機械学習モデルの説明が必要な理由
Google Cloud Japan Team
※この投稿は米国時間 2021 年 6 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
今日、多くの企業が積極的に AI を使用しており、また、今後の戦略として AI の導入を計画する企業も数多くあります。今では企業の 76% が、他のイニシアチブより優先して AI や ML に IT 予算を投じており、グローバルな AI 業界は 2027 年までに 2,600 億ドル規模にまで拡大すると想定されています。しかし、AI や高度な分析が普及するに従い、AI テクノロジーの仕組みに関して、さらなる透明性が求められるようになります。
この投稿では、広範な AI の導入において Explainable AI(XAI)が不可欠である理由と、一般的な XAI メソッドについて、また Google Cloud で行えることについてご説明します。
ML モデルの説明が必要な理由
AI テクノロジーには、いわゆるブラック ボックス問題がつきものです。問題やデータ(入力)がわかっていても、最終的な答え(出力)を導く手順やプロセスは見えません。これは、パターン認識によって学習する見えないノードのレイヤが数多く存在する、ディープ ラーニングや人工ニューラル ネットワークの手法で特に問題になります。
ML が何を行っているか理解できないという理由から、ML プロジェクトに対して消極的な人がいます。特に重要な決定が絡む場合などには、不可解な機械学習モデルに全権を委ねることはできないでしょう。AI システムは、多大な影響をおよぼす予測を行います。医療や自動運転車などの業界においては、この予測が人間の生死を分けることになりかねません。
特に、決定がどのようになされたかに関する説明がない場合、モデルによる決定を信頼できるという確証を得ることは難しく、ましてやモデルを人間よりも優れたものにすることはできないでしょう。AI モデルは、いかにして予測や決定を行ったのでしょうか?アルゴリズムに入り込むバイアスがないことをどのように確認できるでしょうか?モデルによる決定を信頼できるだけの透明性や解釈可能性はあるでしょうか?
意思決定者は、AI ベースの決定の背後にある根拠を理解したうえで、その決定が適切であるという確信を持ちたいと望んでいます。事実、PwC の調査によれば、ほとんど(82%)の CEO は、AI による決定を信頼するには、その説明が必要であるとしています。
Explainable AI とは何か
Explainable AI(XAI)とは、機械学習モデルがどのように決定を行っているかを理解するための、一連のツールとフレームワークです。これは、AI モデルのすべてのステップを分解して示すものではありません。ディープ ラーニングのアルゴリズムで使用される何百万ものパラメータを追跡することはほぼ不可能です。そうではなく、XAI ではモデルの仕組みに関する分析情報が提供されるため、専門家はこれを利用して、決定に至るまでの論理を理解できます。
XAI を適切に適用することで、以下のような 3 つの大きなメリットを得られます。
1. ML モデルに対する信頼の向上
意思決定者などの関係者が、ML モデルがどのようにして最終的な出力を導いたか理解できるようになれば、AI ベースのシステムに対する信頼は高まるでしょう。Explainable AI ツールを利用することで、モデルがその出力をどのように導いたかについて、明確でわかりやすい根拠の説明を確認できます。たとえば、ディープ ラーニング モデルを使用して X 線などの医療画像を分析する際に、Explainable AI を使用して顕著性マップ(ヒートマップ)を生成して、診断に使用された画像内の箇所を強調できます。骨折を分類する ML モデルであれば、患者の骨折の判定に使用された画像内の箇所を強調できるでしょう。
