BigQuery で Vertex AI モデルを使って、SQL のみで LLM のテキスト生成を実行する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 8 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
多くのコードを記述せず、データを移行することなく、SQL クエリだけで簡単な生成 AI を実行できたらいいと思いませんか?しかも、セキュリティやプライバシー、コンプライアンスの問題を心配することなく。BQML(BigQuery ML)なら、Vertex AI の大規模言語モデル(LLM)を使って、BigQuery に格納されているデータを対象に分析を実行できます。これはつまり、BigQuery から連携クエリを使いクエリ可能な Cloud SQL や Spanner などのデータベースに格納されているデータに対しても LLM ベースの分析を実行でき、CSV ファイルや他の外部データソースのデータに対しても SQL のみで LLM 分析を行えるということです。
このブログ投稿では、GitHub リポジトリに含まれるソースコードの要約を生成し、そのプログラミング言語を識別する手順を紹介します。そのために、BigQuery でホストされるリモート関数として Vertex AI の大規模言語モデルを使用し、テキストを生成します(text-bison)。なお、GitHub Archive プロジェクトのおかげで、Google BigQuery 一般公開データセットに含まれるオープンソースの GitHub リポジトリの数はいまや、完全スナップショットで 280 万件以上にのぼります。
1. まず、Google Cloud プロジェクトを作成し、課金と Cloud Shell を有効にし、必要な API(BigQuery API、Vertex AI API、BigQuery Connection API)を有効にします。
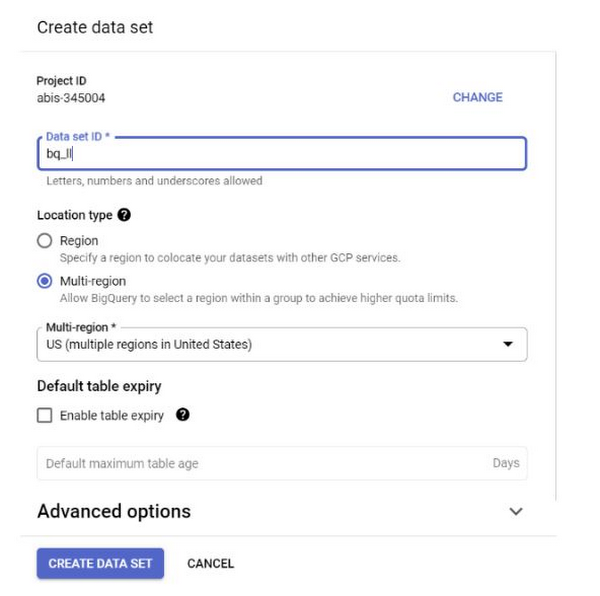
2. 「US」リージョン(またはご希望のリージョン)で BigQuery データセットを作成して、bq_llm という名前を付けます。
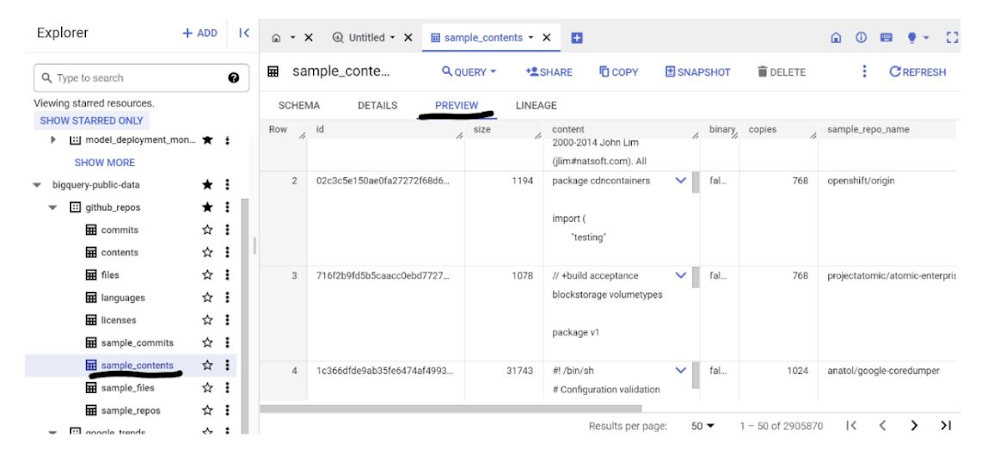
