自動運転の実現に求められる、大規模な ML ワークフローを Dataflow ML で実行する方法
Google Cloud Japan Team
※この投稿は米国時間 2022 年 11 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
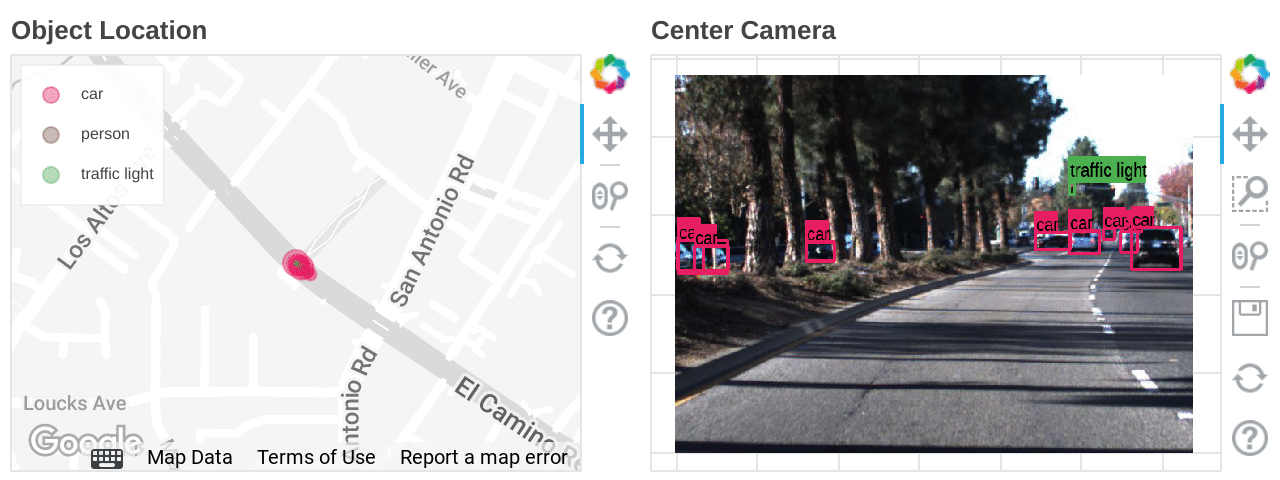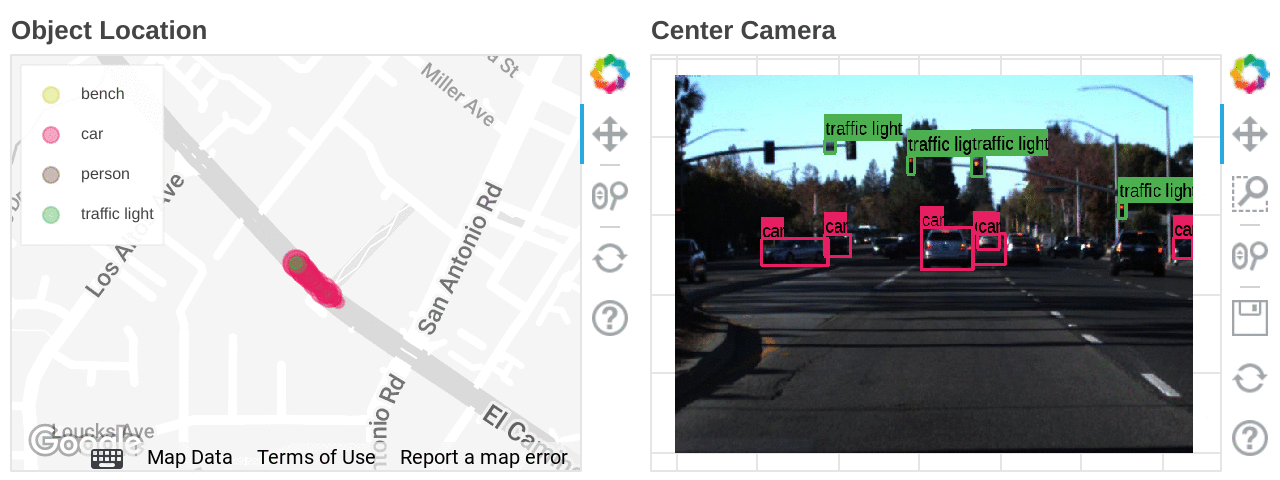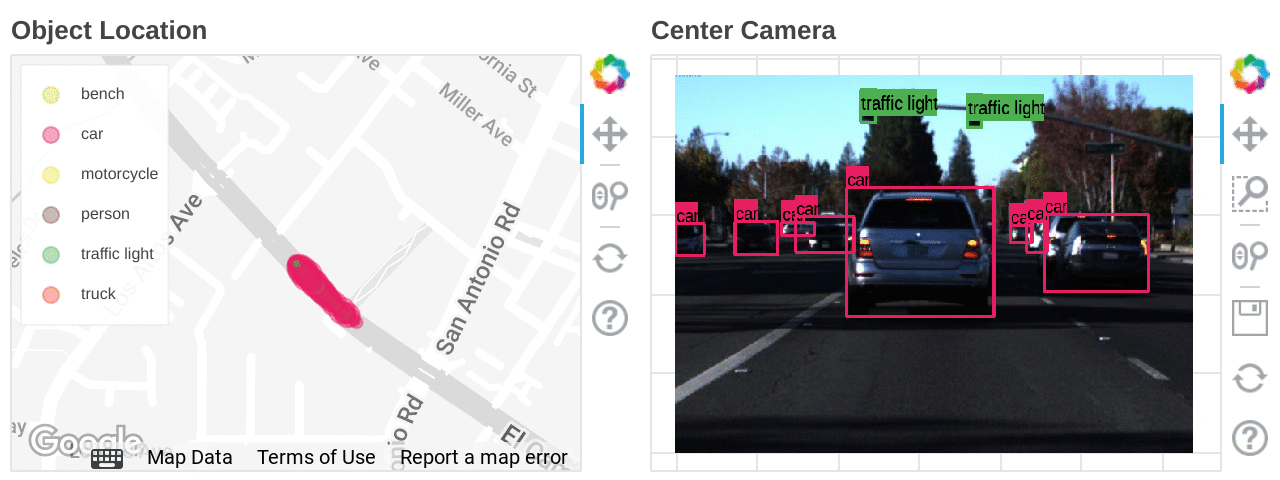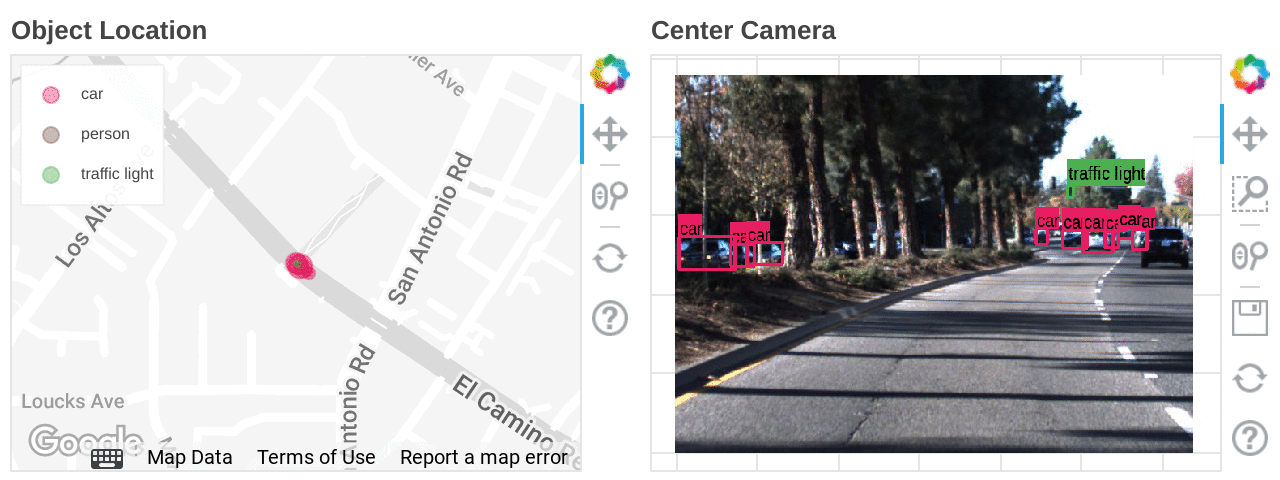
自動運転技術の開発は、量とデータ形式、どちらの観点から見てもデータとの闘いと言えるでしょう。そのデータには、LIDAR から取得したポイント クラウド 3D データ、複数のカメラから取得した動画データ、GPS の位置情報、ミリ波レーダー、ステアリング、各種センサー情報が含まれます。しかし忙しい都会といえども、役立つ情報が含まれているのは元データの 1% 未満であるため、情報をフィルタリングして解釈し、それらを組み合わせて一貫した方法で使用するには、かなりの労力が必要となります。こうしたデータ クレンジング作業をすべて回避する方法の一つとして、3D 仮想空間でのシミュレーションの実行が挙げられます。これにより、データを生成して多くのパターンを大規模に検証できますが 、実世界での動きと照らし合わせるためには、今後も実走行から得られる元データが不可欠です。しかし、このようなデータの調査は容易ではありません。