パーソナライズされたウェブ エクスペリエンスの実現: Vertex AI のエンベディングを使用してユーザーのコンテキストを把握しやすく
Shuhei Kondo
Data Science Engineer, PLAID, Inc.
Miki Katsuragi
AI Consultant, Google Cloud Japan
※この投稿は米国時間 2024 年 8 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
めまぐるしく変化するデジタルの世界において、ウェブサイトやアプリケーションでのユーザーの行動をリアルタイムに解析して顧客体験を向上させる PLAID, Inc. の KARTE のようなプラットフォームでは、ユーザーのコンテキストを把握することが非常に重要になります。最近、PLAID と Google Cloud は、Vertex AI の大規模言語モデル(LLM)やエンベディング技術を含む生成 AI を活用して KARTE のカスタマー サポートを改善するプロジェクトに着手しました。KARTE はエンベディングによってユーザーの意図をより良く理解するため、KARTE のカスタマー サポート機能で関連性の高いレコメンデーションを提供してお客様からの問い合わせに迅速に回答し、顧客満足度を高めることができます。
事前トレーニング済みエンベディングでユーザーの意図を掴む
このプロジェクトの目的は、Vertex AI の エンベディングを活用して、適切なヘルプ コンテンツを推奨するようモデルをトレーニングすることです。このレコメンデーション システムは、クエリとコーパスという 2 つの主要なデータタイプに基づいて動作し、クエリからユーザーの意図を掴んでレコメンデーションのコーパスと照合することに重点を置いています。
実際、ユーザーが KARTE を介してウェブサービスのコンテンツにアクセスし、KARTE のヘルプページで支援を求めたときに、適切なコンテンツが見つからないことがよくあります。当社のモデルは、ユーザーのウェブイベント ログをクエリとして解釈し、それらをコンテキスト内の課題に対処する有用なコンテンツと照合します。レコメンデーションの設計にあたっては、KARTE のウェブログ、KARTE のヘルプページのコンテンツ、KARTE の管理画面を利用しました。エンベディングを使用したリコメンデーションの設計には、次のフローを使用しました。
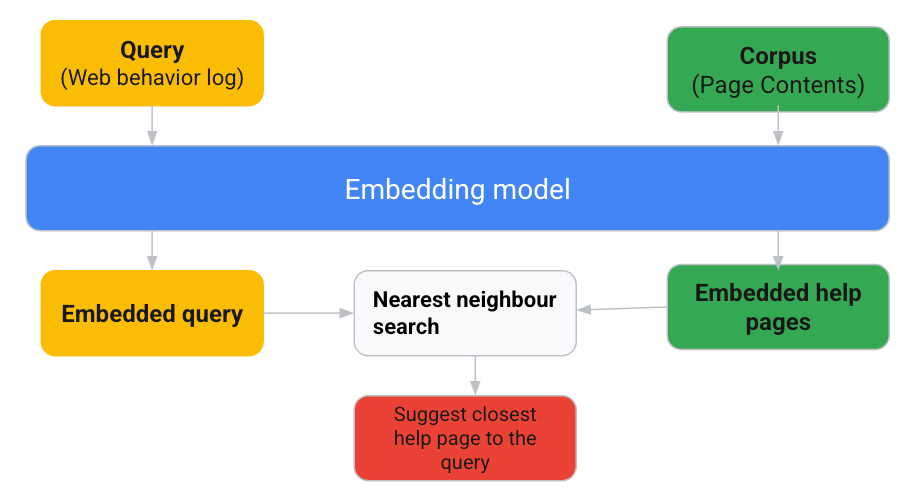
クエリ コンポーネントはユーザー操作データ(特に訪問したページのタイトル)から生成して、ユーザーの最近の関心やニーズを反映させます。この方法をさらに広げて、ページのタイトルに基づいてテキスト プロンプトを作成し、モデルがユーザーの意図をより良く理解できるようにします。単に訪問したページのタイトルを使用するだけでなく、以下のようなテキストをプロンプトとして作成しました。
