なく、すべてのベンチマークのコストは $0.40 から $0.60 の間でした。
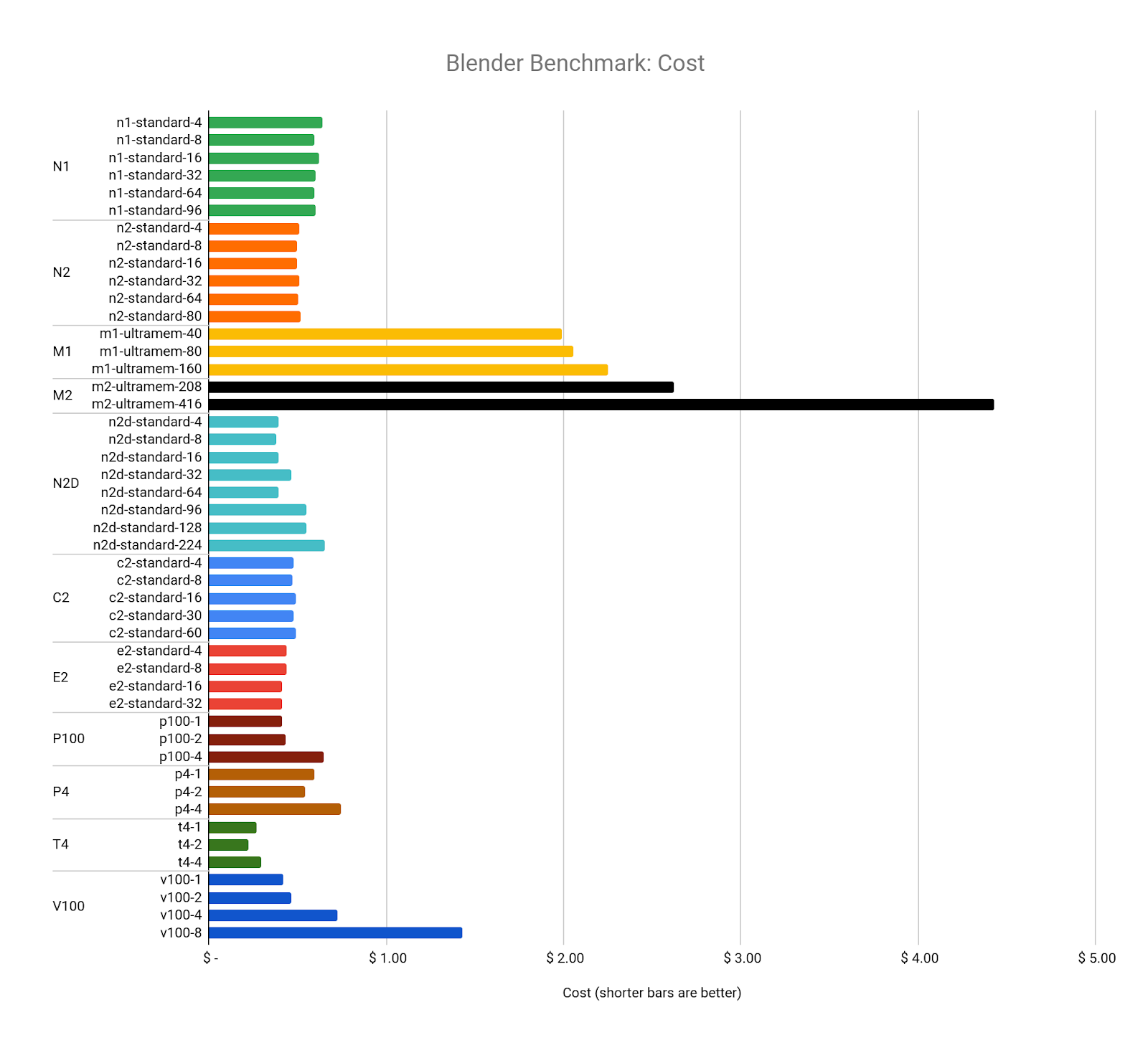
これは、Google Cloud がリソース コスト モデルをどのように設計したかを示すものかもしれませんが、各ベンチマークがまったく同じ量の作業を実行し、まったく同じ出力を生成したことは興味深い注目すべき点です。Blender Cycles の設計とそのリソース使用量の管理方法を調査することは、この記事の範囲を超えていますが、ソースコードは無料で公開されていますので、どなたでも詳細を確認できます。
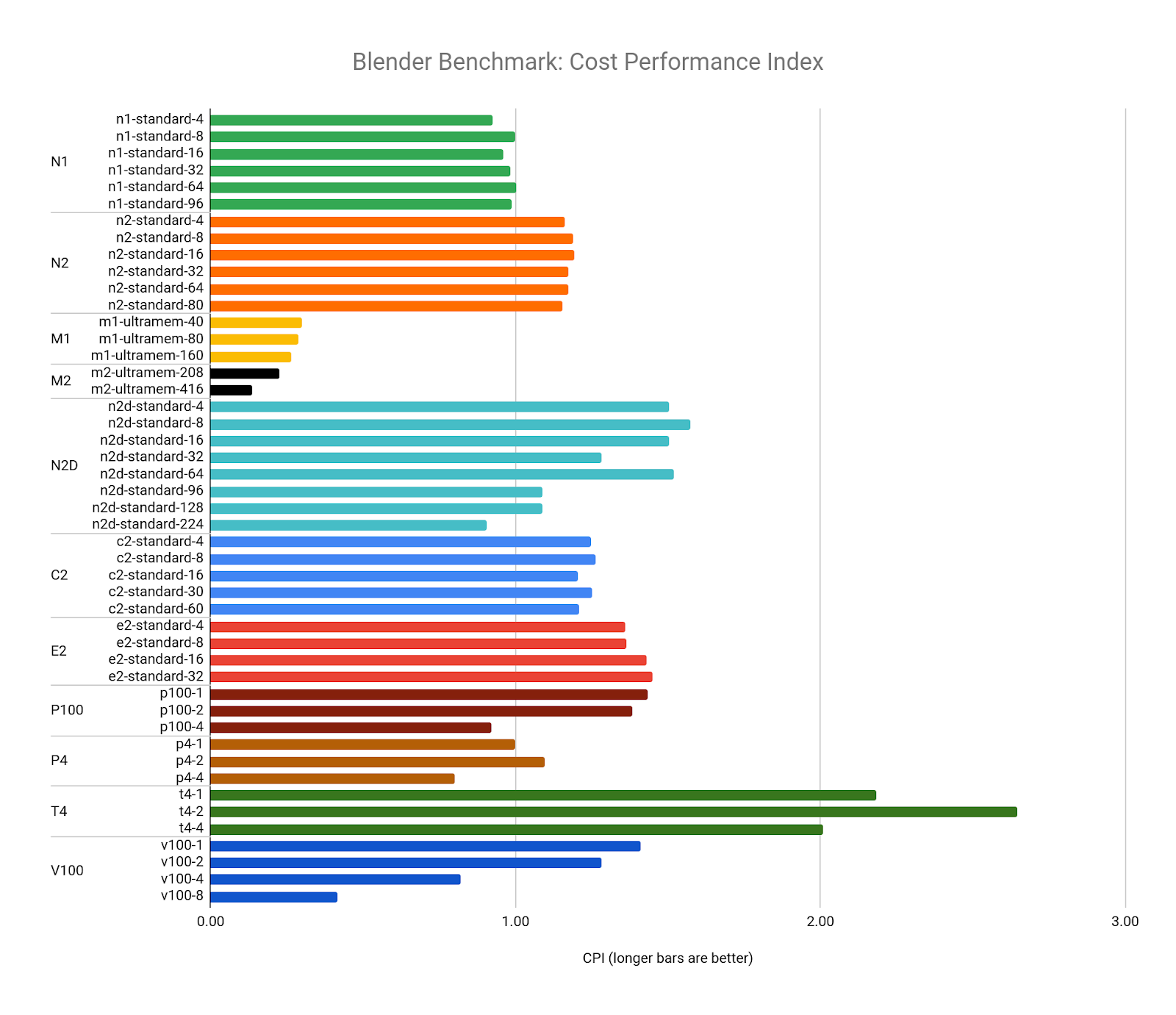
Blender の CPI はベンチマーク コストの逆数ですが、それをターゲット リソース(n1-standard-8)と比較すると、T4 GPU を任意に組み合わせても最高値の構成になることがわかります。最も値の低いリソースは M2 マシンタイプです。この原因は、コストが高いことと、大規模な vCPU 構成で見られるパフォーマンスの低下です。
V-Ray ベンチマーク
V-Ray は、Chaos Group が提供する柔軟なレンダラで、多くの 2D と 3D アプリケーションやリアルタイム ゲーム エンジンと互換性があります。
V-Ray Benchmark は、スタンドアロン プロダクトとして無料で入手でき(アカウント登録が必要)、Windows、Mac OS、Linux で動作します。V-Ray は CPU モードと GPU モードでレンダリングでき、両方を使用するハイブリッド モードもあります。
