Dataflow で ML モデルを本番環境パイプラインに組み込む

Google Cloud Japan Team
※この投稿は米国時間 2022 年 9 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
最近、Google Cloud の Dataflow において、Apache Beam の汎用的な機械学習予測および推論変換である RunInference のサポートが一般提供になったことが発表されました。このブログでは、この変換について詳しく説明します。取り上げる内容は次のとおりです。
単純なモデルを例として、バッチモードとストリーミング モードでの RunInference 変換の使い方を示す。
複数のモデルのアンサンブルで RunInference 変換を使用する。
Torchvision に付属するオープンソース モデルを利用したエンドツーエンドのパイプラインの例を提供する。
これまで、Apache Beam デベロッパーが本番環境パイプラインで機械学習モデルをローカルで利用する場合は、ユーザー定義関数(DoFn)内でモデルの呼び出しをハンドコードする必要があり、ボイラープレート コードのレイヤを自分で記述しなければならないという技術的負担を負っていました。具合的にどうする必要があったかを見ていきましょう。
フレームワークの load メソッドを使用して、共通のロケーションからモデルを読み込みます。
モデルが DoFn の間で共有されていることを手動で確認するか、または Beam の shared クラス ユーティリティを使用して確認します。
モデル効率を向上させるため、モデルを呼び出す前にデータをバッチにまとめます。これは手動で行うか、バッチへのグループ化ユーティリティの一つを使用して行います。
変換から指標のセットを提供します。
本番環境グレードのロギングおよび例外処理と(午前 2 時に働いている SRE にも理解できるような)明快なメッセージを提供します。
特定のパラメータをモデルに渡します。または、構成からモデル内の情報を特定できる汎用的な変換の構築を開始します。