2. トラブルシューティング全般の改善
AI の説明可能性が確保されれば、モデルをデバッグし、モデルが適切に機能しているかについてトラブルシューティングを行えます。たとえば、画像内の動物を特定できるモデルがあるとしましょう。ある日、このモデルが、雪の中で遊んでいるイヌをキツネとして分類し続けていることに気づきます。このようなエラーがなぜ継続的に生じているかは、Explainable AI ツールを使用することで簡単に特定できます。予測がどのように行われるかの確認に使用している Explainable AI モデルを調べてみると、ML モデルが画像内の背景に基づいてイヌとキツネを区別していたことがわかります。このモデルは、室内の背景をイヌと解釈し、画像内に雪が映っていればそこにキツネがいるのだと誤って学習していたのです。
3. バイアスや潜在的な AI の穴を取り除く
XAI は、バイアスの原因の特定にも活用できます。たとえば、違法な左折をする自動車を特定できるモデルがあるとしましょう。画像内のどの箇所に基づいて違反が特定されるか定義するように求められたとき、このモデルがトレーニング データからバイアスを取得していたことに気づきます。このモデルでは、違法に左折する自動車に注目するのではなく、そこに穴があるかどうかが問題になっていました。このような影響は、整備の行き届いていない道路で撮影された画像を大量に含む偏ったデータセットや、都市内の資金の乏しい地域では違反切符が切られやすいという、現実的なバイアスによって引き起こされる可能性があります。
ML のライフサイクルのどの部分で説明可能性が機能するか
Explainable AI は、ML ワークフローの最後に後知恵で行うものであってはなりません。説明可能性は、あらゆるステップ(データ収集、処理、モデルのトレーニング、評価、モデルの提供)に統合し、適用する必要があります。
ML ライフサイクルに説明可能性を組み込む方法はいくつかあります。たとえば、Explainable AI を使用してデータセットの不均衡を特定すること、モデルの動作が特定のルールや公平性の指標を満たしていることを確認すること、モデルの動作をローカルとグローバルの両方で表示することなどです。たとえば、モデルが合成データを使用してトレーニングされた場合は、実際のデータを使用した場合と同様に動作することを確認する必要があります。また、医療画像のディープ ラーニング モデルの例で説明したように、説明可能性を適用するよくある例として、画像分類で使用される画像内領域を特定できるヒートマップを作成することがあります。
他に使用できるツールとして、機械学習モデルのパフォーマンスのスライス評価があります。Google の AI 原則により、不公平なバイアスの発生や助長は防止しなければなりません。多くの場合、AI アルゴリズムやデータセットでは、不公平なバイアスが反映されたり、助長されたりする可能性があります。モデルがうまく機能しない場合があることに気づいた場合には、公平性に関する懸念事項に対応することが重要になります。
スライス評価では、データセットのさまざまな要素が結果にどのように影響するかを確認できます。画像モデルの場合は、露光不足や露光過多などの因子に基づき、さまざまな画像を調査できます。
また、モデルカードの作成もおすすめします。これは、潜在的な制限、パフォーマンス実現のために受け入れる必要のあるトレードオフを説明するもので、モデルの実行内容のテストに使用できます。
Explainable AI のメソッド
