AI Platform で RAPIDS を Dask、NVIDIA GPU と組み合わせて数分でモデル トレーニングをスケーリング
Google Cloud Japan Team
※この投稿は米国時間 2021 年 2 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
Python は、分析や機械学習(ML)に関連したユースケースに向けてデータを準備、処理、分析するデータ サイエンティストにとって、代表的な言語の一つとして定着しています。しかし、Python の基本ライブラリは大規模な変換向けには設計されておらず、作成したコードを本番環境にデプロイしようとするデータ サイエンティストにとって大きな障害となっています。ML 関連タスクでは大量のデータを処理する必要性が増しており、複数のマシンに処理を分散させることが求められています。Dask や RAPIDS のようなライブラリは、データ サイエンティストが Python で分散処理を管理できるようにします。Google Cloud の AI Platform を使用すると、データ サイエンティストはそうしたライブラリがプリインストールされた、さまざまな加速化 GPU を起動できるきわめてパワフルな仮想マシンを簡単にプロビジョニングできます。
RAPIDS は、データ サイエンティストが ML パイプラインで NVIDIA GPU を活用できるようにするための一連のオープンソース ライブラリです。
Dask は Python での 並列コンピューティング用のオープンソース ライブラリで、データ サイエンティストが ML ワークロードをスケールできるようにします。
AI Platform は Google Cloud のフルマネージド プラットフォームで、データ サイエンスと ML 向けに自動的にプロビジョニングされる環境をデータ サイエンティストに提供します。
これらを組み合わせると、指定したクラスタにおけるスケーラブルな分散トレーニングの実行を NVIDIA GPU で高速化できます。このブログ投稿では、その方法を詳しくご説明します。
概要
Dask は現在、PyData や SciPy コミュニティ内で最もよく使用されている並列処理フレームワークです。ノートパソコンの CPU 上の並列化されたワークロードから、クラウド クラスタ内の数千のノードまでスケールできるように設計されています。NVIDIA が開発したオープンソースの RAPIDS フレームワークと組み合わせると、CPU と NVIDIA GPU の両方の並列処理能力を活用できます。
GPU を使用すると、ML パイプラインのあらゆる段階(前処理、トレーニング、推論)を大幅に高速化できます。このブログでは、Jupyter Notebook 環境で Python を使用して行う前処理とトレーニングの段階に注目します。
