How to run evolution strategies on Google Kubernetes Engine
Yujin Tang
Research Software Engineer, Google Research
David Ha
Research Scientist, Google Brain Tokyo
Reinforcement learning (RL) has become popular in the machine learning community as more and more people have seen its amazing performance in games, chess and robotics. In previous blog posts we’ve shown you how to run RL algorithms on AI Platform utilizing both Google’s powerful computing infrastructure and intelligently managed training service such as Bayesian hyperparameter optimization. In this blog, we introduce Evolution Strategies (ES) and show how to run ES algorithms on Google Kubernetes Engine (GKE).
Evolution Strategies are an optimization technique based on ideas of evolution. Recently, ES has been shown (i.e. 1, 2) to be a good alternative for RL at tackling various challenging tasks. Specifically, two of the well known benefits of ES are bypassing noisy gradient estimate for policy optimization and its nature of encouraging distributed computing that brings faster convergence. While ES, first developed in the ‘60s, have the benefit of ease of scalability, only recently did open source projects (i.e. Salimans et al. 2007) in the research community demonstrate that scaling ES to a large number of machines can achieve results competitive to SOTA RL algorithms. As a result, an increasing number of deep learning researchers have been exploring ways to incorporate evolution-based algorithms into recent research (i.e. 1, 2, 3, 4, 5).
Evidence suggests that putting more effort into building better infrastructure to scale evolutionary computing algorithms will facilitate further progress in this area, however few researchers are experts in large scale systems development. Luckily, in the past few years, technologies such as Kubernetes have been developed to make it easier for non-specialist programmers to deploy distributed computing solutions. As a demonstration of how Kubernetes might be used to deploy scalable evolutionary algorithms, in this blog post, we explore the use of Kubernetes as a platform for easily scaling up ES. We provide the code and instructions here and hope all these serve as a quickstart for ML researchers to try out ES on GKE.
For the record, AI Platform provides distributed training with containers which works with an ML framework that supports a distributed structure similar to that of TensorFlow’s. It is primarily for asynchronized model training, whereas distributed computing in ES is for a different purpose as you will see in the following section.
Evolution Strategies 101
ES is a class of black box optimization; it’s powerful for ML tasks where gradient based algorithms fail when the underlying task / function has no gradient, the complexity of computing gradient is high, the noise embedded in gradient estimation prevents learning, and other issues. As an illustration, imagine standing at a point on the terrain shown on the left in the following figure. Your task is to navigate your way to the lowest point of the terrain blindfolded. You are given some magic beads and they are the only way you interact with the environment.
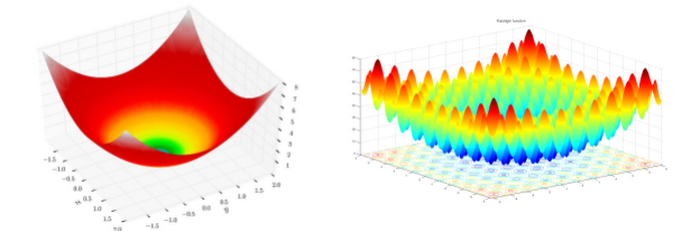
Loosely speaking, with gradient based algorithms, at every decision-making step you drop some beads and let them roll for some time. The beads report their speeds and you walk a step along the direction most of the beads roll fast (because it’s steep there). Following this rule, you will probably reach the goal after a few iterations. Now try the same strategy on the right terrain in the figure. Chances are you will fail the mission and get stuck at the bottom of a valley surrounded by mountains.
ES works very differently. Every optimization step consists of many trials; a decision is made based on the settings of those trials with great fitness. (Fitness is a metric that defines how good a trial is; it can be the altitude in our example, the lower the better. Analogous to the cumulative rewards of a trial in an RL environment.) This process, in which the trials with poor fitness are eliminated and only the fittest survives resembles evolution, hence the name.
To give an example of how ES works in the previous context, instead of dropping the beads at each step, you launch the beads one by one with a pistol and let them spread the nearby region. Each bead reports its position and altitude upon landing, and you move to a point where the estimated altitude seems to be low. This strategy works on both terrains in the figure (suppose our pistol is very powerful and can shoot over high mountains) and it is easy to see that parallel executions of the trials can speed up the process (e.g., replace the pistol with a shotgun).
The description in this section is meant to give you a very basic idea of what ES is and how it works. Interested readers are strongly recommended to refer to this series of blog posts that provides an excellent introduction and in-depth description.