エンジニアにとって、データを徹底的に精査し、対象となる特定の場面を切り出すというのは大きな課題です。信号が青で、一定数の歩行者がいる場面を探し出そうとしているところを想像してみてください。まるで、山積みの DVD の中から特定のミーム 1 つを見つけ出すようなものです。
このブログでは、自動運転開発において、画像のデータセットを使って対象の場面を探し出すために Dataflow ML をどのように活用できるかについて説明します。
Dataflow ML とは
Google Cloud Dataflow は、フルマネージド データ処理サービスであり、ユーザーは大規模なデータに対するバッチやストリーミング パイプラインを、費用対効果の高い、高速かつスケーラブルな方法で実行できます。開発者は、このような大規模なデータ処理の動きを簡素化するオープンソースの統合型プログラミング モデルの Apache Beam を使用して、パイプラインを記述できます。パイプラインは汎用的な変換で表され、ソースやシンクからの読み取りと書き込みに加え、マッピング、ウィンドウ処理、グループ化といったデータ操作など、さまざまな操作を実行できます。
Dataflow ML のリリースブログで説明したように、人工知能や機械学習機能を運用化にする企業が増えています。私たちはすべての開発者に ML / AI のユースケースを拡大したいと考え、その結果、RunInference という新しい Beam 変換を開発しました。
