R 言語を使用して Vertex AI で機械学習モデルのトレーニングとデプロイを行う
Google Cloud Japan Team
※この投稿は米国時間 2022 年 7 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
R は、統計コンピューティングと機械学習の分野で最も広く使用されているプログラミング言語の一つです。特に、データ サイエンス向け R パッケージの独自コレクションである tidyverse が提供する豊富なパッケージがあるため、多くのデータ サイエンティストから支持されています。tidyverse 以外にも、R のパッケージ リポジトリである CRAN には 18,000 を超えるオープンソース パッケージがあります。デスクトップ版として、およびGoogle Cloud Marketplace で提供されている RStudio はよく使用されている統合開発環境(IDE)であり、データの専門家が可視化や機械学習モデルの開発に使用しています。
モデルの構築に成功した後、データ サイエンティストが直面するのは、「R 言語で作成したモデルを、スケーラビリティと信頼性を維持し、メンテナンスの必要性を抑えつつ本番環境にデプロイするにはどうすればよいのだろう」という点です。
このブログ投稿では、Google Vertex AI を使用して、R で構築したエンタープライズグレードの機械学習モデルのトレーニングとデプロイを行う方法について説明します。
概要
Vertex AI での機械学習モデルの管理は、Google Cloud コンソールのユーザー インターフェース、API 呼び出し、Vertex AI SDK for Python など、さまざまな方法で行うことができます。
多くの R ユーザーは RStudio からプログラムで Vertex AI を操作することを好むため、reticulate パッケージを使用して、Vertex AI SDK を介して Vertex AI を操作します。
Vertex AI は、tensorflow、scikit-learn、xgboost で作成されたモデルに対して、モデルのトレーニングと予測のサービングのための事前構築済みの Docker コンテナを提供しています。R の場合は、Google Cloud の R 向け Deep Learning Containers から派生したコンテナを自分で構築します。
Vertex AI でのモデルは、次の 2 つの方法で作成できます。
モデルをローカルでトレーニングして、Vertex AI Model Registry にカスタム モデルとしてそれをインポートし、予測のサービングのためにそこからエンドポイントにデプロイする。
CustomJob を実行し、結果のアーティファクトを Model としてインポートする TrainingPipeline を作成する。
このブログ投稿では、2 番目の方法を使用してモデルを Vertex AI で直接トレーニングします。この方法の場合、後の段階でモデル作成プロセスを自動化しつつ、分散ハイパーパラメータの最適化をサポートできるからです。
Vertex AI での R モデルの作成と管理のプロセスには次の手順が含まれます。
Google Cloud Platform(GCP)API を有効にして、ローカル環境を設定する
トレーニングとサービングのためのカスタム R スクリプトを作成する
Cloud Build と Container Registry を使用した R モデルのトレーニングとサービングをサポートする、Docker コンテナを作成する