まず、Dask または RAPIDS を使用してデータセットを NVIDIA GPU メモリに読み込み、基本的な関数をいくつか実行します。
次に、Dask を使用して GPU メモリの容量を超えてスケールします。
次に、カスタム コンテナで AI Platform Training ジョブを送信して、XGBoost を複数の NVIDIA A100 Tensor Core GPU にわたってスケールします。
最後に、AI Platform Predictions を使用してオンライン推論のためのモデルをデプロイし、GPU で高速化します。
このブログに関連する GitHub リポジトリはこちらにあります。
Dask のユースケース
Dask は、ハイ パフォーマンス コンピューティング、気候科学、バンキング、イメージングの問題など、さまざまな問題に取り組んでいるデータ サイエンス チームによって使用されています。加えて、ビジネス インテリジェンスに関する問題にも適しています。さまざまなチームが Dask を使用して前進したユースケースの一覧については、こちらをご覧ください。
AI Platform で Dask を使用するメリット
Dask は Google Cloud Storage や HDFS などの多様なソース、そして CSV、Parquet、Avro などの各種データ型からのデータ読み込みをサポートしています。これらは、PyArrow、GCSFS、fastparquet、fastavro などのさまざまなオープンソース ライブラリでサポートされています。また、これらのライブラリはすべて AI Platform に含まれています。また、AI Platform は NVIDIA と緊密に連携して、AI Platform と NVIDIA GPU との間で最高水準の互換性も実現しています。
AI Platform Notebooks を使用すると、必要なメモリ、CPU または GPU、ライブラリを含む、ニーズに的確に合った JupyterLab 開発環境を簡単にスピンアップできます。
AI Platform Training を使用すると、データ処理とモデル トレーニングのワークロードをジョブとして送信できます。送信には scikit-learn、TensorFlow、XGBoost のようなホストされたフレームワーク、またはカスタム コンテナ経由で独自のフレームワークを使用します。
AI Platform Notebooks と AI Platform Training のいずれも、あらゆるワークロードと一致するようコンピューティング クラスタを設計できる柔軟性を提供します。それと同時に、内部で大部分の依存性、ネットワーキング、モニタリングも管理します。つまり、インフラストラクチャに気を取られることなく、Python での開発に集中できます(ご希望の場合はマシンのさまざまな設定を試すことも可能です)。