RunInference を使用すると、開発者は本番環境パイプラインで使用できる事前トレーニング済みモデルをプラグインできます。この API は、Beam のコア プリミティブを使ってモデルの使用を本番環境に対応させる作業を行うため、ユーザーはモデルのトレーニングや特徴量エンジニアリングなどのモデルの研究開発に集中できます。GPU のサポートなどの Dataflow の既存機能と組み合わせることで、ユーザーは前処理と後処理を実行する複雑なワークフロー グラフを自由に作成したり、マルチモデル パイプラインを構築したりできます。
メタデータを抽出するためのシンプルな ML パイプラインの構築
では、自動運転に必要な大量のデータを処理するために、Dataflow ML パイプラインを実行してみましょう。このワークフローを再現したい場合は、こちらのデモコードを使用してください。オープンソースのデータセットを使用しているため、大量のデータを扱うことはありません。Dataflow はデータ量に応じて(具体的にはスループットにより)自動的にスケールするので、データが 10 倍または 1,000 倍に増えてもパイプラインの変更は不要です。また、Dataflow はバッチジョブとストリーミング ジョブの両方をサポートしています。このデモでは、バッチジョブを実行して、保存された画像を処理します。では、走行中の車両からアップロードされる各画像をほぼリアルタイムで処理したい場合は、どうすればよいでしょうか。Pub/Sub などの最初の変換を変更することで、パイプラインをバッチからストリーミングに簡単に変換できます。
パイプラインの形状は、以下の画像のようになります。まず、BigQuery から画像のパスを読み込み、Google Cloud Storage からその画像を読み込んで、各画像に対して推論を行ってから、その結果を BigQuery に保存します。
