Neo4j と Google Cloud Vertex AI でよりスマートな AI 向けのグラフを使用する
Google Cloud Japan Team
※この投稿は米国時間 2022 年 1 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
このブログ投稿では、ML 開発プラットフォーム Google Cloud Vertex AI とグラフ データベース Neo4j の 2 つのテクノロジーを一緒に使用する方法について説明します。これらのテクノロジーを組み合わせて使用することで、グラフベースの機械学習モデルを構築し、デプロイできます。
このブログ投稿の基盤となるコードは、こちらのノートブックで参照できます。
データ サイエンスにグラフを使用するべき理由
ビジネス上の重大な問題の多くでは、グラフとして表現できるデータが使用されています。グラフはデータ構造で、データそのものと同様にデータポイント間の関係を記述します。
簡単に言うと、グラフは名詞と動詞の関係に似ています。ノード(名詞)は人々、場所、品物などの「もの」を指します。関係(動詞)は、それらがつながる方法です。人々は互いに知り合い、品物はさまざまな場所に送られます。これらの関係のシグナルは強力です。
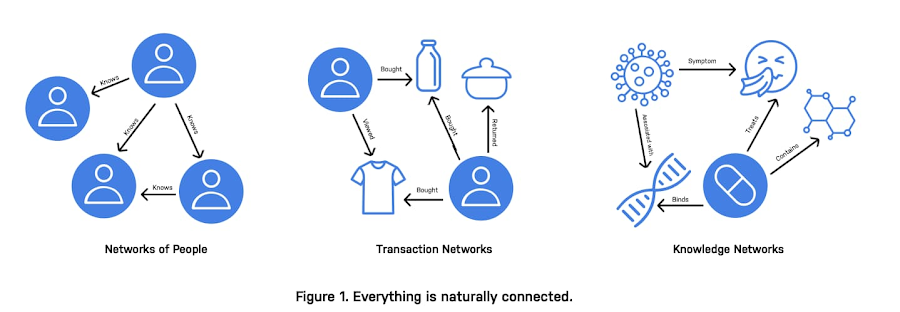
グラフデータは扱うには巨大で乱雑な場合があり、従来の機械学習のタスクで使用するのはほぼ不可能です。
Google Cloud と Neo4j は、グラフデータを最大限に活用するためのスケーラブルでインテリジェントなツールを提供します。Neo4j グラフデータ サイエンスと Google Cloud Vertex AI を使用すると、グラフデータ上に AI モデルを迅速かつ簡単に構築できます。
データセット - PaySim を使用して不正行為を特定する