3. このユースケースでは、Google BigQuery 一般公開データセットから、github_repos データセットのソースコード コンテンツを使用します。これを使用するには、BigQuery コンソールで「github_repos」を検索して、Enter キーを押します。検索結果として表示されたデータセットの横にあるスターをクリックします。続けて、[スター付きのみを表示] をクリックして、一般公開データセットのみを表示します。

データセットのテーブルを開いて、スキーマとデータ プレビューを表示します。ここでは、contents テーブルに含まれる全データのサンプル(10%)のみを含む sample_contents を使用します。データのプレビューは次のとおりです。
4. CSV など任意の形式で保存してある独自データセットに対して同様の操作をしたい場合は、Cloud Shell ターミナルで以下のコマンドを実行して、対象のデータを BigQuery テーブルに読み込みます。
bq load --source_format=CSV --skip_leading_rows=1 bq_llm.table_to_hold_your_data \
./your_file.csv \ text:string,label:string
5. 外部接続を作成し(BigQuery Connection API がまだ有効になっていない場合は有効にします)、接続の構成情報を参照してサービス アカウント ID を書き留めます。
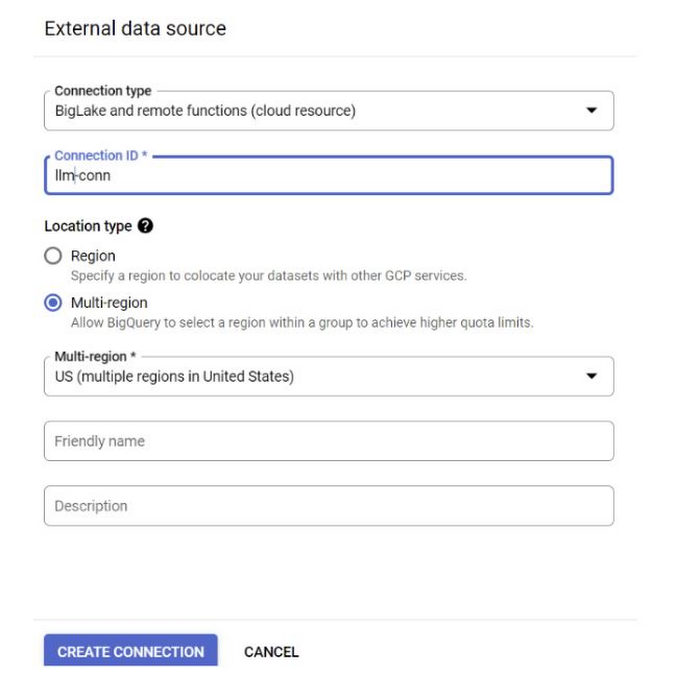
a. BigQuery コンソールの左側の [エクスプローラ] ペインで [+ 追加] ボタンをクリックし、表示された一般的なソースの中から、[外部データソースへの接続] をクリックします。
b. 接続タイプとして [BigLake とリモート関数] を選択し、[接続 ID] に「llm-conn」と指定します。
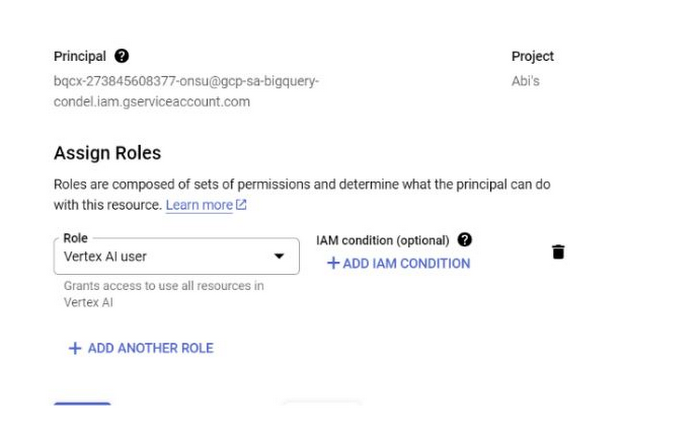
c. 接続を作成したら、接続の構成情報を参照して、生成されたサービス アカウントを書き留めます。
6. サービス アカウントに Vertex AI サービスへのアクセス権を付与するため、IAM を開き、コピーしたサービス アカウントをプリンシパルとして追加して、[Vertex AI ユーザー] ロールを選択します。
7. ホストされる Vertex AI 大規模言語モデルに相当するリモートモデルを作成します。
完了までに数秒かかることがあります。