Vertex AI Training を使用してモデルをトレーニングし、アーティファクトを Google Cloud Storage にアップロードする
Vertex AI Prediction エンドポイントでモデル エンドポイントを作成してモデルをデプロイし、オンライン予測リクエストをサービングする
オンライン予測を行う
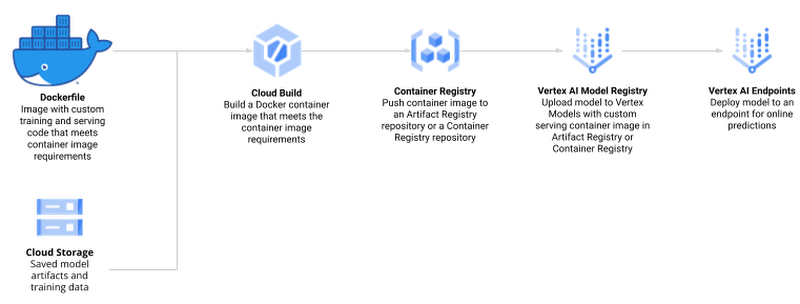
図 1.0(ソース)
データセット
このプロセスの実例として、カリフォルニア州の住宅に関するデータセットを使用して住宅価格を予測する単純なランダム フォレスト モデルをトレーニングします。データには、1990 年のカリフォルニア州国勢調査の情報が含まれています。データセットは Google Cloud Storage で公表されています(gs://cloud-samples-data/ai-platform-unified/datasets/tabular/california-housing-tabular-regression.csv)。
このランダム フォレスト リグレッサー モデルでは、特定の経度および緯度と、対応する国勢調査ブロック グループからのデータに基づいて、住宅価格の中央値を予測します。ブロック グループとは、米国の国勢調査局がサンプルデータを発表する最小の地理的単位です(通常、1 つのブロック グループには 600 人から 3,000 人の人口が含まれます)。
環境の設定
このブログ投稿では、Vertex AI Workbench と R カーネル、または RStudio を使用していることを前提としています。環境では、次の要件を満たしている必要があります。
Google Cloud SDK
Git
R
Python 3
Virtualenv
シェルコマンドを実行するために、ヘルパー関数を定義します。
また、いくつかの R パッケージをインストールして Vertex AI 向け SDK をアップデートします。
次に、トレーニングとデプロイのプロセスをサポートするために次の変数を定義します。
PROJECT_ID: Google Cloud Platform のプロジェクト IDREGION: 現時点で、Vertex AI でサポートされているリージョンは us-central1、europe-west4、asia-east1 です。最も近いリージョンを選択することをおすすめします。BUCKET_URI: データセットとモデルのリソースに関連付けられているすべてのデータが保存される、ステージング バケットDOCKER_REPO: コンテナ アーティファクトを保存する、Docker リポジトリ名IMAGE_NAME: コンテナ イメージの名前IMAGE_TAG: Vertex AI が使用するイメージタグIMAGE_URI: コンテナ イメージの完全な URI
Vertex AI SDK for Python を初期化する際に、Cloud Storage のステージング バケットを指定します。ステージング バケットは、データセットとモデルのリソースに関連付けられているすべてのデータが、セッションをまたいで保持される場所です。
次に、Vertex AI SDK のインターフェースとして Python で作成された reticulate R パッケージをインポートして初期化します。
R モデルのトレーニングとサービングのために、Docker コンテナ イメージを作成する
カスタム コンテナのための Docker ファイルは、Vertex AI Workbench で使用されるのと同じコンテナである、ディープ ラーニング コンテナの上に構築されます。さらに、モデルのトレーニングとサービングそれぞれのために、2 つの R スクリプトを追加します。