そしてもちろん、今日の企業は多くのモデルをデプロイする必要があるので、データ エンジニアは自分のなすべきことを開始し、モデルを抽象化します。基本的に、各企業はそれぞれ独自に RunInference 変換を構築します。
これらすべての作業は大部分がすべてのモデルに共通するボイラープレートであることから、RunInference API が作成されました。この API は tfx_bsl.RunInference 変換から着想されました。この TensorFlow Extended の優れたフォークは、まさに上記の問題を解決するために作成されました。tfx_bsl.RunInference は、TensorFlow モデルを中心に構築されています。本稿で紹介する新しい Apache Beam RunInference 変換は、フレームワークに依存せず、Beam パイプライン上で簡単に組み立てられるように設計されています。
RunInference のシグネチャは、RunInference(model_handler) の形式をとります。この model_handler 構成オブジェクトで、フレームワークに固有の構成と実装を記述します。
これには、デベロッパー エクスペリエンスが明快になり、本番環境の機械学習パイプライン内で新しいフレームワークを簡単にサポートできるという利点があります。デベロッパー ワークフローが阻害されることもありません。たとえば、Apache Beam プロジェクトに参加している NVIDIA は、NVIDIA TensorRTTM を統合しています。この SDK を使用すると、Google Dataflow 内にデプロイするトレーニング済みモデルを、NVIDIA GPU 上でのスループットが最大かつレイテンシが最小になるように最適化できます(プルリクエスト)。
また、Beam Inference を使用すると、デベロッパーは Apache Beam のパイプライン モデルが持つ柔軟性をフルに活用し、複雑なマルチモデル パイプラインを最小限の労力で簡単に構築できます。マルチモデル パイプラインは、A/B テストの実施やアンサンブルの構築のような作業に役立ちます。たとえば、テキストの自然言語処理(NLP)分析を行い、その結果をドメイン固有モデル内で使用して顧客におすすめを提案できます。
