Google Cloud と Equinix: 効果的な ML 運用(MLOps)の実現

Google Cloud Japan Team
※この投稿は米国時間 2023 年 5 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
近年、さまざまな分野にわたり、複雑な問題を効果的に解決するツールとして、ML の活用が広まっています。しかし、大規模な ML モデルの構築とデプロイは、データの準備、特徴量エンジニアリング、モデルのトレーニング、デプロイ、モニタリング、メンテナンスなど多くのタスクが関わるため、容易ではありません。
Accenture のレポート「The Art of AI maturity」では、「データ サイエンス プロジェクトの 87% が本番環境への移行に至らない」と報告されています。そこで役立つのが MLOps です。MLOps は、データの収集や準備から、モデルの開発、テスト、デプロイまで、ML のライフサイクル全体を管理するためのフレームワークを提供し、主要課題の解決を促進します。また、ML モデルの開発から本番環境への移行までの期間を短縮し、ML プロジェクトの成功率を高めます。
Google Cloud は、ML モデルを適切に本番環境に移行するためには、MLOps が重要であることを理解しています。そこで、世界最大級のデジタル インフラストラクチャ企業(The world’s digital infrastructure company™)の Equinix と連携しました。Equinix はグローバル コロケーション データセンターで最大級の市場シェアを誇り、5 大陸の 27 か国にわたり 248 のデータセンターを有しています。Google Cloud は、MLOps のベスト プラクティスやアーキテクチャに関するアドバイザリ サービスを提供することで、Equinix を支援しました。
Equinix における MLOps の要件と、最終的に提案されたアーキテクチャを見ていきましょう。
Equinix にとっての MLOps の意味
Google Cloud は、Equinix 側のチームと複数回にわたり調査セッションを開いた後、Equinix の新しい MLOps アーキテクチャで対処すべき主な要件と課題を特定しました。それは次のとおりです。
再利用性: 特徴やパイプラインなどのコンポーネントをプロジェクト間で再利用することで費用を削減し、効率を高める。
基盤: 環境、フォルダ構造、プロジェクト階層などのインフラストラクチャ基盤は、スケーラビリティと信頼性を確保できるよう適切に設計する。
問題の早期特定: データの検証、通知、再試行の仕組みを用意することで問題を早期に特定する。