AI Platform Notebooks で開発環境を作成する
ここでは、作業に使用する環境を立ち上げるために AI Platform Notebooks を使用します。始める前に、Google Cloud Platform に登録して AI Platform Notebooks API を有効にする必要があります(手順はこちらをご覧ください)。AI Platform Notebooks インスタンスを作成すると料金が発生しますのでご注意ください。料金の詳細はこちらでご確認いただけます。AI Platform Notebooks により、選択した各マシンタイプの 1 か月あたりおよび 1 時間あたりの費用見積もりが提示されます。このチュートリアルの完了後すぐにインスタンスを削除すれば、チュートリアルの完了までにかかった時間分の料金しか請求されません(インスタンスの実行時間が 3 時間だった場合、現在の料金では $3 以下の費用となります)。作業内容を保存する場合、使用していない間はインスタンスを停止すれば、ブートディスクのストレージ分の料金しかかかりません。
Google の AI Platform Notebooks インスタンスをカスタマイズすることで、必要なパッケージとフレームワークをすべて備えた開発環境をほんの数分で作成できます。設定は次のように選択します。
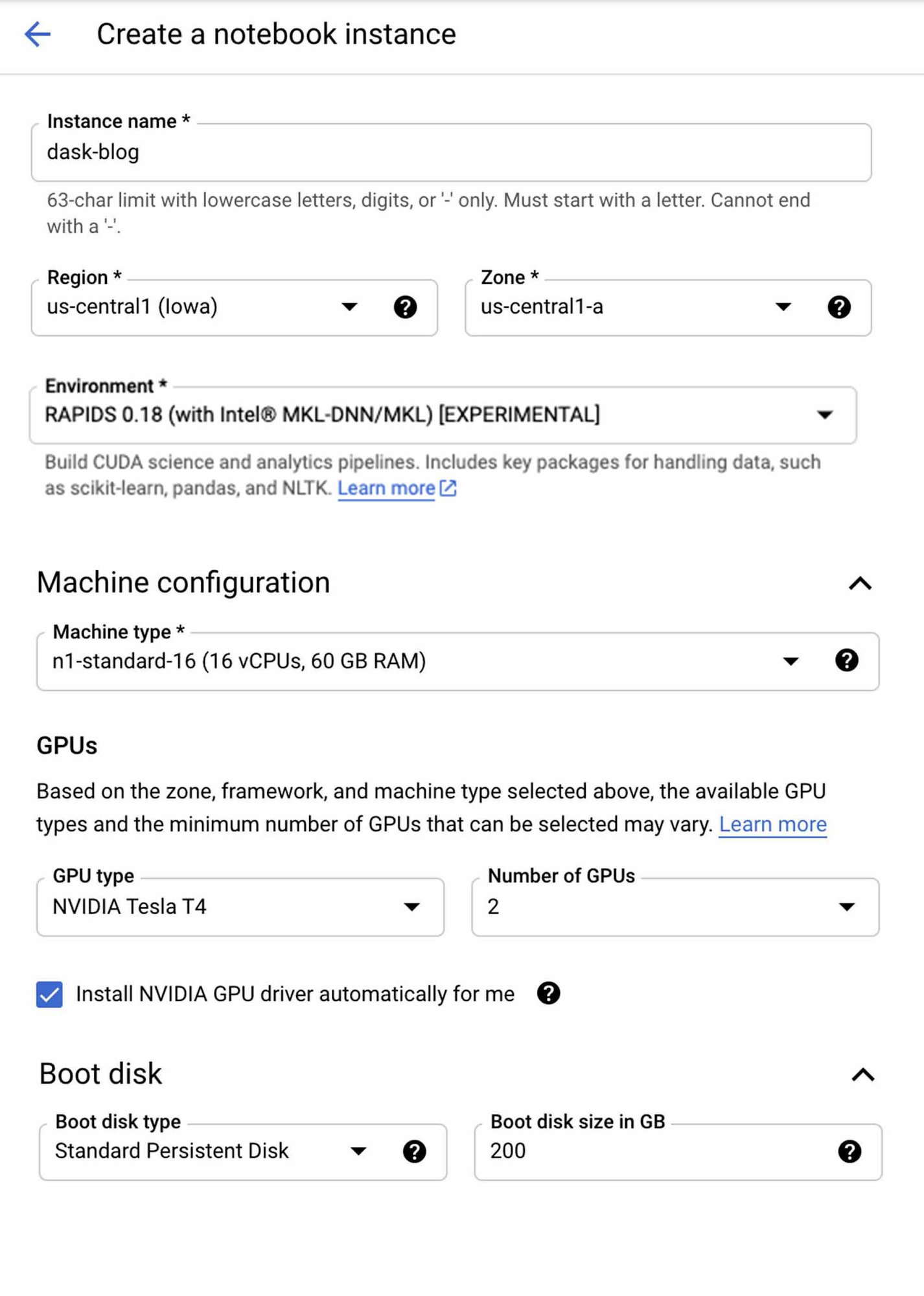
* [NVIDIA GPU ドライバを自動的にインストールする] のチェックボックスを必ずオンにしてください。オンにしない場合、手動でインストールしてインスタンスを再起動する必要があります。
** AI Platform Notebooks インスタンスを使用して Higgs データセットを生成する(後述のセクションで手順をご説明します)場合は、クラウドにアップロードしてブートディスク サイズを 200 GB に増やしてください。
[作成] をクリックしてノートブック環境を起動します。この処理は数分ほどで完了します。完了すると、インスタンスの横に [JupyterLab を開く] というボタンが表示されます。このボタンをクリックして JupyterLab インスタンスに入ります。
AI Platform Notebooks の操作
ほとんどのデータ サイエンティストにとって、Jupyter Notebook の機能は馴染みがあるはずです。必要なライブラリの大部分はすでにインスタンスにインストールされていますが、再現性を確保するために conda 環境を作成します。ターミナルで次のコードを実行します。
Jupyter Notebook 内からターミナル コマンドを発行することもできます。[ファイル] > [新規] > [ノートブック] の順に選択し、新しいコードブロックを作成します。その中に次のコマンドを貼り付けて実行します。これで、このチュートリアル用の GitHub リポジトリのクローンが Notebook インスタンス内に作成されます。フォルダやファイル間を移動するには、Jupyter コンソールの左側にあるファイル ナビゲータを使用します。また、Jupyter コンソールの Git ページから独自の GitHub リポジトリを管理することもできます。