次のセクションでは、ノートブック形式の一般公開されている Codelabから抜粋したコードを使用して、実際の API を見ていきます。このコードは github.com/apache/beam/examples/notebooks/beam-ml から入手することもできます。
Beam Inference API の使用
API の詳しい説明に入る前に、Apache Beam に馴染みがない方のために、CSV ファイルからデータを読み取る小さなパイプラインを組み立ててみましょう。これは構文について知るためのウォーミングアップです。
このパイプラインでは、ReadFromText ソースを使用して CSV ファイルから Parallel Collection(Apache Beam では PCollection と呼ばれます)にデータを取り込んでいます。Apache Beam の構文では、パイプ演算子(|)は実質的に「適用」を意味します。つまり、最初の行は ReadFromText 変換を適用しています。次の行では、beam.Map() を使用してデータの要素単位の処理を実行しています。この例では、データは print 関数に送られます。
次に、非常に単純なモデルを利用して、RunInference を異なるフレームワークに対してどのように構成できるかを示します。使用するモデルは単一レイヤの線形回帰で、すでに y = 5x のデータでトレーニングされています(つまり、九九の 5 の段を学習済みです)。このモデルを構築するには、この Codelab の手順に従ってください。
RunInference 変換のシグネチャは RunInference(ModelHandler) です。ModelHandler は、モデルに関する詳細を RunInference に伝え、出力の型情報を提供する構成オブジェクトです。Codelab では、PyTorch 保存モデルファイルの名前は「five_times_table_torch.pt」で、このファイルにモデルの state_dict 上の torch.save() の呼び出し結果が出力されます。RunInference に渡すこのモデル用の ModelHandler を作成するには、次のようにします。
