Google Cloud の導入を促進する 13 のサンプル アーキテクチャ
Google Cloud Japan Team
※この投稿は米国時間 2020 年 8 月 18 日に、Google Cloud blog に投稿されたものの抄訳です。
組織のパフォーマンスやコストニーズがどのようなものであれ、Google Cloud は非常に柔軟なプラットフォームであり、数も種類も豊富なアプリケーション アーキテクチャをサポートしています。では、導入にあたって何から始めればよいでしょうか。
Google Cloud デベロッパー アドボケイトとして、先日 Twitter で 13 days of GCP(GCP の 13 日間) というシリーズを立ち上げました。このシリーズでは、一般的な Google Cloud リファレンス アーキテクチャを紹介しました。この記事では、そちらで紹介したものをすべてまとめています。ハイブリッド クラウドやモバイルアプリ、マイクロサービス、CI / CD、機械学習、セキュリティなど、何をデプロイしたいのかにかかわらず、この記事を読むことで Google Cloud の導入方法について詳しく理解できることでしょう。(この記事で紹介するものはほんの一例であり、各ソリューションを達成する方法はこの他にもあります。)
1. Google Cloud とオンプレミスでハイブリッド アーキテクチャを設定する
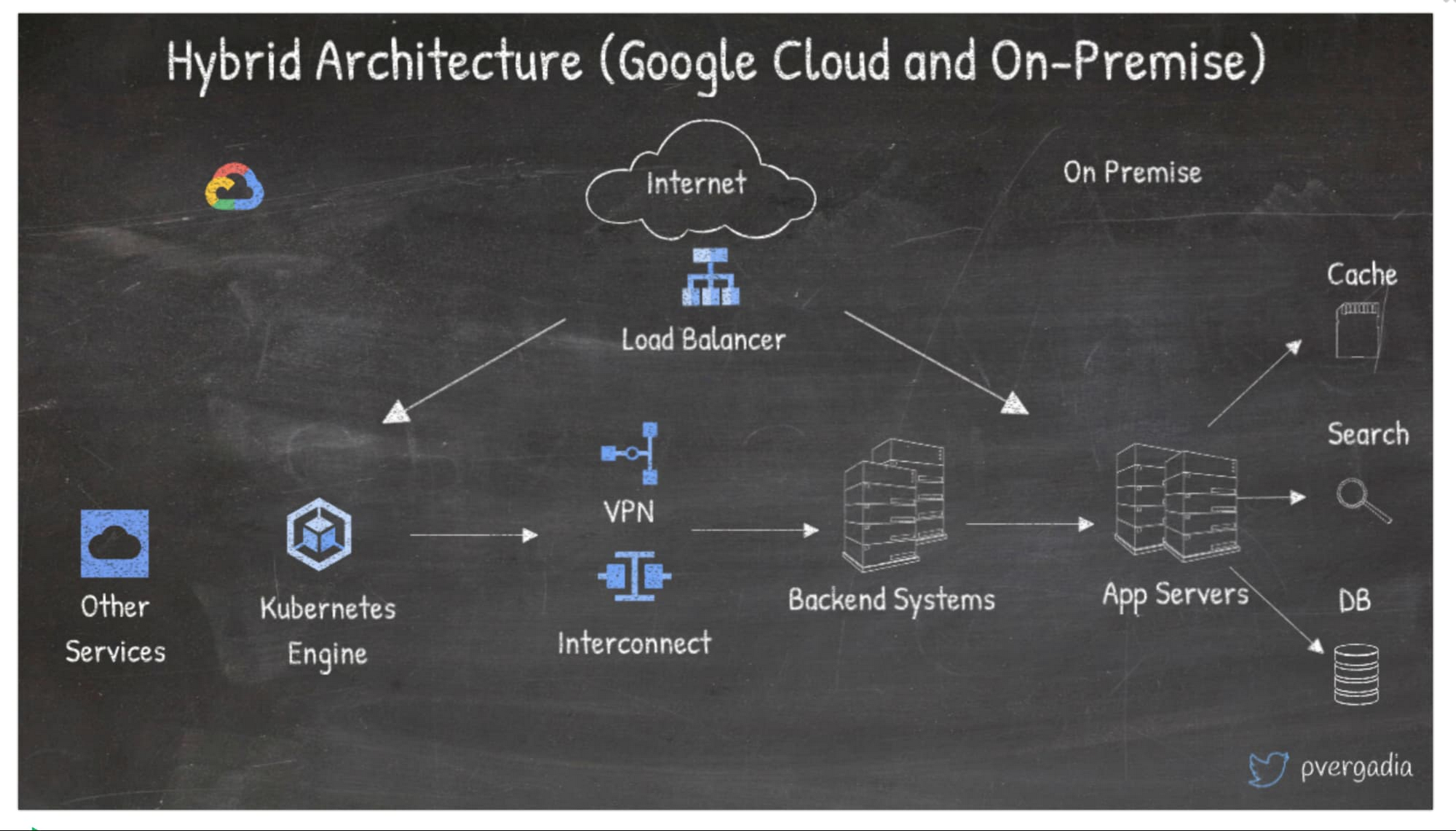
システムを移行する場合やプリケーションの一部をオンプレミス、一部をクラウドで実行する場合には、ハイブリッド アーキテクチャが一般的です。ごく一般的なのは、フロントエンドとアプリケーション サーバーの両方またはどちらかを Google Cloud でデプロイし、バックエンドをオンプレミスにしたハイブリッド アーキテクチャです。
- この場合、ユーザーはインターネットを介してアプリケーションをリクエストし、グローバル ロードバランサがリクエストを Google Cloud 上、もしくはオンプレミスのアプリケーションにルーティングします。
- その後、グローバルな負荷分散によってトラフィックを分配し、適切なサービスに負荷分散を行います。サービスは Compute Engine、Google Kubernetes Engine(GKE)、App Engine など、どのコンピューティング プラットフォームでも実行できます。