グラフベースの機械学習には数多くのアプリケーションがあります。一般的なアプリケーションには、さまざまな形態の不正行為に対処するものがあります。クレジット カード会社ではなりすましの取引の特定、保険会社では不正な申請への対処、金融機関では盗難された認証情報かどうかの確認に活用されています。
統計情報と機械学習は、数十年前から不正行為に対処するために使用されてきました。一般的な方法は、支払いやユーザーの個別の機能の分類モデルを構築することです。たとえば、データ サイエンティストは、取引金額、取引日時、取引元口座、取引先口座、取引結果残高に基づいて取引が不正かどうかを予測する XGBoost モデルをトレーニングできます。
これらのモデルは多くの不正行為を見逃します。不正な行為者のネットワークで取引が行われることで、不正利用者は単一の取引しか監視されないチェックをすり抜けられます。成功するモデルには、不正な取引、正当な取引、ユーザー間の関係の理解が必要とされます。
このような問題には、グラフの手法が最適です。この例では、この状況でグラフがどのように適用されるかを説明します。その後、Neo4J と Vertex AI を使用して完全なモデルをトレーニングするエンドツーエンドのパイプラインを構築する方法を紹介します。この例では、グラフ機能を含む Kaggle の PaySim データセットでのバリアントを使用します。
Neo4j へのデータの読み込み
まず、データセットを Neo4j に読み込む必要があります。この例では、AuraDS を使用しています。AuraDS は、GCP 上のマネージド サービスとして実行する Neo4j グラフ データベースと Neo4j グラフデータ サイエンスを提供します。現在は限定プレビュー中で、こちらから登録できます。
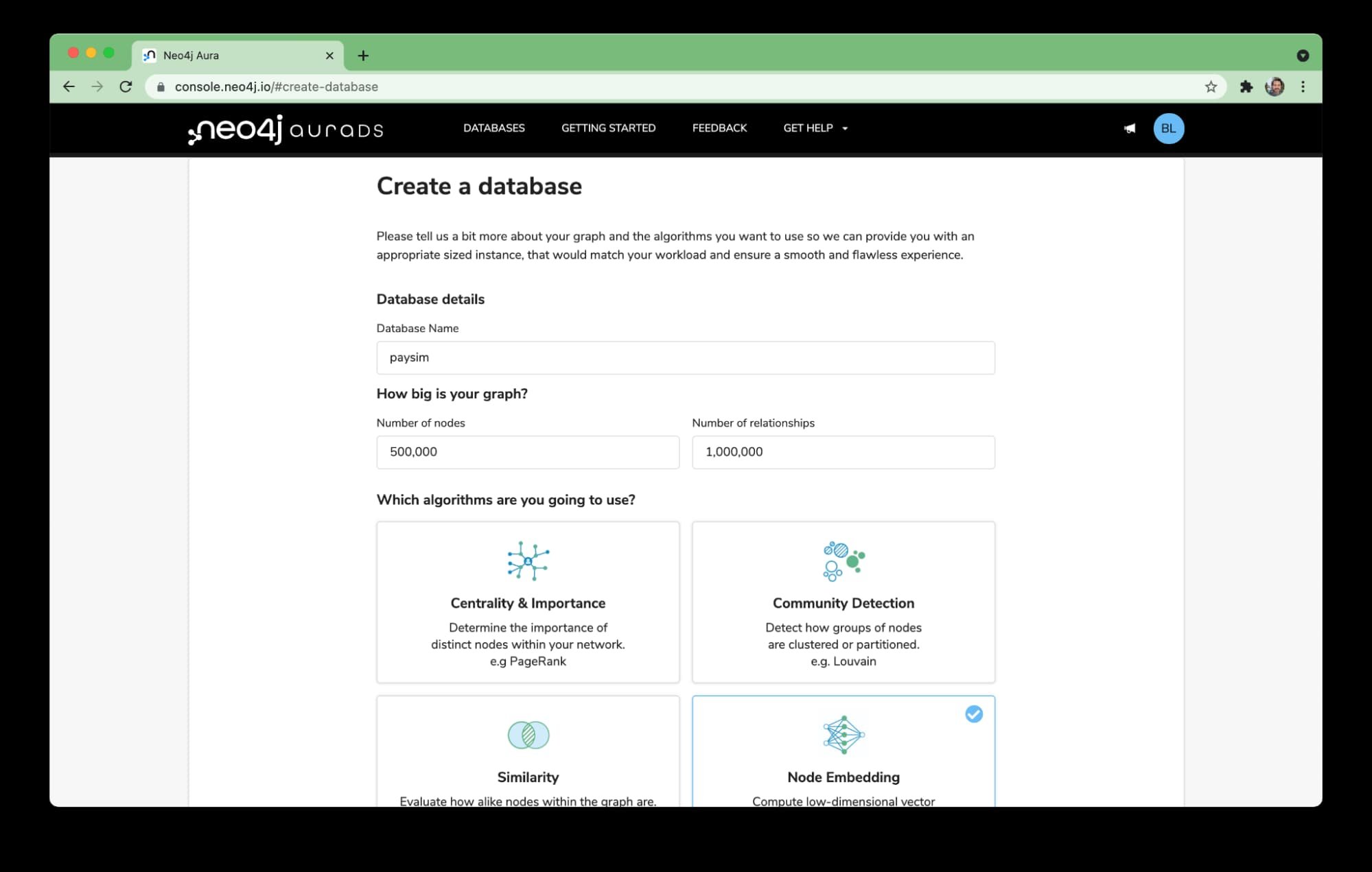