model_class は、モデル アーキテクチャを torch.nn.Module のサブクラスとして定義する PyTorch モデルのクラスです。model_params は、model_class のコンストラクタによって定義されているパラメータです。この例では、これらのパラメータはノートブック LinearRegression クラス定義で次のように使用されています。
使用する ModelHandler により、モデルへの入力型に関する変換情報も決まります。PytorchModelHandlerTensor は torch.Tensor 要素を受け入れます。
この構成を利用するため、先ほど作成したパイプラインをこの構成で更新します。さらに、取得したデータを、作成済みモデルにとって適切なシェイプと型に格納するために必要な前処理も行います。このモデルはシェイプ [-1,1] の torch.Tensor を受け入れますが、CSV ファイルのデータは 20,30,40 のような形式になっています。
このパイプラインは、CSV ファイルを読み取り、取得したデータをモデルのシェイプに格納して、推論を実行します。print ステートメントの結果は次のようになります。
PredictionResult オブジェクトには、例と結果の両方が含まれます。上記の例では、入力 20 に対する結果が 100.0047 です。
次に、単一のパイプライン内で複数の RunInference 変換を組み立てることにより、少ないコード行で複雑なアンサンブルを構築する方法を見ていきます。その後、TorchVision で実際のモデルの例を示します。
マルチモデル パイプライン
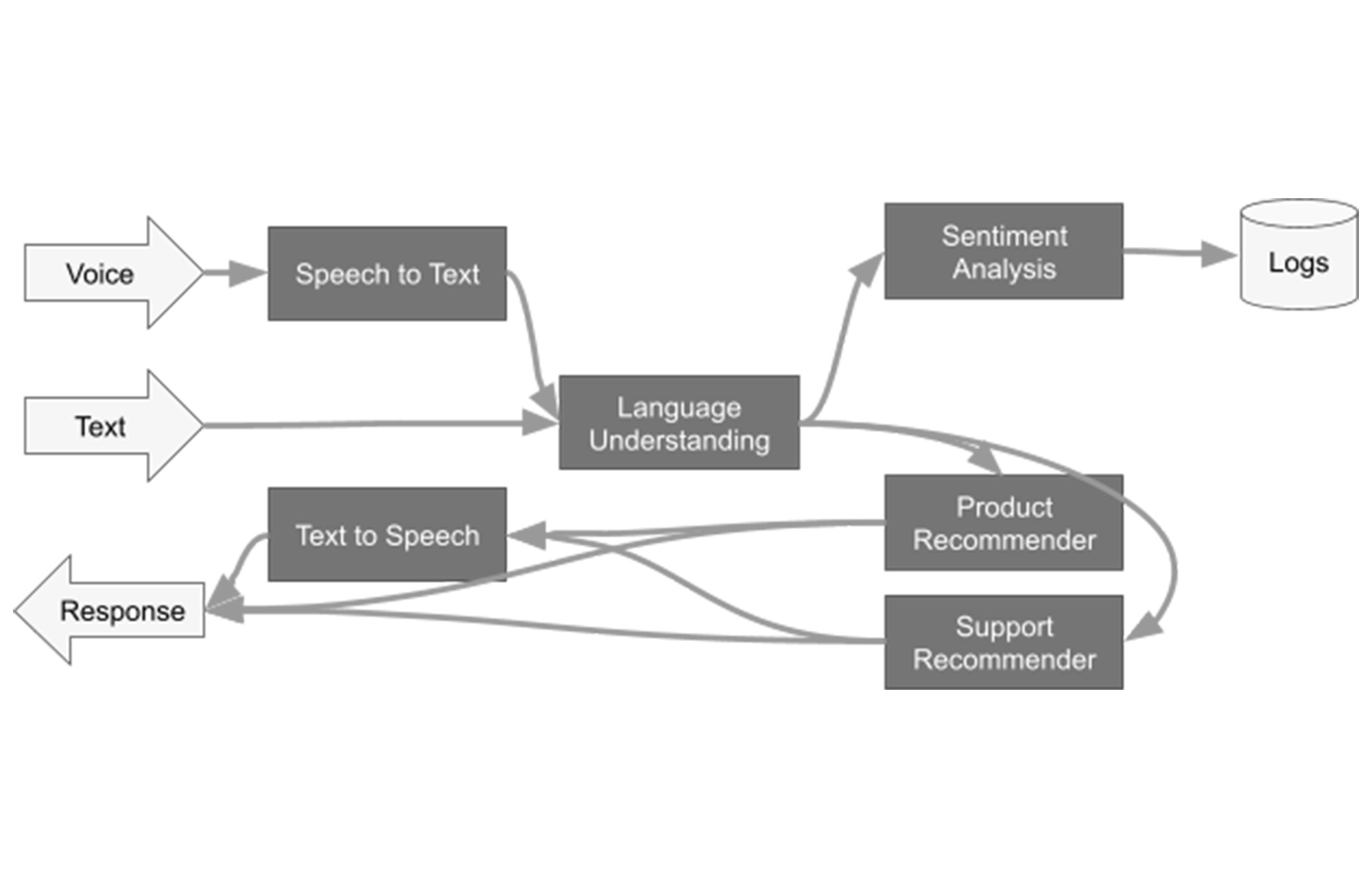
前の例では、1 つのモデル、ソース、出力を使用しました。そのパターンは多くのパイプラインで使用されます。ただし、モデルのアンサンブルも必要になります。そこでは、データの前処理やドメイン固有のタスクにモデルが使用されます。たとえば、NLP モデルに渡す前に音声をテキストに変換します。上の図は流れが複雑ですが、実際には、主要なパターンは次の 3 つだけです。
1- データがグラフの下流に流れる。
2- あるステージ(たとえば、「Language Understanding」)の後にデータが分岐する。
3- あるモデルから別のモデルにデータが流れる。
項目 1 は非巡回なので、単一の Beam パイプラインにするのが適しています。項目 2 と 3 のコードは Beam SDK で簡潔に表現できます。これらについて見てみましょう。
分岐パターン:
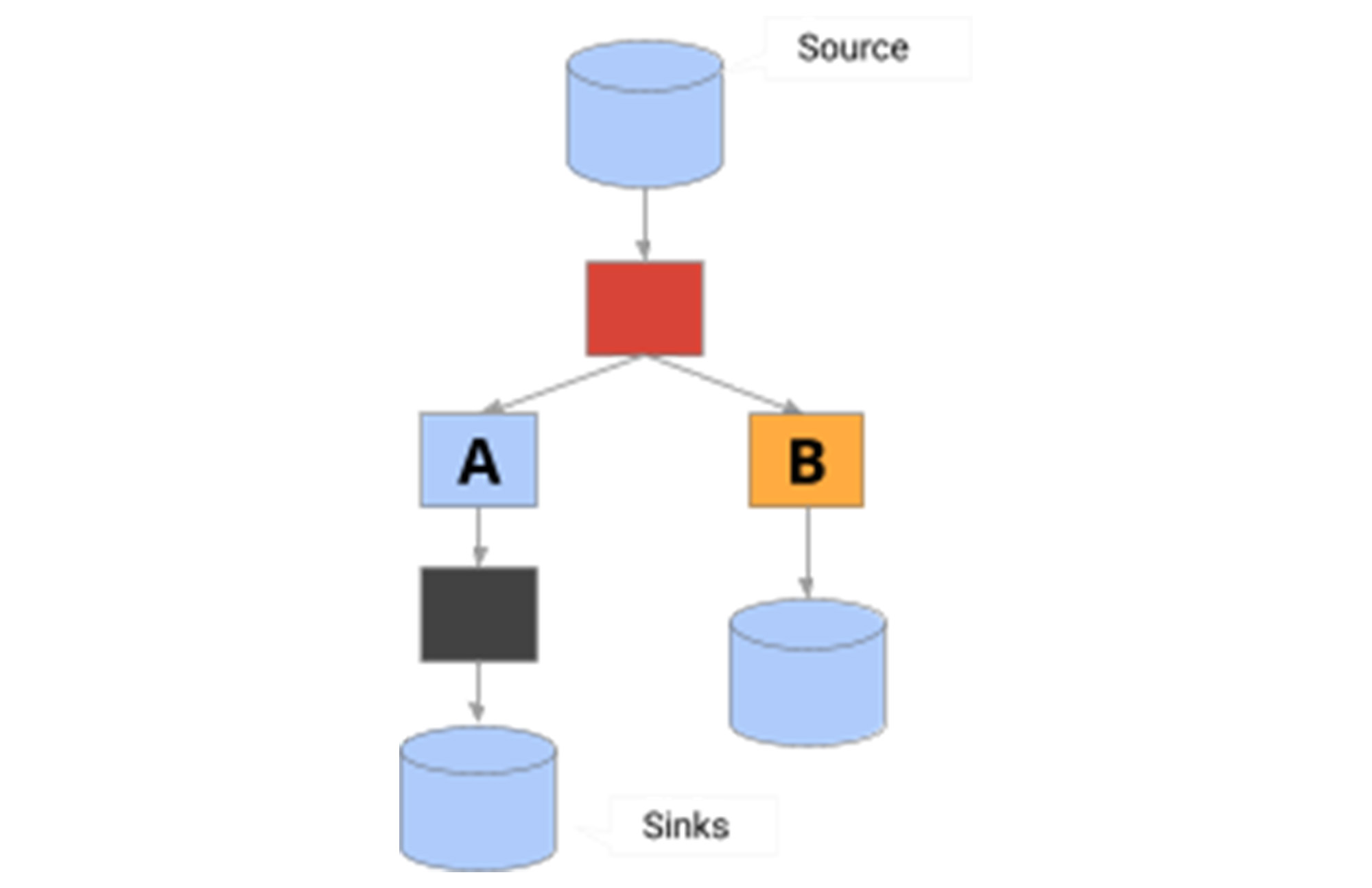
このパターンでは、データは 2 つのモデルに分岐します。すべてのデータを両方のモデルに送るには、次の形式のコードを使用します。
モデルの直列化:
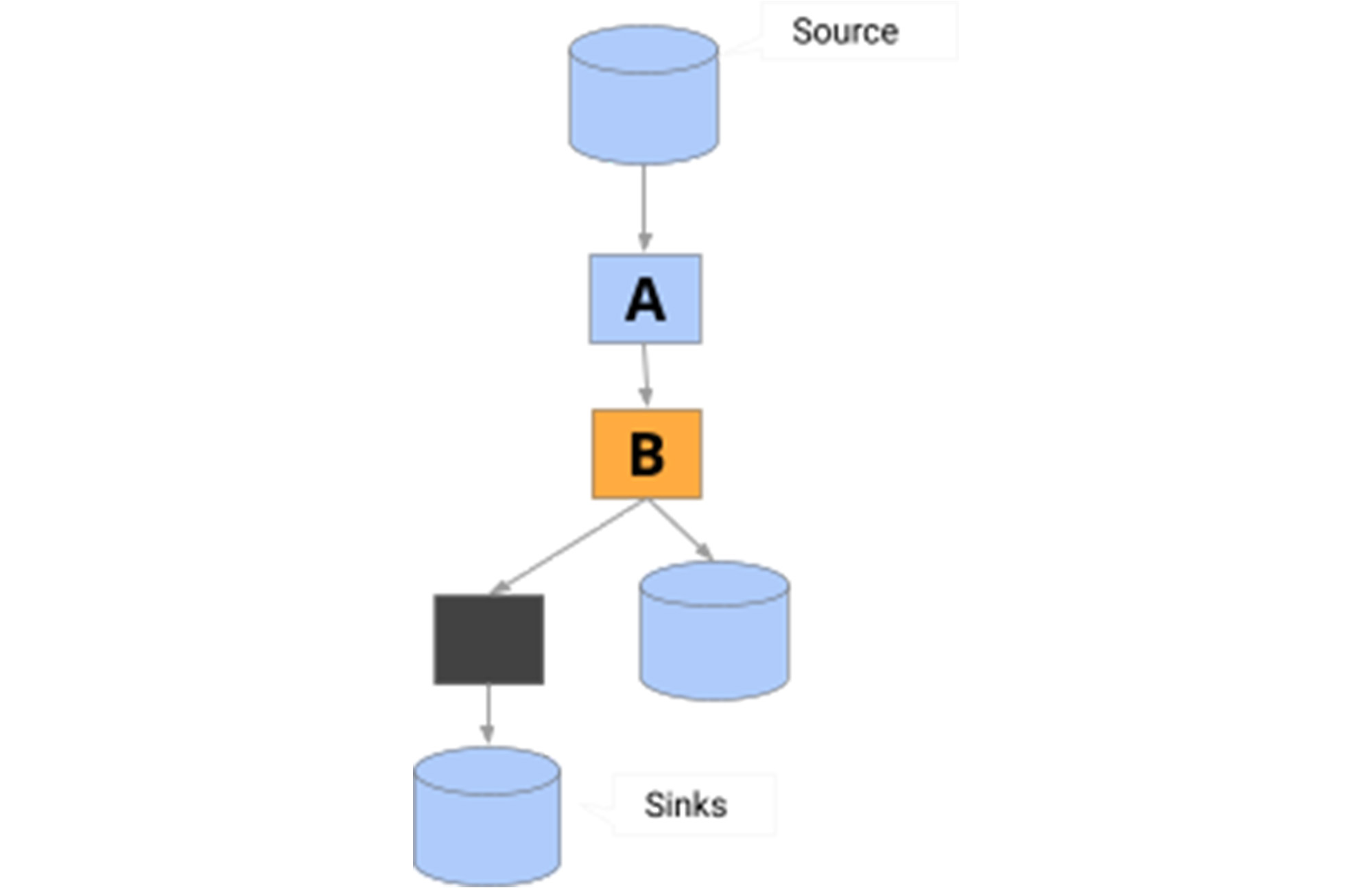
このパターンでは、最初のモデルの出力が次のモデルに送られます。通常は、これらのステージの間になんらかの形の後処理が発生します。データを次のステップ用に適切なシェイプで取得するには、次の形式のコードを使用します。
これら 2 つの単純なパターン(分岐とモデルの直列化)を構成要素として、モデルの複雑なアンサンブルを構築できます。また、他の Apache Beam ツールを利用して、これらのパイプラインのさまざまなステージでデータを充実させることもできます。たとえば、直列モデルにおいて、モデル A の出力をデータベースから取得したデータと結合してからモデル B に渡すことができます。Beam ではこのような使い方が一般的です。
オープンソース モデルの使用
最初の例では、Codelab で提供されているトイモデルを使用しました。このセクションではオープンソース モデルを使用し、モデルデータをデータ ウェアハウス(Google Cloud BigQuery)に出力してより包括的なエンドツーエンドのパイプラインを作成する方法を見ていきます。
このセクションに示すコードは自己完結しており、前のセクションで使用した Codelab には含まれていません。