- お客様のデータセンターにあるバックエンド システムと通信するアプリケーションは、お客様の帯域幅の要件に応じて Cloud VPN または Interconnect を介して接続する必要があります。どれを選べばよいか判断できない場合は、こちらをご覧ください。
- オンプレミス アプリケーションのリクエストはロードバランサに送られ、そこからアプリケーション サーバー全体に負荷が分散されます。
- ユーザーのリクエストを実行するため、アプリケーション サーバーは検索、キャッシュ、データベースなどのバックエンドに接続します。
ハイブリッド ソリューションについて詳しく知るには、こちらのソリューションをご覧ください。
2. クラウド バースト機能を活用するためのハイブリッド アーキテクチャを設定する
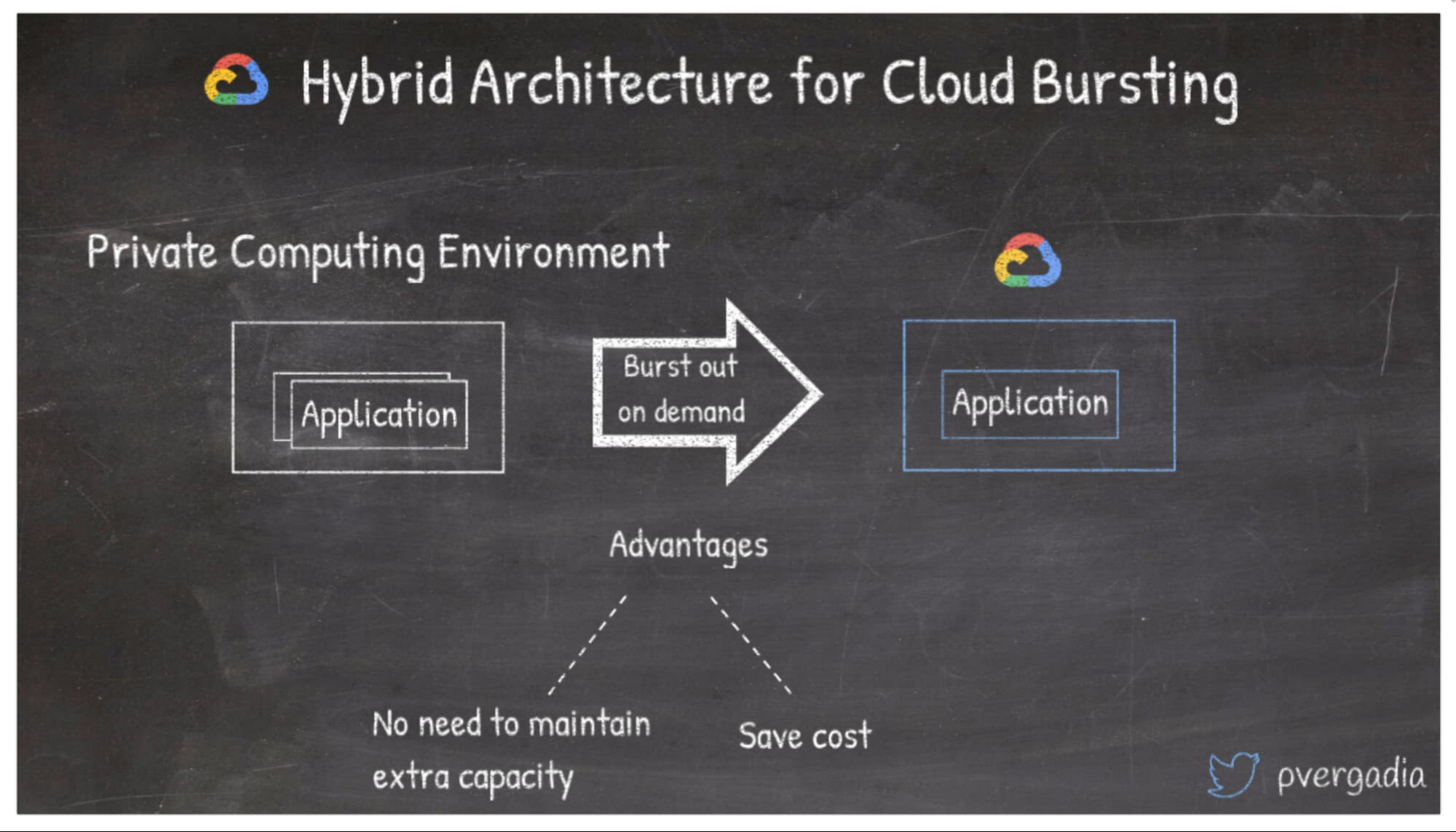
クラウドへのトラフィックのバースティングはクラウドの導入を開始するうえでうってつけの方法です。オンプレミスのアプリケーションの場合、ベースラインのワークロードはオンプレミスでデプロイし、トラフィックが突然増加して追加の容量が必要になった際に、一時的に Google Cloud にバーストできます。これを実施する主な理由は、オンプレミスで追加の容量を管理する手間を省くことです。また、Google Cloud では料金は使用した分だけ請求されるので、バースト機能はコスト削減にもつながります。
ハイブリッドのソリューションとパターンについて詳しく知るには、こちらをクリックしてください。
3. データ損失防止(DLP)API を使用して、chatbot の機密データをマスクする
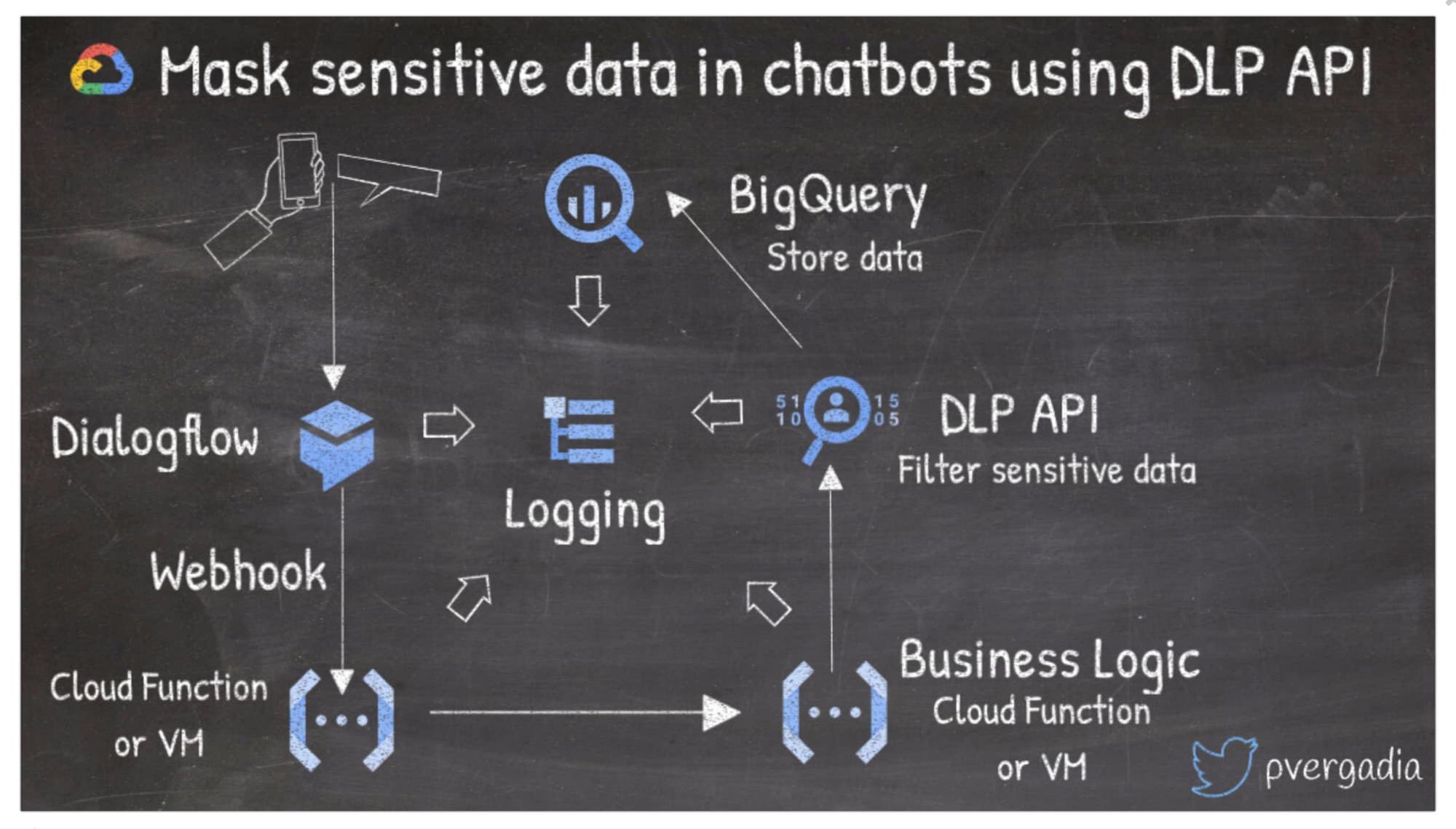
ビジネス上、もしくはユーザーが機密情報を chatbot を使用して共有するシチュエーションを想定してみましょう。Dialogflow を使用することで、機械学習や人工知能についての知識なしで自然な会話環境をユーザーに提供できます。
たとえば、このアーキテクチャでは、ユーザーはスマートフォンもしくはウェブ上でチャット機能を使い、Dialogflow エージェントを呼び出します。リクエストはサーバーレスの Cloud Functions または仮想マシンを使用したビジネス ロジックにより実行されます。チャットの機密情報を匿名化する場合は、DLP API を使用して BigQuery に保存し、さらなる処理を実施できます。
4. Google Cloud でモバイルアプリのバックエンドをビルドする
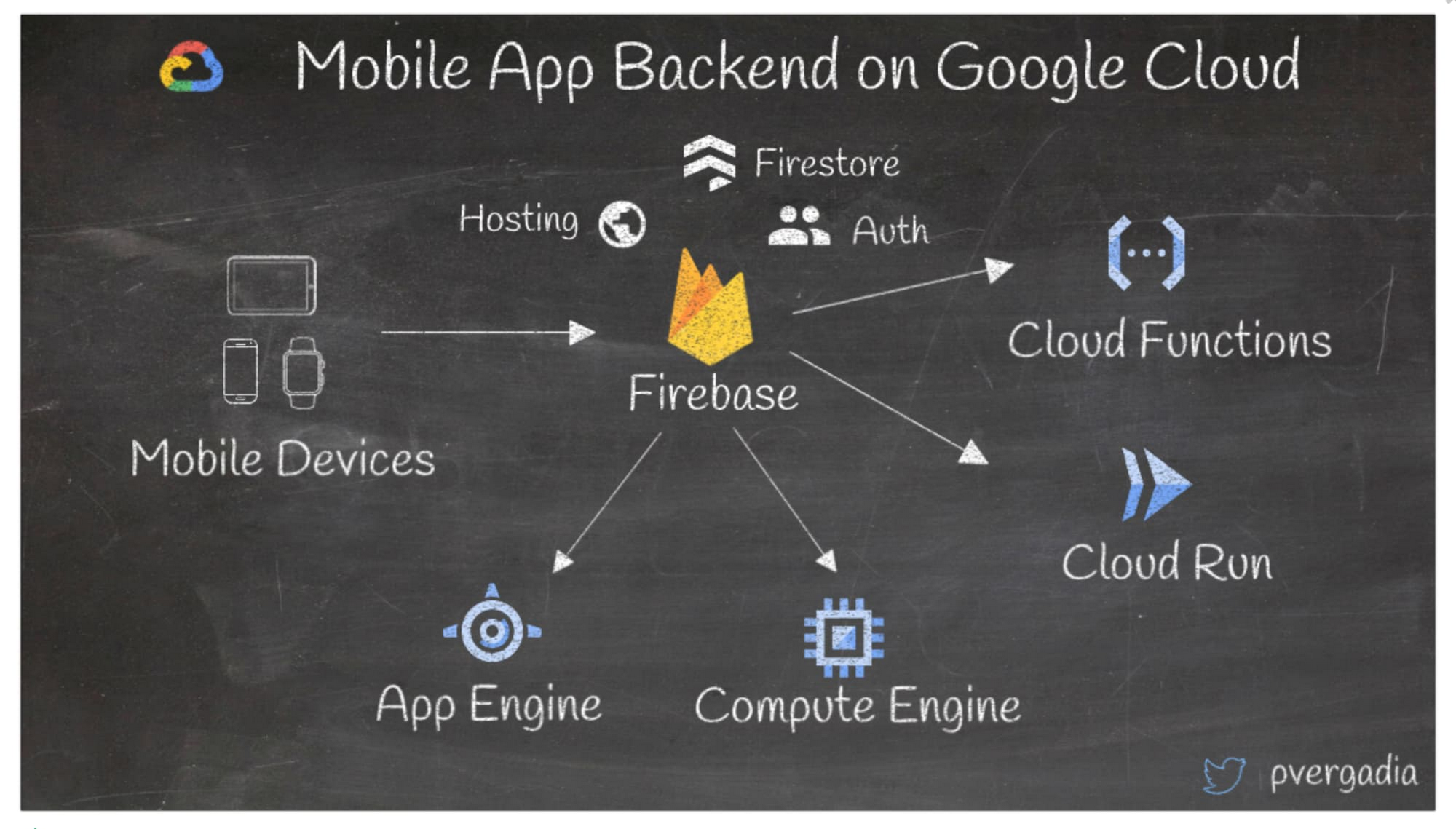