~/ai-platform-samples/training/rapids/rapids_AIP に移動します。このフォルダ内に、このチュートリアルで必要となるファイルがすべて保存されています。まず、dask_blog.ipynb を開きます。
こちらの手順でローカル環境に Dask をゼロからインストールすることもできます。
LocalCudaCluster のインスタンス化
次は LocalCUDACluster をインスタンス化します。このインスタンスは、アタッチされた GPU を Python プロセスにアサインするために使用されます。なお、単一ノードと単一 GPU では Dask を使用する必要はありませんが(cuDF と cuML も使用可能です。これらのライブラリではさらに多くの関数を使用できます)、スケールアップする際には必要となります。
データの準備
このチュートリアルで使用するデータセットは、Higgs Boson Machine Learning Challenge 向けに公開された粒子活動のシミュレーション データです。この公開データセットを複製し、Higgs のさまざまなサブセット(規模の大きいもの、小さいもの)を使用して AI Platform における Dask のスケーリング能力を示します。
リポジトリ内で makedataset.sh スクリプトを実行すると、このデータセットをダウンロードおよび複製し、GitHub で GCS にアップロードできます。このスクリプトは AI Platform Notebooks または別の GCE インスタンスで実行できます。必要に応じてローカルで実行することも可能です。
データを Notebook インスタンスに取り込む方法は数多くあります(ローカル ファイルをアップロードするなど)。ここでは、データを GCS(Google Cloud Storage)から DataFrame に読み込んで GPU で処理します。
cuDF は Python GPU DataFrame ライブラリで、Apache Arrow カラム型メモリ形式に基づいて構築されています。読み込み、結合、集約、フィルタリングのほか、DataFrame スタイルの API を使用した表形式データの操作に使用します。
Dask-cuDF は、DataFrame パーティションを Pandas DataFrame ではなく cuDF GPU DataFrame で処理できるようにするために、必要に応じて Dask を拡張します。たとえば、dask_cudf.read_csv(…) を呼び出すと、クラスタの GPU は基盤となる cudf.read_csv() で CSV ファイルの解析作業を行います。