Kubernetes 101
Kubernetes started at Google and was open-sourced in 2014. It is a platform for managing containerized workloads and services that facilitates both declarative configuration and automation. A thorough description of Kubernetes requires pages of documentation; in this section we will only scratch the surface and give an ES centred introduction of Kubernetes.
From our previous discussion, it is easy to see the implementation of ES falls into a controller-worker architecture wherein at each iteration the controller commands the workers to do trials with given settings and perform optimization based on the workers’ feedback. With this implementation plan, let’s give some definitions and a description of how ES is conducted on Kubernetes in our earlier lowest point-finding example.
You are not given a gun or beads this time; instead you have a cellphone and you can call someone to do the job of shooting the beads for you. You need to specify what you are expecting before requesting any service (in this example, bead-shooting). So you write your specification on the “Note to service provider”. You also prepared a "Note to myself" as a memo. Submitting the specification to a service provider, you started your exciting adventure.

In this metaphor, the “What to do” sections on the service provider’s note is the worker’s program and the other is the controller’s program. Together with some runtime libraries, we package them as container images. The service provider is Kubernetes, and the specification it receives is called a workload, which consists of the container images and some system configurations such as resources. For example, the 10 cars in our example corresponds to 10 nodes / machines in a cluster; the 100 bead-shooters represents how many running containers (pods, in Kubernetes language) we wish to have, and Kubernetes is responsible for the availability of these pods. You probably don’t want to call each of these 100 bead-shooters to collect results. Plus, some bead-shooters may take sick leaves (E.g., failed containers due to machine reboot) and have delegated their jobs to other shooters (newly started containers) whose numbers you may not have. To cope with this, Kubernetes exposes a workload as a service that acts as a point of contact between the controller and the workers. The service is associated with the related pods; it always knows how to reach them and it provides load balance to the pods.
With Kubernetes as a platform, we have high availability (Kubernetes makes sure the number of running pods match your expectations) and great scalability (Kubernetes allows adding / removing running pods at runtime). We think that’s what makes Kubernetes an ideal platform for ES. And GKE extends Kubernetes’s availability and scalability to node level which makes it an even better platform!
ES on GKE
In this section, we describe our implementation of ES and instructions for running it on GKE. You can access the code and the instructions here.
Our implementation
As is discussed in the previous sections, we adopt a controller-worker architecture in our implementation and we use gRPC as the interprocess communication method. Each worker is an independent server and the controller is the client. Remote procedure call (RPC) is not as efficient as other options such as message passing interface (MPI) in terms of data passing, but RPC’s user friendliness for data packaging and high fault tolerance makes it a better candidate in cloud computing. The following code snippet shows our message definitions. Each rollout corresponds to a trial and rollout_reward is the fitness reported from the rollout.
The ES algorithms we provide as samples are Parameter-exploring Policy Gradients (PEPG) (based on estool) and Covariance Matrix Adaptation (CMA) (based on pycma). You can play with them in Google Brain's Minitaur Locomotion and OpenAI's BipedalWalkerHardcore-v2, a particularly difficult continuous-control RL environment to solve. You can also easily extend the code there to add your ES algorithms or change the configs to try the algorithms in your own environments. To be concrete, we defined an interface in algorithm.solver.Solver, as long as your implementation conforms to that interface, it should run with the rest of the code.
Run ES on GKE
To run our code on GKE, you need a cluster on Google Cloud Platform (GCP); follow the instructions here to create yours. We use the following command and configs to create our cluster; feel free to change these to suit your needs.
When you have a cluster sitting there, running our sample ES code on GKE involves only three steps, each of which is a simple bash command:
- Build container images for the controller and the workers.
- Deploy the workers on the cluster.
- Deploy the controller on the cluster.

That's all! ES should be training in your specified environment on GKE now.
We provide 3 ways for you to check your training progress:
- Stackdriver—In the GCP console, clicking the GKE Workloads page gives you detailed status report of your pods. Go to the details of the
es-master-podand you can find "Container logs" that will direct you to Stackdriver logging where you can see training and test rewards. - HTTP Server—In our code, we start a simple HTTP server in the controller to make training logs easily accessible to you. You can access this by checking the endpoint in
es-master-servicelocated in the GKE Services page. - Kubectl—Finally, you can use the kubectl command to fetch logs and models. The following commands serve as examples.
Run ES locally
As a debugging process, both training and test can be run locally.
Use train_local.sh and test.py, and add proper options to do so.