Google Cloud でモバイルアプリをビルドする際、ストレージ、ユーザー認証、ホスティングなどには Firebase が適しています。Firebase はサーバーレスの Cloud Functions と統合しビジネス ロジックをつなぎ合わせたり、または Cloud Run と統合しサーバーレス コンテナをアプリのバックエンドとして運用するなど、複数のバックエンドと統合できます。また、App Engine と Compute Engine にバックエンドが存在する場合、これらにも接続できます。
詳しくは、こちらのシリーズをご覧ください。
5. Oracle データベースを Spanner に移行する
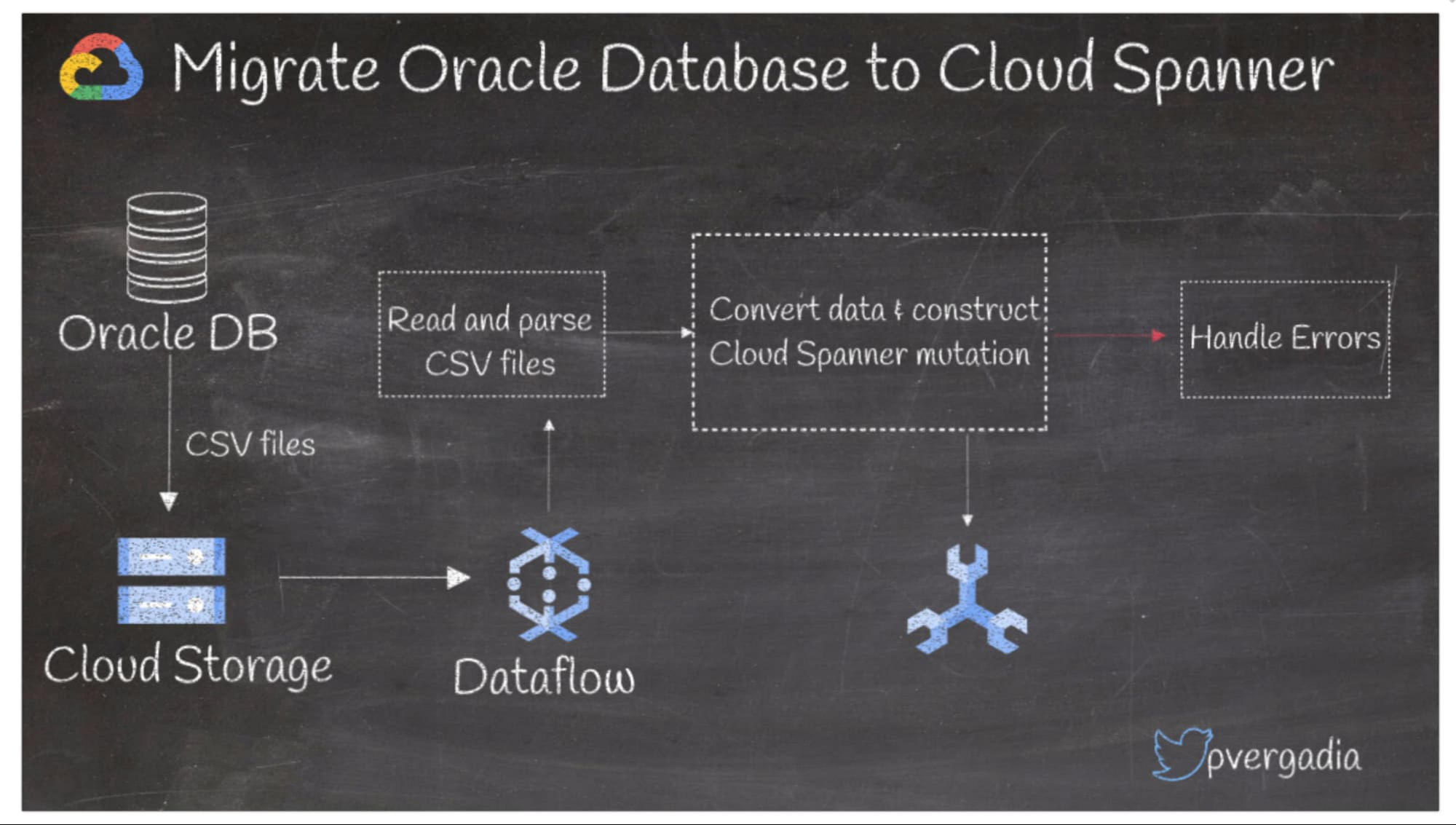
Oracle を Cloud Spanner に移行する最適な方法とは何でしょうか。Oracle データベースを使用しており、グローバル規模の Spanner に移行を考えている場合、最初にすべきことは、Oracle データベースを CSV などのポータブル ファイル形式でエクスポートして Cloud Storage に保存することです。次に、データを Dataflow に取り込みます。ここで、ファイルの読み取りと解析を行い、データを変換して Spanner ミューテーションを構築し、エラーを処理した後、Spanner への書き込みを行います。
詳しくは、こちらのソリューションをご覧ください。
6. Google Cloud でデータレイクを構築する
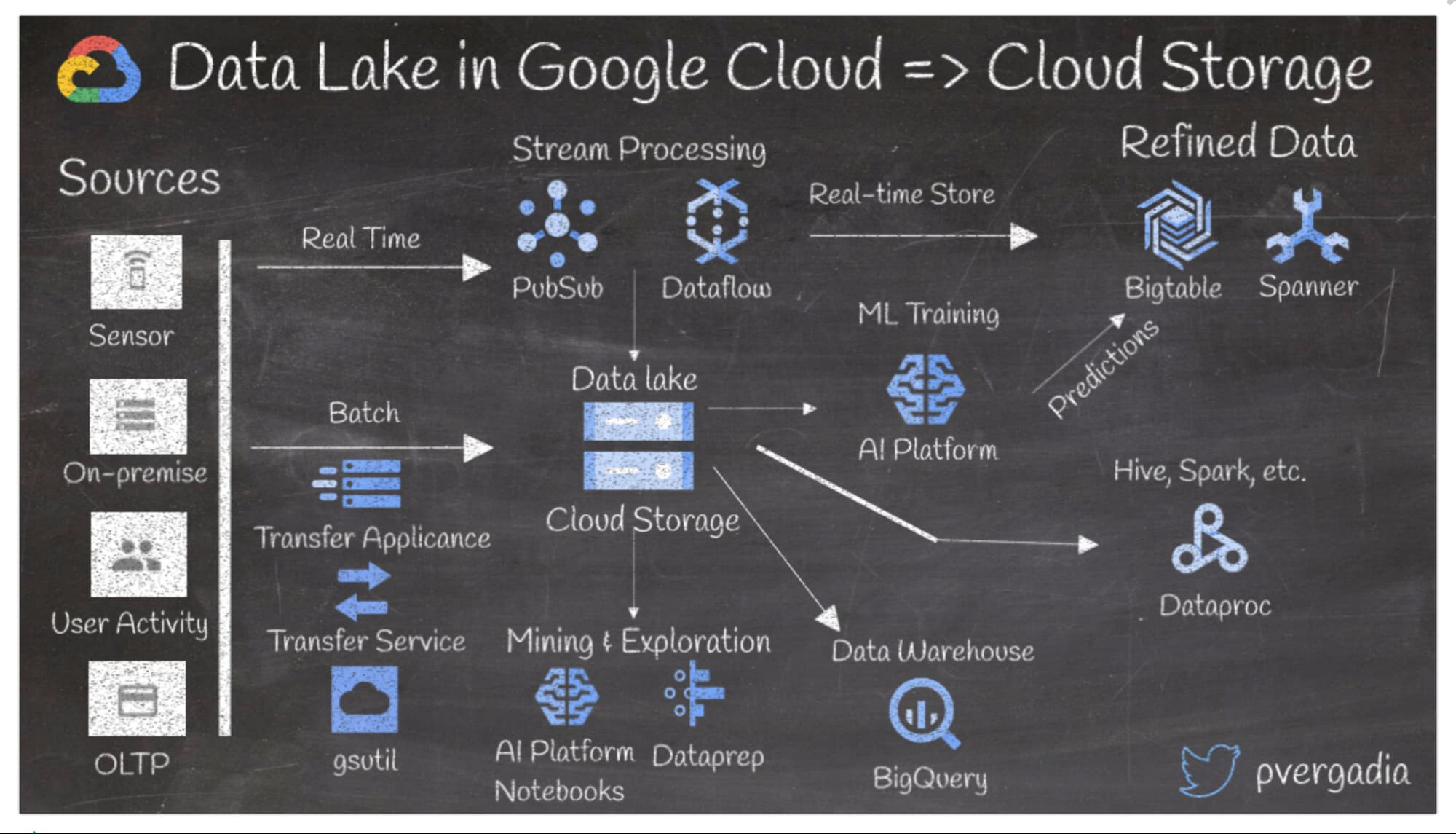
データレイクの目的は、マイニングやデータマート、リアルタイム解析、機械学習などのワークフロー用にデータを取り込み、保存することです。以下では、Google Cloud でデータレイクを設定する際に考慮すべき点を挙げます。
- データは、IoT センサー、オンプレミス、クリック ストリームなどのユーザーのアクション、オンライン取引など、さまざまなソースから取り込めます。
- リアルタイム データは、Pub/Sub と Dataflow を使用して取り込めます。データ量の変化に合わせて容易にスケーリングが可能です。
- バッチデータは、帯域幅とボリュームに応じて、Transfer Appliance、Transfer Service、gsutil のいずれかを使用して取り込めます。調整したリアルタイム データは、Bigtable または Spanner に保存できます。