AuraDS はフルマネージド サービスであり、GCP に慣れるためのおすすめの方法です。Paysim データで実行中のデータベースを設定するには、いくつかの画面をクリックして、データベースのダンプファイルを読み込む必要があります。
データが読み込まれると、さまざまな方法により Neo4j でそのデータを使用できます。その一つはノートブックの Python API を使用してクエリを実行することです。
たとえば、クエリを実行してノードラベルを表示できます。
ノートブックでは、これは次のようになります。
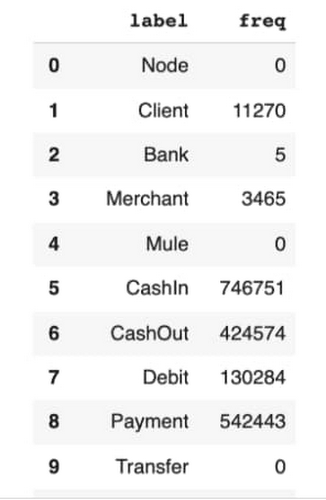
ノートブックは、関係タイプやトランザクション タイプも含む、他のクエリの例を示しています。これらはこちらで確認できます。
Neo4j を使用してエンベディングを生成する
データを試したら、次の一般的なステップは Neo4j グラフデータ サイエンスの一部であるアルゴリズムを使用して、複雑で高次元のグラフデータを表形式の機械学習アルゴリズムが使用できる値にエンコードする機能を組み込むことです。
多くのユーザーは、基本的なグラフ アルゴリズムから開始してパターンを識別します。脆弱な接続コンポーネントを確認して、共通ログインを共有するアカウント所有者の分断されたコミュニティを検出できます。Louvain メソッドはマネー ロンダリングを行う不正利用者のグループを見つけるのに便利です。どのアカウントが最も重要かを把握するには、ページのランクを使用できます。しかし、これらの手法を使用するにあたり、探しているパターンを正確に理解している必要があります。
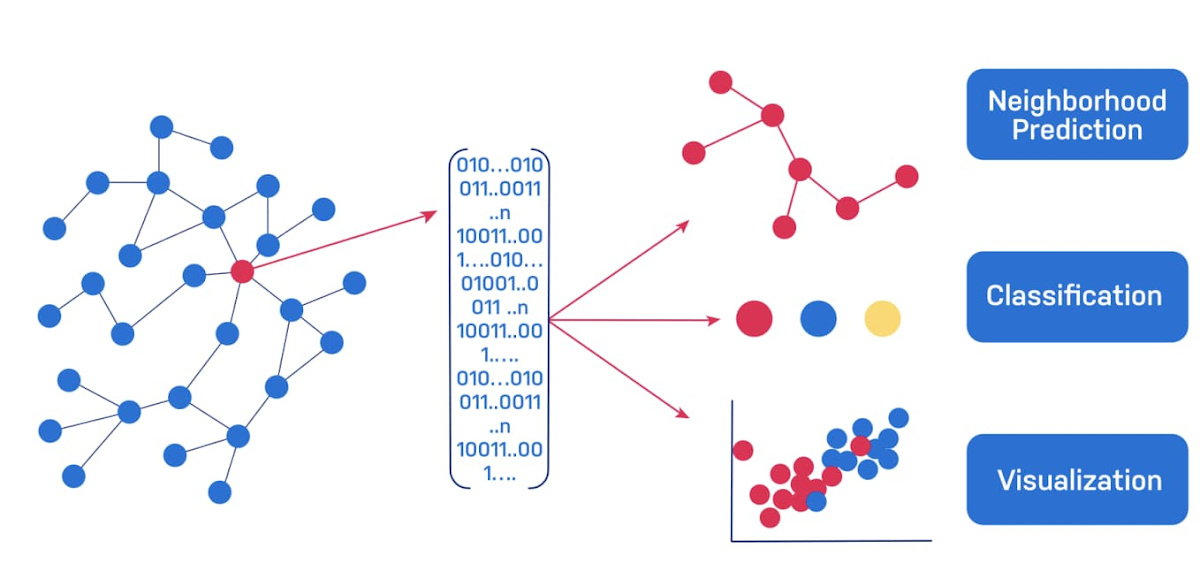