パフォーマンスを高速化するには、CSV ではなく Parquet 形式を使用します。また、ワーカー全体に作業を分散できるようにデータをシャーディングする必要もあります。これを行う方法は複数あり、読み込む前にデータを複数のファイルに分割してから、* デコレータを使用して読み込むこともできます。このチュートリアルではこの方法を取ります。npartitions 引数を read_csv() で使用するか、Dask 配列でチャンクサイズ単位でパーティションを設定することもできます。
目安として、通常はパーティションあたり NVIDIA T4 GPU では 1 GB、V100 GPU(メモリ 16 GB 超)では 2~3 GB のサイズにすることをおすすめします。これよりパーティションを大きくすると、通常はある程度までパフォーマンスを高速化できますが、使用する GPU メモリに適合するかを確認する必要があります。
これにより最初のデータセットが読み取られ、パーティションの数が表示されます。使用するデータセットのサイズは 10 GB で、1 GB のパーティション 10 個に分割されています。
それでは、Dask DataFrame で基本的な関数をいくつか実行してみましょう。実行には 1 分ほどかかります。なお、Medium のこちらのブログでは、こうした Dask 関数が GPU では CPU と比較して 2~3 倍早く実行されることが示されています。このグループ分けをこのサイズの pandas DataFrame で実行した場合、高確率でマシンでエラーが発生するか、タスク完了までに何時間もかかります。
GPU のメモリ使用状況を追跡するには、rapids-0.17 conda 環境内のターミナルで nvidia-smi dmon を実行します。その他の指標も追跡するには、dask-labextension や nvdashboard などの JupyterLab 拡張機能を利用して、GPU メモリの使用状況と使用率といったさまざまなグラフと指標を可視化します。dask-labextension を使用すると、GPU の使用率の変化が大きいことがわかります。「Dask Gpu Memory」の合計は localCUDAcluster の合計メモリ(ノートブック インスタンスの CPU メモリを含む)を計測しているため、正確ではありません。
現在のところ、AI Platform Notebooks でサポートされていない JupyterLab 拡張機能の使用は難しいことがあります(Git リポジトリに手順説明を含めていますが、他の構成で機能するかどうかは保証していません)。このような指標の追跡が要件となる場合は、Dask を GKE または Dataproc で使用して、独自の Jupyter 環境を構築することをおすすめします。次回のブログでは、より詳細な GPU 指標を可視化する方法をご紹介する予定です。