V-Ray は CPU と GPU の両方で実行できますが、ベンチマーク ソフトウェアがレンダリングするサンプルシーンは異なります。また、各プラットフォームでの結果を異なる単位(CPU は vsamples、GPU は vpaths)を使って比較します。今回、V-Ray ベンチマークの結果を別々の CPU と GPU 構成にグループ化しました。
V-Ray Benchmark をダウンロード(この記事ではバージョン 5.00.01 を使用)
ベンチマークの観察
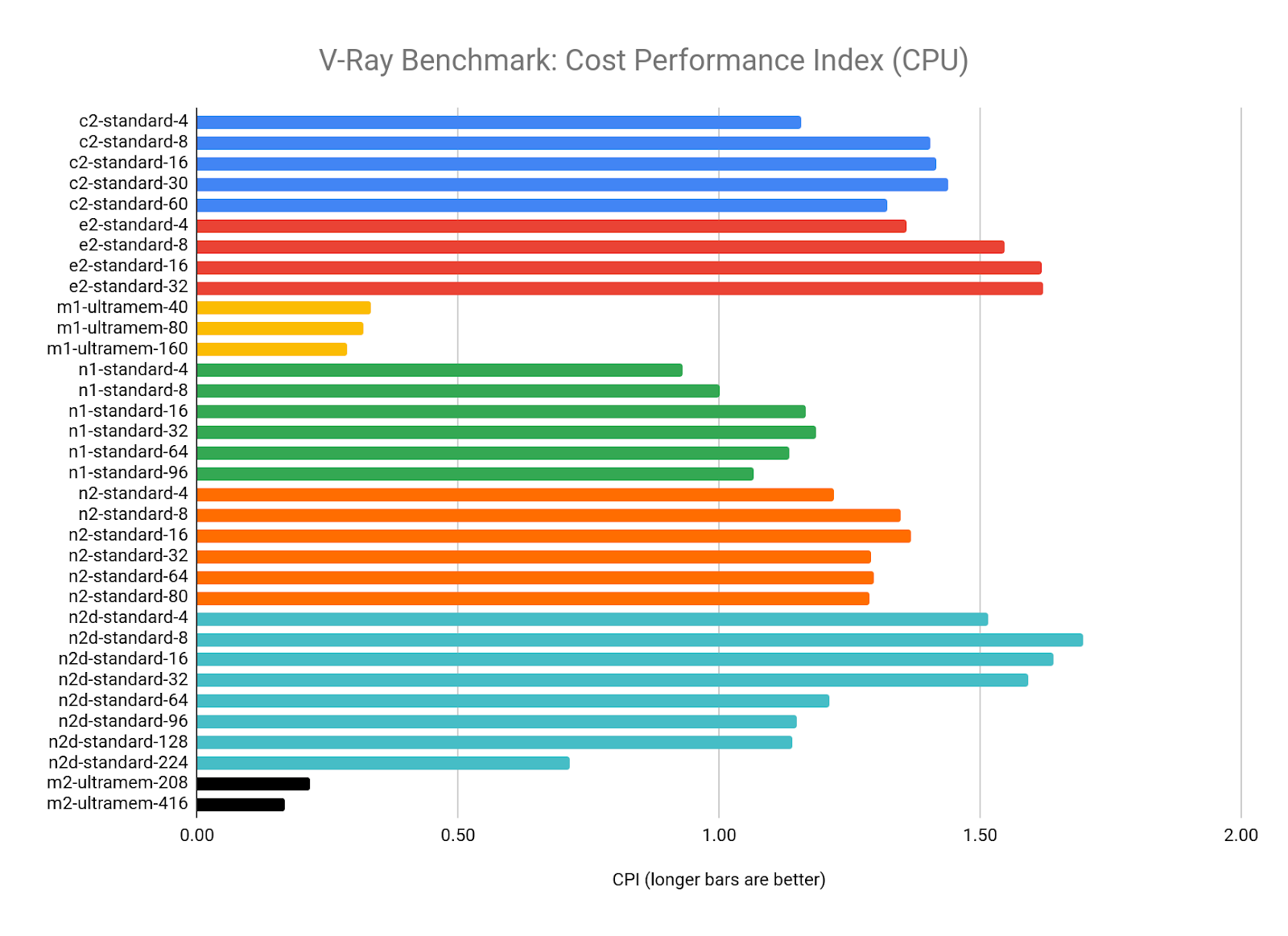
CPU レンダリング(ベンチマークに mode = vray を使用)の場合、V-Ray は vCPU の数が増えるにつれてうまくスケールでき、GCP で提供される最新の CPU アーキテクチャ、特に N2D の AMD EPYC および M2 Ultramem マシンタイプの Intel Cascade Lake の利点を活用できるようです。
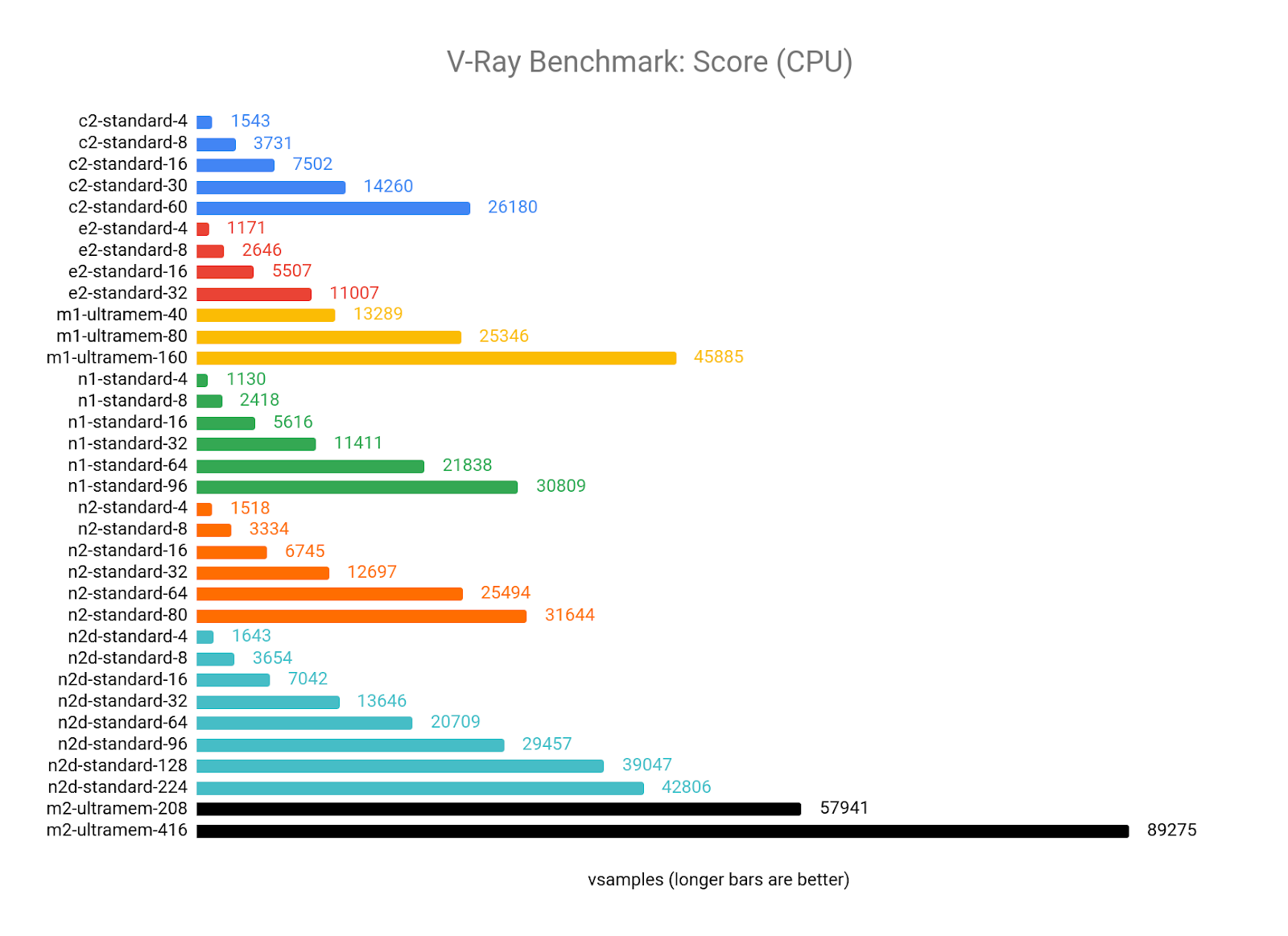
CPI の結果を見ると、V-Ray の値が最大になるのは vCPU が 8~64 個の間といえます。4 つの vCPU 構成のスコアはすべて、各マシンタイプの平均よりも低くなる傾向があり、より大きな構成では、vCPU の数が増えるにつれて収穫逓減が見られ始めます。