別のアプローチとして、Neo4j を使用してグラフ エンベディングを生成することもできます。グラフ エンベディングは、グラフ内の複雑なトポロジの情報を固定長のベクトルに分類します。グラフ内の関連ノードには近隣のベクトルが含まれます。グラフのトポロジ(不正利用者がやり取りする相手や不正利用者がどのような行動を取るかなど)が重要なシグナルである場合、エンベディングは既知の不正利用者に対する類似のエンベディングがあるため、以前検出できなかった不正利用者を識別できるようにそのシグナルをキャプチャします。
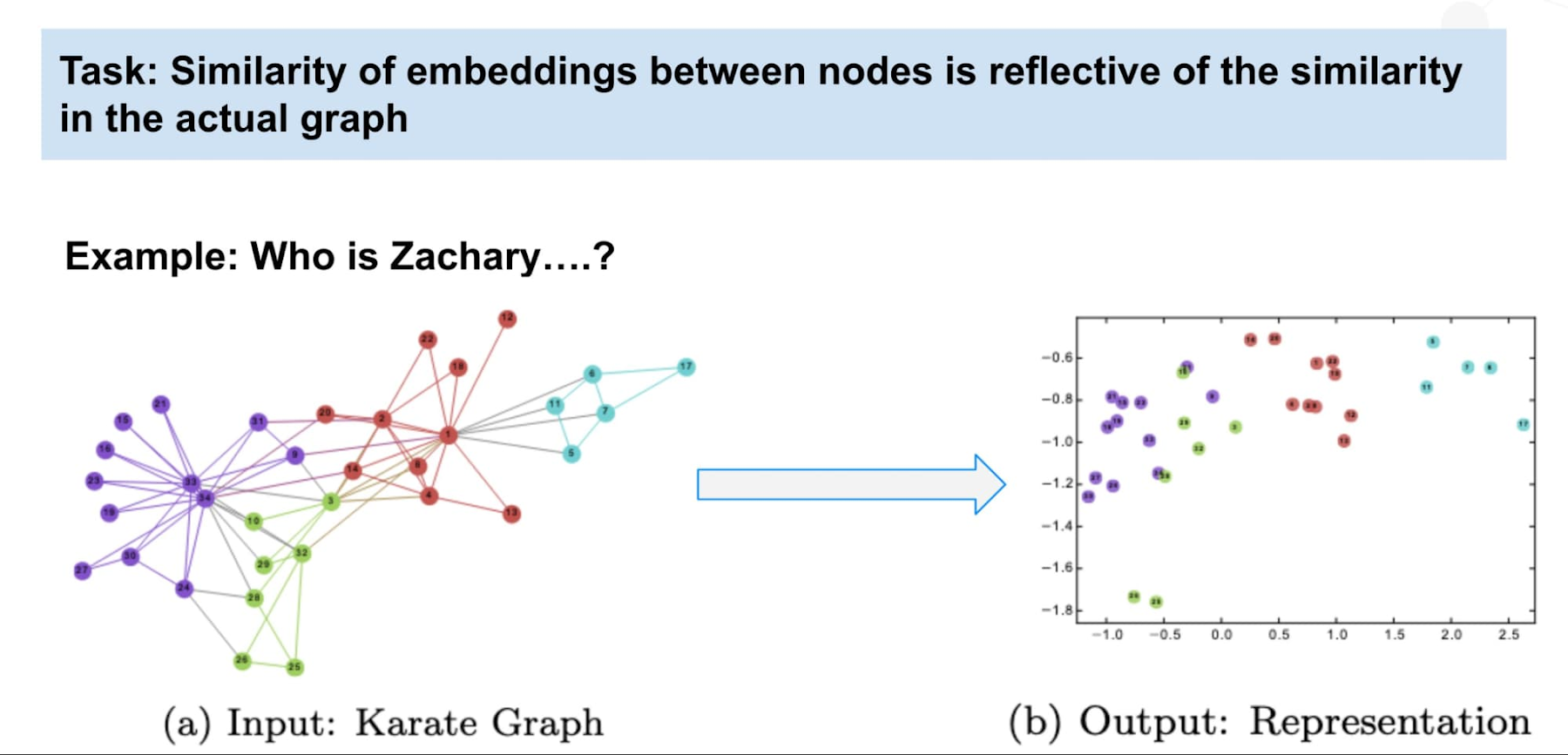
エンベディングを独自に利用する手法もあります。たとえば、t-sne プロットを使用して視覚的にクラスタを検出したり、未加工の類似スコアを計算したりできます。エンベディングと Google Cloud Vertex AI を組み合わせて管理されたモデルをトレーニングすることで、魔法のようなことが本当に起こります。
PaySim の例では次の呼び出しでグラフ エンベディングを作成できます。
これにより、Fast Random Projection アルゴリズムを使用して 16 次元のグラフ エンベディングを作成します。その便利な機能の一つに、nodeSelfInfluence パラメータがあります。このパラメータは、グラフの遠方にあるノードがエンベディングに与える影響の調整に役立ちます。
エンベディングが計算されたので、それを pandas データフレームへダンプし、CSV に書き込み、Google Cloud の Vertex AI が連携できる Cloud Storage バケットに push できるようになりました。前回同様、これらの手順はこちらのノートブックで詳しく説明しています。
Vertex AI を使用した機械学習
グラフのダイナミクスをベクトルにエンコードしたので、Google Cloud の Vertex AI 内の表形式メソッドを使用して機械学習モデルをトレーニングできます。