また、さまざまなバリエーションでパフォーマンスを検証するために、次の 4 種類のプロンプトを作成しました。
-
プロンプト 1: 現在のセッションでのすべてのユーザー行動を含みます(ヘルプページを訪問するまで)
-
プロンプト 2: そのセッションでのユーザー行動だけでなく、過去 30 日間の訪問回数が最も多かった上位 50 ページも含みます
-
プロンプト 3: プロンプト 2 と同様ですが、上位 5 ページのみを含みます
-
プロンプト 4: 現在のセッションで訪問した最後の 3 ページのみという、非常に少ない情報を使用してテストします
ユーザーのテキスト(クエリ)とウェブサイトのコンテンツ(コーパス)の両方をエンベディングに変換することで、ユーザーの意図の本質を捉えてセマンティック分析に使用できるようにしました。このプロセスにより、クエリとコーパスのエンベディングを有意に比較でき、レコメンデーションをユーザーの状況に応じたニーズに整合する、関連性の高いものにすることができます。
事前トレーニング済みエンベディングを使用したベンチマークの作成
事前トレーニング済みエンベディングを使用したベンチマークは、モデルのパフォーマンス向上を評価する鍵となります。まず、「textembedding-gecko-multilingual@latest」のモデルをベンチマークとしてテストしました。パフォーマンスを測定するために、正規化された減価累積利得(NDCG)指標を使用して、検索システムとレコメンデーション システムの有効性を評価しました。NDCG は各項目の関連性を考慮して、リストの下に行くほど重要度が下がり、上に行くほど関連性が上がるように、リストの位置に基づいてスコアを増減します。
事前トレーニング済みエンベディングを使用した、プロンプト 1~4 の NDCG は次のとおりです。
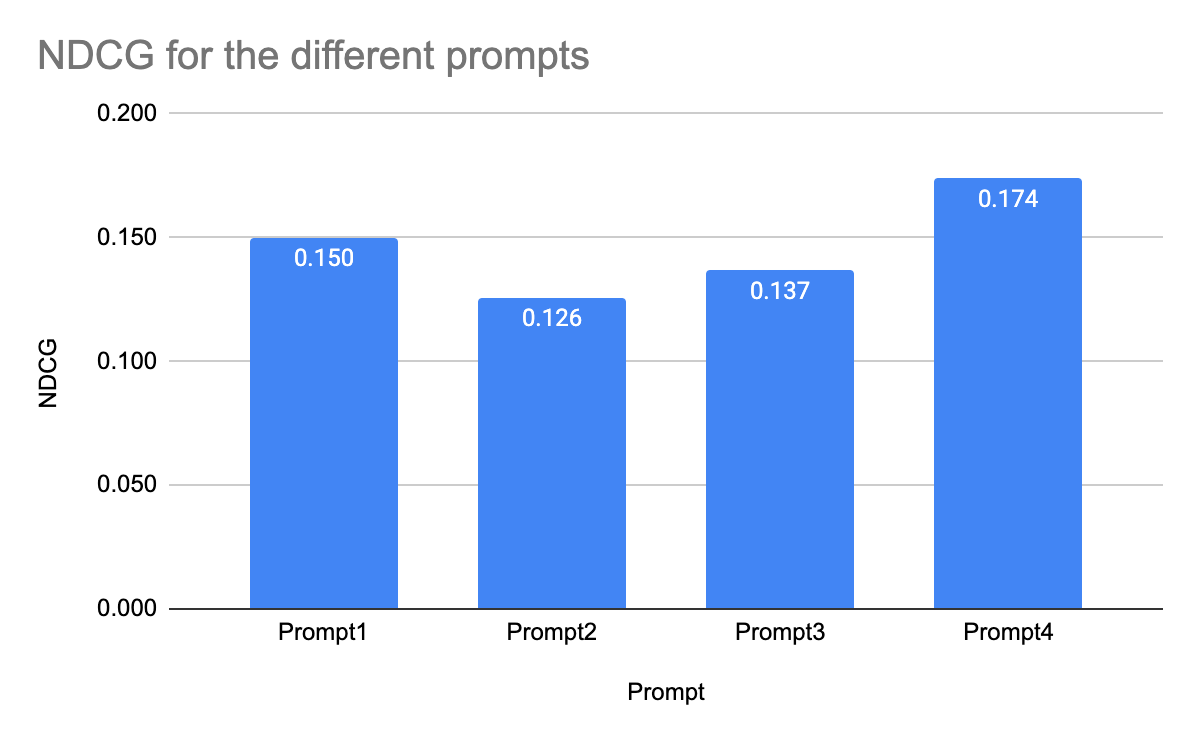
事前トレーニング済みエンベディングの場合、プロンプトが単純なほど NDCG スコアが高くなりました。訪問した最後の 3 ページのみを含む、最も単純なプロンプトのスコアが最も高く、最も複雑なプロンプトのスコアが最も低い結果となりました。これは、事前トレーニング済みエンベディングでは、簡潔な情報を使用したほうがパフォーマンスが高く、複雑なプロンプトでは良い結果が得られないことを示しています。以降のステップでは、チューニング済みエンベディングを使用したテストにより、この傾向が変わらないかどうかを確認します。
チューニング済みエンベディングを使用したパフォーマンスの向上
次に、エンベディング モデルをチューニングし、そのパフォーマンスを事前トレーニング済みモデルと比較しました。次の手順でエンベディングをチューニングしました。
-
チューニング用データセットを準備します。
-
モデルのチューニング用データセットを Cloud Storage バケットにアップロードします。
-
