AI & 機械学習
Google Kubernetes Engine で進化戦略を実行する方法
2019年7月12日
Google Cloud Japan Team
*この記事は Yujin Tang と David Ha による Cloud Blog の記事 "How to run evolution strategies on Google Kubernetes Engine" を元に翻訳・加筆したものです。詳しくは元記事をご覧ください。
強化学習(RL)は、ゲーム、チェス、ロボティクスですばらしい成果をあげており、それとともに機械学習コミュニティでの人気も高まっています。以前のブログ投稿では、Google の強力なコンピューティング インフラや、ハイパーパラメータのベイズ最適化などスマートなトレーニング サービスを活用して、AI Platform で RL アルゴリズムを実行する方法を紹介しました。このブログでは、進化戦略(ES)アルゴリズムについて説明し、Google Kubernetes Engine(GKE)で実行する方法を紹介します。
進化戦略は、進化の考え方に基づいた最適化テクニックです。最近、ES は RL に代わってさまざまな難題に対処するものと見なされるようになっています(1、2)。特に、ノイズの多いポリシー最適化の勾配推定をバイパスでき、かつ収束の早い分散コンピューティングに向いた性質を備えているという 2 点が、よく知られている ES のメリットとしてあげられます。ES は 1960 年代に開発され、容易にスケールする点がメリットとして知られていました。しかし、研究コミュニティのオープンソース プロジェクト(Salimans 他、2007 年)によって、ES を大量のマシンにスケーリングすることで RL アルゴリズムの最高性能に匹敵する結果を出せることが実証されたのは、つい最近のことです。そのため、最新の研究に進化型のアルゴリズムを取り入れる方法を探るディープ ラーニング分野のリサーチャがますます増えています(1、2、3、4、5)。
進化型コンピューティング アルゴリズムをスケーリングする優れたインフラストラクチャを構築すれば、この領域はさらに進展するということは判明していましたが、大規模システム開発に明るい研究者は多くはいません。幸い、ここ数年間で Kubernetes などのテクノロジーが生み出され、専門のエンジニアでなくても簡単に分散環境によるソリューションを構築できるようになりました。そこで本稿では、Kubernetes を活用してスケーラブルな進化型アルゴリズムをデプロイする仕組みの実例を紹介します。コードと手順もこちらで公開していますので、ML 研究において GKE 上で ES を試す際の参考にお役立てください。
ちなみに、Google Cloud ではコンテナによる分散トレーニングが可能なプラットフォームとして AI Platform も提供しています。AI Platform では TensorFlow と同様の分散処理をサポートする ML フレームワークが利用可能です。しかしその目的は、おもにモデルを非同期でトレーニングすることであり、次のセクションで説明するような ES の分散コンピューティングの目的とは異なります。
強化学習(RL)は、ゲーム、チェス、ロボティクスですばらしい成果をあげており、それとともに機械学習コミュニティでの人気も高まっています。以前のブログ投稿では、Google の強力なコンピューティング インフラや、ハイパーパラメータのベイズ最適化などスマートなトレーニング サービスを活用して、AI Platform で RL アルゴリズムを実行する方法を紹介しました。このブログでは、進化戦略(ES)アルゴリズムについて説明し、Google Kubernetes Engine(GKE)で実行する方法を紹介します。