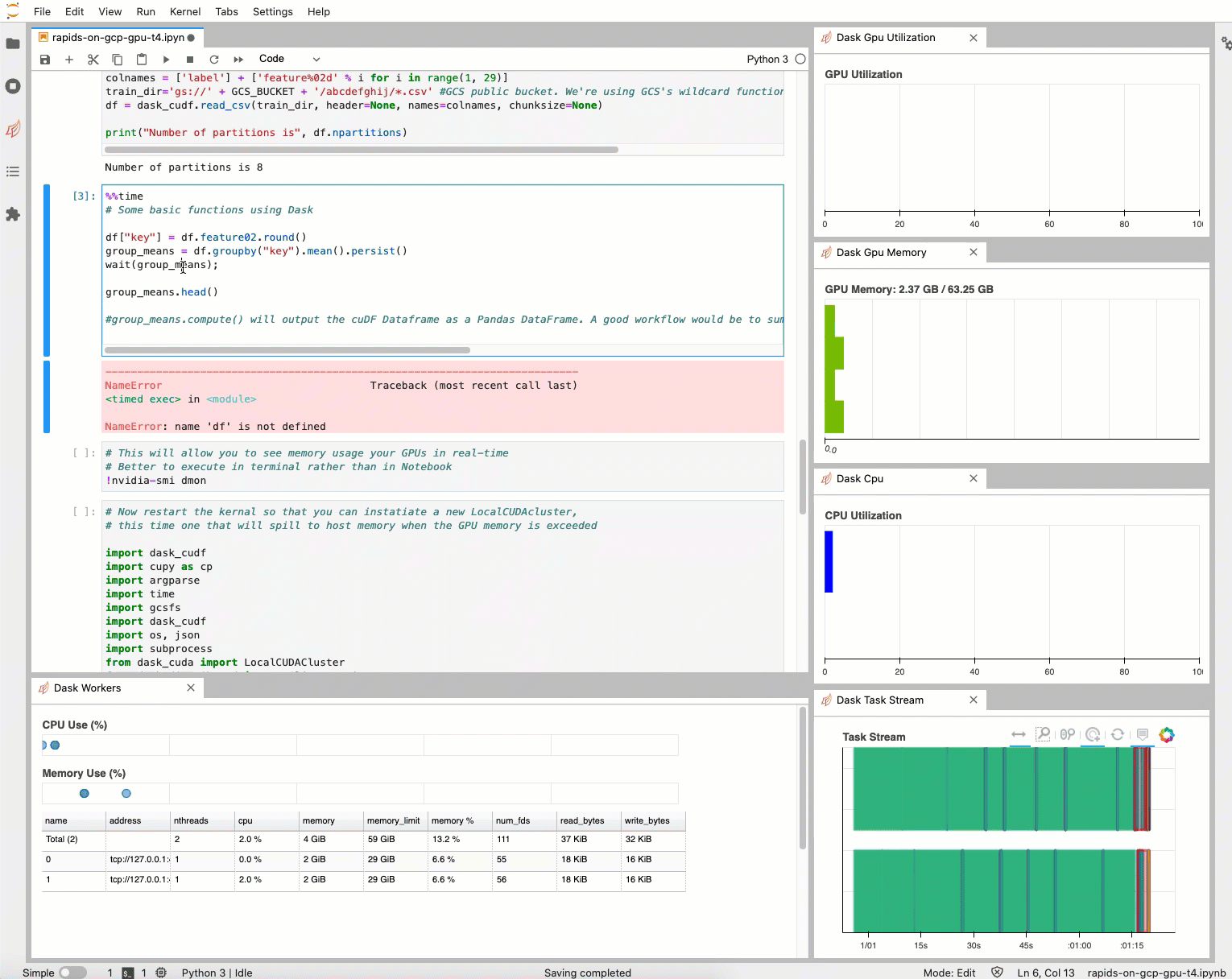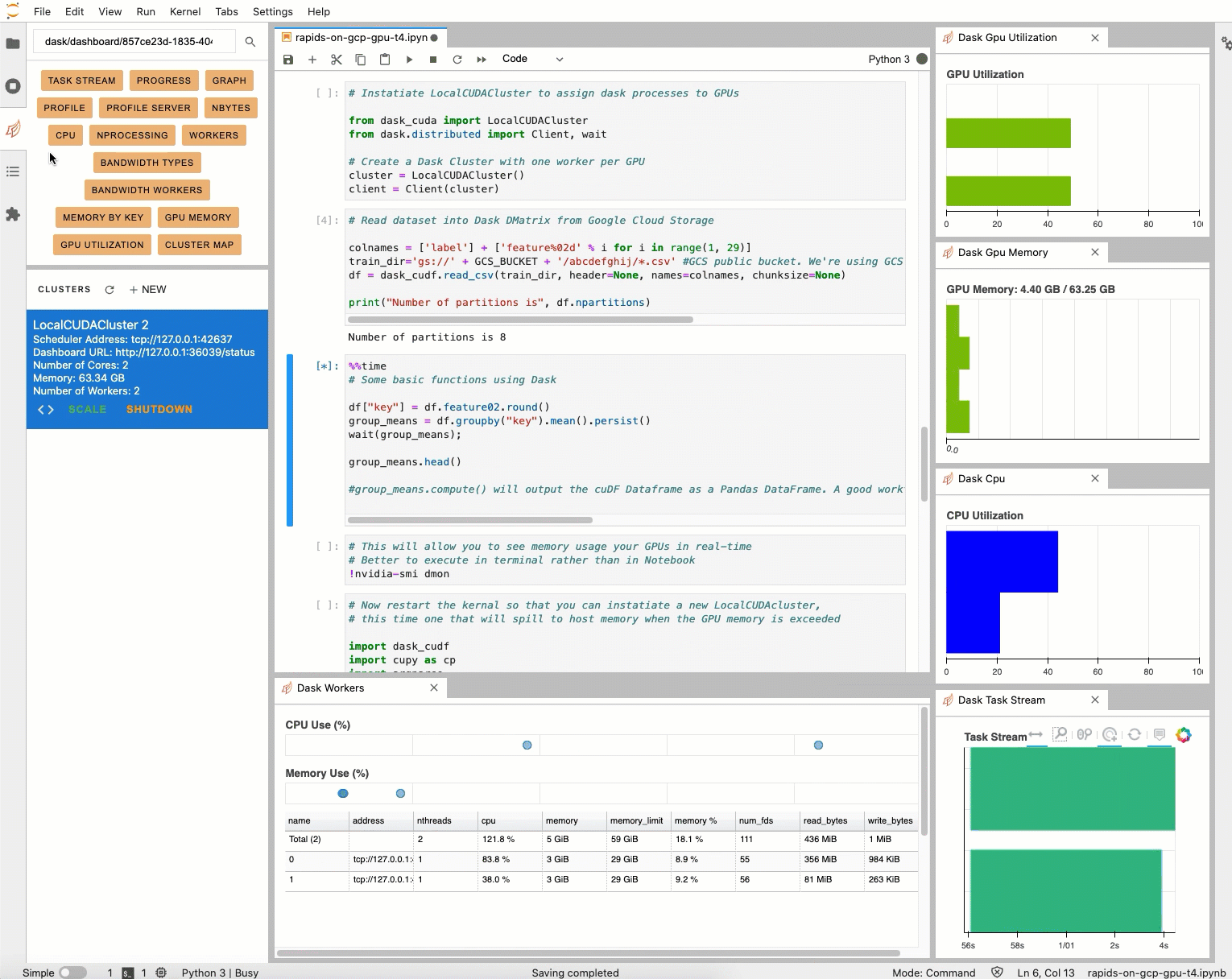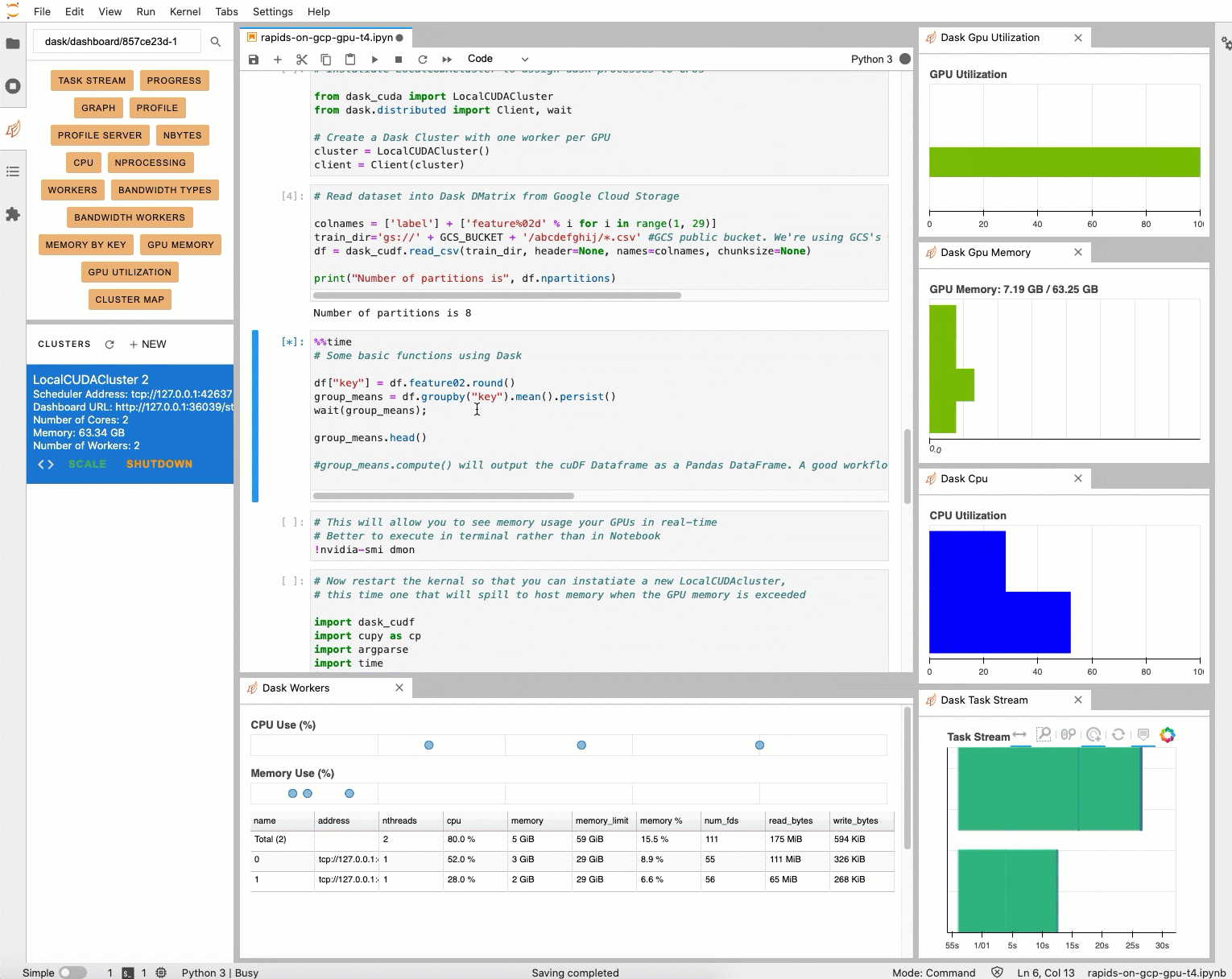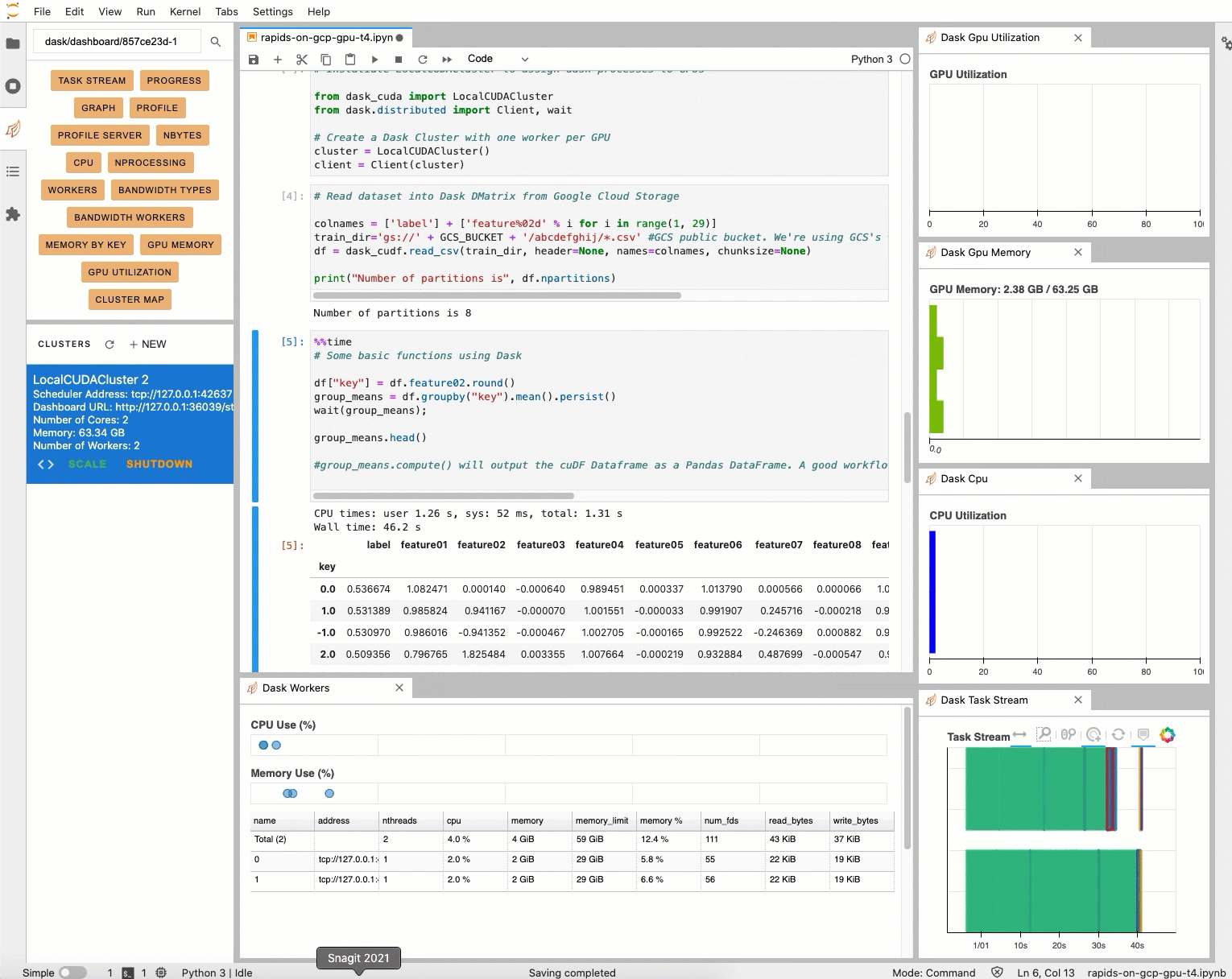
20 GB までスケールする
読み込もうとしているデータセットは 20 GB ありますが、アタッチされた NVIDIA T4 GPU にはメモリが 16 GB しかありません。ありがたいことに、Dask では GPU がメモリ不足になっても、GPU メモリからホストメモリにデータをあふれさせることができます。これを行うには、Python カーネルを再起動して、device_memory_limit セットで新しい LocalCUDACluster を作成します。通常、Dask はデフォルトでディスクにあふれさせますが、device_memory_limit を設定すると、どの時点であふれさせるかを制御できます。
なお、新しい LocalCUDACluster は、ターミナルと JupyterLab のカーネル セッション管理ページを使用して、カーネルをシャットダウンし、再起動することでインスタンス化できます。必ず rapids-0.17 カーネルを選択してください。
コードをもう一度実行すると、関数が実行されます。制約があっても実行できるよう、Dask がデータの移動を制御します。実行には約 2 分ほどかかります。
AI Platform Training を使用して 100 GB までスケールする
次は、100 GB のデータセットで XGBoost モデルをトレーニングします。ただし、Dask DataFrame を使用しても、XGBoost は完全にメモリ内で実行されるため、GPU からホストメモリに動的にあふれさせることができません。つまり、GPU を増強する必要があります。
AI Platform Notebooks インスタンスは、より多くの GPU または別種の GPU を使用して簡単にサイズ変更を行えます。しかしここでは、AI Platform Training をカスタム コンテナと使用する、より動的な方法を取ります。AI Platform Training は指定されたリソースをスピンアップしてコードをジョブとして実行し、完了するとリソースをスピンダウンします。使用するコードは簡単にパッケージ化して AI Platform Notebooks から送信できます。