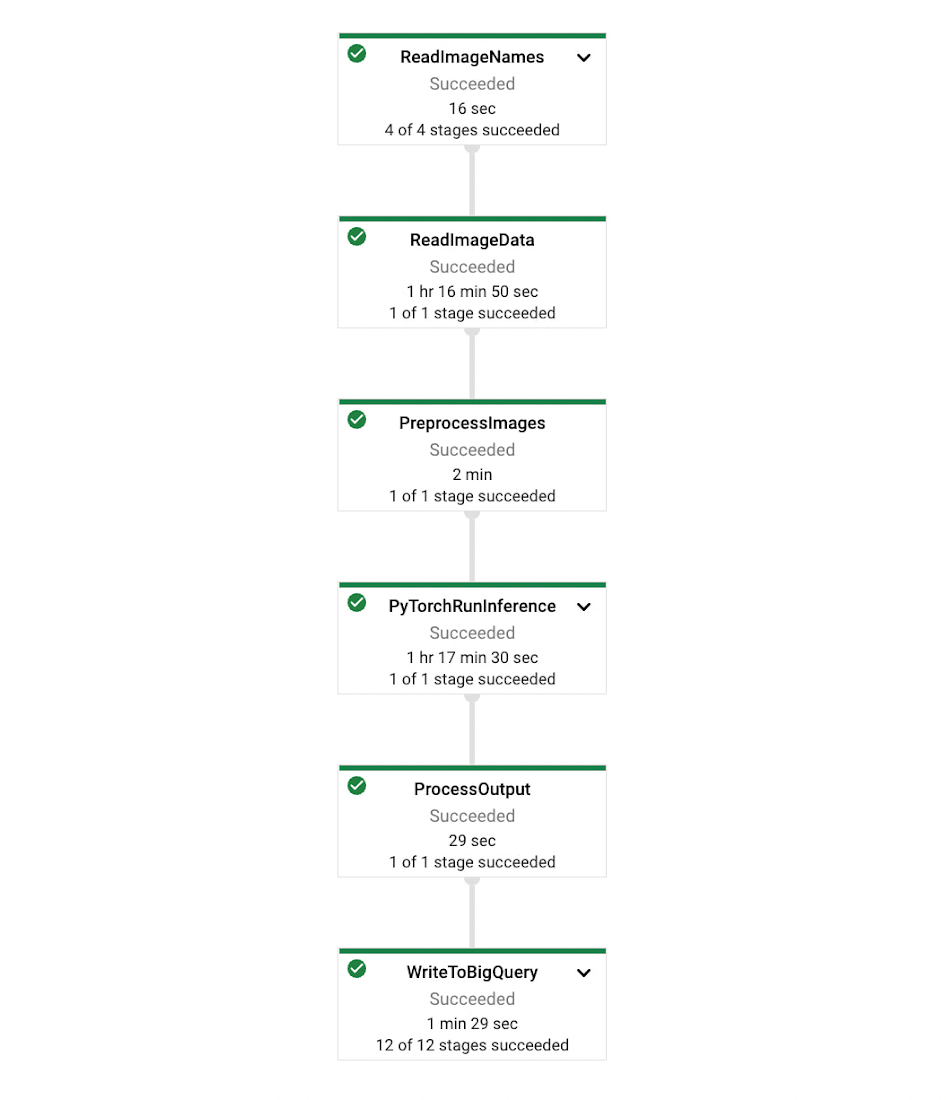
Dataflow では、パイプラインにおいて Java、Python、または両方の組み合わせ(Beam の言語間変換を使用)を選択できます。デモコードは、最初にイメージをビルドし、次にそれを Dataflow 環境にデプロイします。この方法は複雑に見えるかもしれませんが、実行環境の違いをなくすために重要です。
ML ワークロードを容易に処理
RunInference を使用
RunInference を使用した Beam パイプラインの記述は、以下のようになります。
データは、Beam の I/O 変換のいずれかを使用してソースから読み取られます。そのデータは次に RunInference 変換に渡され、ここで ModelHandler オブジェクトがパラメータとして取り込まれます。この ModelHandler オブジェクトは、使用される基盤となるモデルをラップするものです。
インポートする ModelHandler は、フレームワークと、入力を含むデータ構造の種類によって異なります。たとえば、Scikit-learn モデルを使用していて、入力データが numpy 配列であれば、SklearnModelHandlerNumpy を使う必要があります。PyTorch テンソルの場合は、PytorchModelHandlerTensor を使用してください。