モデルのチューニング用ジョブを作成します。
-
チューニングされたモデルを Vertex AI エンドポイントにデプロイします。
エンベディング モデルをチューニングするためのデータセット形式
エンベディング モデルをチューニングするには、Cloud Storage のトレーニング データセットに 4 つのファイル(クエリファイル、コーパス ファイル、2 種類のトレーニング ラベルファイル)が必要です。トレーニング ラベルは、それぞれのクエリファイルとコーパス ファイルにリンクしているクエリ ID とコーパス ID を使用して、クエリのサブセットをコーパスと照合します。スコアは負でない整数であり、関連性を示すものです。スコアが高いほど関連性が高いことを示し、省略した場合はデフォルトのスコア 1 になります。これらのファイルのパスは、チューニング パイプラインの起動時にパラメータで指定されます。
チューニングに使用されるファイルは以下のとおりです。

エンベディングのチューニングによるパフォーマンスの向上
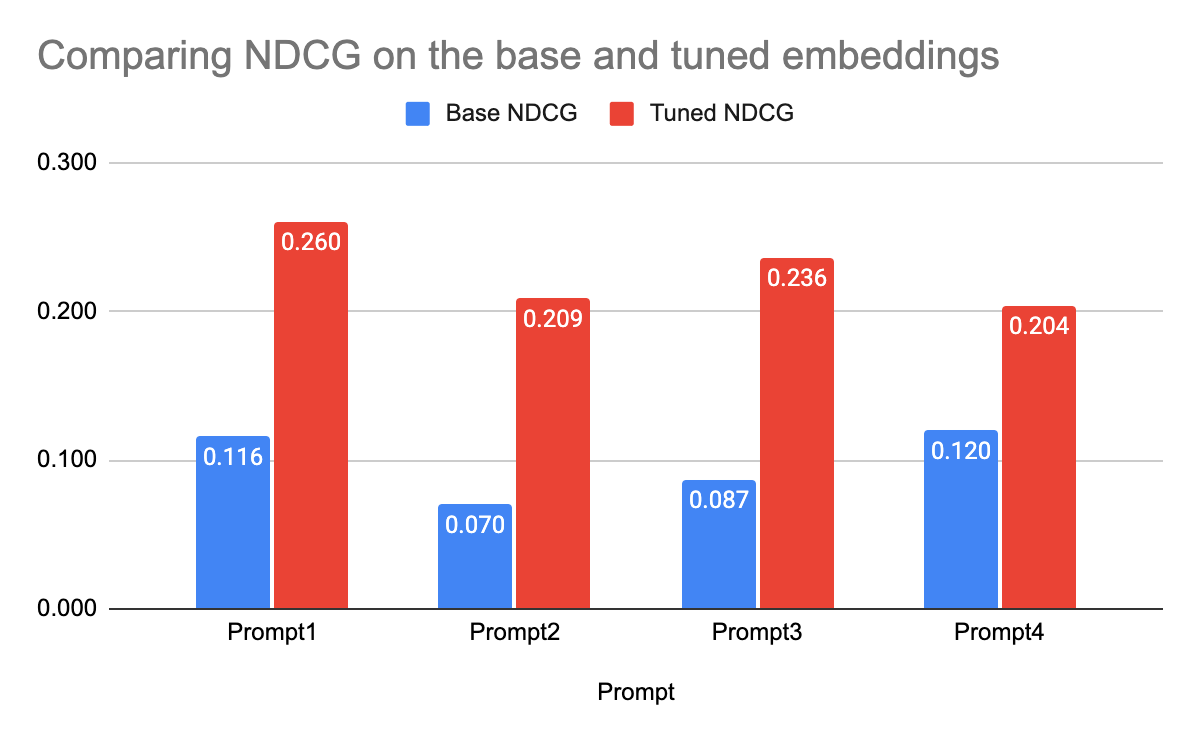
各プロンプトに対して 4 つのチューニング済みエンベディング モデルを作成した後、すべてのモデルで NDCG が大幅に改善しました。事前トレーニング済みエンベディングでは最も単純なプロンプト(プロンプト 4)のスコアが最も高かったのに対し、今回はこのプロンプトのスコアが最も低く、チューニング済みモデルが他のプロンプトからの追加情報を効果的に使用していることが示されました。ただし、最も情報量の多いプロンプト(プロンプト 2)の NDCG は前回と同様に 2 番目に低く、パフォーマンスの最適化に際しては、プロンプトで提供する情報量のバランスを取る必要があることが示唆されています。
明らかになったポイントと、さらなる改善のための次のステップ
このプロジェクトでは、関連性の高い提案を生成するうえで最近のアクションが重要な役割を果たしており、ユーザーの関心や行動に合わせたウェブ コンテンツのレコメンデーションにおいて、Vertex AI のエンベディングベースのモデルを使用する価値が実証されています。エンベディング モデルをチューニングすることで、NDCG スコアの大幅な改善が見られ、この方法の有効性が示されました。ただし、改善したものの、エキスパートによる手作業でのラベル付けと評価を統合して、レコメンデーションの精度を高めてユーザーのニーズに応えるなど、さらなる改良の余地はあります。今後の取り組みでは、人間による分析とアルゴリズムの精度を組み合わせて、動的なデジタル環境でレコメンデーション システムを改善することに重点を置いていきます。
エンベディングと Vertex AI の詳細については、以下のドキュメントをご覧になり、その機能をお試しください。
-PLAID、データ サイエンス エンジニア 近藤 周平氏
-Google Cloud Japan、AI コンサルタント 葛木 美紀


