How to run a large scale ML workflow on Dataflow ML for autonomous driving
Andy Ye
Software Engineer, Dataflow ML
Hayato Yoshikawa
Customer Engineer, Automotive
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialDeveloping autonomous driving technology is a battle with data, both from a volume and data format point of view. Sources include point cloud 3D data obtained from LIDAR, video data obtained from multiple cameras, GPS position information, millimeter-wave radar, steering and various sensor information. Even in a busy city, less than 1% of the raw data contains useful information, so substantial effort needs to be put into filtering, interpreting, and combining the information to be used in a coherent manner. One way to avoid all this data cleansing effort is to run simulations in 3D virtual space, which can generate this data to verify many patterns at scale, but raw data obtained from actual driving will continue to be essential to test against real-world behavior. Exploring this data is not easy; it is a huge challenge for engineers to comb through data and isolate specific scenes of interest. Imagine trying to find a scene with green traffic lights and a specific number of pedestrians. It's like finding a particular meme in a pile of DVDs.
In this blog, we will walk through how Dataflow ML can be used in autonomous driving development to find a scene of interest using a data set of images.
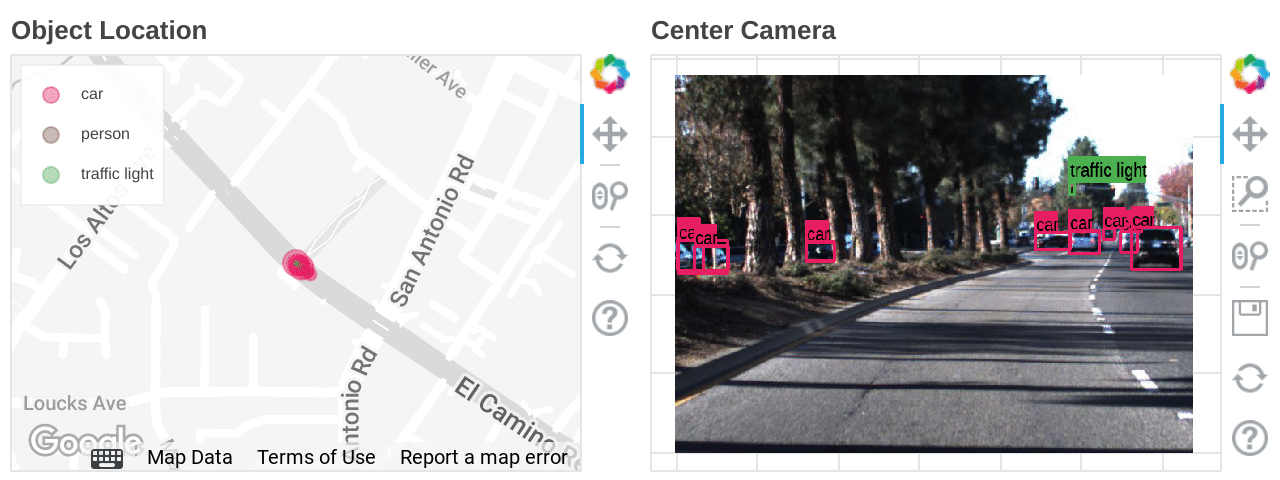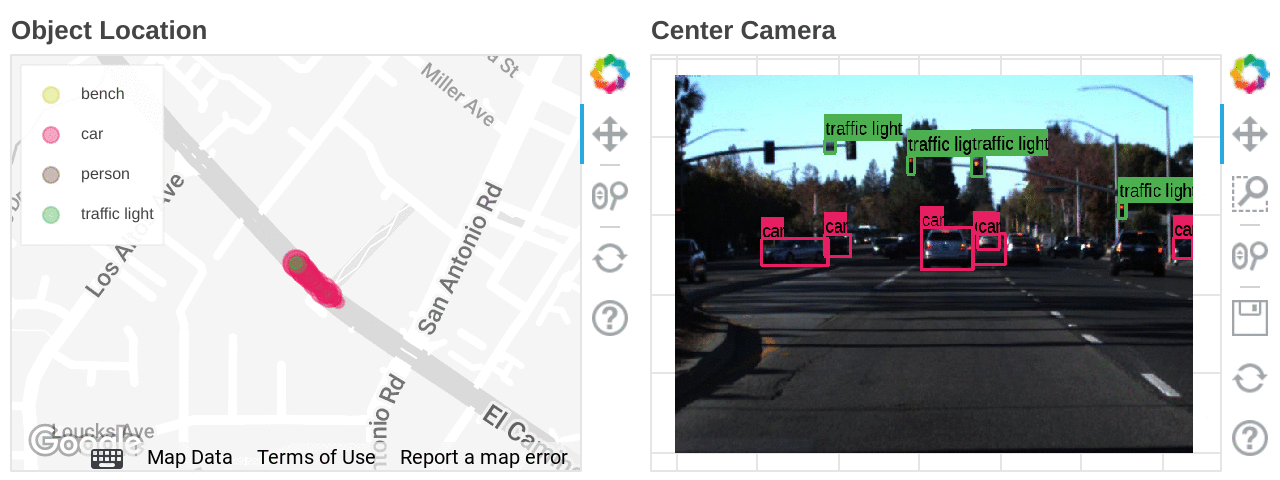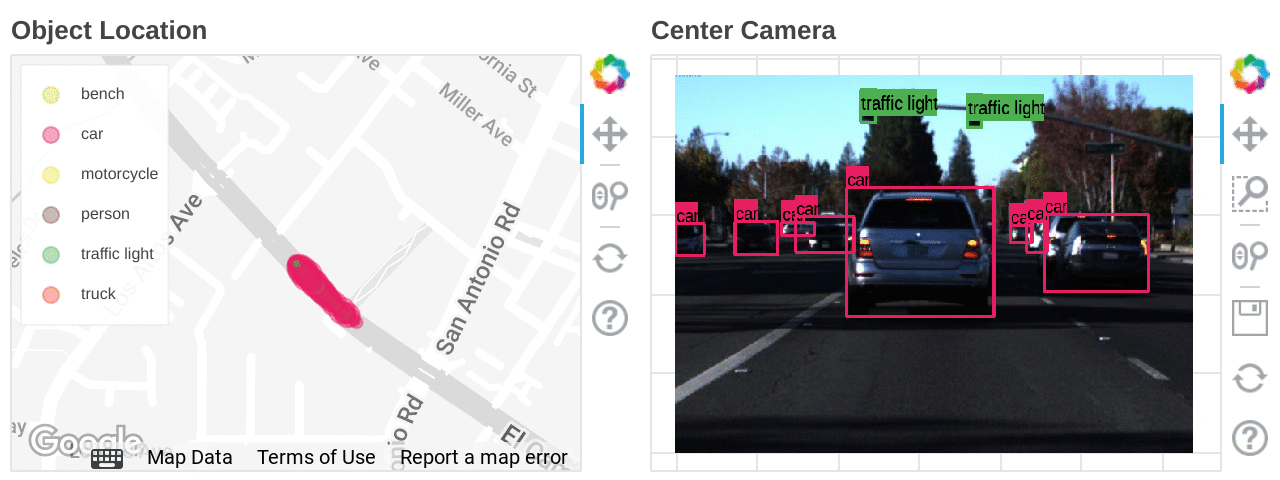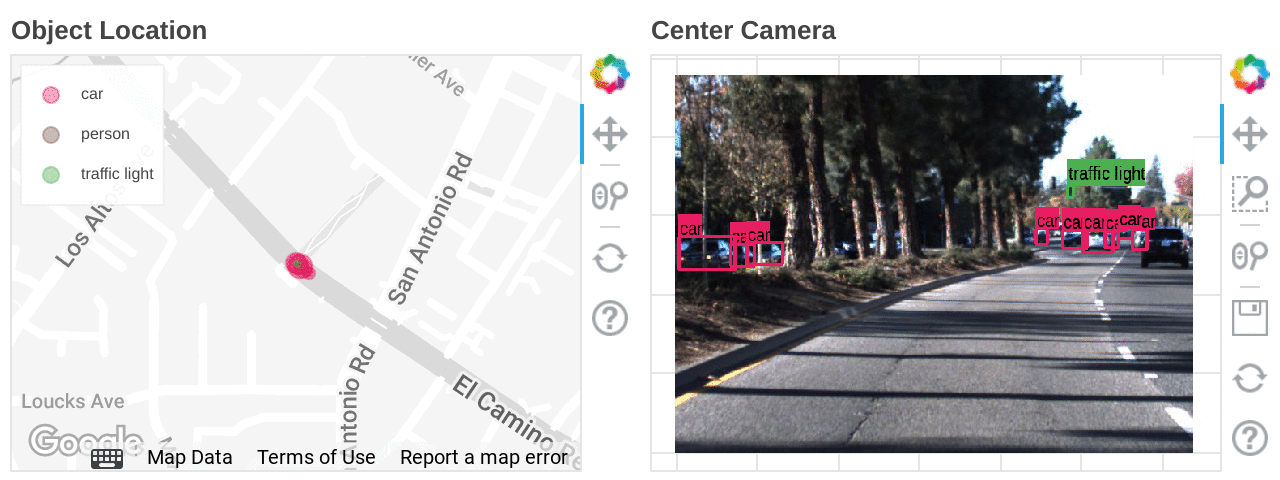
What is Dataflow ML?