このデモに使用する PyTorch モデルは、Torchvision v0.12.0 に付属する maskrcnn_resnet50_fpn です。このモデルは、画像セグメンテーションの問題を解きます。与えられた画像から、そこに含まれる個々のオブジェクトを検出して境界ボックスで囲みます。
一般に、Torchvision の事前トレーニング済みモデルのようなライブラリは、事前トレーニング済みモデルをメモリに直接ダウンロードします。このようなモデルを RunInference で実行するには、異なる準備が必要です。RunInference は、Python プロセスごとにモデルを一度読み込み、それを多くのスレッド間で共有するためです。したがって、この種のライブラリに含まれる事前トレーニング済みモデルを使用する場合は、若干の準備作業を行います。この PyTorch モデルでは、次のことを行う必要があります。
1- 状態ディクショナリをダウンロードし、ライブラリとは無関係に Beam から使用できるようにする。
2- モデルクラス ファイルを決定して ModelHandler に提供し、クラスの「自動読み込み」機能を無効にする。
バージョン 0.12.0 でこのモデルのシグネチャには、自動ダウンロードを開始する 2 つのパラメータ(pretrained と pretrained_backbone)があります。モデルクラスがモデルファイルを読み込まないようにするため、次のようにこれらのパラメータをどちらも False に設定します。
ステップ 1 -
状態ディクショナリをダウンロードします。場所は、maskrcnn_resnet50_fpn のソースコードに記載されています。
次に、このモデルをダウンロード先のローカル ディレクトリから、ワーカーがアクセスできる共通領域に push します。Google Cloud Storage(GCS)をオブジェクト ストアとして使用している場合は、gsutil のようなユーティリティを使用できます。
ステップ 2 -
この例の ModelHandler では、model_class を使用する必要があります。この例では、これは torchvision.models.detection.maskrcnn_resnet50_fpn です。