まず、Cloud Storage バケットからデータを pull し、そのデータを使用して Vertex AI 内にデータセットを作成します。Python の呼び出しは次のようになります。
データセットが作成されたので、そのデータセット上でモデルをトレーニングできます。その Python の呼び出しは次のようになります。
その呼び出し結果をノートブックに表示できます。または、GCP コンソールにログインして、結果を Vertex AI の GUI に表示できます。
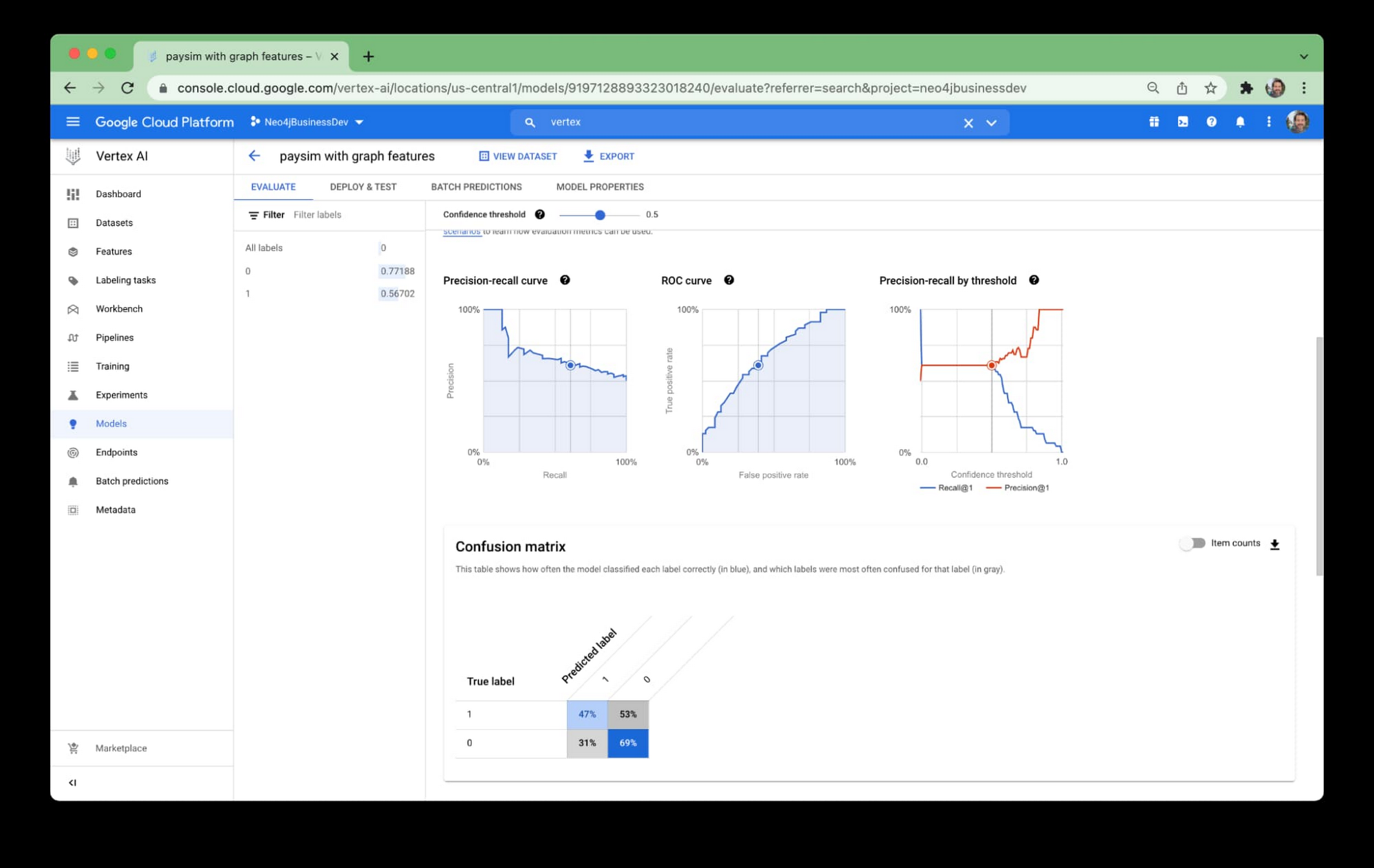
コンソール ビューには ROC 曲線や混同行列などが含まれるので便利です。いずれも、モデルがどのように実行されるかを理解するのに役立ちます。
Vertex AI は、トレーニング済みモデルをデプロイするための有用なツールも提供しています。データセットは Vertex AI Feature Store に読み込むことができます。その後、エンドポイントをデプロイできます。新しい予測はそのエンドポイントを呼び出すことで計算できます。その詳細については、こちらのノートブックをご確認ください。
今後の作業
ノートブックに取り組むことで、この分野でできる潜在的な作業が膨大にあることがすぐに判明しました。グラフを使用した機械学習は、特に表形式データの手法の研究と比べると、かなり新しい分野です。
今後の作業で追究していく具体的な分野には以下が含まれます。
改善されたデータセット - データのプライバシー上の理由で、不正なデータセットを一般に公開することは非常に困難です。そこで、この例で PaySim データセットを使用することにしたのです。それが合成データセットです。データセットとデータセットを作成する生成ツールの両方を調査したところ、データにはほとんど情報がないようです。実際のデータセットならば、もっと確認しやすい構造になっているはずです。