- データレイクのデータ マイニングには、Datalab と Dataprep を使用します。機械学習については、Datalab または Machine Learning Engine を使用してトレーニングを行い、Bigtable に予測を保存します。
- ウェアハウジングについては、データを BigQuery に送ります(Hive エコシステムのユーザーの場合は、Dataproc に送ります)。
詳しくは、Cloud Storage をデータレイクとして使用する場合のソリューションをご覧ください。
7. Google Cloud でウェブサイトをホストする
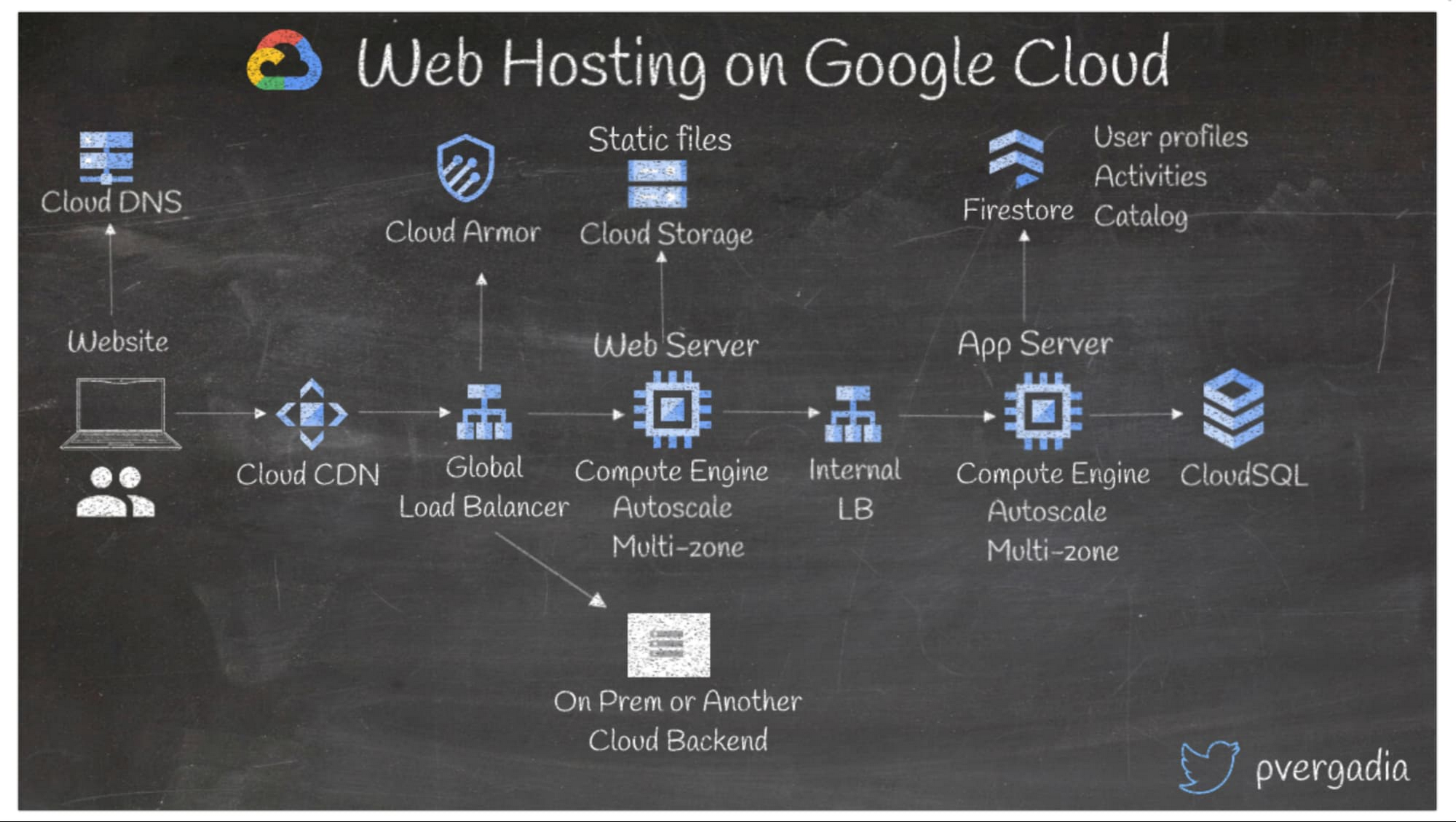
トラフィックに基づいてウェブサイトをスケーリングするのは簡単ではありません。Google Cloud では、シンプルで費用対効果の高い方法でウェブサイトをホストでき、多数のリクエストをサポートするスケーリングが可能です。以下では、Google Cloud でウェブサイトをスケーリングする方法について説明します。
- ウェブサイトにユーザーがリクエストを送信すると、Cloud DNS はホスト名をウェブサーバーの IP アドレスに変換します。
- 次に、リクエストは Cloud CDN に送られ、Cloud CDN はキャッシュから応答します。キャッシュに保存されているレスポンスがない場合、リクエストはグローバル ロードバランサに送られ、Compute Engine のウェブサーバー全体に負荷分散を行います。オンプレミス、または別のクラウドをバックエンドとして設定することもできます。
- 画像のような静的ファイルは Cloud Storage から提供されます。その後、内部ロードバランサによって、リクエストがアプリサーバーに送られ、最終的に任意のデータベースに送られます。
- ユーザーのプロフィールとアクティビティについては、Firestore ドキュメント データベースを使用します。
- リレーショナル データには、CloudSQL を使用します。
- バックエンドをレイヤ 3 とレイヤ 4 の DDoS 攻撃から保護するには、グローバル ロードバランサが備わった Cloud Armor を有効にします。
- この例では、Compute Engine をバックエンドとして使用していますが、GKE、Cloud Run、App Engine で動作するコンテナにバックエンドをデプロイすることも可能です。
- Compute Engine を使用する際にインフラストラクチャをスケーリングするには、負荷の増加に合わせて自動でスケーリングするマネージド インスタンス グループを使用します。(App Engine と Cloud Run は負荷に合わせて自動でスケーリングします)。