Experiments
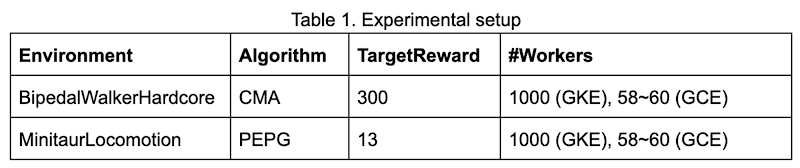
To prove the benefits of running ES on GKE, we present two examples in this section: a 2D walker trained with CMA in OpenAI’s BipedalWalkerHardcore environment, and a quadruped robot in Google Brain’s MinitaurLocomotion environment. We consider the tasks solved if the agents can achieve an average of reward greater than TargetReward in 100 consecutive test trials; both tasks are challenging (try solving them with RL). The following table summarizes our experimental settings. We also ran experiments on a standalone Google Compute Engine instance with 64 cores for the purpose of comparison, the number of workers on this Compute Engine instance is tuned to make sure its CPU utilization is above 90%.
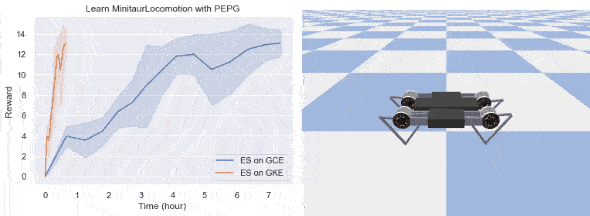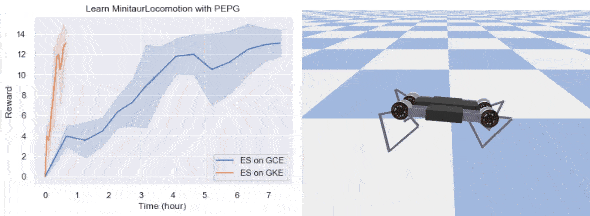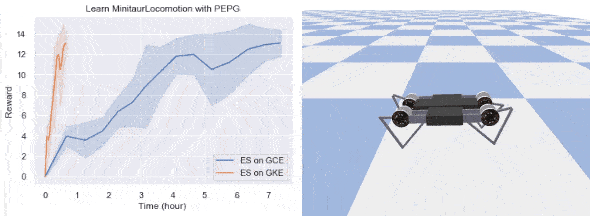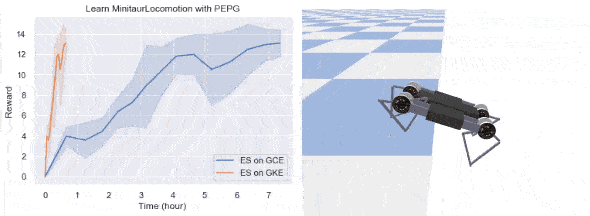
Our implementation is able to solve both tasks and the results are presented below.
Although the exact ratio is task dependent, ES can get significant speedup when run on GKE. In our examples, learning BipedalWalkerHardcore is 5 times faster and learning a quadruped robot is more than 10 times faster. To ML researchers, this speedup brings opportunities to try out more ideas and allows for faster iteration in ML algorithm development.
Conclusion
ES is powerful for ML tasks where gradient based algorithms do not give satisfactory solutions. Given its nature of encouraging parallel computation, ML researchers and engineers can get significant speedup when ES is run on Kubernetes and this allows faster iteration for trying out new ideas.
Due to the ease of scalability of ES, we believe the applications that can get the most benefit from ES are those where cheap simulation environments exist for difficult problems. Recent works (i.e. 1, 2) demonstrate the effectiveness of training virtual robot controllers first in a simulation, before deploying the controller in the real world environment. Simulation environments, rather than having to be hand-programmed, can also be learned from collected observations and represented as a deep learning model (i.e. 1, 2, 3). These types of applications might leverage the scaling of ES to learn from thousands of parallel simulation environments.
As evolutionary methods allow more flexibility in terms of what is being optimized, applications can span beyond traditional RL policy optimization. For instance, this recent work used ES in an RL environment to not only train a policy, but also learn a better design for the robot. We expect many more creative applications in the area of generative design using evolution. In this latest research work, the authors demonstrated the possibility of finding minimal neural network architectures that can perform several RL tasks without weight training using evolutionary algorithms. This result surprises a lot of ML researchers and points at a brand new research field wherein evolution plays the main role. Just as GPUs were the catalyst that enabled the training of large, deep neural networks leading to the deep learning revolution, we believe the ability to easily scale up evolutionary methods to large clusters of low-cost CPU workers will lead to the next computing revolution.
To learn more about GKE and Kubernetes for deep learning, visit:



