Google Cloud での説明を使用したイベントのモニタリング

Google Cloud Japan Team
※この投稿は米国時間 2022 年 3 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
ユースケース
IT や各業界でのオペレーションにおけるイベントをモニタリングし、その問題を説明するための新しい本番環境の機械学習ソリューションについて説明します。このソリューションは、さまざまな産業用アプリケーションとして使用されています。これには、IT 運用インフラストラクチャの積極的なモニタリング、産業用のモノのインターネット(IoT)のコネクテッド デバイスでのイベントのモニタリング、また、ハイパーコンバージド、Cloud、仮想インフラストラクチャ、アプリケーション、ネットワーク、マイクロサービスなどのあらゆる IT オペレーション管理コンポーネントに対する予測モニタリングなどが含まれます。
このソリューションは、Google のコーポレート エンジニアリングの革新的な研究と機械学習と Google Cloud のプロフェッショナル サービスによってまとめられた Google Cloud の運用化ツールを組み合わせることで Google Cloud Platform にデプロイされます。
このアプローチの主なメリットは次のとおりです。
Google の新しいソリューションは、主にラベル付けされていないデータに対してスケーラブルで教師なしのアプローチを提供し、データ ストリーム内でイベントを積極的にモニタリングし、予測を説明します。このアプローチは次の場合に特に便利です。
データに相関関係があり、マルチモーダルである
障害が複雑である
条件が予測不能である
モニタリングされるコンポーネントが新しすぎるため、通常モードか障害モードかを定義できない
Google のソリューションでは、Google Research の革新的なモデルの説明可能性テクノロジーを使用して、予想される障害を説明します。
このソリューションは、以下のようなさまざまな産業用および IT 管理用アプリケーションにデプロイされてきました。
商業ビルや電力設備の電力および空調管理。
IT インフラストラクチャのモニタリングと管理。
物理的なセキュリティ システムでのバッジリーダーおよびアラーム。
発電所の電気機械コンポーネント。
このブログでは、IT サービス保険会社である Zenoss が、スマートな IT 運用管理に関する業界の重要な問題に対処するために、どのように Google のソリューションをデプロイしているのかをご紹介します。