詳しくは、こちらのウェブ ホスティング ソリューションをご覧ください。
8. Google Cloud で CI / CD パイプラインを設定する
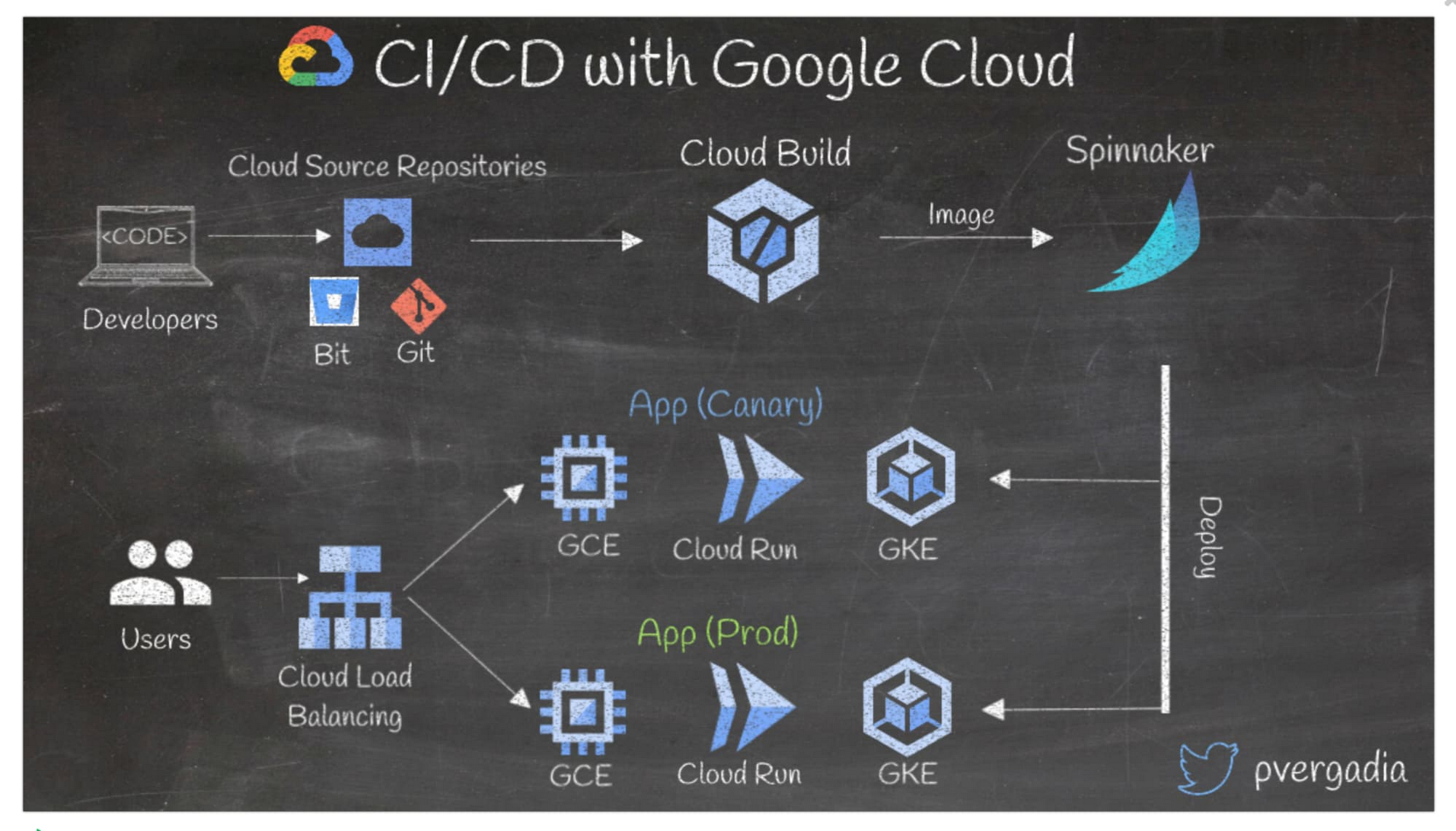
CI / CD は、開発者の苦労を削減し、健全なデプロイメントを維持する効果的な方法です。Google Cloud で CI / CD を設定するのは簡単です。
- デベロッパーが書いたコードを Google Cloud Source Repositories、Bitbucket、Git リポジトリに push します。
- コードがリポジトリに到達するとすぐに、Cloud Build が起動します。Cloud Build では、テストとセキュリティ スキャンを実施し、Docker イメージをビルドして、Spinnaker(オープンソースのマルチクラウド継続的デリバリー プラットフォーム)に push します。Jenkins または Gitlab も使用可能です。
- その後、Spinnaker ではコンテナを GKE、Cloud Run、Compute Engine の本番環境クラスタにデプロイします。また、カナリアアプリをデプロイして、実際のトラフィックに対して変更をテストすることもできます。
- 受信したユーザー トラフィックがロードバランサに到達し、カナリアアプリまたは本番環境アプリにルーティングされます。
- カナリアアプリが不十分である場合は、迅速なロールバックを自動化できます。
詳しくは、CI / CD ソリューションをご覧ください。
9. Google Cloud でサーバーレス マイクロサービスをビルドする
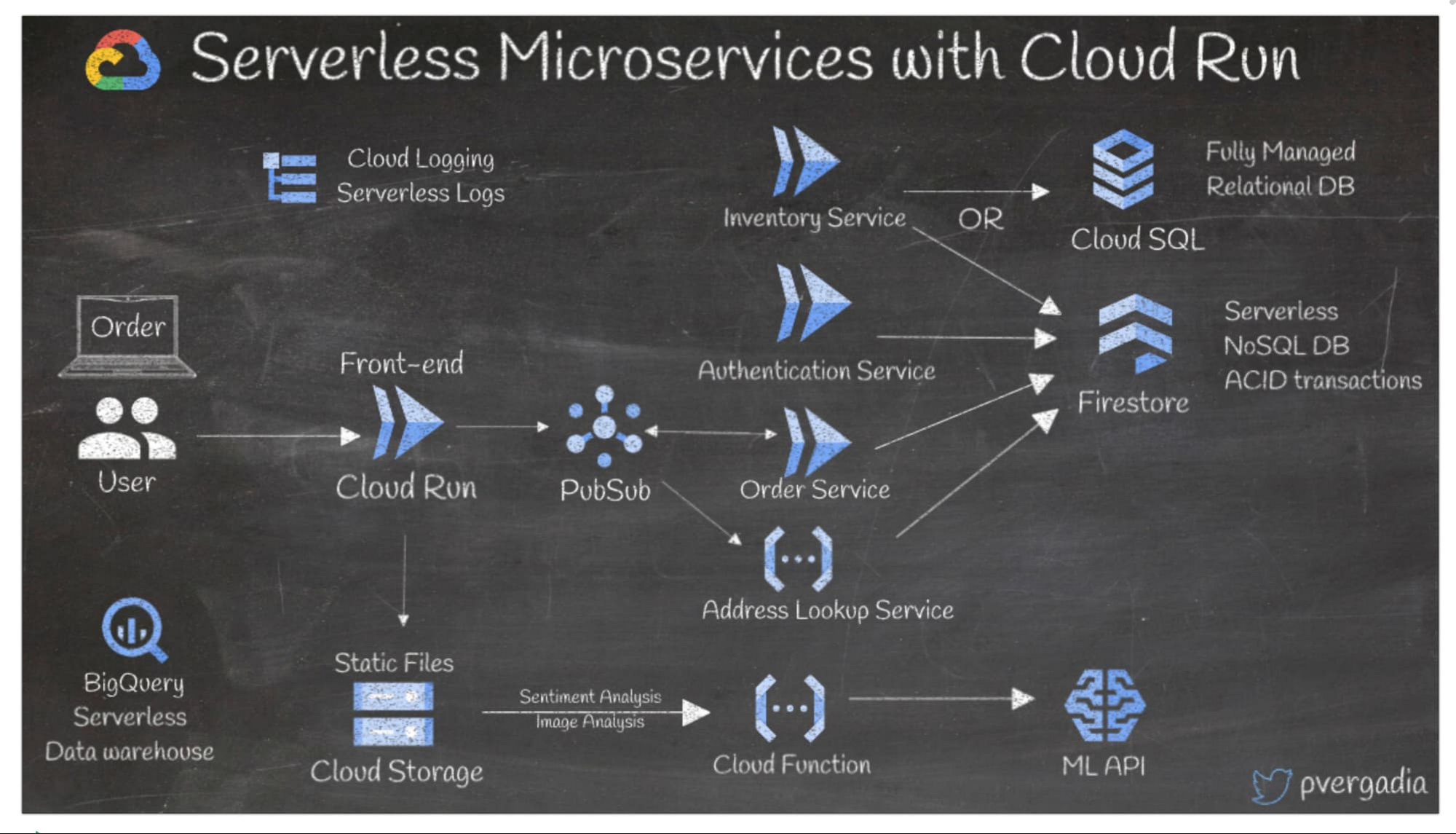
マイクロサービスとサーバーレス アーキテクチャを使用することで、コストを削減しながら、スケーラビリティと柔軟性を向上させ、リリースまでの時間を短縮できます。Google Cloud でサーバーレスのマイクロサービス アーキテクチャをビルドするには、Cloud Run を使用するのがおすすめです。ここでは、e コマースアプリを例に説明します。
- ユーザーが注文を確定すると、Cloud Run のフロントエンドがリクエストを受信し、Pub/Sub(非同期メッセージ サービス)に送ります。
- 同じく Cloud Run にデプロイされている後続のマイクロサービスでは Pub/Sub イベントのサブスクリプションが登録されます。
