PyTorch / XLA 2.6 によるモデル パフォーマンスの向上
Kyle Meggs
Sr. Product Manager, AI Infrastructure
Yifei Teng
Software Engineer
※この投稿は米国時間 2025 年 2 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
PyTorch のディープ ラーニング フレームワークを Cloud TPU とともに使用しようとしている開発者にとって、PyTorch / XLA Python パッケージは鍵となる存在です。このパッケージにより、わずかなコード変更だけで PyTorch モデルを Cloud TPU 上で実行できます。これは、Google が開発した OpenXLA を活用することで実現しており、開発者は、モデルを一度定義するだけでさまざまな種類の ML アクセラレータ(GPU、TPU など)で実行できるようになります。
PyTorch / XLA の最新リリースには、開発者のための次にようなパフォーマンスの改善が含まれています。
-
新しい試験運用版の scan 演算子によって、繰り返し実行されるコードブロック(for ループなど)のコンパイルを高速化
-
TPU テンソルをホスト CPU のメモリに移動するホスト オフロードによって、より少ない TPU でより大きなモデルを処理
-
C++ 2011 標準アプリケーション バイナリ インターフェース(C++ 11 ABI)フラグを使用してコンパイルされた新しいベース Docker イメージによって、トレースに制約されるモデルのグッドプットを改善
これらの改善点に加えて、必要な情報が簡単に見つかるようにドキュメントも再編成されました。
それぞれの機能について、詳しく見ていきましょう。
試験運用版の scan 演算子
大規模言語モデル(LLM)や PyTorch / XLA を使用するとき、特に多数のデコーダレイヤを含むモデルを扱うときに、コンパイルに時間がかかったことはないでしょうか。モデルで実行されるすべての操作のグラフを走査するグラフトレース中、これらの反復ループは完全に「展開」されます。つまり、サイクルごとに各ループ反復のコピーと貼り付けが行われ、結果として演算グラフが大きくなります。グラフが大きくなると、コンパイル時間が長くなります。しかし、この状況に新しい解決策が登場しました。jax.lax.scan にヒントを得た新しい試験運用版 scan 関数です。
scan 演算子は、コンパイル中にループが処理される方法を変更します。各ループ反復を個別にコンパイルして冗長なブロックを作成する代わりに、scan は最初の反復のみコンパイルします。コンパイル結果として得られる高レベル操作(HLO)が、その後のすべての反復で再利用されます。これは、後続のループごとに生成される HLO や中間コードが少なくなることを意味します。scan は最初のループ反復のみコンパイルするため、for ループと比較するとわずか数分の一の時間でコンパイルが完了します。これにより、開発者は LLM など多数の同種レイヤを含むモデルで作業しているときの反復処理時間を短縮できます。
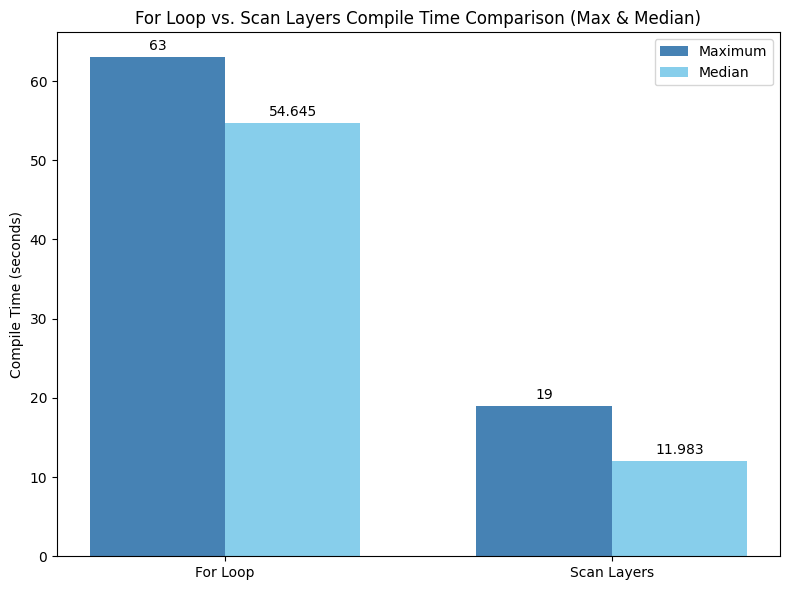
torch_xla.experimental.scan をベースに構築された torch_xla.experimental.scan_layers 関数は、nn.Modules のシーケンスをループするための簡略化されたインターフェースを提供します。これは、PyTorch / XLA に「これらのモジュールはすべて同じなので、一度だけコンパイルして再利用しましょう」と伝える手段だと考えてください。以下に例を示します。
注意点は、カスタム pallas カーネルがまだ scan をサポートしていないことです。LLM で scan_layers を使用する完全な例についてはこちらをご覧ください。
ホスト オフロード