アルゴリズム
あなたは何千台ものネットワーク接続デバイスをメンテナンスする技術者だとします。メンテナンスしているデバイスは、仮想マシン、サーバー、暖房換気空調システム ユニット、エンジンなどで、これらはタイムスタンプ付きの多次元測定のアップデートのデータ ストリームを生成します。フリートのどこかに注意を要する障害のあるデバイスが存在する可能性は常に高いと言えます。複雑なデバイス操作や動的な環境により、正常なオペレーションの状態をルールで特徴付けることはもちろん、ラベル付けされた障害の事例から機械学習分類器をトレーニングすることさえ不可能な場合があります。このような状況では、分離フォレストや 1 クラス サポート ベクター マシンのような教師なしの異常検出器(ラベルなしでトレーニング)がよく使われますが、デバイスが通常とは異なる更新を行った場合は非記述的なアラームが表示されます。
問題のあるデバイスの検出は技術者のタスクの始まりにすぎず、修理には以下のことを行うために非記述的なアラーム以上のことが必要になります。
異常が真陽性かどうかを判断する
問題を診断し、根本的な原因を推定する
問題のトリアージと優先順位付けを行う
修理の特定と適用を行う
修理が正常に行われたことを確認する
ここからは、これらのタスクを達成するために不可欠な 3 つの実用的な異常検出のコンセプト(精度と説明可能性、相関とモードに対する感度、大規模なデプロイ)について説明します。
精度と説明可能性
患者は医師に自分の病気を説明するときに、「鼻が詰まっていて、激しい頭痛がする」という変数アトリビューションと、「通常は楽に呼吸できるし、普段は頭痛もない」という対比的な正常な状態を述べます。デバイスの場合も同様に、検出精度(偽陽性、偽陰性のエラー率)と説明可能性の両方を考慮しなければならず、人間の症状と同じように、以下に基づいて異常を説明する必要があります。
最も重要な変数に「原因」スコアを割り当てる変数アトリビューション
異常が正常からどの程度外れているかを示す、最も近い対比的な正常ポイント
下の図は、さまざまな異常検出を検出精度と説明可能性の観点から比較したものです。
変量の統計メソッドは、外れ値の基準を各変数に個別に適用します。変数の相関を認識したり、マルチモーダル分布の処理をしたりはしません。
クラスタリング、1 クラス サポート ベクター マシン(OC-SVM)、分離フォレスト、拡張分離フォレストなどの標準の多変量アプローチは、中~高度の検出精度ですが、説明は提供されません。
DIFFI と Autoencoder+SHAP はどちらも変数アトリビューションで、中程度の検出精度です。