進化戦略は、進化の考え方に基づいた最適化テクニックです。最近、ES は RL に代わってさまざまな難題に対処するものと見なされるようになっています(1、2)。特に、ノイズの多いポリシー最適化の勾配推定をバイパスでき、かつ収束の早い分散コンピューティングに向いた性質を備えているという 2 点が、よく知られている ES のメリットとしてあげられます。ES は 1960 年代に開発され、容易にスケールする点がメリットとして知られていました。しかし、研究コミュニティのオープンソース プロジェクト(Salimans 他、2007 年)によって、ES を大量のマシンにスケーリングすることで RL アルゴリズムの最高性能に匹敵する結果を出せることが実証されたのは、つい最近のことです。そのため、最新の研究に進化型のアルゴリズムを取り入れる方法を探るディープ ラーニング分野のリサーチャがますます増えています(1、2、3、4、5)。
進化型コンピューティング アルゴリズムをスケーリングする優れたインフラストラクチャを構築すれば、この領域はさらに進展するということは判明していましたが、大規模システム開発に明るい研究者は多くはいません。幸い、ここ数年間で Kubernetes などのテクノロジーが生み出され、専門のエンジニアでなくても簡単に分散環境によるソリューションを構築できるようになりました。そこで本稿では、Kubernetes を活用してスケーラブルな進化型アルゴリズムをデプロイする仕組みの実例を紹介します。コードと手順もこちらで公開していますので、ML 研究において GKE 上で ES を試す際の参考にお役立てください。
ちなみに、Google Cloud ではコンテナによる分散トレーニングが可能なプラットフォームとして AI Platform も提供しています。AI Platform では TensorFlow と同様の分散処理をサポートする ML フレームワークが利用可能です。しかしその目的は、おもにモデルを非同期でトレーニングすることであり、次のセクションで説明するような ES の分散コンピューティングの目的とは異なります。
進化戦略入門
ES は一種のブラックボックス最適化です。ベースとなるタスクや関数に勾配がない場合や、勾配の計算が非常に複雑な場合、または勾配推定にノイズが多く学習できない場合など、勾配ベースのアルゴリズムではうまく解決できない ML タスクに有効です。例として、下の図の左側に示す地形に立っていることを想像してみてください。あなたのタスクは、目隠しをして最も低い場所へ向かうことです。あなたは複数の魔法の玉を持っており、それを介してしか周囲の状況を知ることができません。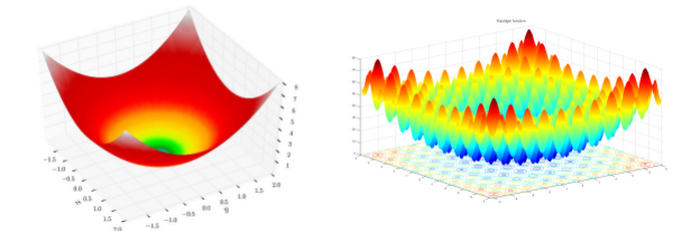
図 1. 球関数(左)と Rastrigin 関数(右)(出典: Wikipedia)
大ざっぱに言えば、勾配ベースのアルゴリズムでは、玉を落として転がしながら行く先を決めるというステップを経ていきます。玉の動く速さを見て、一番速く転がる方向(勾配が一番急な方向)に進みます。左側の地形であれば、このルールに従って何度か玉転がしを繰り返せばゴールにたどり着けます。しかし、同じやり方を右側の地形で試すとどうなるでしょうか。おそらく、山に囲まれた谷底にはまってしまい、目標は達成できないでしょう。
ES のアプローチはこれとはまったく異なります。最適化のステップごとに、複数回の試行を行います。そして、高い適応度(fitness)を示した設定に基づいて進み先を決めます(適応度とは、試行がどのくらい優れているかを測る指標です。上図の地形の例では地面の高さがそれに当たり、低いほど適応度が高いことになります。RL で言えば試行で得られる累積報酬に当たります)。この過程を通じて、適応度が低い試行は取り除かれ、適応度がもっとも高いものだけが生き残ります。これが進化の過程に似ているため、進化戦略という名前が付けられています。
先ほどのたとえに当てはめて ES の仕組みを説明するなら、各ステップで玉を落として転がす代わりにピストルに玉を込めて数発を発射し、いくつかの玉を周囲に散りばめる、ということになります。それぞれの玉が地面に打たれた時点で位置と高度がわかるので、ステップを繰り返すうちに高度が低いと推定される場所に徐々に移動していけます。この方法は、図の左右どちらの地形にもうまく働きます(高い山の向こうにも届く強力なピストルを使うことを想定します)。またこの方法なら、複数回の試行を同時に実行することで最適化を簡単に高速化できます。ますたとえるならピストルの代わりに散弾銃を使うようなものです。