M1 と M2 Ultramem の構成は、優れたパフォーマンスをコストが相殺するため、ターゲット リソース(n1-standard-8)の CPI を大幅に下回っています。ただし、予算に余裕がある場合は、これらのマシンタイプから最高の生のパフォーマンスを得ることができます。
ワークロードが 32 GB の RAM に収まる場合、最適な値は N2D-standard-8 からと考えられます。
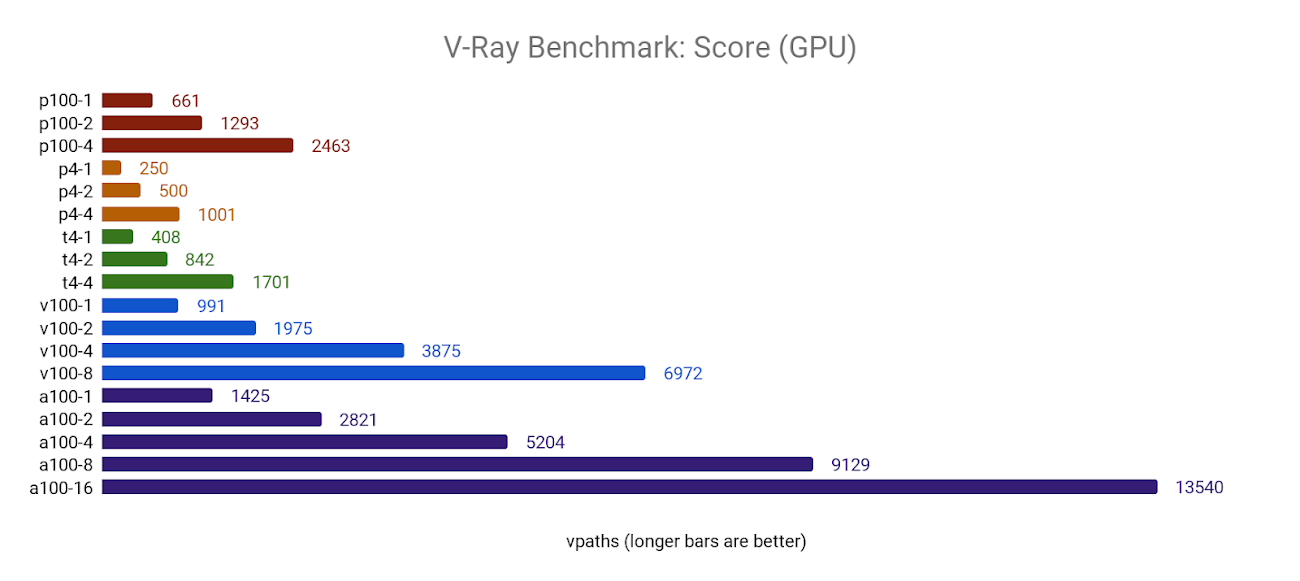
GPU モード(mode=vray-gpu-cuda を使用)では、V-Ray は複数の GPU を適切にサポートし、GPU の数に応じてほぼ直線的にスケールします。
また、V-Ray は A100 GPU の新しい Ampere アーキテクチャをうまく活用でき、V100 よりもパフォーマンスが 30~35% 向上します。
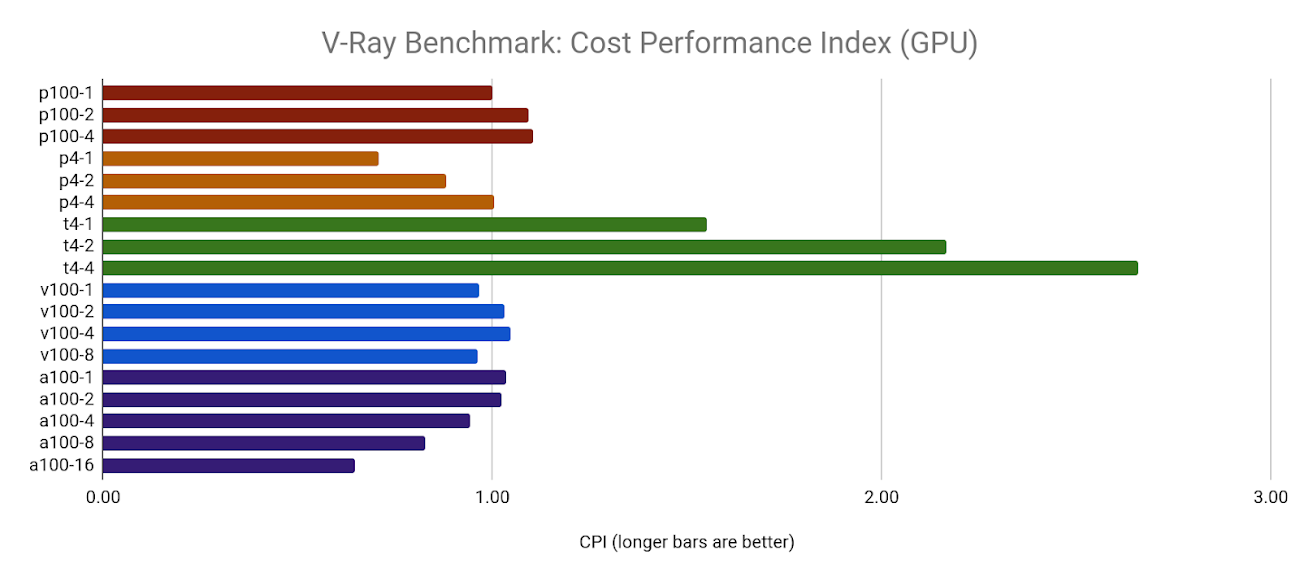
ただし、このパフォーマンスの向上にはコストがかかります。1x と 2x の A100 構成の CPI は、ターゲット リソース(1xP100)よりもわずかに優れており、4x、8x、16x 構成は、パフォーマンス能力と比較してコストが高くなっていきます。
他のすべてのベンチマークと同様に、すべての T4 GPU 構成においてフリートで最大値の GPU が明らかになりました。