ModelHandler では、Scikit-learn に対しては pickle 化モデルへのパス、PyTorch モデルに対してはモデルの重みとして知られる state_dict など、他にもいくつかのパラメータを必要とする場合があります。詳しくは、事前トレーニング済みモデルの読み込み方法のドキュメントをご確認ください。
RunInference でのバッチ処理
このデモ パイプラインのコードが示すように、ModelHandler の batch_elements_kwargs 関数を設定しました。これにはどのような意味があるでしょう。RunInference では、BatchElements 変換による動的バッチ処理が行われ、ダウンストリームのオペレーションにかかる時間をプロファイリングすることで、平均化された処理の要素をバッチ処理します。ただし、API は異なる形の要素をバッチ処理できないため、変換に渡されるサンプルは同じディメンションまたは長さでなければなりません。
バッチサイズは、実行時に 1〜10,000 のデフォルトの範囲で調整される場合があります。ModelHandler の batch_elements_kwargs 関数をオーバーライドして、バッチの最大サイズ(max_batch_size)と最小サイズ(min_batch_size)を必要な値に設定することで、バッチ処理の動作を変更できます。
RunInference でのバッチ処理について詳しくは、テンソル要素のバッチ処理ができない場合のトラブルシューティングについて説明したセクションをご覧ください。batch_elements_kwargs をオーバーライドする別の例については、言語モデリングの例をご参照ください。