このコンテナを作成する前に、ご利用のリージョンで Artifact Registry を有効にして、リクエストを認証するように Docker を構成します。
次に、Dockerfile を作成します。
次に、R モデルのトレーニングに使用するファイル train.R を作成します。このスクリプトは、カリフォルニア州の住宅に関するデータセットを使用して randomForest モデルをトレーニングします。Vertex AI は、活用できる環境変数を設定します。このスクリプトは Vertex AI マネージド データセットを使用するため、データ分割が Vertex AI によって行われ、スクリプトは、トレーニング、テスト、検証のセットを示す環境変数を受け取ります。その後、トレーニング済みモデルのアーティファクトは Cloud Storage バケットに保存されます。
次に、R モデルのサービングを行うために使用するファイル serve.R を作成します。このスクリプトは Cloud Storage からモデルのアーティファクトをダウンロードしてそれを読み込み、ポート 8080 で予測リクエストをリッスンします。次のような、予測サービスのためのいくつかの環境変数を自由に使用できます。
AIP_HEALTH_ROUTE: AI Platform Prediction がヘルスチェックを送信するコンテナの HTTP パス。AIP_PREDICT_ROUTE: AI Platform Prediction が予測リクエストを転送するコンテナの HTTP パス。
次に、サーバレス CI / CD プラットフォームの Cloud Build で Docker コンテナ イメージを構築します。 Docker コンテナ イメージの構築には、10~15 分ほどかかります。
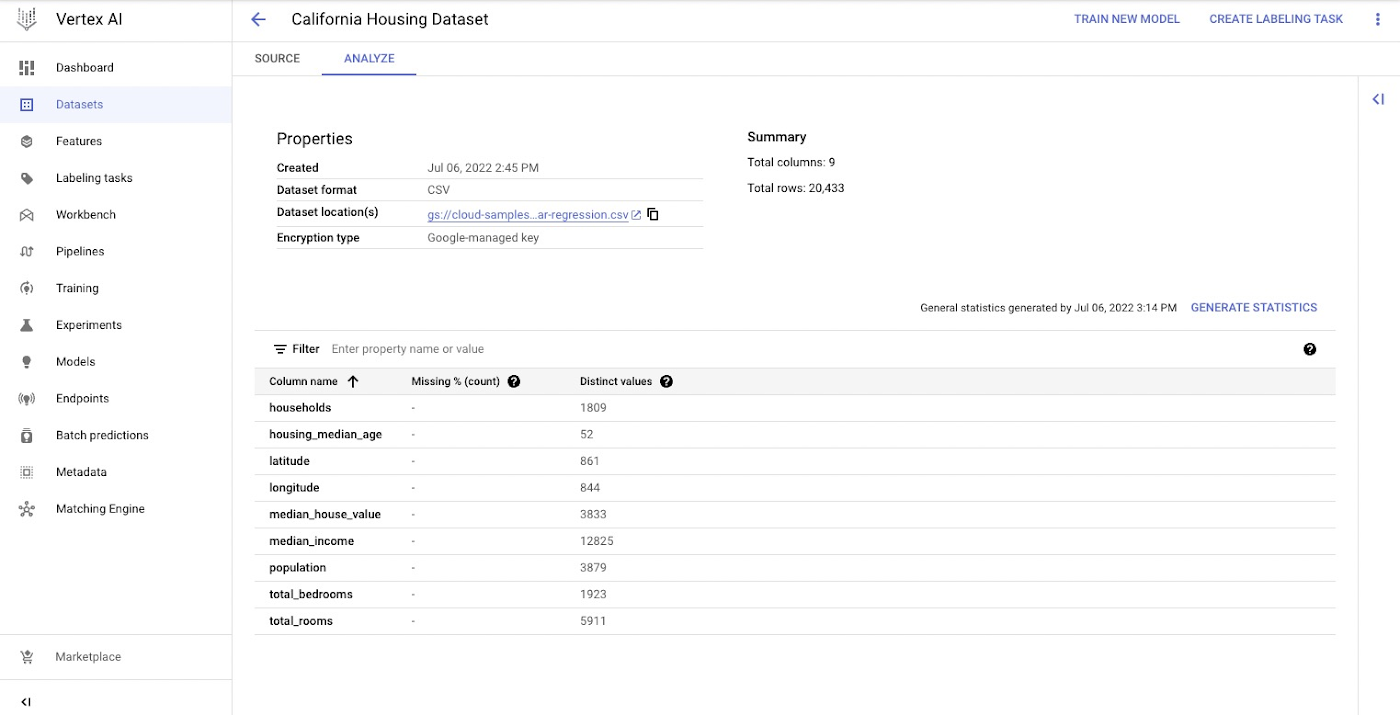
Vertex AI マネージド データセットを作成する
Vertex AI マネージド データセットを作成して、Vertex AI にデータセットの分割を行わせます。これはオプションであり、代わりに環境変数を使用してデータセットへの URI を渡すこともできます。
次のスクリーンショットは、Cloud コンソール内の新しく作成された Vertex AI マネージド データセットを示しています。
Vertex AI で R モデルをトレーニングする
カスタム トレーニング ジョブは、コンテナ イメージのインスタンスを作成して、モデル トレーニングのための train.R とモデル サービングのための serve.R を実行することにより、トレーニング プロセスをラッピングします。
注: トレーニングとサービングの両方に対して同じカスタム コンテナを使用します。
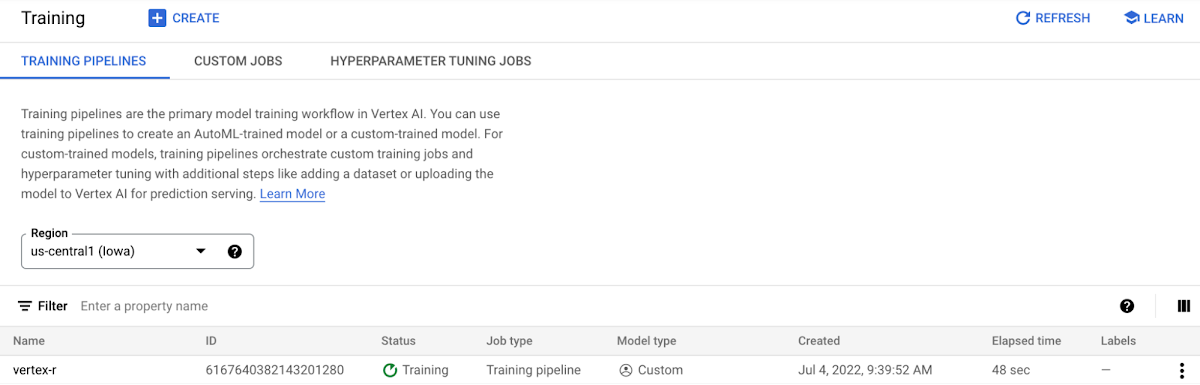
モデルのトレーニングを行います。データセットを使用して機械学習モデルをトレーニングするのに十分なリソースを備えたマシンタイプを指定して、メソッド run() を呼び出します。このチュートリアルでは、n1-standard-4 VM インスタンスを使用します。
モデルのトレーニングが実行され、進捗状況を Vertex AI コンソールで確認できます。
エンドポイント リソースのプロビジョニングとモデルのデプロイ
Endpoint.create() メソッドを使用して、エンドポイントのリソースを作成します。少なくとも、エンドポイントの表示名を指定します。オプションとして、プロジェクトとロケーション(リージョン)を指定できます。指定しない場合は、init() メソッドを使用して Vertex AI SDK を初期化した際に設定した値が継承されます。