ここまで、ES の基本的な考え方と仕組みを説明しました。さらに興味がある方は、筆者によるブログ記事により詳しい説明が記載されていますので、ぜひ読んでみてください。
これまでの説明で、ES がいわゆるコントローラ ワーカー(controller-worker) アーキテクチャで実装できることが分かるかと思います。この場合、ある設定で試行するようコントローラがワーカーに命令し、ワーカーから戻ってきた結果に基づいて最適化を進める、という処理を繰り返し行います。この実装方法について、先ほどの地形の例を使って Kubernetes 上で ES を実行する方法の定義と説明を書いてみましょう。
今回は、銃や玉は使いません。その代わり、携帯電話で誰かに連絡して玉を発射してもらえます。ただしその前に、何を実行したいのかを具体的に伝えなければなりません(この例では、玉を発射してもらうことです)。そこで「サービス プロバイダへのメモ」に仕様を記述します。また記録のため「自分用のメモ」も準備します。サービス プロバイダにこの仕様を送れば、そこからは Kubernates の楽しい仕掛けが動き始めます。
ES のアプローチはこれとはまったく異なります。最適化のステップごとに、複数回の試行を行います。そして、高い適応度(fitness)を示した設定に基づいて進み先を決めます(適応度とは、試行がどのくらい優れているかを測る指標です。上図の地形の例では地面の高さがそれに当たり、低いほど適応度が高いことになります。RL で言えば試行で得られる累積報酬に当たります)。この過程を通じて、適応度が低い試行は取り除かれ、適応度がもっとも高いものだけが生き残ります。これが進化の過程に似ているため、進化戦略という名前が付けられています。
先ほどのたとえに当てはめて ES の仕組みを説明するなら、各ステップで玉を落として転がす代わりにピストルに玉を込めて数発を発射し、いくつかの玉を周囲に散りばめる、ということになります。それぞれの玉が地面に打たれた時点で位置と高度がわかるので、ステップを繰り返すうちに高度が低いと推定される場所に徐々に移動していけます。この方法は、図の左右どちらの地形にもうまく働きます(高い山の向こうにも届く強力なピストルを使うことを想定します)。またこの方法なら、複数回の試行を同時に実行することで最適化を簡単に高速化できます。ますたとえるならピストルの代わりに散弾銃を使うようなものです。
ここまで、ES の基本的な考え方と仕組みを説明しました。さらに興味がある方は、筆者によるブログ記事により詳しい説明が記載されていますので、ぜひ読んでみてください。
Kubernetes 入門
Kubernetes は、コンテナ化したワークロードとサービスを宣言的な設定や自動化を活用して管理するためのプラットフォームです。Google が開発を始め、2014 年にオープンソース化されました。Kubernetes を詳細に解説するには何ページも必要なので、ここでは概説にとどめ、ES への応用を中心に説明します。これまでの説明で、ES がいわゆるコントローラ ワーカー(controller-worker) アーキテクチャで実装できることが分かるかと思います。この場合、ある設定で試行するようコントローラがワーカーに命令し、ワーカーから戻ってきた結果に基づいて最適化を進める、という処理を繰り返し行います。この実装方法について、先ほどの地形の例を使って Kubernetes 上で ES を実行する方法の定義と説明を書いてみましょう。
今回は、銃や玉は使いません。その代わり、携帯電話で誰かに連絡して玉を発射してもらえます。ただしその前に、何を実行したいのかを具体的に伝えなければなりません(この例では、玉を発射してもらうことです)。そこで「サービス プロバイダへのメモ」に仕様を記述します。また記録のため「自分用のメモ」も準備します。サービス プロバイダにこの仕様を送れば、そこからは Kubernates の楽しい仕掛けが動き始めます。