統合勾配を使用した失敗ラベルでトレーニングされた教師ありの分類器は対比的な説明を提供しますが、検出精度は低くなります。
Google のソリューションは、高度な検出精度と対比的な説明の両方を兼ね備えています。
下の図は、オフィスの換気に使用されている可変風量(VAV)の異常について説明したものです。
異常アラート: デバイスが、午後 12 時 24 分に 1.0 という高い異常スコアを記録しました。
変数アトリビューション: この異常は、2 つの変数に起因しています。異常検出の 43% は加熱水バルブ、41% は給気流量が原因です。
- 対比的な説明: 観測された異常なバルブ設定は 100% オープンですが、最も近い正常ポイントは 6% です。同様に風量も 1,200 立方フィート / 分に設定されていますが、最も近い正常ポイントは 0.5 です。
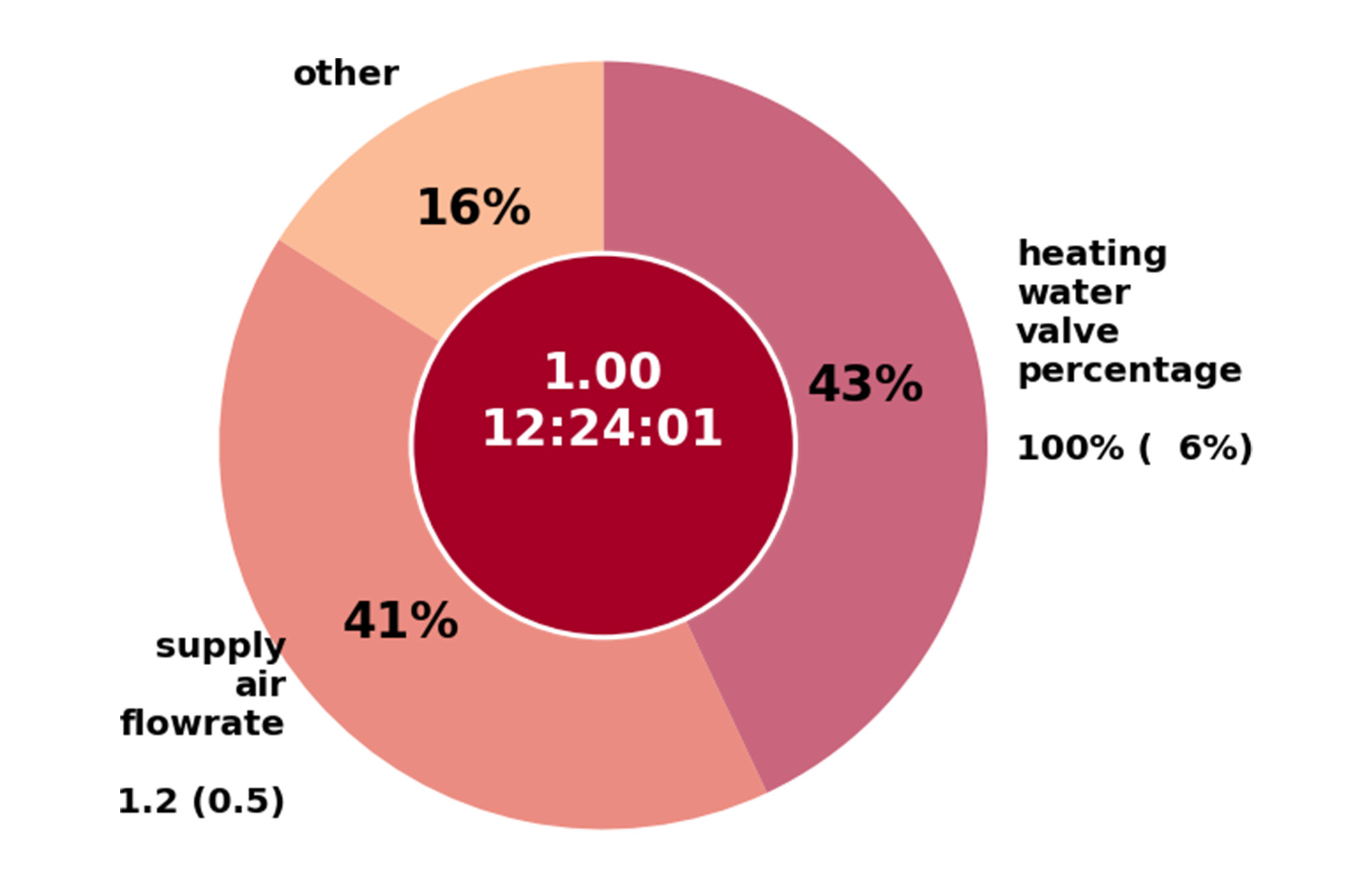
これらの情報を使用して、技術者は医師と同じように症状を評価し、問題を診断し、治療法を処方できます。 ここでは、技術者はこの異常の根本原因は給水の温度不足によって空気が適切に加熱されていないことだと特定し、問題を解決できます。
最適な検出精度の達成
通常のオペレーションでは、変数は多くの場合相関しており、時には非線形になります。簡単な例では、サーモスタットの室温測定値と設定温度は直線的に相関するはずです。しかし、ディーゼル エンジンの場合、油圧、油温、エンジン回転数(RPM)の関係はもっと複雑です。
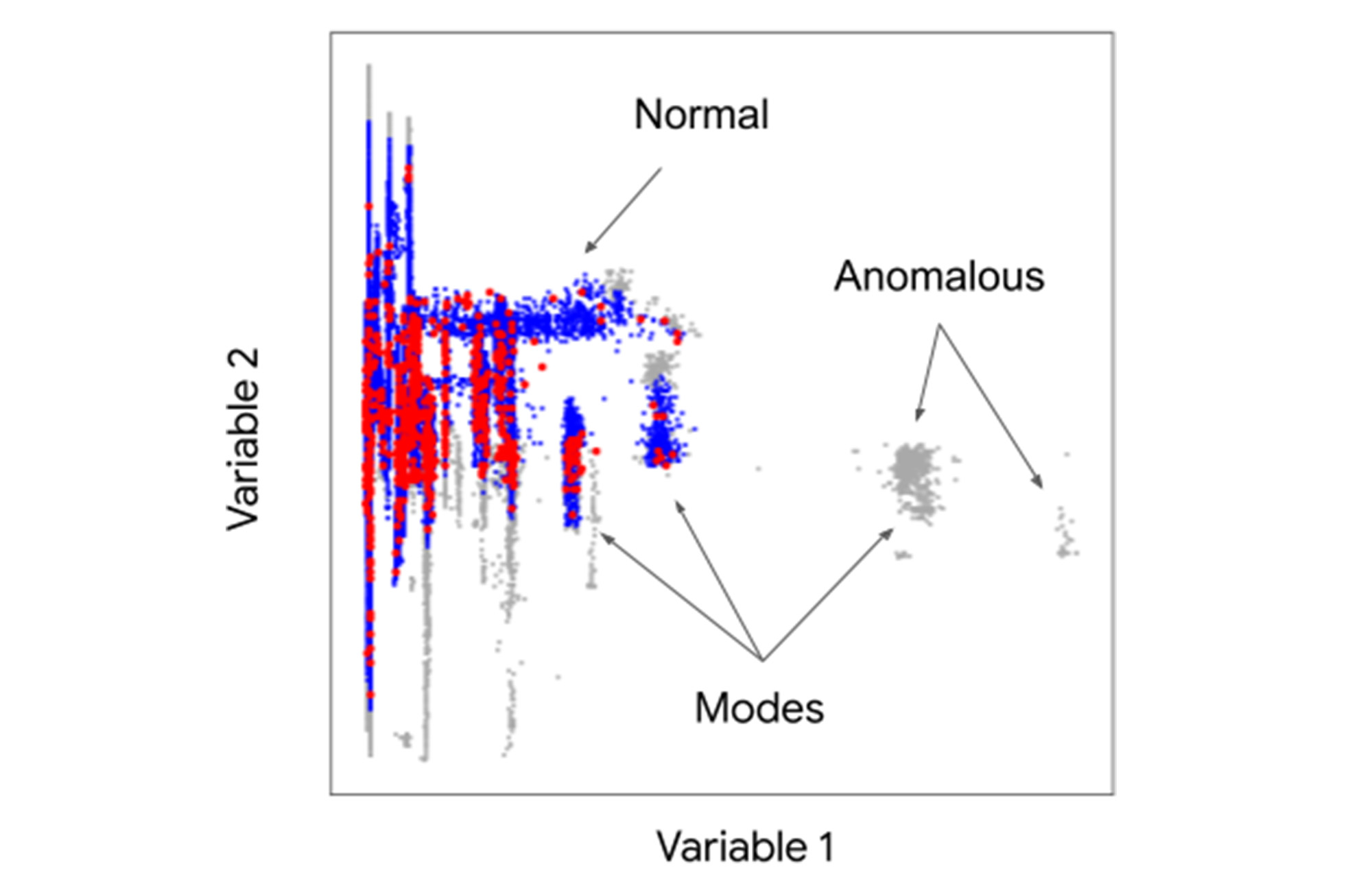
異なるモード(アイドル状態 / アクティブ状態、昼 / 夜、離陸 / 巡航 / 着陸)で動作するデバイスのもう一つの複雑な要因は、通常のオペレーションでは一つ以上の項目で複数のピークがあるマルチモーダルな分布が生成される可能性があることです。下の散布図は、あるデバイスのたった 2 つの変数がいかに複雑な相互作用を生成するかを示しています。青い点は異常検出器が正常と特定したもの、赤い点は対比的な模範ポイントとして選択されたもの、グレーの点は個別の外れ値やモードとして現れる異常領域を表しています。
Google のソリューションでは、ネガティブ サンプリングとディープ ラーニングを組み合わせることで、相関やマルチモーダルな分布に対する感度を使用し、より高い検出精度を実現します。ネガティブ サンプルはラベルのないトレーニング データを補完し、異常なスペースを表します。その後、ディープ ニューラル ネットワークは複雑な相関関係やマルチモーダルな分布を持つデータに対しても、正常領域と異常領域の境界を効率的に判断することを学習します。