これで ModelHandler を構築できます。この例では KeyedModelHandler を作成することに注意してください。これは上記の単純な例で使用したものとは異なります。KeyedModelHandler は、RunInference API に送られる値がタプルである場合に使用します。タプルでは、最初の値はキーで、2 番目の値はモデルによって使用されるテンソルです。これにより、推論が関連付けられている画像の参照を維持することができ、これが後処理ステップで使用されます。
どのようなモデルでも、ある程度の前処理が必要です。ここで、この例のパイプライン用の前処理関数を作成します。重要な注意事項: PyTorch ModelHandler では、バッチにまとめる際、テンソルのサイズをバッチ全体で同じにする必要があります。そのため、ここでは image_size を前処理ステップの一環として設定します。また、この関数は最初の要素が文字列であるタプルを受け入れることにも注意してください。これは「キー」であり、この例のパイプライン コードではファイル名をキーとして使用します。
モデルの出力は、BigQuery に送信する前に後処理する必要があります。ここでは、ラベルを実際の名前(例: person)で非正規化し、これを境界ボックスおよびスコアの出力と集約します。
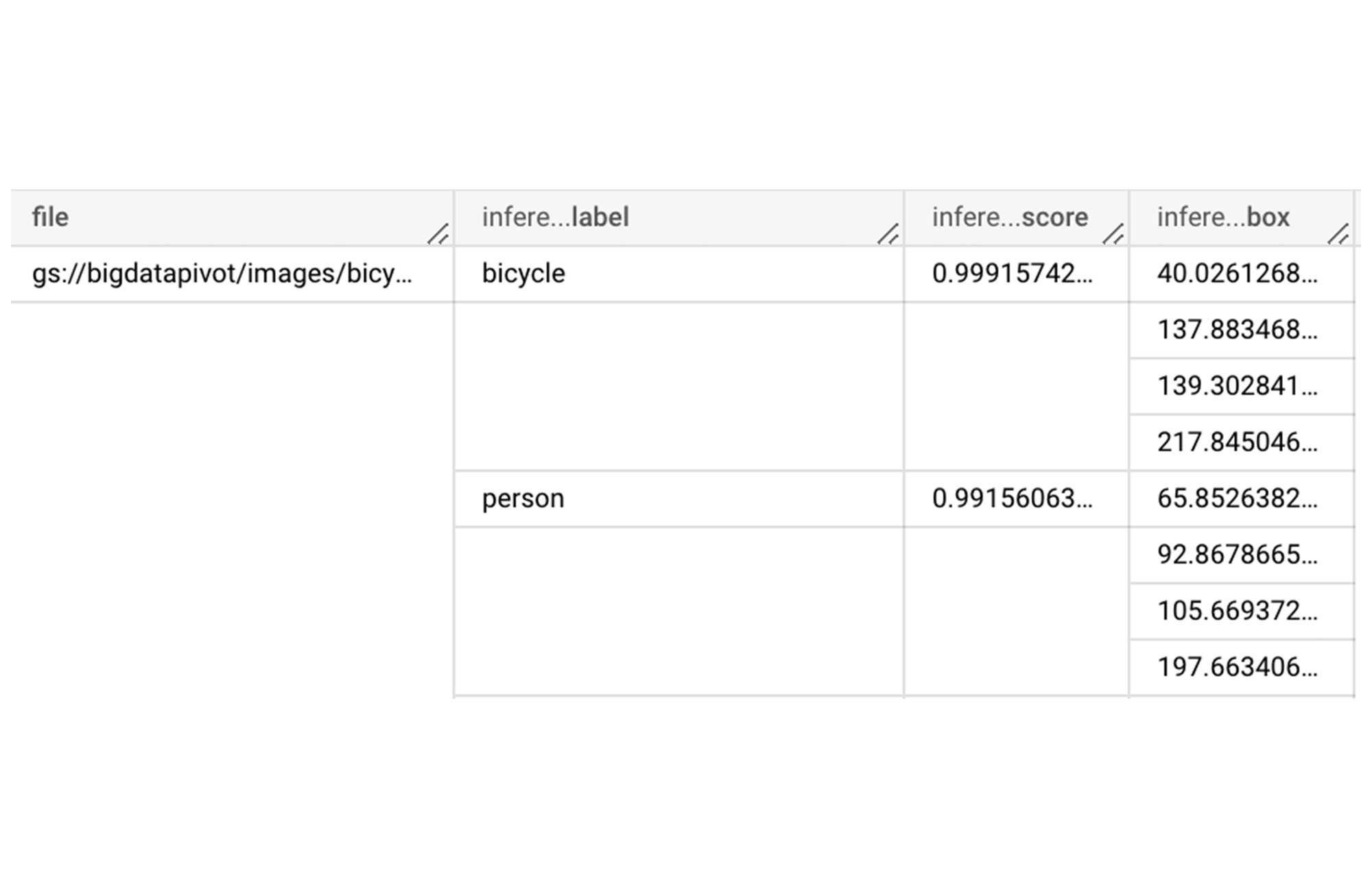
次に、このパイプラインをダイレクト ランナーで実行しましょう。ダイレクト ランナーは、GCS から画像を読み取ってモデル全体に適用し、結果を BigQuery に出力します。使用する BigQuery スキーマを渡す必要があります。このスキーマは、後処理で作成したディクショナリと一致させます。WriteToBigQuery 変換は、スキーマ情報を table_spec オブジェクトとして受け取ります。これは次のスキーマを表します。
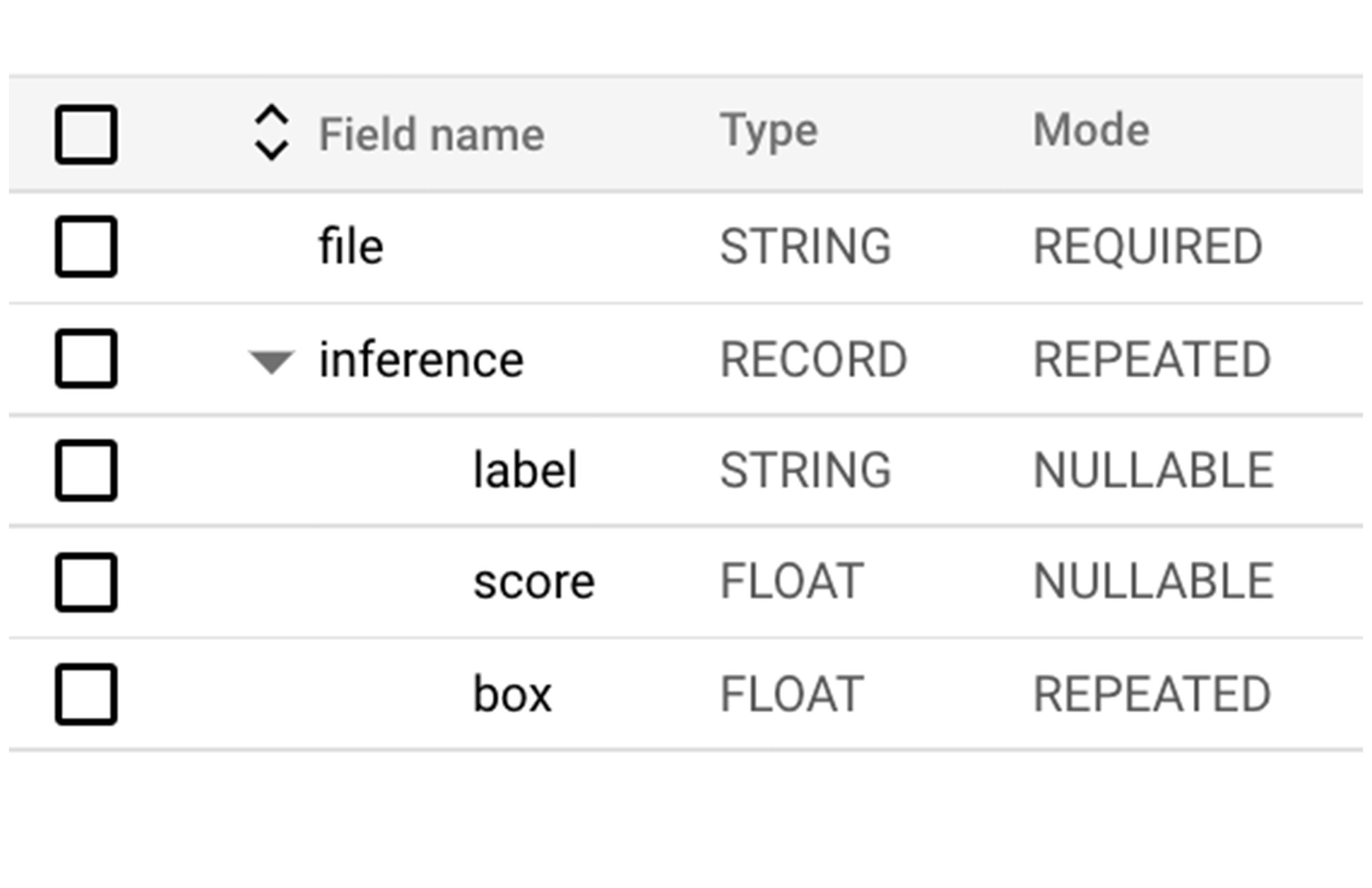