次のステップ
ここでは、特定の条件下で画像を検索するために、Dataflow ML でオブジェクト検出モデルを実行しました。オブジェクト検出は、モデルが学習したクラスしか検出できないため、より柔軟に場面を探索したい場合は、特徴抽出モデルを使用して Vertex AI Matching Engine のインデックスを作成します。Vertex AI Matching Engine は、50 パーセンタイルのレイテインシ(最低 5 ミリ秒)で同様の特徴を持つデータを検索できます。
また、データセットに緯度と経度の情報が含まれている場合、BigQuery GIS と、Looker などの BI ツールを組み合わせて、データ分析を加速させることも可能です。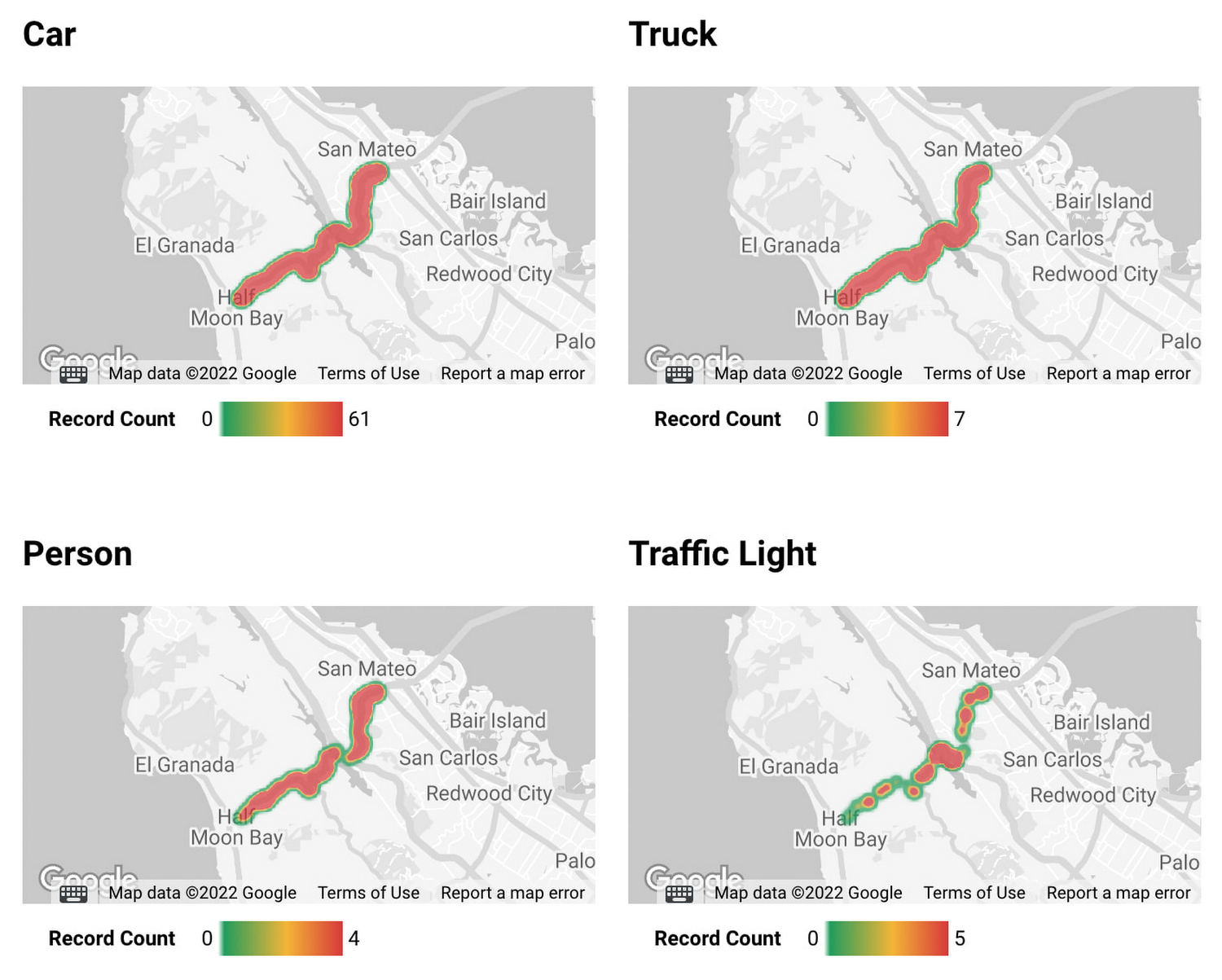
Dataflow についての詳細は、以下のリンクよりご覧ください。
追加資料
Apache Beam のウェブサイトで、RunInference Beam 変換について詳しくご紹介しています。
Beam Summit 2022 での RunInference の解説については、こちらの動画をご覧ください。
パイプラインで TensorFlow モデルを使用する方法については、こちらのブログ投稿をご覧ください。
RunInference を使用してオブジェクト検出や言語モデリングなどのタスクを実行するパイプラインの例をご覧ください。
- Dataflow ML ソフトウェア エンジニア Andy Ye
- 自動車業界担当カスタマー エンジニア Hayato Yoshikawa