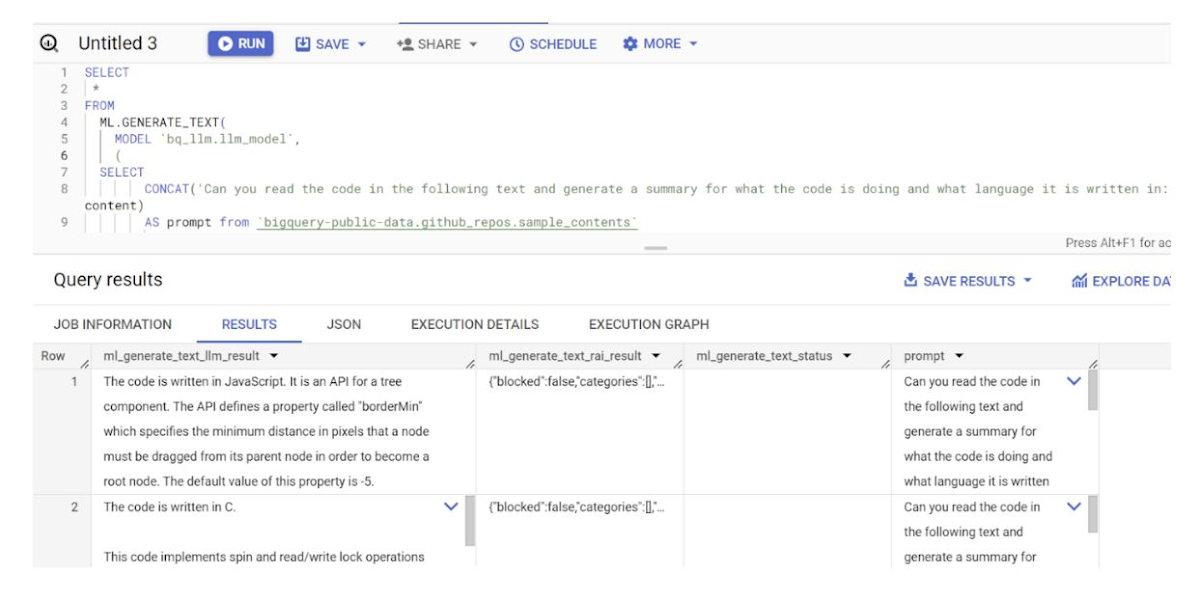
8. モデルの作成が完了したら、そのモデルを使ってテキストを生成、分類します。
説明:
ml_generate_text_result は、テキスト生成モデルから返される JSON 形式のレスポンスで、コンテンツ(content)と安全性属性(safetyAttributes)の両方が含まれます。
a. content は、生成されたテキストの結果を表します。
b. safetyAttributes は、調整可能なしきい値を持つ Vertex AI PaLM API に付属のコンテンツ フィルタを表します。このフィルタを使って、大規模言語モデルからの想定外の予期せぬレスポンスを除外することができます。具体的には、安全性のしきい値に収まらないレスポンスはブロックされます。
ML.GENERATE_TEXT は、BigQuery 内で使用する構造で、Vertex AI LLM にアクセスしてテキスト生成処理を実行します。
CONCAT は、PROMPT 文とデータベース レコードを連結します。
github_repos は、データセット名です。sample_contents は、このプロンプト設計で使用するデータを含むテーブルの名前です。
temperature は、レスポンスのランダム性を制御するプロンプト パラメータです。この値が小さいほど、関連度が高くなります。
max_output_tokens は、レスポンスに含める単語の数です。
クエリのレスポンスは以下のようになります。
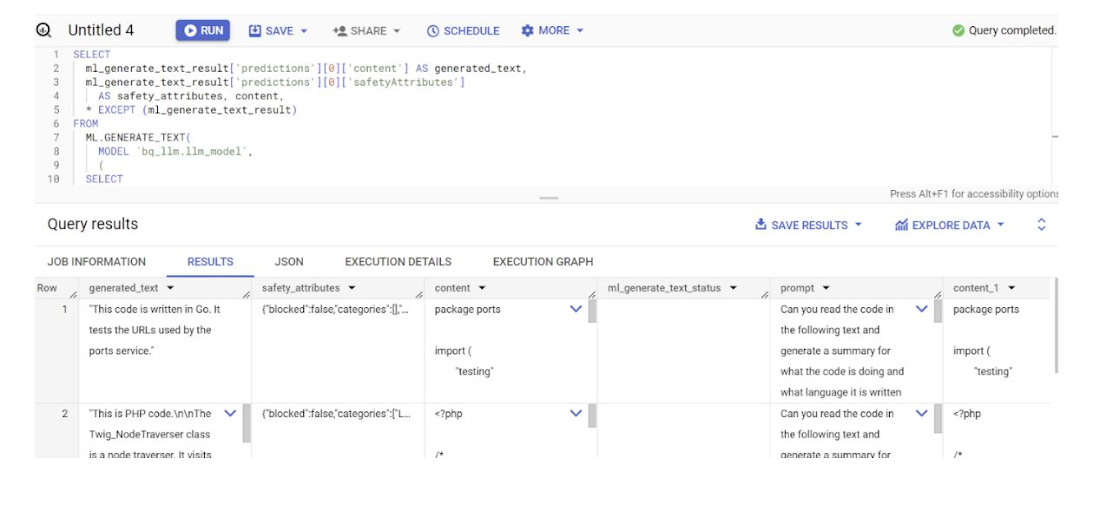
9. 結果を平坦化し、クエリ内で JSON を明示的にデコードせずに済ませるには、以下のように記述します。
結果:
flatten_json_output はブール値で、true に設定すると、JSON のレスポンスから平坦でわかりやすいテキストが抽出されて返されます。
これで完了です。プログラムで Vertex AI テキスト生成 LLM を使用して、SQL クエリのみを使って、独自データに対してテキスト分析を実行することができました。使用可能なモデルの詳細については、Vertex AI LLM プロダクトのドキュメントをご覧ください。ここで紹介した例をご自分で実際に試してみるには、Codelab をご覧ください。
- Google、デベロッパー アドボケイト Abirami Sukumaran