費用の最適化: 従量制の料金体系にし、費用を最適化する。
エンタープライズ規模の CI / CD 要件: GitHub や GitActions と統合し、エンタープライズ規模の CI / CD 要件に対応する。
スケーリング: 将来的な成長に合わせてインフラストラクチャをスケールできるようにする。
セキュリティ: IAM のロール、ネットワークなど、エンタープライズ規模のセキュリティ要件に対応する。
MLOps のアーキテクチャ
Equinix が示した上述の要件に基づき、設計上の主なポイントが検討されました。たとえば、オンラインの特徴サービングに Big Query ではなく Vertex AI Feature Store を使用すること、前処理に既存の Python ではなく DataFlow を使用することなどです。あらゆる選択肢が慎重に検討された後、GCP 内の MLOps に次のリファレンス アーキテクチャが提案されました。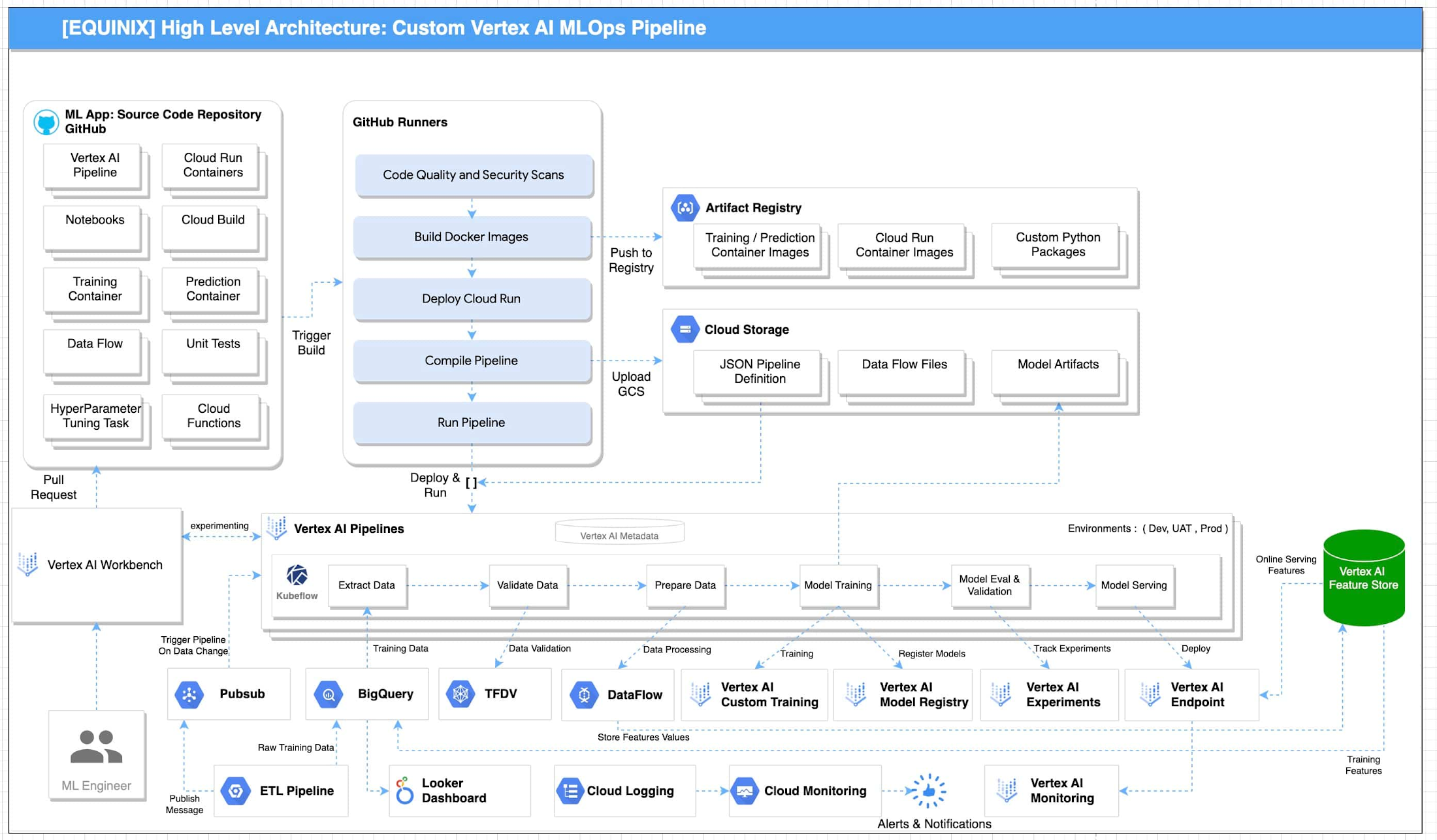
GCP を使用した MLOps のリファレンス アーキテクチャを図 1 に示します。このアーキテクチャには次のパイプライン ステージがあります。
Vertex AI Workbench は、データ サイエンティストが新しいアイデアの検討、新しいモデルの開発やテストを短時間で実施できるようにします。ソースコードは GitHub のリポジトリに保存されます。
自己ホスト型のランナーを備えた GitHub Actions が、ソースコードのリポジトリとして GitHub に統合されています。このため、コード、品質、セキュリティ スキャンの継続的インテグレーションが可能です。プロセス中に生成されるアーティファクトは Artifact Registry と Google Cloud Storage に保存されます。これらのアーティファクトがデプロイされ、パイプラインが実装されます。
単体テストと統合テストは、自己ホスト型ランナーを備えた GitHub Actions における継続的インテグレーション中に実施できます。エンドツーエンド テストは、継続的インテグレーションのパイプラインで必要に応じて実施されます。
アーティファクトに関するメタデータは Vertex ML Metadata で生成、保存されます。
パイプラインを実行する自動トリガーを有効にできます。たとえば、新しいトレーニング データが利用可能状態になることをトリガーにできます。こうしたトリガーにより、モデル トレーニングのパイプラインを実行し、新しいトレーニング済みモデルを Vertex AI Model Registry に push できます。