この仕様を Kubernetes で実装する場合、サービス プロバイダへのメモにある「やるべきこと」の部分をワーカーのプログラムとして記述し、自分用のメモの部分をコントローラのプログラムとして記述します。これらをいくつかのランタイム ライブラリと合わせてパッケージ化し、コンテナ イメージを作成します。そして Kubernetes がサービス プロバイダとなり、ワークロードと呼ばれる仕様を受け取り。ワークロードはコンテナ イメージとリソースなどのいくつかのシステム設定で構成されます。
上記例にある 10 台のクルマは、クラスタ内の 10 個のノードに相当します。また 100 人の玉の射撃手は、実行したいコンテナ(Kubernetes の用語ではポッドと言います)の数を表します。Kubernetes は、これらのポッドを用意する責任を持ちます。また 100 人の射撃手を用意できても、個々の射撃手と直接やりとりして結果を集めたりするのは面倒な作業です。中には、病気で休んだ人(マシンの再起動により動作していないコンテナ)が、あなたの知らない別の人(新しく起動したコンテナ)に仕事を引き継いでいるかもしれません。こうした面倒に対処するため、Kubernetes はワークロードをサービスとして公開し、コントローラとワーカーの連絡窓口とします。サービスは関連するポッドを取りまとめているので、いつでもポッドに取り次いでくれるうえ、負荷の分散も可能です。
プラットフォームとして Kubernetes を使うと、高可用性(希望どおりの数のポッドを確実に実行可能)と大きな拡張性(実行時にポッドを追加・削除可能)が得られます。こうした性質を備えた Kubernetes は、ES に理想的なプラットフォームだと私たちは考えています。また、Kubernetes の可用性と拡張性をノードレベルにまで拡張する GKE を導入することで、さらに優れたプラットフォームが実現可能です。
次のコード スニペットに、メッセージの定義を示します。「ロールアウト」とは 1 回の試行を表しており、rollout_reward はロールアウトから返される適応度です。
上記例にある 10 台のクルマは、クラスタ内の 10 個のノードに相当します。また 100 人の玉の射撃手は、実行したいコンテナ(Kubernetes の用語ではポッドと言います)の数を表します。Kubernetes は、これらのポッドを用意する責任を持ちます。また 100 人の射撃手を用意できても、個々の射撃手と直接やりとりして結果を集めたりするのは面倒な作業です。中には、病気で休んだ人(マシンの再起動により動作していないコンテナ)が、あなたの知らない別の人(新しく起動したコンテナ)に仕事を引き継いでいるかもしれません。こうした面倒に対処するため、Kubernetes はワークロードをサービスとして公開し、コントローラとワーカーの連絡窓口とします。サービスは関連するポッドを取りまとめているので、いつでもポッドに取り次いでくれるうえ、負荷の分散も可能です。
プラットフォームとして Kubernetes を使うと、高可用性(希望どおりの数のポッドを確実に実行可能)と大きな拡張性(実行時にポッドを追加・削除可能)が得られます。こうした性質を備えた Kubernetes は、ES に理想的なプラットフォームだと私たちは考えています。また、Kubernetes の可用性と拡張性をノードレベルにまで拡張する GKE を導入することで、さらに優れたプラットフォームが実現可能です。
GKE による ES の実装
では、ES の実装方法の詳細と、それを GKE で実行する手順を見ていきましょう。コードと実装手順はこちらでアクセスできます。実装
上述のとおり、実装にはコントローラ ワーカー アーキテクチャを採用します。各ワーカーは独立したサーバーで構成され、コントローラがクライアントとなります。プロセス間通信には gRPC を利用します。リモート プロシージャ コール(RPC)はデータを渡す手段としてはメッセージ パッシング インターフェース(MPI)などの他の選択肢ほど高効率ではありません。しかしデータのパッケージングが簡単で耐障害性も高いため、クラウド環境ではよく使われています。次のコード スニペットに、メッセージの定義を示します。「ロールアウト」とは 1 回の試行を表しており、rollout_reward はロールアウトから返される適応度です。
読み込んでいます...