- 認証サービスから Firestore(サーバーレス NoSQL ドキュメント データベース)へ呼び出しが送られるとします。インベントリ サービスから CloudSQL フルマネージド リレーショナル データベースもしくは Firestore のどちらかのデータベースに対してクエリが実施されます。その後、注文サービスは Pub/Sub からイベントを受信し、注文を処理します。
- 静的ファイルは Cloud Storage に保存されます。その後、ML API を呼び出すことでCloud Functions の関数がトリガーされ、データ分析が行われます。
- アドレス ルックアップのような Cloud Functions にデプロイされているその他のマイクロサービスも存在する場合があります。
- すべてのログは Cloud Logging に保存されます。
- BigQuery には、サーバーレス ウェアハウジングのすべてのデータが保存されています。
詳しくは、サーバーレス プラットフォームの選び方についてのガイドをご覧ください。
10. Google Cloud の機械学習
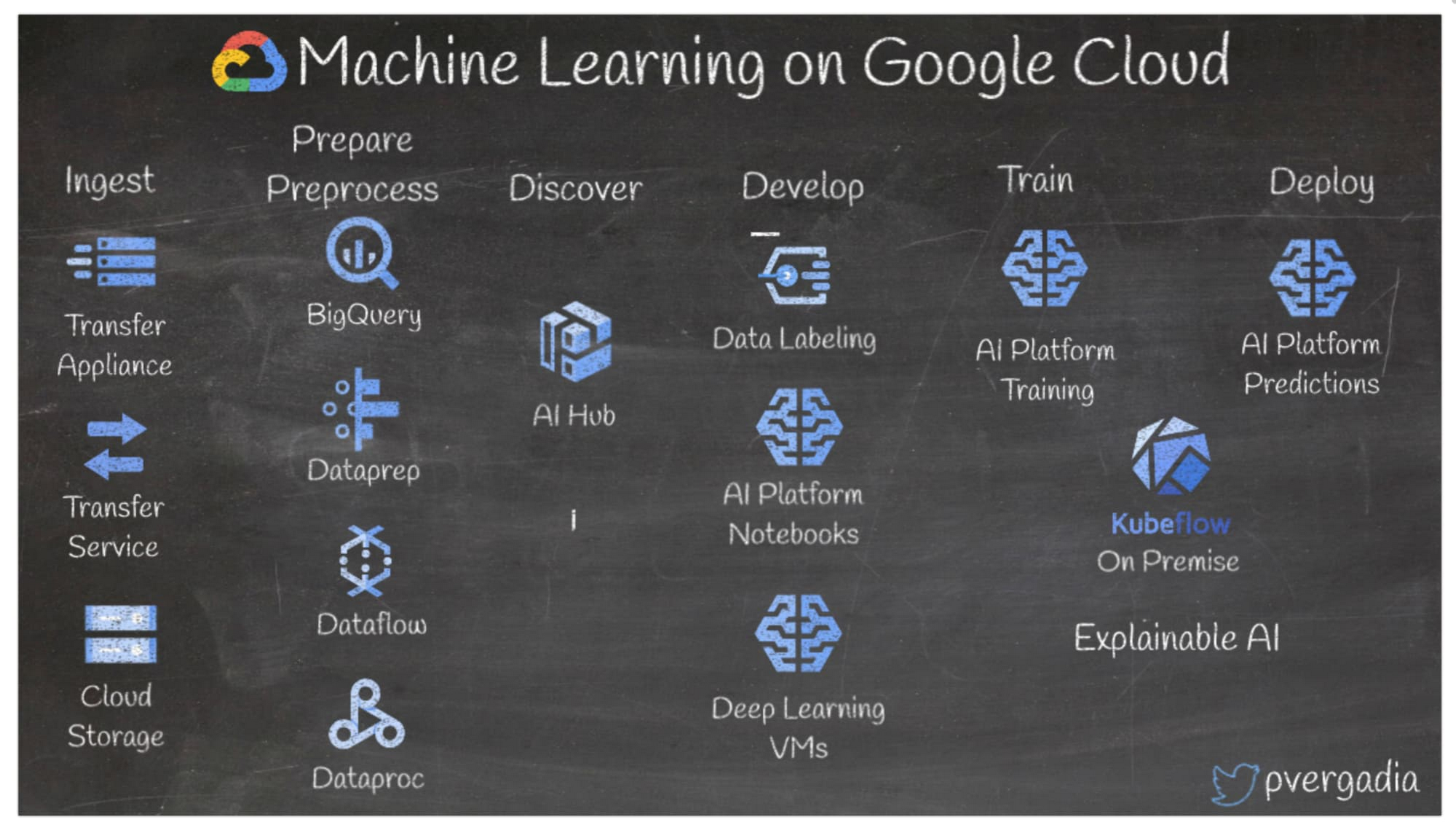
組織では常にデータが生成されています。機械学習技術を使用することでデータを分析して情報を得ることが可能です。以下では、Google Cloud で機械学習を行う手順について説明します。
- 最初に、Transfer Appliance または Transfer Service を使用してデータを Cloud Storage または BigQuery に取り込みます。
- 次に、BigQuery、Dataprep、Dataflow、Dataproc のいずれかを使用してデータの準備と前処理を行います。
- AI Hub を使用して、既存のパイプラインと AI コンテンツを探します。
- 準備が完了したら、AI Platform の Data Labeling Service を使用して、データのラベル付けを行います。
- 機械学習アプリケーションをビルドするには、マネージド Jupyter ノートブックとDeep Learning VM Image を使用します。
- 次に AI Platform Training と AI Platform Prediction サービスを使用して、モデルをトレーニングし、サーバーレス環境で Google Cloud にデプロイするか、Kubeflow を使用してオンプレミスにデプロイします。
- Explainable AI を使用してビジネス ユーザーにモデルの結果を説明し、AI Hub でその他のユーザーに共有します。