Google Cloud Dataflow is a fully managed data processing service that lets users run batch and streaming pipelines on large-scale data in a fast, scalable, and cost-effective manner. Developers can write their pipelines using Apache Beam, which is an open-source, unified programming model that simplifies these large-scale data processing dynamics. Pipelines are expressed with generic transforms that can perform a wide array of operations such as reading and writing from sources and sinks, as well as performing data manipulations such as mapping, windowing, and grouping.
As mentioned in the launch blog for Dataflow ML, we are seeing more enterprises shift to operationalize their artificial intelligence and machine learning capabilities. We wanted to expand use cases of ML/AI for all developers, and as a result, developed a new Beam transform called RunInference.
RunInference lets developers plug in pre-trained models that can be used in production pipelines. The API makes use of core Beam primitives to do the work of productionizing the use of the model, allowing the user to concentrate on model R&D such as modeling training or feature engineering. Coupled with Dataflow’s existing capabilities such as GPU support, users are able to create arbitrarily complex workflow graphs to do pre- and post-processing and build multi-model pipelines.
Building a simple ML pipeline to extract metadata
Now let’s run a Dataflow ML pipeline to process large amounts of data for autonomous driving. If you want to recreate this workflow, please follow the demo code here. As we are using an open-source dataset, we won’t be working with a large data volume. Dataflow automatically scales with your data volume (more specifically, by throughput), so you will not need to modify your pipeline as the data grows 10x or even 1,000x. Dataflow also supports both batch and streaming jobs. In this demo we run a batch job to process saved images. What if we want to process each image uploaded from running vehicles in near real-time? It is easy to convert the pipeline from batch to streaming, by modifying the first transform such as Pub/Sub.
The pipeline shape is shown in the image below. First, it reads the image path from BigQuery, reads the images from Google Cloud Storage, does inference for each image, and then saves the results to BigQuery.
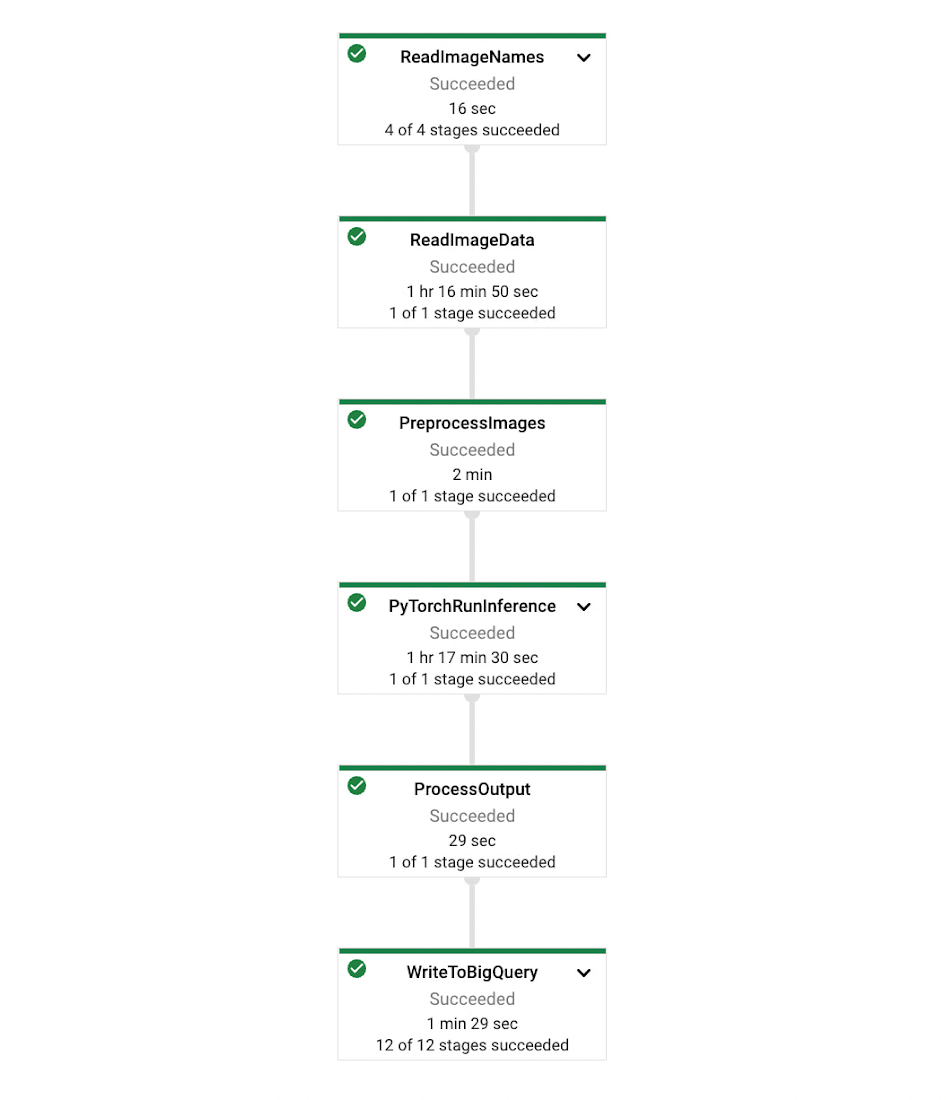
In Dataflow, you can select Java, Python, or even a combination of both (using Beam’s cross-language transforms) in your pipeline. The demo code first builds an image and then deploys it to the Dataflow environment. This approach might seem convoluted, but it is important for eliminating differences between the execution environments.