この例では、次のパラメータを指定します。
display_name: 人が判読できる形式のエンドポイント リソース名。project: プロジェクト ID。location: リージョン。labels: (オプション)Key-Value ペアの形式の、エンドポイントのユーザー定義メタデータ。
このメソッドは、エンドポイント オブジェクトを返します。
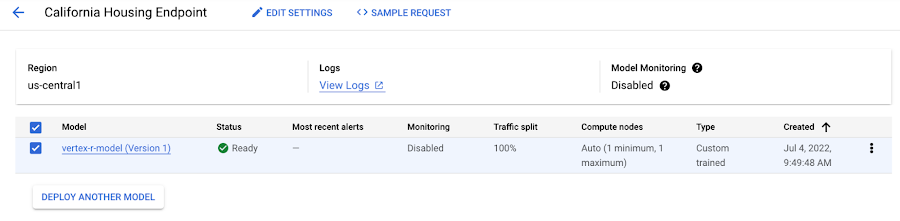
同じエンドポイントに、1 つまたは複数の Vertex AI モデルリソース インスタンスをデプロイできます。デプロイされる Vertex AI モデルリソースのそれぞれには、サービス提供バイナリのための独自のデプロイ コンテナが含まれます。
次に、Vertex AI モデルリソースを Vertex AI エンドポイント リソースにデプロイします。Vertex AI モデルリソースは、それのためのデプロイ コンテナ イメージを定義しています。デプロイするには、次の追加の構成設定を指定します。
マシンタイプ。
GPU のタイプと数(ある場合)。
VM インスタンスが静的、手動、自動スケーリングのいずれであるか。
この例では、次のように、最低限のパラメータを指定してモデルをデプロイします。
model: モデルリソース。
deployed_model_displayed_name: 人が判読できる形式の、デプロイされるモデル インスタンスの名前。machine_type: 各 VM インスタンスのマシンタイプ。
リソースをプロビジョニングする必要があるため、最大で数分かかることがあります。
注: この例では、モデル アーティファクトを Vertex AI モデルリソースにアップロードするステップで、R デプロイ コンテナをすでに指定しています。
モデルがエンドポイントにデプロイされ、結果を Vertex AI コンソールで確認できます。
新しく作成されたエンドポイントを使用して予測を行う
最後に、いくらかのサンプルデータを作成して、テストとしてデプロイされたモデルに対して予測リクエストを行います。data_uri にある元のデータファイルからの、5 つの JSON エンコードされたサンプル データポイント(ラベル median_house_value は含まない)を使用します。最後に、サンプルデータを使用して予測リクエストを行います。この例では、REST API(例: Curl)を使用して予測リクエストを行います。
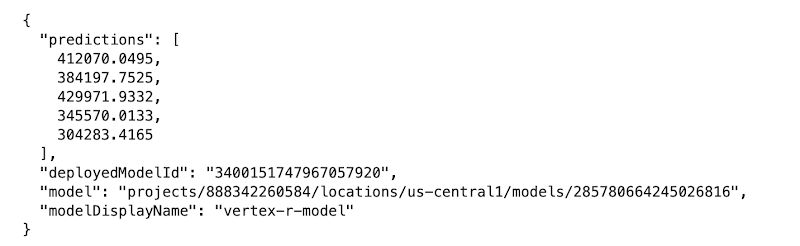
エンドポイントは、送信されたサンプルと同じ順序で、5 つの予測を返します。
クリーンアップ
このプロジェクトで使用したすべての Google Cloud リソースをクリーンアップするには、チュートリアルで使用した Google Cloud プロジェクトを削除するか、作成されたリソースを削除します。
まとめ
このブログ投稿では、R モデルをトレーニングして Vertex AI にデプロイするために必要な手順について学びました。もう一度行うには、GitHub にあるこの Notebook が役立ちます。
謝辞
このブログ投稿は、多くの人の協力によって完成できました。特に、 Rajesh Thallam 氏による戦略および技術面での監修、Andrew Ferlitsch 氏による技術的側面での助言、説明、コードレビュー、Yuriy Babenko 氏によるレビューに謝意を表します。
- 機械学習スペシャリスト Fabian Hirschmann
- 機械学習スペシャリスト Justin Marciszewski