このサンプルで利用する ES アルゴリズムは、estool に基づく Parameter-exploring Policy Gradients(PEPG)と 、pycma に基づく Covariance Matrix Adaptation(CMA)です。これらは解決がとりわけ難しい連続制御 RL 環境である Google Brain の Minitaur Locomotion や OpenAI の BipedalWalkerHardcore-v2 でも試せます。また、コードを拡張して ES アルゴリズムを追加したり、設定を変更して独自の環境でアルゴリズムを試したりすることも簡単です。具体的には、algorithm.solver.Solver で定義されたインターフェースに従った実装であれば他のコードと合わせて実行できるはずです。
GKE で ES を実行する
GKE でのコードの実行には、Google Cloud Platform(GCP)で動作するクラスタが必要です。こちらの手順に従ってクラスタを作成します。この例では、次のコマンドと設定を使ってクラスタを作成しましたが、必要に応じて変更しても構いません。読み込んでいます...
クラスタができたら、次の 3 つのステップでサンプルの ES コードを GKE で実行できます。それぞれ簡単な bash コマンドです。
- コントローラとワーカーのコンテナ イメージをビルドする
- ワーカーをクラスタにデプロイする
- コントローラをクラスタにデプロイする
読み込んでいます...

図 2. デプロイが成功した GCP コンソールの例
以上です。これで、GKE 上の指定した環境で ES のトレーニングが実行されています。
トレーニング プロセスの確認は、次の 3 つの方法で行えます。
トレーニング プロセスの確認は、次の 3 つの方法で行えます。
- Stackdriver—GCP コンソールで [GKE Workloads] ページをクリックすると、ポッドの詳細ステータス レポートが表示されます。es-master-pod の詳細に移動すると、[Container logs] から Stackdriver のログを確認できます。ここから、トレーニングやテストの報酬を確認します。
- HTTP サーバー—今回のコードではコントローラ内で簡単な HTTP サーバーが動作しており、トレーニングのログに簡単にアクセスできます。[GKE Services] ページにある es-master-service のエンドポイントからアクセスできます。
- kubectl—kubectl コマンドでもログやモデルを取得できます。例として以下のコマンドを示します。
読み込んでいます...
ローカルで ES を実行する
トレーニングとテストの両方をローカルで実行してデバッグに利用できます。train_local.sh と test.py に適切なオプションを追加して使います。読み込んでいます...
実験結果
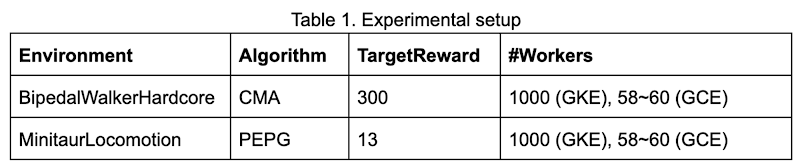
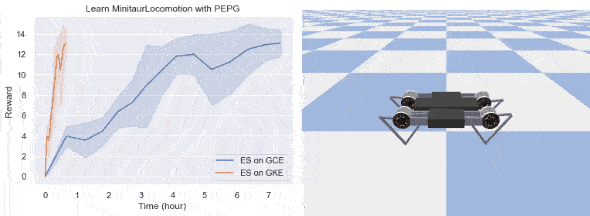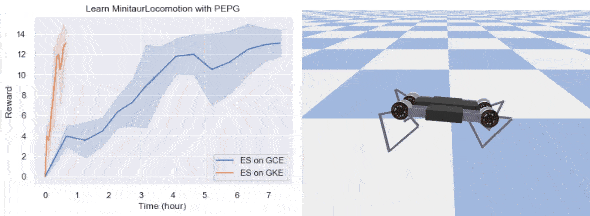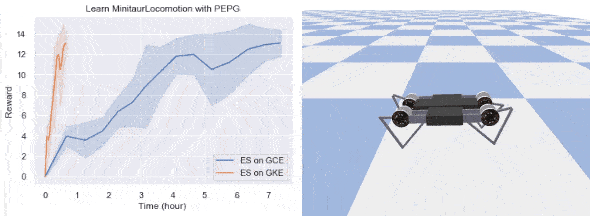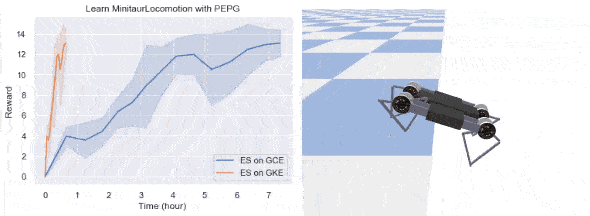