大規模なデプロイ
コホートを使用してフリートをスケーリングします。何千台ものデバイスのあるシステムでは通常、1 台の異常検出器では組み合わされたデータ ストリームに対応しきれません。また、デバイスごとに異常検出器を個別に実行するのも効率的ではありません。異常検出の処理を分散させる方法が必要です。モノのインターネット(IoT)のアプリケーションでは、デバイスは通常、カテゴリまたはデバイスタイプに分類されます。たとえば、ビルの空調システムには、エアコン、送風機、給湯設備、換気装置、シェーダーなどのデバイスがあります。同じカテゴリや同じ動作状態のデバイスをコホートにグループ化することで、ピアとの比較が可能になります。
デバイスをコホートに割り当てることで、次の 2 つの重要なメリットを享受できます。
多くの類似デバイスからの履歴が多いほど、統計ベースラインが大きくなるため、決定境界をより最適なものにできます。
異常検出プロセスをコホートごとに起動することで、数百台から数百万台のデバイスまでオンデマンドのスケーリングが可能になります。
デバイスの離脱を自動的に処理します。大量のフリートをモニタリングするときには、常に、変更が生じる可能性があります。古いデバイスの交換や、デバイスタイプ全体の追加や削除を行うこともあります。スケーラビリティのために、この「デバイスの離脱」は自動的に処理される必要があります。コホート割り当てのロジックはユースケースによって異なる傾向がありますが、一般的には、コホート割り当てプロセスでは、各デバイスをコホートに配置するメンバーシップ テーブルを定期的に更新します。
新しいデバイスがコホートに追加されると、適切な異常検出器は、そのデバイスとコホート内の他のすべてのデバイスに対するクエリの実行を開始します。
新しいコホートが作成されると、新しい異常検出処理が開始されます。
同様に、デバイスがコホートから削除されると、異常検出器はそのクエリ構成からデバイスを削除します。
コホートが破棄されると、関連する異常検出プロセスが終了します。
Google 初のスマート ビルディングへの実装。Google は、もともと数百棟の建物の数万台の空調デバイスをモニタリングするために設計された、大規模に動作する説明型異常検出のための汎用パイプラインを開発しました。Google は、機械学習アルゴリズムをオープンソース化し、説明された異常に関するディープ ラーニング アルゴリズムの論文を発表しました。このアルゴリズムは、ネガティブ サンプリングとディープ ラーニングの分類器を組み合わせ、統合勾配を適用して説明を生成し、ベースライン ポイントとして「最も近い正常値」を選択します。変数アトリビューション(「原因」)と最も近い正常ポイントは技術者に異常な症状を指摘するうえでの豊富な対比的説明を提供します。技術者は根本原因について推測し、処理法を選択できます。