Explainable AI のメソッドに関しては、グローバル メソッドとローカル メソッドの違いを理解することが重要です。
グローバル メソッドは、モデルがどのように決定を行うかに関して、その全体的な構造を理解します。
ローカル メソッドは、ある 1 つの事例に関して、モデルがどのように決定を行ったかを理解します。
たとえば、グローバル メソッドでは、使用されたすべての特徴を含むテーブルを確認して、意思決定に関する全体的な重要度でランク付けできます。特徴重要度テーブルは一般的に、構造化データモデルを説明するために使用されます。特定の入力変数がモデルの最終出力にどのように影響するかを理解できます。
しかしモデルが個々の予測や特定の人の決定をどのように行うかを説明するのはどうでしょうか?ここでローカル メソッドが役に立ちます。
この投稿では、画像データのモデル予測の説明でローカル メソッドをどのように使用するかに着目します。
以下は、最も一般的な Explainable AI のローカル メソッドです。
Local interpretable model-agnostic explanation(LIME)
Kernel Shapley additive explanations(KernalSHAP)
統合勾配(IG)
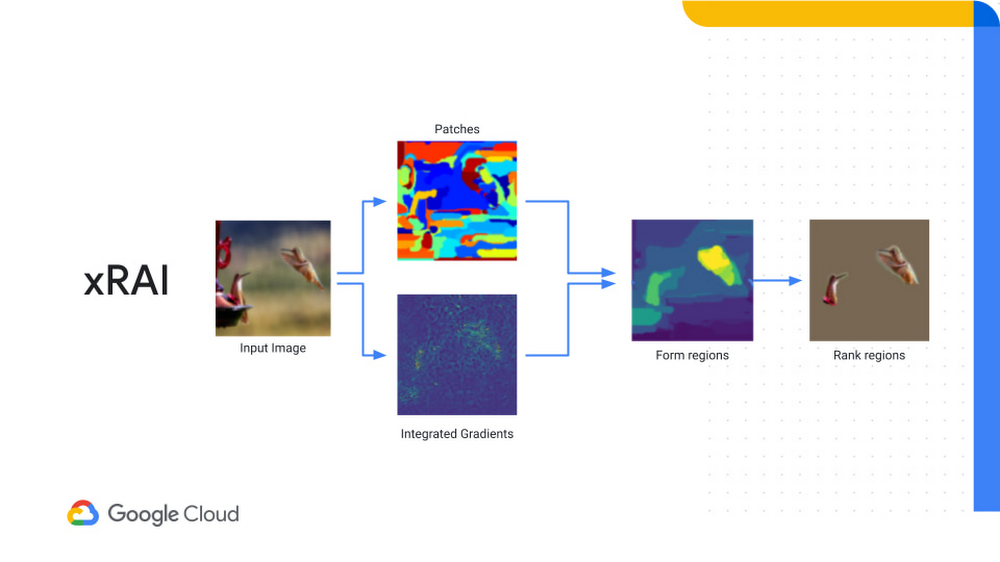
Explainable explanations through AI(XRAI)
LIME と KernalShap は両方とも、画像をパッチに分解します。パッチは、予測からランダムにサンプリングされたものであり、これにより、多数の摂動された(変更された)画像が生成されます。この画像はもとの画像と似たものになりますが、画像の一部分が完全に取り除かれています。摂動された画像はトレーニング済みモデルに供給され、予測を行うように要求されます。
以下の例では、「この画像はカエルの画像かそうではないか」という質問にモデルが回答します。
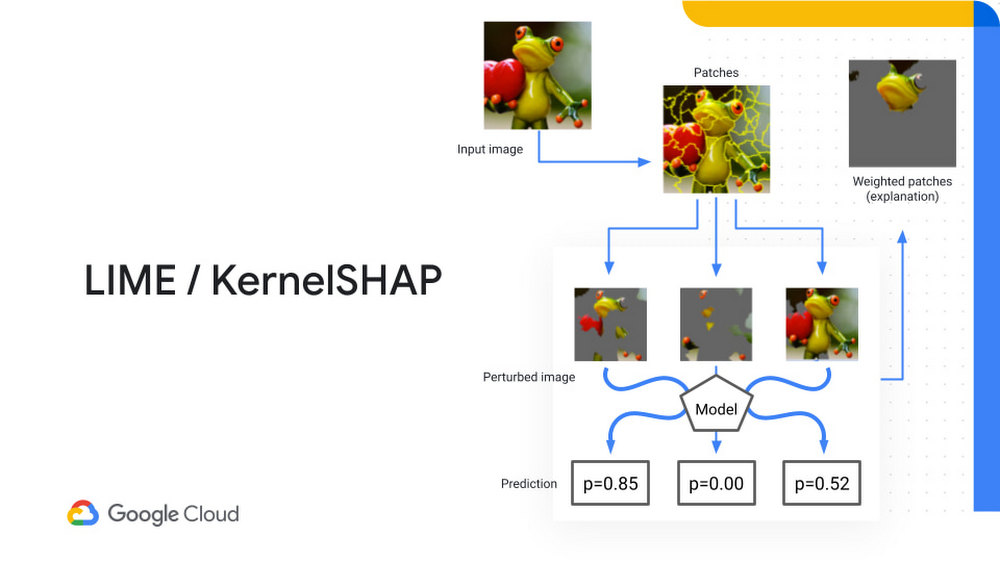
このモデルは、この画像がカエルである確率を出力します。選択されたパッチに基づき、各パッチの重要度を実際にランク付けして、最終的な確率を計算できます。これらのメソッドは、画像にカエルが含まれるかの決定に関する、局所的な重要度を説明するために使用できます。
統合勾配は、最終出力の勾配に基づいて重要度の値を算出する手法です。IG では、ベースライン画像を利用して、モデルで識別する情報を含む画像の実際のピクセル値とこれを比較します。トレーニング済みモデルで検出する物体がこの画像に含まれていれば、この値の精度が向上するはずです。これは、ベースライン画像から予測を行う点までの勾配の変化を判断するのに役立ちます。その際、画像の分類に何が使用されているかを判断するのに役立つ、アトリビューション マスクを使用します。
XRAI は、前述の 3 つの方法すべてを組み合わせた手法です。パッチによる識別と統合勾配を組み合わせて、個々の画像内領域ではなく、決定に最も影響を与える領域を表示します。この手法においては、大きな領域が良質な結果につながる傾向があります。
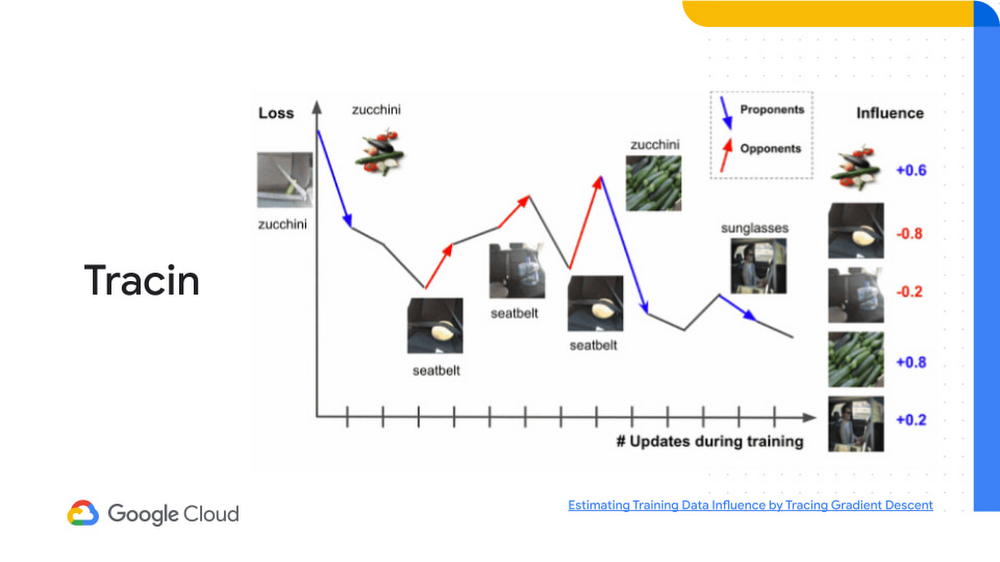
Google Cloud が取り入れようとしているもう一つの新しい方法は TracIn で、これは、トレーニング データの影響を推定できるシンプルでスケーラブルな手法です。ML モデルのトレーニング データの品質は、モデルのパフォーマンスに大きな影響を与える可能性があります。TracIn では、さまざまなデータセットで誤ってラベル付けされたサンプルと外れ値を追跡し、各トレーニングのサンプルに影響度スコアを割り当てることで予測を説明します。