Handling ML workloads easily
Using RunInference
Writing a Beam pipeline using RunInference looks like this:
Data is read from a source using one of Beam’s I/O transforms. That data is then passed to the RunInference transform, which takes in a ModelHandler object as a parameter. This ModelHandler object is what wraps the underlying model being used.
The ModelHandler you import depends on the framework and type of data structure that contains the inputs. For example, if you’re using a Scikit-learn model, and your input data is a numpy array, you should use SklearnModelHandlerNumpy. For PyTorch tensors, you should use PytorchModelHandlerTensor.
ModelHandlers might require a few other parameters such as the path to the pickled model for Scikit-learn, or the state_dict, also known as model weights, to your PyTorch model. For more information, see the documentation on how to load pretrained models.
Batching in RunInference
As seen in the code of this demo pipeline, we configured the ModelHandler’s batch_elements_kwargs function. Why did we do this? RunInference uses dynamic batching via the BatchElements transform, which batches elements for amortized processing by profiling the time taken by downstream operations. The API, however, cannot batch elements of different shapes, so samples passed to the transform must be of the same dimension or length.

The batch size might adjust during runtime with a default range from 1 to 10,000. You can change the batching behavior by overriding the batch_elements_kwargs function in your ModelHandler and setting the largest size of a batch (max_batch_size) and the smallest size of a batch (min_batch_size) to your required values:
For more information about batching in RunInference, see the Unable to batch tensor elements troubleshooting section. For another example of overriding batch_elements_kwargs, see the language modeling example.
What’s Next
We ran an object detection model in Dataflow ML to search for images under specific conditions. Object detection can only detect classes that the model has learned, so if you want even more flexibility in exploring the scene, you can use the feature extraction model to create indexes for the Vertex AI Matching Engine. Vertex AI Matching Engine can search data with similar features with latency as low as 5ms in the 50th percentile.
Also, if latitude and longitude information is included in the dataset, you can accelerate data analysis by combining BigQuery GIS and BI tools such as Looker.