新しい ML モデルを新しいデータでトレーニングするために、デプロイ済みの Vertex AI パイプラインが実行されます。
新しい ML モデルを新しい実装でトレーニングするために、CI / CD パイプラインを通じて新しいパイプラインがデプロイされます。
「提案されたアーキテクチャ設計は、当社が求めていた要件とシナリオを網羅しています。当社の AI と ML のポートフォリオは規模も複雑さも増しているため、ソリューションが提供する価値を継続的に高めていくには、明確な最新のアーキテクチャに従うことが重要です。このプロセスの一環として、チームはこれを完全に実装するためのスキルも習得できました」と、Equinix のデータ サイエンス担当シニア マネージャーの Bernardo Fernandes 氏は述べています。
Equinix における MLOps の実装前と実装後の機能の概要を次に示します。
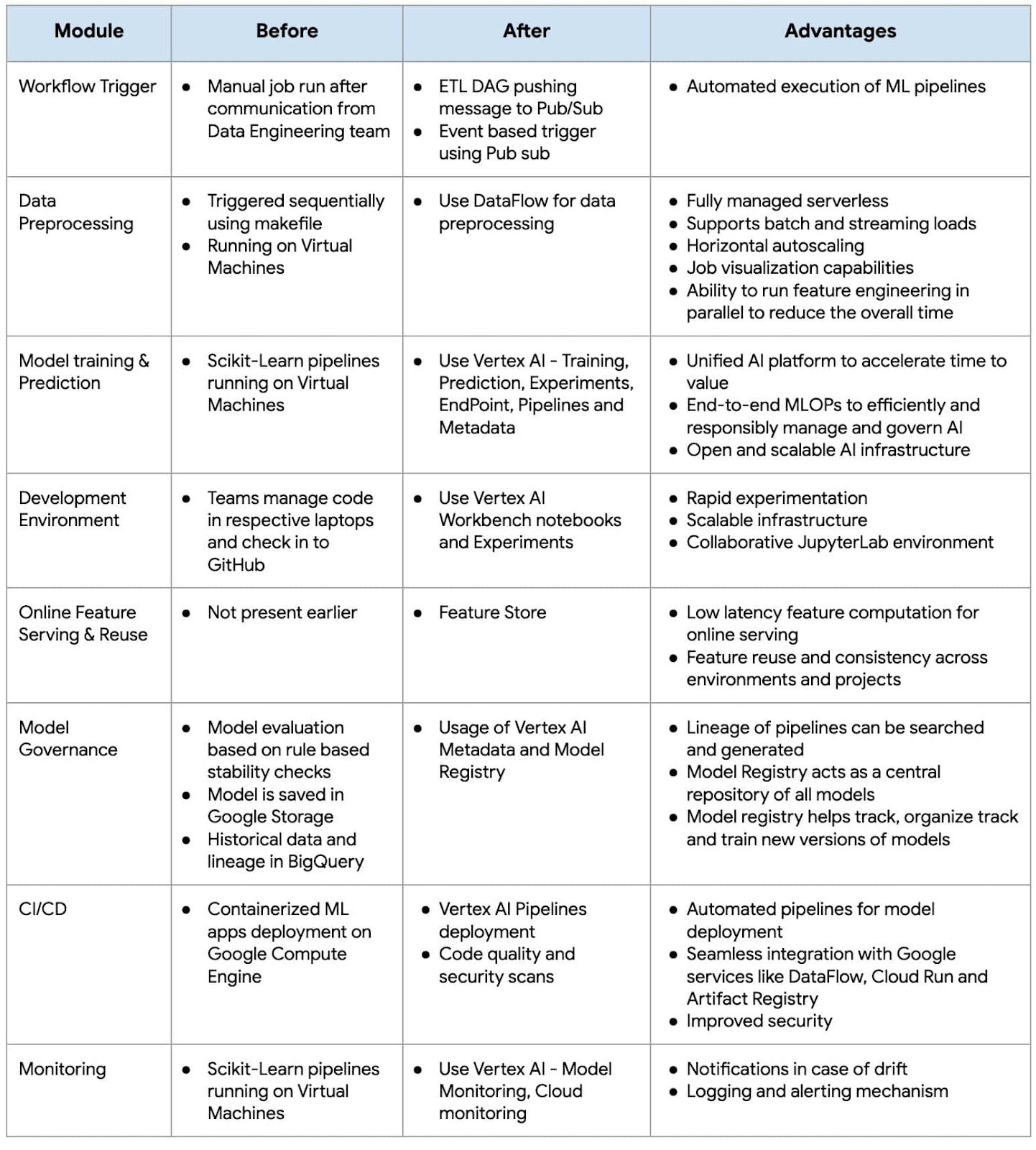
競争力強化のために ML を活用する企業が増加する中、MLOps がその戦略の重要な要素となっています。MLOps 手法を導入することで、組織は ML の取り組みにおいて、製品化までの時間を短縮し、パフォーマンスや ROI を高めることができます。
Google Cloud AI サービス(AIS)によるエンドツーエンドの迅速な導入
Google Cloud と Equinix のパートナーシップは、組織が望ましい結果を推進するために、複雑な問題を解決する AI 搭載ソリューションを提供している最新の例のひとつです。Google Cloud の AI サービスについて詳しくは、AI と ML のプロダクト ページをご覧ください。
Nitin Aggarwal、Vijay Surampudi、Parag Mhatre、Anantha Narayanan Krishnamurthy には、プロジェクト全体を通したサポートと指導に対して深く感謝します。また、Equinix のチーム(Ravi Pasula 氏、Brendan Coffey 氏、Bernardo Fernandes 氏、Łukasz Murawski 氏、Jakub Michałowski 氏、Sonia Przygocka-Groszyk 氏、Marek Opechowski 氏、Daria Bondara 氏、Nila Velu 氏、Vijay Narayanan 氏、Dharmendra Kumar 氏、Shailesh Sukare 氏、Arunraj Kumar Raje 氏、Seng Cheong Lee 氏)との円滑な連携にも感謝いたします。
- Google Cloud、AI プロジェクト リード Sharmila Devi