機械学習ソリューション
このソリューションにより、Google 内の次のアセットが集約されます。
Google のコーポレート エンジニアリングと研究による、新しい教師なしの異常検出アルゴリズム。
GCP を含む 20 以上の Google プロダクトに実装されている、Google の研究による独自のモデル説明テクノロジー。
Google Cloud Platform(GCP)の機械学習(ML)および ML 運用(MLOps)ツール。
このソリューションの大きな特徴は、マネージド Kubeflow パイプラインと Vertex AI Pipelines を使用した GCP に実装された MLOps パイプラインです。
IT 運用管理の例では、IT インフラストラクチャ上で数千台もの物理的な IT デバイスや仮想インフラストラクチャのコンポーネントやアプリケーションが稼働しています。これらをまとめてコンポーネントと呼んでいます。まず、ディスク クラスタのような同じ固定プロパティを持つ、同等のコンポーネントのセットを特定します。これをコホートと呼んでいます。
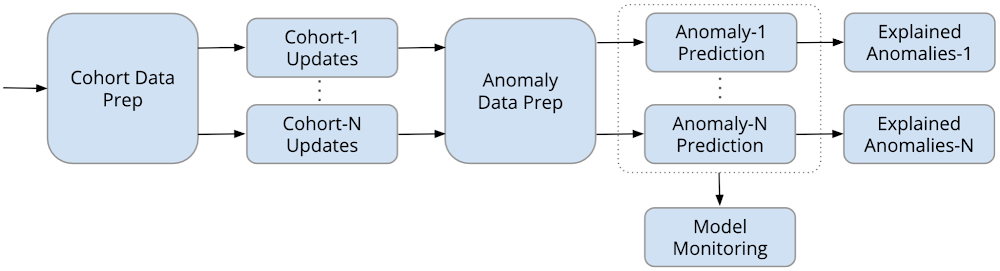
この問題に対する大まかな流れは、動作やデータが類似している同様のコンポーネントであるコホートを特定し、イベントをモニタリングするために各コホート クラスタをモニタリングできるようにします。その後、コホート間のイベントや異常をランク別に並び替えて結果を説明します。下の図は、このプロセスのステップを表したものです。
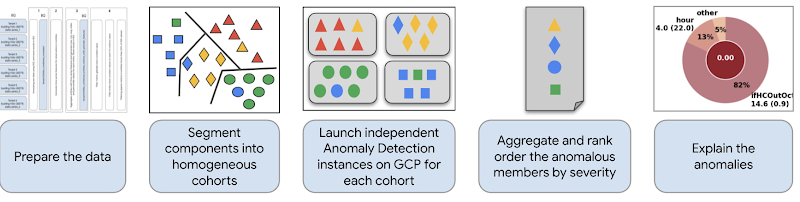
IT 運用管理の例に戻ると、何百台ものデバイスが頻繁に追加および削除されています。このような変化に対応する ML システムには、次のような ML 運用(MLOps)の技術が必要です。
ML パイプラインの実行を自動化して、新しいデータで新しいモデルを再トレーニングし、新しいパターンをキャプチャします。継続的なトレーニングと予測は Kubeflow Pipelines または Vertex AI Pipelines を使用して行われます。
ML パイプライン全体の新しい実装をデプロイするための継続的デリバリー システムを設定します。CI / CD は Cloud Build を使用して実現します。
