Vertex AI の評価サービスと LLM Comparator で生成 AI モデルを評価
Jincheol Kim
Solution Lead, Machine Learning
Win Woo
Principal Architect, AI
※この投稿は米国時間 2025 年 3 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
ニーズに適した生成 AI モデルをどのように見極めればよいか、という疑問は常に存在しますが、結局のところ、そのすべてはスマートな評価にかかっています。
この投稿では、Vertex AI の評価サービスと LLM Comparator を使用して、2 つのモデルを直接比較するペアワイズ モデル評価を行う方法を説明します。各ツールの便利な機能、LLM のパフォーマンス評価に役立つ理由、ツールを使って堅牢な評価フレームワークを作成する方法についてもご紹介します。
パフォーマンスを評価するペアワイズ モデル評価
ペアワイズ モデル評価とは、2 つのモデルを直接比較して、特定のタスクにおける相対的なパフォーマンスを評価することです。LLM のペアワイズ モデル評価には、主に次の 3 つのメリットがあります。
-
十分な情報に基づく意思決定: LLM の数と種類が増えるなか、特定のタスクに最適なモデルを慎重に評価し、選択することが大切です。各オプションの長所と短所を考慮することは必須です。
-
「より良い」を定量的に定義: 自然言語テキストや画像などといった生成 AI モデルにより生成されたコンテンツは、通常は構造化されておらず、長文なこともあり、人間の介入なしに自動的に評価することは困難です。ペアワイズは、人間による検査によって、各プロンプトに対して人間の回答に近い「より良い」回答を定義するのに役立ちます。
-
最新のデータに留意: LLM は、以前のバージョンや他の最新モデルと比較して強化されるように、新しいデータで継続的に再トレーニングし、チューニングする必要があります。
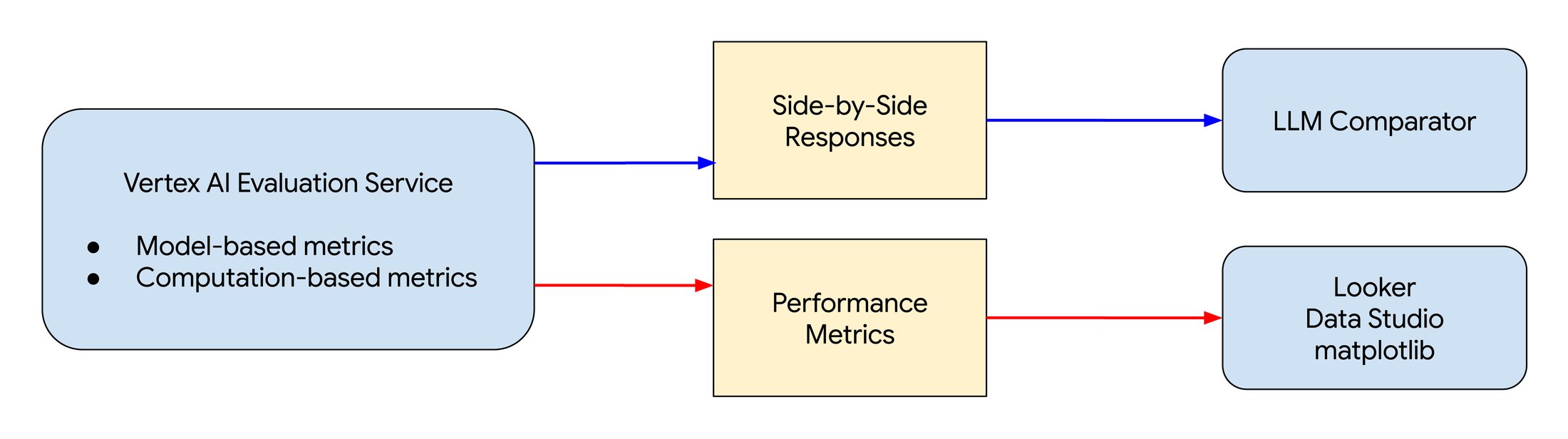
LLM の評価プロセス案。
Vertex AI の評価サービス
Vertex AI の Gen AI Evaluation Service を使用すると、生成モデルまたはアプリケーションを評価し、独自の評価基準に基づいて、独自の判断と照らし合わせて評価結果のベンチマークを実施できます。このサービスには以下のようなメリットがあります。
-
特定のユースケースに適したモデルの選択
-
さまざまなモデル パラメータによるモデル構成の最適化
-
希望する動作や回答を導くプロンプト エンジニアリング
-
LLM をファインチューニングして精度、公平性、安全性を向上させる
-
RAG アーキテクチャの最適化
-
モデルの異なるバージョン間の移行
-
異なる言語間の翻訳品質の管理
-
エージェントの評価
-
画像や動画の評価
また、ポイントワイズ評価とペアワイズ評価の両方に使用できるモデルベースの指標や、入力 / 出力ペアのグラウンド トゥルース データセットを使用した計算ベースの指標もサポートしています。
Vertex AI の評価サービスの使用方法
Vertex AI の評価サービスは、生成 AI モデルを厳密に評価するのに役立ちます。事前構築済みのテンプレートや独自の専門知識を活用してカスタム指標を定義し、特定の目標に対するパフォーマンスを正確に測定できます。標準的な NLP タスクでは、分類に対する F1 スコア、翻訳に対する BLEU、要約に対する ROUGE-L など、計算ベースの指標が提供されます。
モデルを直接比較する場合、ペアワイズ評価により、どちらのモデルのパフォーマンスが高いかを定量化できます。candidate_model_win_rate や baseline_model_win_rate などの指標は自動的に計算され、判定モデルによってスコアリングの決定に関する説明が提供されるため、貴重なインサイトを得られます。また、計算ベースの指標を使用してペアワイズ比較を行い、グラウンド トゥルース データと比較することもできます。
事前構築済みの指標に加え、数式やプロンプトを使用して独自の指標を柔軟に定義し、ユーザー定義の指標のコンテキストに沿って「判定モデル」を補完できます。意味的類似性の評価には、エンベディングベースの指標も使用できます。
Vertex AI Experiments と Metadata は評価サービスとシームレスに統合されており、データセット、結果、モデルを自動的に整理、追跡します。評価ジョブは REST API や Python SDK を使用して簡単に開始でき、結果を Cloud Storage にエクスポートして、より詳細な分析と可視化のために利用できます。
端的にいうと、Vertex AI の評価サービスは、以下を行うための包括的なフレームワークを提供します。
-
モデルのパフォーマンスの定量化: 標準指標とカスタム指標の両方を使用します。
-
モデルの直接比較: ペアワイズ評価と判定モデルのインサイトを使用します。
-
評価のカスタマイズ: 特定のニーズに対応します。
-
ワークフローの合理化: トラッキングの統合と API への容易なアクセスによって実現します。
また、サービスにはガイダンスやテンプレートも用意されており、テンプレートを参照して独自の指標を定義することも、プロンプト エンジニアリングや生成 AI の経験を活かしてゼロから定義することもできます。