画像にズッキーニが映っているかどうか予測するモデルをトレーニングしている場合は、勾配の変化を調べて、どの部分がロスを削減(プロポーネント)しているか、ロスを増加(オポーネント)しているかを特定できます。TracIn を使用することで、モデルがズッキーニを特定するために使用する画像と、ズッキーニではないものを特定するために使用する画像を区別できます。
Google Cloud で Explainable AI を使用する
Google は、Vertex Explainable AI をリリースしました。これにより、データ サイエンティストはモデルを改善できるようになり、意思決定者は分析情報を活用してモデルに簡単にアクセスできるようになります。Google の目的は、ML モデルがどのようにして結論に至ったかに関する説明、モデルのデバッグ、バイアスへの対応など、さまざまな形でデータ サイエンス チームをサポートできる、一連の有用なツールとフレームワークを提供することです。
Vertex Explainable AI プラットフォームでは、以下のことを行えます。
包括的でわかりやすい AI を設計する。データとモデル間のバイアス、ブレ、その他の隔たりを検出して解決できるように設計された Vertex Explainable AI ツールを使用して、AI システムを一から構築できます。データ サイエンティストは AI Explanations を活用して、AutoML Tables、Vertex Predictions、Notebooks を使用し、因子がモデルの予測にどの程度貢献したかを説明して、データセットとモデルアーキテクチャを改善できます。What-If ツールを使用して、さまざまな特徴にわたるモデルのパフォーマンスを調査し、戦略を最適化して、個々のデータポイント値を操作することもできます。
人間が理解しやすい説明を活用して、確信をもって ML モデルをデプロイする。AutoML Tables または Vertex AI にモデルをデプロイすると、トレーニング データで見つかったパターンを反映して、さまざまな因子が最終出力にどのように影響したかに関する予測とスコアをリアルタイムに取得できます。
パフォーマンスのモニタリングとトレーニングで、モデルのガバナンスを合理化する。継続評価機能を使用すると、予測を簡単にモニタリングし、予測入力の正解ラベルを提供できます。Vertex Data Labeling は、予測を正解ラベルと比較して、フィードバックを組み込み、モデルのパフォーマンスを最適化します。
AI は、あらゆる業界の企業の未来を形作り、刺激し続ける魅力的なフロンティアとして存続します。しかし、AI の潜在能力を最大限に発揮し、幅広く導入するためには、データ サイエンティストのみならず、すべての関係者が ML モデルの仕組みを理解する必要があります。AI が今後どのように進展するとしても、Google はお客様、ビジネス ユーザー、意思決定者など、あらゆる人にとって AI が役立つものとなるように取り組みを続けます。
次のステップ
Cloud AI Platform で Jupyter Notebook を実行して、予測と一緒に説明を提供する方法をご確認ください。ステップバイステップの手順は Qwiklabs でも利用できます。また、今後 5 年間の機械学習の進展に関心がある場合は、Applied ML Summit をチェックして、Spotify、Google、Kaggle、Facebook など、機械学習コミュニティにおけるリーダーの話をご確認ください。
-分析および AI ソリューション部門ディレクター Lak Lakshmanan