では、GKE で ES を実行するメリットを 2 つの例を通じて確認しましょう。1 つは OpenAI の BipedalWalkerHardcore 環境で CMA を使ってトレーニングした 2D ウォーカー、もう 1 つは Google Brain の MinitaurLocomotion 環境の四足歩行ロボットです。ここでは、テスト試行で 100 回連続して TargetReward よりも大きな平均報酬を実現できれば、エージェントがタスクを解決したと見なします。RL で試せばわかりますが、どちらのタスクも難易度はかなり高いです。次の表は、実験環境の設定についてまとめたものです。比較のため、スタンドアロンの 64 コア Google Compute Engine インスタンスでも実験を行いました。この Compute Engine インスタンスのワーカーの数は、CPU 使用率が 90% を超えるように調整します。
今回の実装では、両方のタスクをクリアできました。結果を下に示します。
厳密にはタスクの内容に依存しますが、GKE で ES を実行すると速度を大幅に向上できる可能性があります。今回の例では、BipedalWalkerHardcore の学習は 5 倍、四足歩行ロボットの学習は 10 倍以上高速です。ML 研究においてこの高速化はより多くのアイデアを試すチャンスとなり、ML アルゴリズム開発のイテレーションの向上にもつながります。
まとめ
ES は、勾配ベースのアルゴリズムでよい結果が得られない ML タスクに対して強力なソリューションとなります。ES には並列処理との親和性が高い性質があるので、Kubernetes で ES を実行することで大幅な高速化を実現できます。これにより、ML リサーチャやエンジニアが新しいアイデアを試すイテレーションのスピードが上がります。簡単にスケールできるという ES の力をもっとも活かせる応用は、難しい問題を解くためのシミュレーション環境をローコストに用意できるケースです。最近の研究(1、2)では、コントローラを実環境にデプロイする前に、まずシミュレーションで仮想ロボット コントローラをトレーニングする方法が効果的であることが実証されています。また、手作業のプログラミングではなく、収集した観測結果から学習で得られたディープラーニング モデルでもシミュレーション環境を実現できます(1、2、3)。こうした応用であれば、ES のスケーリングを活かした数 1000 ノード規模の並列シミュレーション環境での学習が可能でしょう。
進化の手法を用いると最適化する対象の選択肢がぐんと広がるため、従来の RL ポリシー最適化では対応できなかったさまざまな応用が可能です。たとえば、この最新の研究では RL 環境で ES を使い、ポリシーのトレーニングだけでなくより優れたロボットの設計まで学習しています。進化の手法を使うジェネラティブ デザインの領域では、ずっと多くのクリエイティブな応用が生まれるはずです。また、この最新の研究成果では、複数の RL タスクを実行できる最小のニューラル ネットワーク アーキテクチャが、進化型アルゴリズムを使うことでパラメータのトレーニングなしで得られることを実証しています。この結果は多くの ML リサーチャを驚かせ、進化の手法が切り拓くまったく新しい研究分野の存在を示しています。
ディープ ラーニングの革命は、大規模なディープ ニューラル ネットワークのトレーニングを実現する GPU が触媒となり生じました。同様に、ローコストな CPU で構成された大規模クラスタへ簡単にスケールできる進化の手法は、これからのコンピューティング革命をリードするカギとなるでしょう。
GKE や Kubernetes によるディープラーニングの詳細については以下をご覧ください。



