Machine learning with XGBoost gets faster with Dataproc on GPUs
Karthik Rajendran
Product Manager, AI and Big Data at NVIDIA
Dong Meng
Solution Architect, NVIDIA
Google Cloud’s Dataproc gives data scientists an easy, scalable, fully managed way to analyze data using Apache Spark. Apache Spark was built for high performance, but data scientists and other teams need an even higher level of performance as more questions and predictions need to be answered using datasets that are rapidly growing.
With this in mind, Dataproc now lets you use NVIDIA GPUs to accelerate XGBoost, a common open source software library, in a Spark pipeline. This combination can speed up machine learning development and training up to 44x and reduce costs 14x when using XGBoost. With this kind of GPU acceleration for XGBoost, you can get better performance, speed, accuracy, and reduced TCO, plus an improved experience when deploying and training models. Spinning up elastic Spark and XGBoost clusters in Dataproc takes about 90 seconds. (We’ll describe this process in detail later in the post.)
Most machine learning (ML) workloads today in Spark run on traditional CPUs, which can be sufficient for developing applications and pipelines or working with datasets and workflows that are not compute-intensive. But once developers add compute-intensive workflows or machine learning components to the applications and pipelines, processing times lengthen and more infrastructure is needed. Even with scale-out compute clusters and parallel processing, model training times still need to be reduced dramatically to accelerate innovation and iterative testing.
This advancement to GPU acceleration with XGBoost and Spark on Dataproc is a big step forward to make distributed, end-to-end ML pipelines an easier process. We often hear that Spark XGBoost users run into some common challenges, not only in terms of costs and training time but also with installing different packages required to run a scale-out or distributed XGBoost package on a cloud environment. Even if the installation is successful, reading a large dataset into a distributed environment with optimized partitioning can require multiple iterations. The typical steps for an XGBoost training include reading data from storage, converting to DataFrame, then moving into XGBoost’s D-matrix form for training. Each of these steps depends on CPU compute power, which directly affects the daily productivity of a data scientist.
See the cost savings for yourself with a sample XGBoost notebook
You can use this three-step process to get started:
Download the sample dataset and PySpark application files
Create a Dataproc cluster with an initialization action
Run a sample notebook application as shown on the benchmark clusters
Before you start a Dataproc cluster, download the sample mortgage dataset and the PySpark XGBoost notebook that illustrates the benchmark shown below. The initialization action will ease the process of installation for both single-node and multi-node GPU-accelerated XGBoost training.
The initialization step has two separate scripts. First, initialization script.sh will pre-install GPU software that includes CUDA drivers, NCCL for distributed training, and GPU primitives for XGBoost. Second, rapids.sh script will install Spark RAPIDS libraries and Spark XGBoost libraries on a Dataproc cluster. These steps will ensure you have a Dataproc cluster running and ready to experiment with a sample notebook.
Saving time and reducing costs with GPUs
Here’s the example that produced the numbers we noted above, where training time—and, as a result, costs—go down dramatically once XGBoost is accelerated:
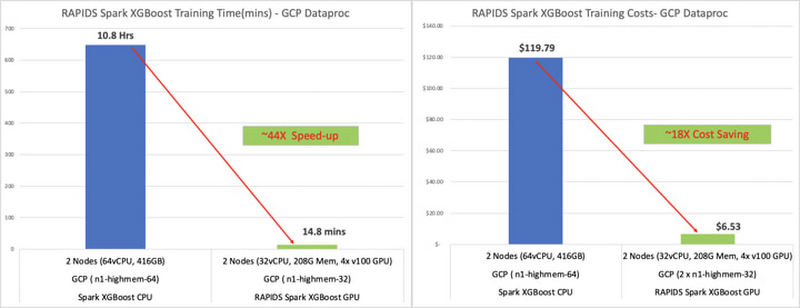
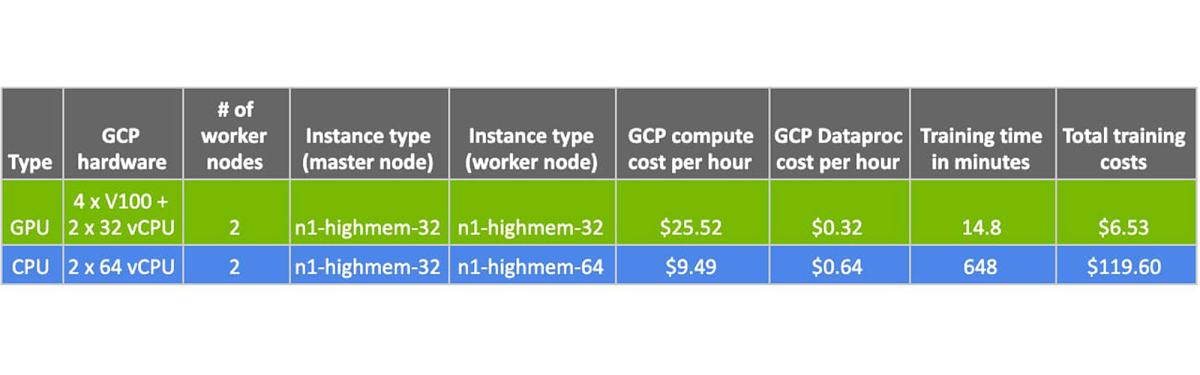
Here are the high-level details of this GPU vs. CPU XGBoost training comparison on Dataproc:
Once you’ve saved this time and cost, you can focus on making models even smarter by training them with more data. While being smarter, you can also be faster by progressing sooner to the next stage in the pipeline.
Stay tuned for additional capabilities and innovations coming with the release of Spark 3.0 later in the year.
For more on AI with NVIDIA GPUs, including edge computing and graphics visualization, check out these on-demand online sessions: Google Cloud AutoML Video and Edge Deployment and Building a Scalable Inferencing Platform in GCP.