このスキーマに含まれる file 文字列は、出力タプルのキーです。各画像の予測は(ラベル、スコープ、境界ボックスの頂点の) List の形式をとるため、RECORD 型を使用して BigQuery のデータを表現します。
次に、パイプライン オプションを使用してパイプラインを作成します。これは、ローカル ランナーを使用してバケットからの画像を処理し、その結果を BigQuery に push します。BigQuery 呼び出しのためにプロジェクトにアクセスする必要があるため、オプションを介してプロジェクト情報を渡します。
次に、パイプラインを前処理および後処理ステップと連結します。
Beam の MatchFiles 変換は、指定された glob パターンに一致するすべてのファイルを返します。一致したファイルが ReadMatches 変換に送られ、ReadableFile オブジェクトの PCollection が出力されます。このオブジェクトには Metadata.path 情報が含まれ、read() 関数を呼び出してファイルの bytes() を取得できます。その後、取得したバイトを前処理パスに送ります。
このパイプラインを実行すると、予測の結果が BigQuery テーブルに格納されます。
たとえば 10,000 点の画像のバケットがある場合にこのパイプラインをクラウドで実行するには、単にパイプライン オプションを更新し、Dataflow に依存関係の情報を提供するだけです。
requirements.txt ファイルに依存関係を出力します。
適切なパイプライン オプションを作成します。
まとめ
Apache Beam の新しい apache_beam.ml.RunInference 変換を使用すると、機械学習モデルを組み込む大量のボイラープレート データ パイプラインが不要になります。また、これらの変換を利用するパイプラインは Apache Beam の表現力をフル活用することができ、データの前処理と後処理を追加することはもちろん、複雑なマルチモデル パイプラインを最小限のコードで構築することもできます。
- Dataflow 担当シニアスタッフ デベロッパー アドボケイト Reza Rokni