今後の作業では、SEC EDGAR Form 4 トランザクションのグラフを詳しく見ていきます。これらのフォームは上場企業の役員が行う取引を示します。これらの役員の多くは複数の企業で役員を務めているため、かなり興味深いグラフになることが予想されます。2022 年には、Neo4j と Vertex AI を使用して、参加者がこのデータを一緒に確認できるワークショップを計画しています。Google BigQuery にデータを pull するローダはすでにこちらにあります。
ブーストとエンベディング - Fast Random Projection のようなグラフ エンベディングでは、各表形式のデータポイントにサブグラフのコピーが生じるため、データが重複します。XGBoost やその他のブースト メソッドでも、結果を改善させるためにデータが重複します。Vertex AI は XGBoost を使用しています。その結果、この例のモデルで過剰なデータの重複が発生する可能性が高くなります。ニューラル ネットワークなど、他の機械学習メソッドを使用する方が優れた結果を得られる可能性ははるかに高いと考えられます。
グラフ機能 - この例では、エンベディングを使用してグラフ機能を自動的に生成しました。新しいグラフ機能を手動で組み込むことも可能です。これら 2 つのアプローチを組み合わせることで、より充実した機能を実現することができるでしょう。
次のステップ
このブログ投稿を読んで興味を持ち、詳細を希望される方は、こちらで AuraDS のプレビュー版にご登録ください。Vertex AI の詳細はこちらでご確認ください。作業を行ったノートブックはこちらをご覧ください。フォークして、必要に応じて変更していただければ幸いです。pull リクエストはいつでもお待ちしております。
- Neo4j グローバル クラウド チャネル アーキテクチャ担当ディレクター Ben Lackey