LLM Comparator: 人間参加型の LLM 評価のためのオープンソース ツール
LLM Comparator は、Google の PAIR(People + AI Research)が開発した評価ツールであり、現在も進行中の研究プロジェクトです。
LLM Comparator の非常に直感的なインターフェースは、異なるモデルの出力を並べて比較するのに適しており、LLM の自動評価を人間参加型のプロセスで補強するための優れたツールです。たとえば、プロンプトのカテゴリ別にグループ化したモデル A やモデル B の勝率を測定する指標など、さまざまな有益な指標を使用して 2 つの LLM の回答を並べて評価するのに役立つ便利な機能が用意されています。また、Custom Functions という機能を使用して、ユーザー定義の指標でツールを簡単に拡張できます。

Google の PAIR が開発した LLM Comparator のダッシュボードと可視化されたデータ。
モデル A とモデル B のパフォーマンスを、さまざまな指標やプロンプト カテゴリごとに比較でき、結果を [Score Distribution] や [Metrics by Prompt Category] で視覚的に確認できます。さらに、[Rationale Summary] では、評価結果に影響を与える主な要因が視覚的に要約され、あるモデルが別のモデルよりも優れている理由に関するインサイトを得ることができます。

[Rationale Summary] パネルで、一方のモデルの回答の方が優れていると判断された理由を視覚的に確認できます。
LLM Comparator は PyPI で Python パッケージとして提供されており、ローカル環境にインストールできます。Vertex AI の評価サービスでのペアワイズ評価の結果は、提供されているライブラリを使用して LLM Comparator に読み込むこともできます。自動評価結果を JSON ファイルに変換する方法の詳細については、LLM Comparator の JSON データ形式とスキーマをご覧ください。
Rationale Cluster による可視化や Custom Functions などの機能を備えた LLM Comparator は、全体的な品質を確保するために人間参加型のプロセスを必要とする LLM 評価の最終段階において、非常に有用なツールとなります。
現場からのフィードバック: LLM Comparator が Vertex AI の評価サービスに付加価値をもたらす
LLM Comparator は、すぐに使える便利な可視化ツールと自動的に計算されるパフォーマンス指標で人間の評価者をサポートし、ML エンジニアが独自の可視化ツールや品質モニタリング ツールを開発する手間を省きます。LLM Comparator では JSON データ形式と JSON スキーマが使われているため、大規模な開発作業なしで Vertex AI の評価サービスと LLM Comparator を簡単に統合できます。
Google のチームメンバーからは、LLM Comparator で最も役立つ機能として「Rationale Summary」による可視化が挙げられています。「Rationale Summary」は説明可能な AI(XAI)ツールの一種と考えることができ、2 つのモデルのうち、なぜ特定のモデルが判定モデルの観点で優れているのかを理解するのに非常に役立ちます。「Rationale Summary」での可視化のもう一つの重要な側面は、特定の言語モデルの動作が他のモデルとどのように異なるかを理解できることです。これは、モデルが特定のタスクにより適している理由を推測するうえで、非常に重要なサポートとなる場合があります。
LLM Comparator を使用できるのは、モデルのペアワイズ評価のみという制限があり、複数のモデルを同時に評価することはできません。ただし、LLM Comparator には比較評価を行うための基本的なコンポーネントがすでに備わっており、これを複数のモデルを同時に評価する機能に拡張することは、技術的に大きな問題ではないかもしれません。これは、LLM Comparator プロジェクトに貢献する素晴らしいプロジェクトとなるでしょう。
まとめ
この記事では、PAIR によるオープンソース LLM 評価ツールである LLM Comparator と Vertex AI を使用して、LLM の評価プロセスを整理する方法について説明しました。Vertex AI の評価サービスと LLM Comparator を組み合わせることで、Google Cloud でのさまざまな LLM のパフォーマンスを体系的に評価、比較する半自動化されたアプローチを紹介しました。今すぐ Vertex AI の評価サービスをお試しください。
このブログ投稿と全体的なベスト プラクティスに関するガイダンスに協力してくれた Rajesh Thallam、Skander Hannachi、Applied AI エンジニアリング チームに感謝します。また、このブログ投稿と技術的なガイダンスに協力してくれた Anant Nawalgaria にも感謝します。
-ML ソリューション リード Jincheol Kim
-AI プリンシパル アーキテクト Win Woo