下の図は、Kubeflow Pipelines と Vertex AI Pipelines を使用して実装されたトレーニング パイプラインを示しています。
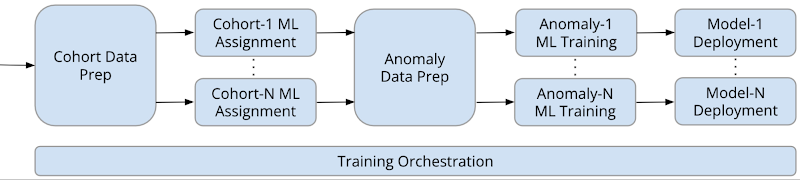
トレーニングおよびデプロイされたモデルを Kubeflow Pipelines と Vertex AI Pipelines を使用した以下の予測パイプラインで使用します。
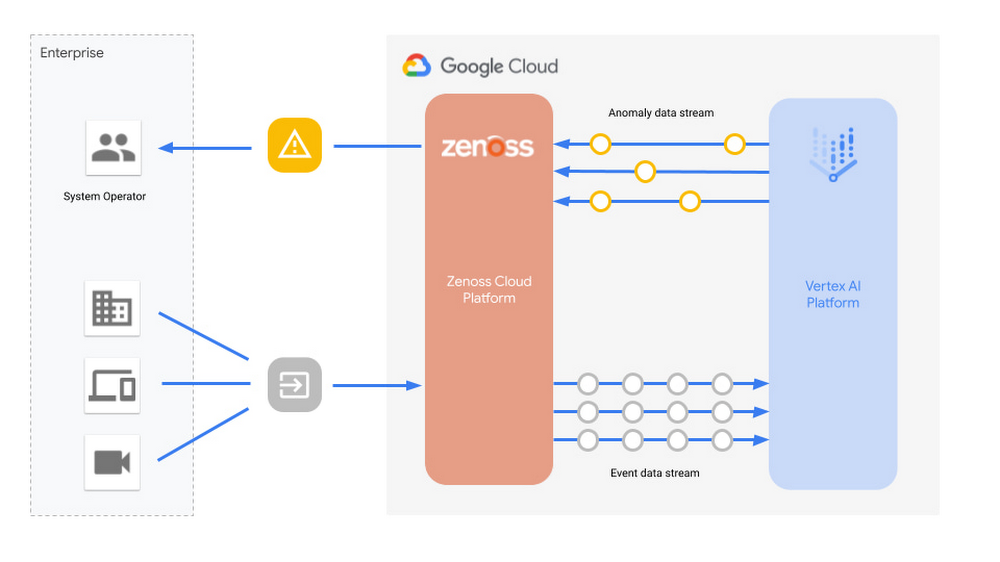
Zenoss による AI を活用したフルスタック モニタリング
すでにさまざまな業界のグローバル企業のお客様が、業界特有の課題を解決するために Google の新しいモニタリング ソリューションを利用しています。
インテリジェント アプリケーションおよびサービス モニタリングにおける Forester のリーダーである Zenoss にとって、最小限のオペレーション オーバーヘッドで非常に高い精度で実行される機械学習ソリューションは AIOps 戦略に不可欠です。AIOps ツールは、IT オペレーションにおける問題解決を加速させるために、大きく分けてデータの収集と分析の 2 つを実行します。IT オペレーション用のアプリケーションやサービス モニタリング ツールのユーザーは、システムを健全に保つために依存しているソリューションに対し、ますます多くの人工知能を期待するようになっています。機械学習を適用してデータを効率的に分析し、問題をトリアージし、さらには人手をかけることなく問題を改善するという見通しが、今、現実のものとなりました。
インフラストラクチャ モニタリング プラットフォームに対する AIOps の需要の高まりに対処するために、Zenoss は Google Cloud の AI チームと連携して ML を異常検出に適用する方法を再定義しました。Google は、大規模オフィスビルの空調制御デバイスの問題の発見と修理に役立つ AI ベースの故障検出ソリューションを開発したスマート ビルディング チームで学んだことを活かしました。また、ML を構築するための Google Cloud サービスを一つにまとめ、UI と API を統一した Vertex AI も活用しました。その結果が Zenoss のプラットフォーム内の分散型ディープ ラーニング ソリューションです。IT インフラストラクチャにおける障害の理解、優先付け、解決をサポートするための説明を提供します。