詳しくは、Google Cloud の機械学習をご覧ください。
11. Google Cloud で画像、動画、テキストをサーバーレス処理する
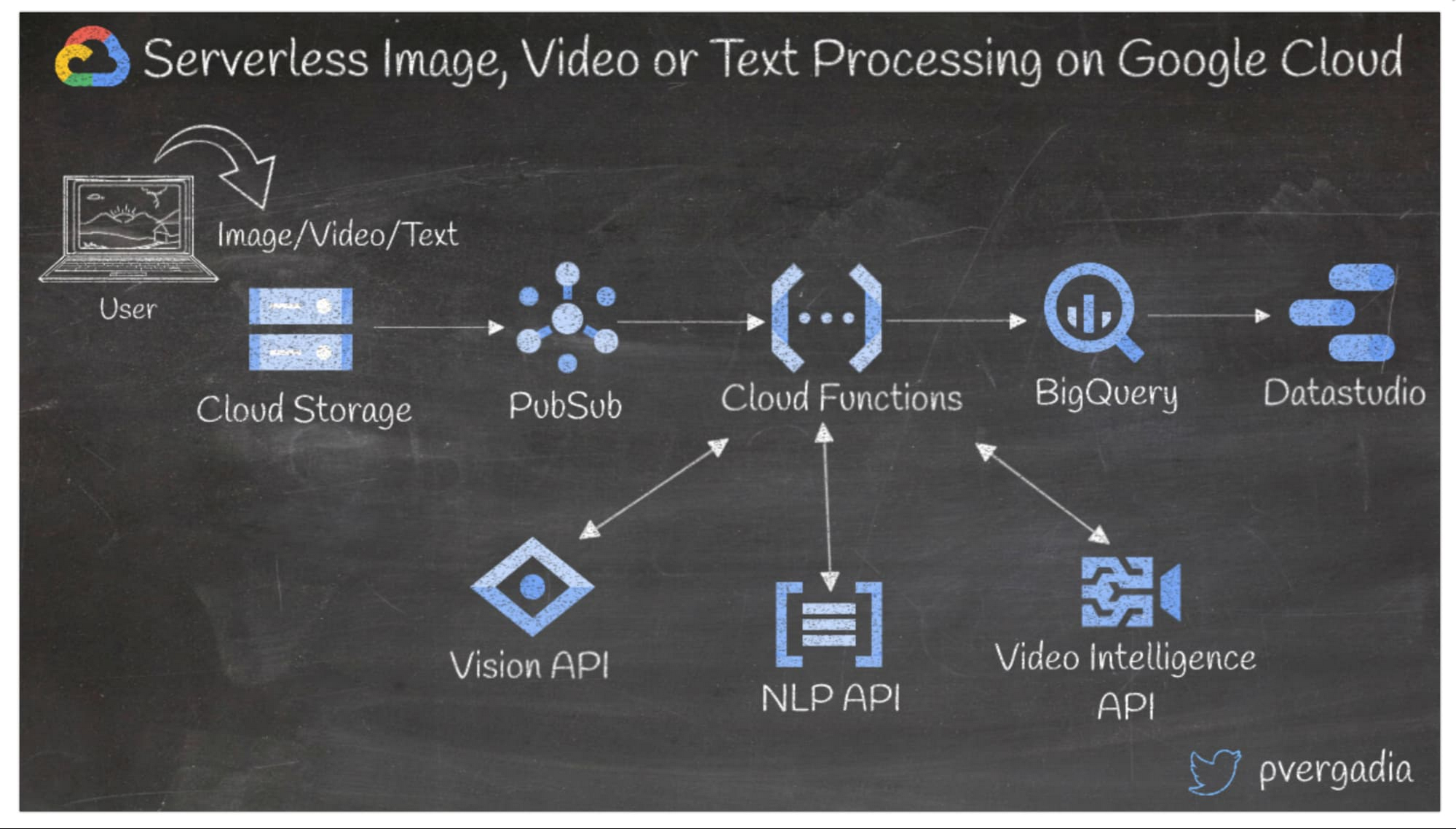
ほとんどのアプリケーションでは、ある程度の量の画像、動画、テキストを処理する必要があります。このアーキテクチャでは、ユーザーが動画、画像、テキストの形式でコンテンツを作成するブログサイトを想定しています。
- フロントエンドのユーザー作成コンテンツは Cloud Storage に保存され、その後 Pub/Sub イベントが作成され、Cloud Functions の関数がトリガーされます。
- 次に Cloud Functions からユーザーがアップロードするファイルの種類に応じて、Vision API、Video Intelligence API、NLP API のいずれかが呼び出されます。
- Cloud Functions はそれぞれの ML API から JSON レスポンスを受信し、知見をさらに処理し、さらなる分析のために BigQuery へ送信します。
- Google データポータルやその他の可視化ツールを使用してカスタム ダッシュボードを作成し、傾向を分析することができます。
詳しくは、AI Platform のページをご覧ください。
12. Google Cloud のモノのインターネット(IoT)
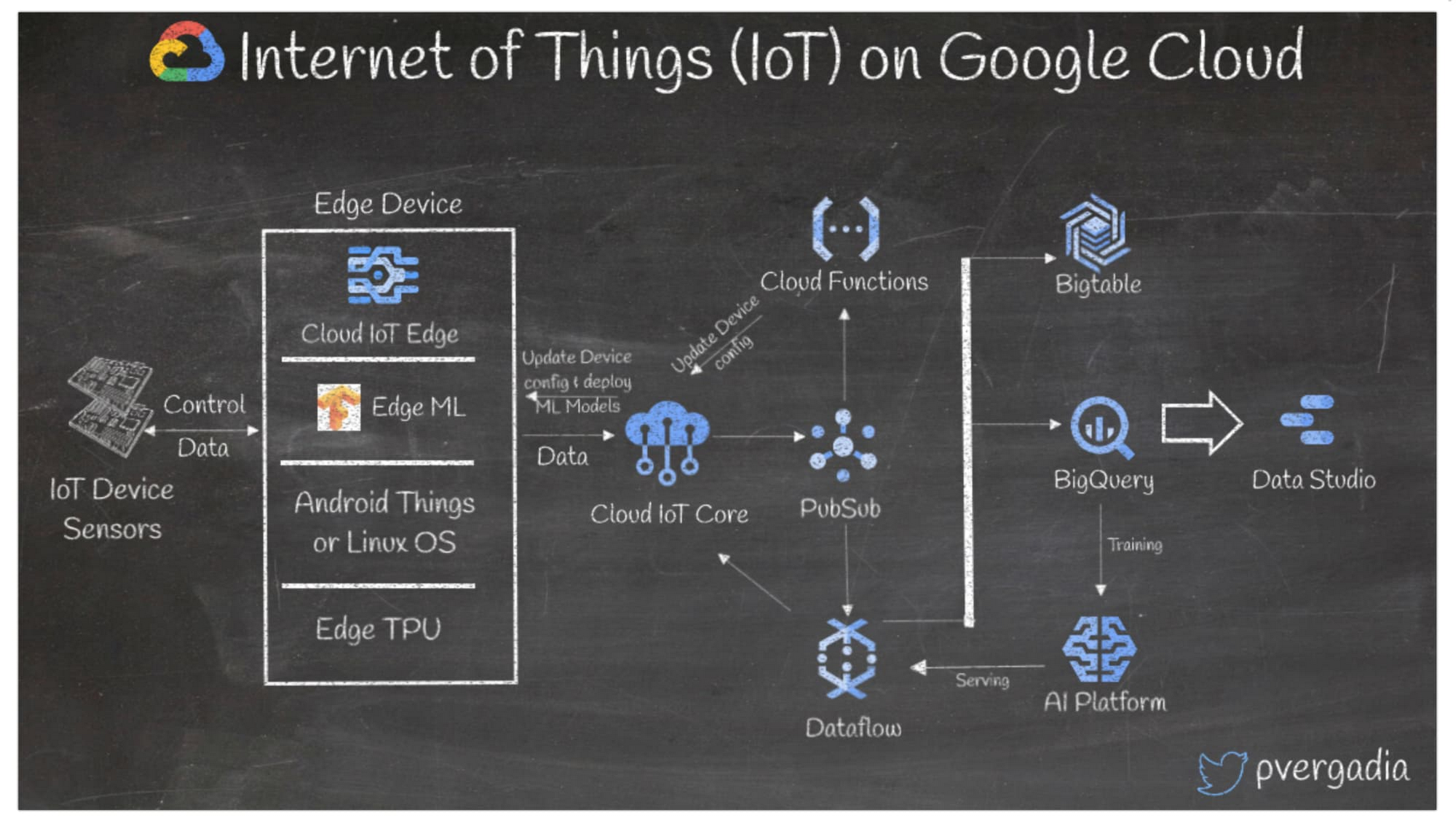
データを生成するデバイスが多数ある場合、IoT ワークフローを使えばデータの接続、管理、取り込みを簡単かつ安全に行い、ダウンストリームのアプリケーションに活用できます。以下に、Google Cloud の IoT ワークフローの例を挙げます。
- センサーから Edge TPU(エッジで ML モデルを実行するチップ)が搭載されたエッジデバイスにデータが送られます。
- エッジデバイスのCloud IoT Edge ソフトウェア レイヤでは、ML モデルを Android Things または Linux OS で実行できます。
- エッジデバイスからデータが MQTT または HTTP(S) を介して Cloud IoT Core に送られ、Pub/Sub でイベントが作成されます。
- その後、Pub/Sub で Cloud Functions がトリガーされ、デバイス構成が更新されます。