PyTorch / XLA には、メモリ最適化のための別の強力な手段としてホスト オフロードがあります。この手法により、テンソルを TPU からホスト CPU のメモリに一時的に移動し、トレーニング中に貴重なデバイスメモリを解放することができます。これは、メモリへの負荷が懸念される大規模モデルの場合に特に役立ちます。torch_xla.experimental.stablehlo_custom_call.place_to_host を使用してテンソルをオフロードし、torch_xla.experimental.stablehlo_custom_call.place_to_device を使用して後で取得できます。一般的なユースケースでは、フォワードパス中に中間アクティベーションをオフロードし、バックワード パス中にそれらを戻します。こちらのホスト オフロードの例をご覧ください。
ホスト オフロードを戦略的(メモリが限られていてアクセラレータを継続的に使用できない場合など)に使用すると、ハードウェアのメモリ制約内で大規模かつ複雑なモデルをずっとスムーズにトレーニングできるようになる可能性があります。
代替のベース Docker イメージ
ホスト CPU がジャストインタイム コンパイルのためにモデル実行グラフをトレースして大きな負荷を抱えているときに、TPU がアイドル状態になったことはないでしょうか。これは、モデルがトレースの制約を受けていること、つまりパフォーマンスがトレース動作の速度によって制限されていることを示します。
この場合、C++11 ABI イメージが解決策となります。今回のリリースから、PyTorch / XLA は Python ホイールと Docker イメージの両方に対して C++ ABI フレーバーの選択肢を提供します。このため、PyTorch / XLA で使用する C++ のバージョンが選択可能になります。PyTorch アップストリームと一致させる場合のデフォルトである C++11 以前の ABI と、より新しい C++11 ABI の両方を含むビルドが用意されます。
C++11 ABI のホイールまたは Docker イメージに切り替えると、上記のシナリオで顕著な改善が実現します。たとえば、C++11 以前の ABI から C++11 ABI に切り替えたとき、v5p-256 Cloud TPU(グローバル バッチサイズ 1024)上で Mixtral 8x7B モデルのグッドプットが相対的に 20% 向上しました。ML グッドプットにより、特定のモデルがハードウェアをどれだけ効率的に利用しているかを把握できます。したがって、同じハードウェアで同じモデルのグッドプットの測定値が大きい場合、そのモデルのパフォーマンスが高いことになります。
Dockerfile で C++11 ABI の Docker イメージを使用する場合の例を以下に示します。
あるいは、Docker イメージを使用していない場合(ローカルでテストしている場合など)、次のコマンドを使用してバージョン 2.6 の C++11 ABI ホイールをインストールできます(Python 3.10 の例)。
上記のコマンドは Python 3.10 で動作します。他のバージョンでの手順は、こちらのドキュメントに記載されています。
C++ ABI は柔軟に選択できるため、特定のワークロードとハードウェアに最適なビルドを選択でき、最終的には PyTorch / XLA プロジェクトのパフォーマンスと効率が向上します。
ぜひ PyTorch / XLA の最新バージョンをお試しください。詳しくは、最新のリリースノートをご覧ください。
GPU サポートに関する注意事項
PyTorch / XLA 2.6 リリースでは、PyTorch / XLA:GPU ホイールは提供されていません。Google はこれが重要であることを理解しており、2.7 リリースまでに GPU サポートを復活させることを予定しています。PyTorch / XLA はオープンソース プロジェクトであるため、プロジェクトの維持と改善のために、コミュニティの皆さんの貢献を歓迎しています。プロジェクトに参加するには、まずコントリビューター ガイドをご覧ください。
PyTorch / XLA:GPU ホイールが利用可能な最新の安定版は torch_xla 2.5 です。
-シニア プロダクト マネージャー、Kyle Meggs
-ソフトウェア エンジニア、Yifei Teng