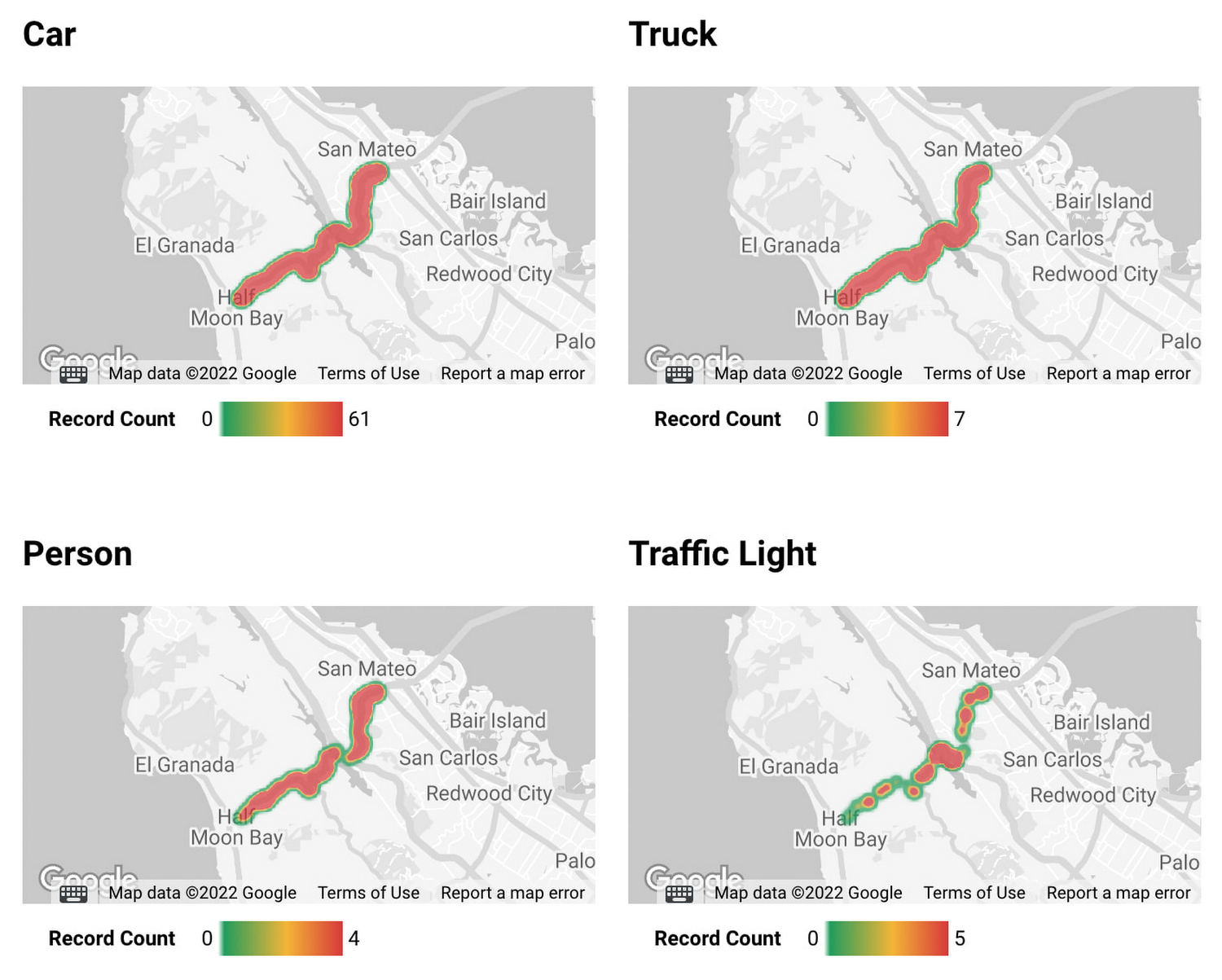
To learn more about Dataflow, please follow the links below.
Additional readings
Read more about the RunInference Beam transform on the Apache Beam website.
Watch this talk about RunInference at Beam Summit 2022.
Read this blog post on how to use TensorFlow models in a pipeline.
- Read the example pipelines using RunInference that do tasks such as object detection and language modeling.