実行するのは前述で使用したものと同じライブラリですが、実行場所は NVIDIA A100 GPU 4 基を接続した AI Platform Training です。AI Platform で使用可能な A100 には、40 GB の GPU メモリが搭載されており、マシン 1 台あたり最大 16 基までスケールアップが可能です。複数ノードへの分散について心配する必要はありません(このブログの公開時点では、16 基に対応しているクラウド プロバイダは GCP のみです)。つまり、実に 640 GB もの GPU メモリを使用できるということです。そのため、環境の管理が容易になり、複数ノードの構成を扱う際に発生する可能性があるネットワーキングの問題を抑えることができます。
コンテナによるトレーニング
コンテナを使用すると、トレーニング ジョブをどのマシンで、どのように送信するかを完全にカスタマイズできます。
Git リポジトリ全体のクローンをすでに作成済みなので、JupyterLab ナビゲーション パネルを使用して XGboost_training フォルダに移動します。フォルダ内には、RAPIDS ベースのコンテナをビルドし、AI Platform Training ジョブをデプロイするために必要なファイルがあります。
コンテナをビルドする
使用している Dockerfile 内に RAPIDS のベースイメージが表示されます。
コンテナをビルドして独自の GCR に push するには、build.sh を開いてリポジトリと照合するパスを更新し、スクリプトを実行します。
これでトレーニング ジョブを送信する準備が整いました。送信するには、AI Platform Notebooks のターミナルにある次のコードを実行します(README ファイルでもご確認いただけます)。
ジョブをモニタリングするには、Cloud Console で、AI Platform のジョブ一覧([AI Platform] > [ジョブ])から該当ジョブをクリックします。ジョブの詳細ページには、CPU と GPU の使用率などのさまざまな指標が表示されます。さらに、[ログを表示] をクリックすると Cloud Logging に移動して、ジョブによって生成されたすべてのログを表示できます。また、gcloud ai-platform jobs stream-logs $JOB_NAME を実行して、ログをターミナルにストリーミングすることも可能です。
トレーニング環境を起動してコードの実行を開始するまでには 11 分ほどかかります。ログを観察することで、手順を追うことができます。さらに、使用状況の指標が反映されるまでに数分ほどかかります。100 GB のデータセットを使用してこのジョブを実行した際は、19 分で完了しました(トレーニング環境の起動時間を含みます)。XGBoost によるトレーニング部分には 56 秒しかかかりませんでした。
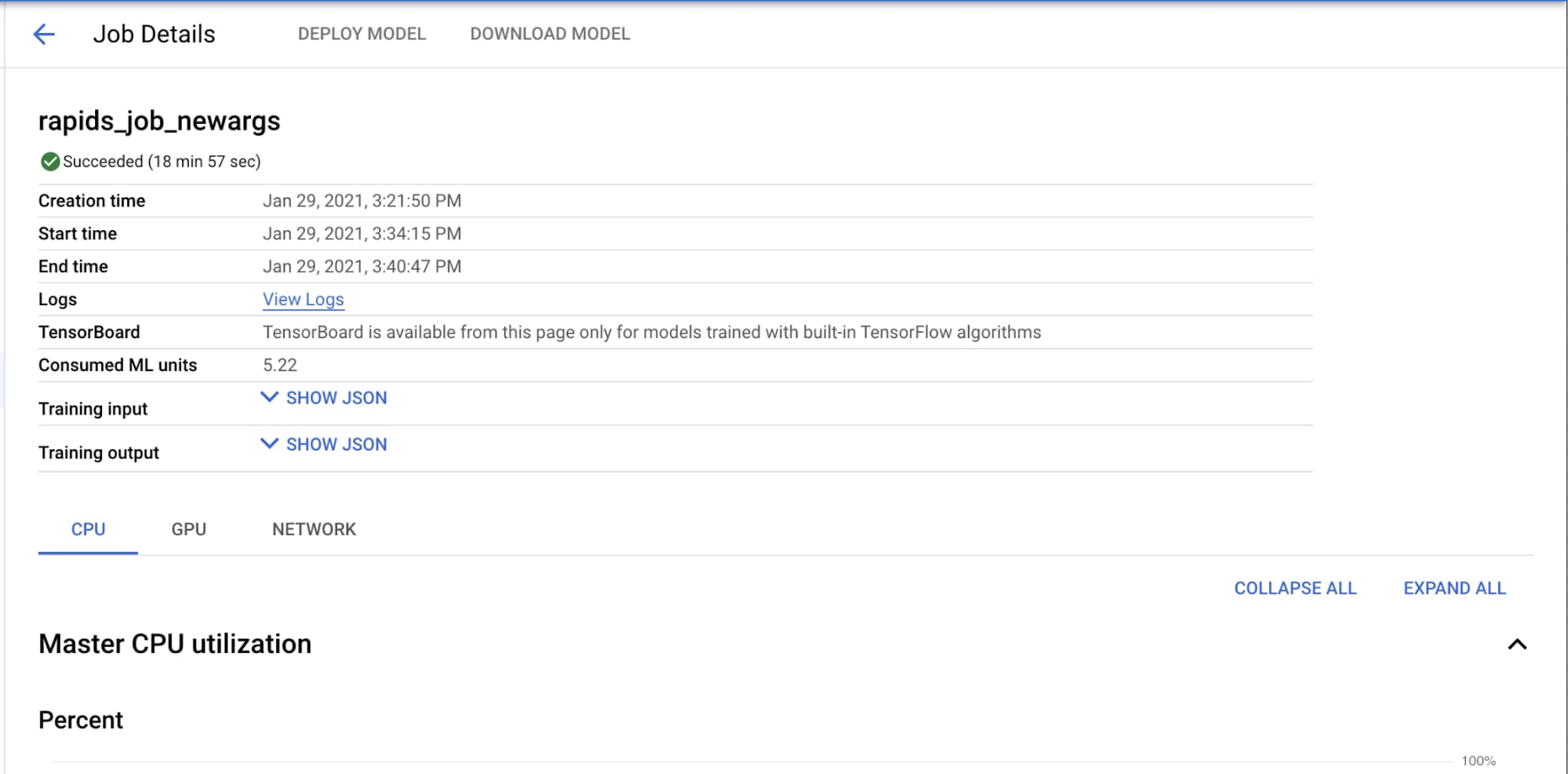