Zenoss のお客様にとって、このソリューションの主なメリットは、新たにモニタリングされるデバイスが、モデルをトレーニングして正確な予測を行うために数か月分のデータを収集する必要がなくなったことです。Google のオープンソースの機械学習アルゴリズムは、イベントを積極的にモニタリングするためのスケーラブルで教師なしのアプローチを提供し、IT オペレーション担当者が IT サービスを確実にモニタリングするために必要な分析情報を即座に提供します。Google のアルゴリズムを使用して、Zenoss は Google を活用した異常検出を企業のお客様に提供し、ビジネスに不可欠な IT インフラストラクチャを常に利用できる状態に保てるようサポートしています。
Zenoss の CTO の Ani Gujrathi 氏は、「AIOps は多くのお客様にとっての未来です」と述べます。「お客様はオンプレミス、単一のパブリック クラウド、または複数のパブリック クラウドにおける IT オペレーションで、できるだけ人手をかけずにインフラストラクチャの状態に関する信頼性の高い実用的なデータをシームレスかつ安全に入手できることを求めています。実績のある Google の異常検出アルゴリズムを Zenoss のフルスタック モニタリング プラットフォームに統合し、Vertex AI を使用して MLOps を効率化し、Google Cloud とのパートナーシップを拡大することで、お客様の要望を実現できることを嬉しく思います。」
Google Cloud は、機械学習をより利用しやすく便利なものにすること、さまざまな業界の企業のために機械学習の有効性を高めることにコミットしており、これらがすべての取り組みにおける最優先事項です。Google 内の無数の実績ある機械学習ソリューション、Google Cloud の幅広い AI / ML スペシャリスト、Vertex AI 内の統合された機械学習ツールスイートを活用することで、組織はビジネスの変革が可能になります。
Vertex AI による ML モデリングを使い始める準備はできましたか?無料で作成を開始できます。Vertex AI Platform が、企業の ML 投資に対する収益率を高める方法の詳細については、Google にお問い合わせください。謝辞: Google Cloud プリンシパル アーキテクト Micah Knox
- Google Cloud クラウド AI プログラム マネージャー Chanchal Chatterjee
- Google Enterprise AI 担当スタッフ ソフトウェア エンジニア John Sipple