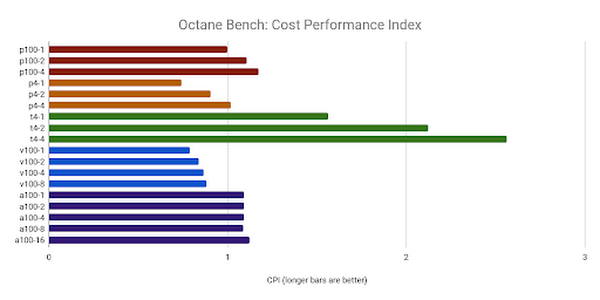
Octane Bench
Octane Render(OTOY 製)は、最も人気のある 2D、3D、ゲーム エンジン アプリケーションと統合された偏りのない GPU のみのレンダラです。
Octane Bench は無料でダウンロードでき、構成のパフォーマンスに基づいてスコアを返します。スコアは Ms/s(メガサンプル/秒)で測定され、OTOY が選択したベースライン GPU である NVIDIA GTX 980 のパフォーマンスを基準にしています。Octane Bench スコアの計算方法の詳細については、Octane Bench の結果ページを参照してください。
Octane Bench をダウンロード(この記事ではバージョン 2020.1.4 を使用)
ベンチマークの観察
Octane Render は、GCP で提供されるほとんどの GPU、特に a2-megagpu-16g マシンタイプで比較的高いスコアを獲得しました。これは、最初の公開結果において最高のスコアでした。
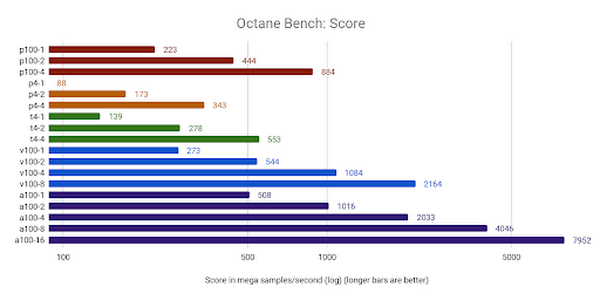
T4 のすべての構成が最大値をもたらしましたが、P100 と A100 もターゲット リソースを上回りました。興味深いことに、複数の GPU を追加すると、すべてのケースで CPI が向上しましたが、他のベンチマークでは必ずしもそうなるとは限りません。
Redshift Render
Redshift Render(Maxon 製)は偏りのない GPU による高速レンダラで、Maya、3DS Max、Cinema 4D、Houdini、Katana などの 3D アプリケーションと統合されます。
Redshift は、インストールの一部にベンチマーク ツールが含まれており、デモバージョンの場合はベンチマークの実行にライセンスが不要です。以下のリソースにアクセスするには、こちらで無料アカウントを登録してください。
Redshift をダウンロード(この記事ではバージョン 3.0.31 を使用)
ベンチマークの観察
Redshift Render は GPU の数に応じて直線的にスケールします。
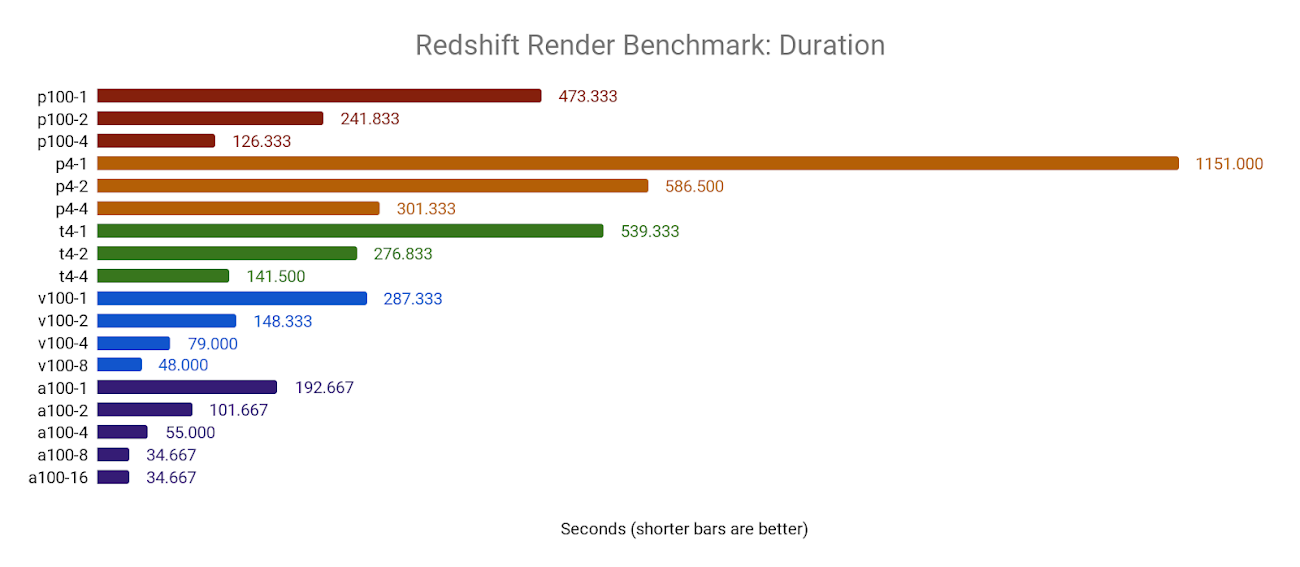
NVIDIA A100 GPU でのベンチマークでいくつかの制限があることがわかりました。8x A100 構成と 16x A100 構成はどちらも同じ結果で、4x A100 構成よりもわずかに高速でした。このような高速ベンチマークは、ソフトウェア自体の限界を押し上げているか、接続されている永続ディスクの書き込みパフォーマンスなどの他の要因によって制限される可能性があります。
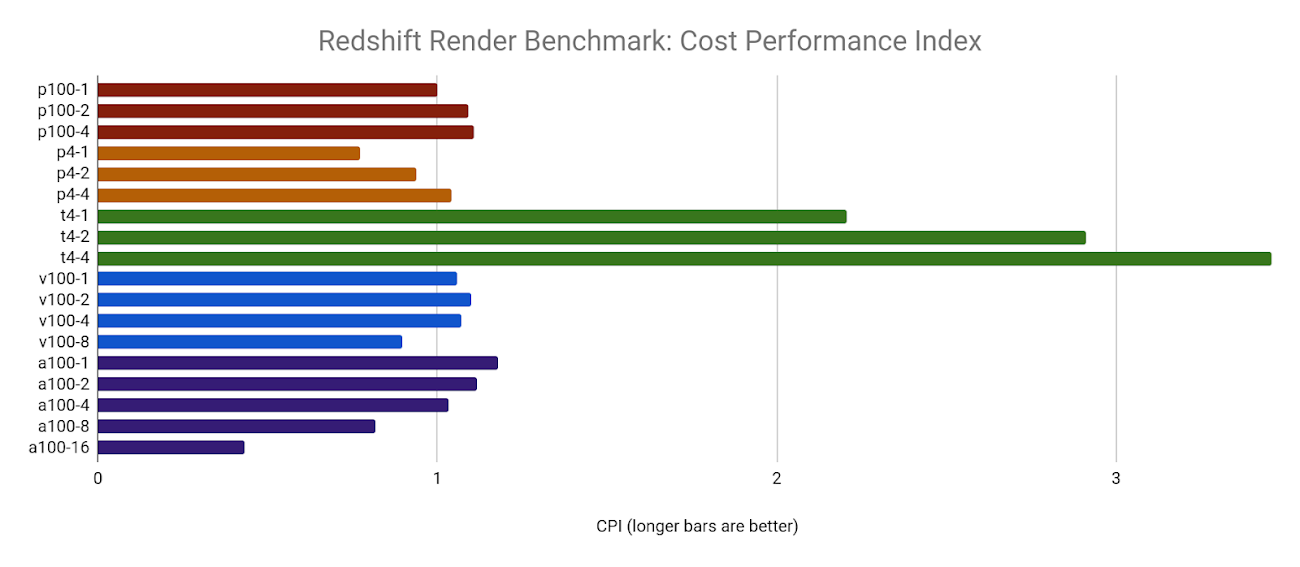
NVIDIA T4 GPU は、特に複数の GPU が使用されている場合に、低コストで競争力のあるコンピューティング パフォーマンスを発揮するため、CPI が圧倒的に高くなっています。残念ながら、8x と 16x A100 GPU に見られた制限により、CPI が低くなります。これはこのベンチマーク アーキテクチャとサンプルシーンの制限が原因である可能性があります。
要点
このデータは、レンダリング ワークロードを実行するお客様が、個々のジョブ要件、予算、期限に基づいて、使用するリソースを決定するのに役立ちます。この調査の要点を以下に簡単に示します。
時間に制約がなく、レンダリング ジョブが大量のメモリを必要としない場合は、N2D または E2 マシンタイプなど、CPI が高い、より小規模でプリエンプティブな構成を選択することをおすすめします。
納期が迫っていて、コストをあまり気にしない場合は、M1 や M2 マシンタイプ(CPU の場合)または A2 マシンタイプ(GPU の場合)で最高のパフォーマンスが得られますが、プリエンプティブとして利用できないことや、選択したリージョンで利用できないことがあります。
まとめ
この調査が、各コンピューティング プラットフォームの特性や、コンピューティング ワークロードに対するパフォーマンスとコストの関連性について理解を深めるために、お役に立てば幸いです。
今回実行したすべてのレンダリング ベンチマークに関する最終的な観察結果は次のとおりです。
CPU レンダラについては、N2D マシンタイプが、妥当なコストで優れた柔軟性(単一の VM で最大 224 個の vCPU)と最高のパフォーマンスを実現する。
GPU レンダラについては、NVIDIA T4 が、RTX と TensorFlow の両方のワークロードを実行できる低価格の Turing アーキテクチャにより、最大値を実現する。ただし、各 GPU は 16 GB のメモリに制限されているため、T4 では一部の大きなジョブを実行できない場合がある。より多くの GPU メモリが必要な場合は、接続されているすべての GPU メモリを統合するために、NVLink を提供する GPU タイプを検討する必要がある。
純粋な馬力を考えると、M2 マシンタイプが、驚異的な量のメモリ(最大 11.7 GB)を備えた大量のコア数(4.0 GHz で動作する最大 416 個の vCPU)を提供する。これはほとんどのジョブにとっては過剰かもしれないが、Houdini での流体シミュレーションや 16 k のアーキテクチャ レンダリングでは、正常に完了するためにリソースの追加が必要になる場合がある。
納期が迫っている場合や、土壇場での変更に対処する必要がある場合は、さまざまな構成の CPI を使用して、モデルの本番環境ワークロードにコストをかけることができる。パフォーマンス指標と組み合わせると、ジョブのコスト、所要時間、特定のアーキテクチャでのスケーラビリティを正確に見積もることができる。
A2 マシンタイプの A100 GPU は、以前の NVIDIA GPU 世代に比べて大幅な向上をもたらすが、すべての構成ですべてのベンチマークを実行できなかった。このテストを実施したとき、Ampere プラットフォームは比較的新しく、すべての GPU 対応レンダリング ソフトウェアで Ampere のサポートがリリースされていなかった。
一部のお客様は、値に関係なく、仕事の要求に基づいてリソースを選択しています。たとえば、GPU レンダリングは、異常に大量のテクスチャ メモリを必要とし、NVLink を提供する GPU タイプでのみ正常に完了できる場合があります。また、コストを問わず、レンダリング ジョブを短時間で完了する必要があるシナリオもあるでしょう。このどちらのシナリオでも、ユーザーは、CPI が最も高い構成ではなく、ジョブを完了できる構成を選択する可能性があります。
レンダリング ワークロードは 2 つとして同じものはなく、あらゆるジョブのコンピューティング要件を完全に満たす単一のベンチマークはありません。独自の概念実証レンダリング テストを実行して、独自のソフトウェア、プラグイン、設定、シーンデータがクラウド コンピューティング リソースでどのように機能するかを測定することをおすすめします。
その他のベンチマーク リソース
ディスク、メモリ、ネットワーク パフォーマンスなどの他の指標のベンチマークは実施していないことに注意してください。詳細や Google Cloud で独自のベンチマークを実行する方法については、次の記事をご覧ください。
Linux と Windows の VM インスタンスに関する PerfKitBenchmarker の結果
-シニア Cloud ソリューション アーキテクト Adrian Graham