YAML ファイルをわずか数か所変更するだけで、同じコードを 4 基の NVIDIA T4 GPU で実行できます。Dask は GPU メモリだけでは実行を完了できないと判断し、必要に応じてディスクにあふれさせます。その結果、ジョブの実行時間は全体で 20 分、トレーニング時間は 124 秒となります。8 基の V100 GPU を使用した場合、トレーニング時間はたった 28 秒でした。AI Platform では簡単に構成を変更できるので、さまざまなリソース構成とデータサイズで試してみることをおすすめします。
オンライン予測用のモデルをデプロイする
GCS バケットでのモデルのトレーニングが完了したので、次はモデルをオンライン推論用に AI Platform Predictions にデプロイします。ここでも GPU を活用して推論速度を上げることができます。
クリーンアップ
これ以降は料金が発生しないようにするため、AI Platform Notebooks インスタンスを削除します。作業内容を保存する場合は、削除する代わりにインスタンスを停止するように選択できます。
GCS バケットを削除します。
まとめ
Dask は、ここ数年で著しい成長を遂げた画期的なフレームワークです。RAPIDS と Dask を組み合わせると、NVIDIA GPU のパワーを活用して、データ処理とトレーニングにかかる時間を大幅に削減できます。NVIDIA A100 GPU を使用すると、NVIDIA T4 GPU と比較して、データ量が 2 倍になった場合でもトレーニング時間が短くなることがわかりました。
また、Dask は利用可能なリソースに基づいて実行方法を自動的に調整できる面でも便利です。GPU メモリを使い切ると、CPU メモリを使用するよう Dask が自動的に元に戻すこと、その仕組みが制御可能なことを確認しました。
AI Platform では、Dask の使用を簡単に開始できます。AI Platform Notebooks では任意の数の GPU を使用して、JupyterLab 環境で開発できます。さらに、AI Platform Training を使用して、パワーアップしたマシンで実行するように、必要に応じてコードをスケールアップすることも可能です。16 基もの A100 GPU を自由に使って何ができるか、想像してみてください。
NVIDIA GPU で XGBoost トレーニングを加速できる証拠をさらに確認する場合は、こちらのブログをご覧ください。A100 を活用するその他のおすすめの方法は、こちらでご覧いただけます。
私を指導し、サンプル ワークフロー作成を支援してくださった Mikhail Chrestkha、Winston Chiang、Guoqing Xu、Ethem Can、Dong Meng、Arun Raman、Rajesh Thallam、Michael Thomas、Rajan Arora、Subhan Ali(敬称略)に厚くお礼申し上げます。
-カスタマー エンジニア Remy Welch