- 長期保存については、Dataflow でデータのフィルタリングと処理を行い、Bigtable NoSQL データベースまたは BigQuery にデータが送られます。
- BigQuery では、BigQuery ML または AI Platform を使用して機械学習のモデルをトレーニングできます。
- データポータルまたはその他のダッシュボードで、データの可視化が可能です。
詳しくはCloud IoT Core をご覧ください。
13. BeyondCorp ゼロトラスト セキュリティ モデルを設定する
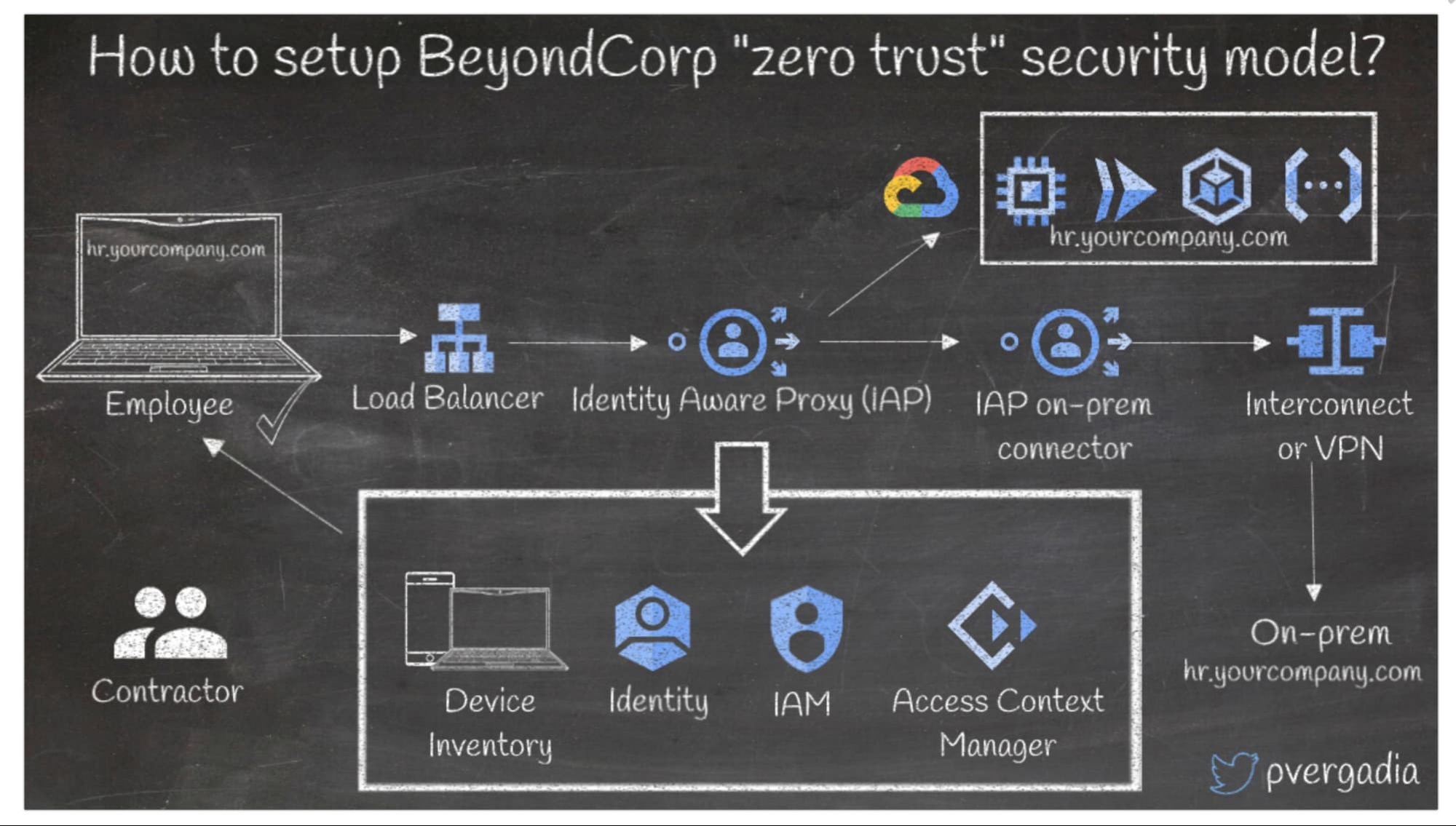
BeyondCorp は、ゼロトラスト セキュリティ モデルを Google が実装したものです。Google での 8 年に及ぶゼロトラスト ネットワークの構築を基に、コミュニティから寄せられた最善のアイデアやベスト プラクティスを加味して設計されています。ここでは、ある会社で従業員が内部アプリにアクセスする例を見てみましょう。
- リクエストは Cloud Load Balancing に送られ、そこから Identity-Aware Proxy(IAP)に送られます。
- 次に、IAP はデバイス インベントリに接続し、正当なユーザーであるかを確認します。エンドポイント管理のために Cloud Identity、認証のために Active Directory、ポリシーベースのコンテキスト アクセスのために Identity and Access Management(IAM)と Access Context Manager に接続します。この確認は、従業員と契約者とで別々に設定できます。
- 完了後、確認がサービスにルーティングされます。確認が完了しない場合、ユーザーのアクセスは拒否されます。
- バックエンドがオンプレミスの場合、IAP オンプレミス コネクタと Cloud Interconnect、または Cloud VPN はデータセンターに直接接続します。
詳しくは、BeyondCorp をご覧ください。
すべての「問題」を解決しましょう
本記事で紹介した一般的な Google Cloud リファレンス アーキテクチャの概要がお客様のお役に立てば幸いです。こちらのパズル問題で学習した内容をテストできます。この他に Google Cloud アーキテクチャで取り上げて欲しいものがありましたら、私の Twitter(@pvergadia)にご連絡ください。あなたのご意見をお聞かせください。
-Google Cloud デベロッパー アドボケイト Priyanka Vergadia



