MCP ツールボックスと ADK を使用して Looker を Gemini Enterprise に数分で接続する方法
Rob Carr
Enterprise Customer Engineer
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try now※この投稿は米国時間 2025 年 12 月 13 日に、Google Cloud blog に投稿されたものの抄訳です。
AI による回答の質は、基盤となるデータの整合性に左右されることは周知のとおりです。しかし、AI モデルは強力であるものの、そのままではビジネス コンテキストが欠けています。自然言語を使用してデータについて質問する組織が増えるにつれ、ビジネスにおけるメジャーとディメンションを統合し、会社全体で一貫性を確保することがますます重要になっています。信頼できる AI を実現するには、ビジネス指標の信頼できる唯一の情報源として機能するセマンティック レイヤが必要です。
しかし、エンドユーザーがそのデータにアクセスして活用できるようにするにはどうすればよいでしょうか。Looker の Model Context Protocol(MCP)サーバーの最近の導入を基に、このブログでは、データベース向け MCP ツールボックスを介して Looker に接続され、Gemini Enterprise 内で公開される Agent Development Kit(ADK)エージェントを作成するプロセスについて説明します。さあ始めましょう。
ステップ 1 - MCP ツールボックスで Looker との統合を設定する
データベース向け MCP ツールボックスは、ツールセットをホストして管理する中央のオープンソース サーバーです。これにより、エージェント アプリケーションはプラットフォームを直接操作することなく Looker の機能を活用できます。エージェントは、ツールロジックと認証を直接管理するのではなく、MCP クライアントとして機能し、ツールボックスにツールをリクエストします。MCP ツールボックスは、Looker への安全な接続、認証、クエリの実行などの基本的な複雑さをすべて処理します。
データベース向け MCP ツールボックスは、Looker の事前構築済みツールセットをネイティブにサポートします。これらのツールにアクセスする手順は次のとおりです。
Cloud Shell に接続します。次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
mcp-toolbox という名前のフォルダを作成します。
以下のコマンドで mcp-toolbox フォルダに移動します。
以下のスクリプトを使用して、データベース向け MCP ツールボックスのバイナリ バージョンをインストールします。このコマンドは Linux 用です。Macintosh または Windows で実行する場合は、正しいバイナリをダウンロードしてください。オペレーティング システムとアーキテクチャのリリース ページを確認し、正しいバイナリをダウンロードします。
ツールボックスを Cloud Run にデプロイする
次に、MCP ツールボックスを実行する必要があります。最も簡単な方法は、Google Cloud のフルマネージド コンテナ アプリケーション プラットフォームである Cloud Run です。手順は次のとおりです。
必要に応じて、関連する API を有効にします。
サービス アカウントを作成し、必要なロールを割り当てます。
クライアント ID とシークレットの取得については、ドキュメントをご覧ください。
deploy.env ファイルを作成します。
ツールボックス構成をイメージ変数にエクスポートします。
MCP ツールボックスを Cloud Run にデプロイします。
Cloud Run で未認証を許可するかどうかを尋ねられたら、[いいえ] を選択します。
Allow Unauthenticated: N
ステップ 2: ADK エージェントをエージェント エンジンにデプロイする
次に、AI エージェントの開発とデプロイ用に設計された、柔軟性の高いモジュール型のフレームワークである Agent Development Kit(ADK)を設定する必要があります。ADK は、エージェント開発をソフトウェア開発のように感じられるよう設計されており、デベロッパーは単純なタスクから複雑なワークフローまで、幅広いエージェント アーキテクチャを簡単に作成、デプロイ、オーケストレートできます。ADK は Gemini と Google エコシステム向けに最適化されていますが、モデルにもデプロイにも依存せず、他のフレームワークとの互換性を考慮して構築されています。
Vertex AI Platform の一部である Vertex AI Agent Engine は、開発者が本番環境で AI エージェントをデプロイ、管理、スケーリングできるようにする一連のサービスです。本番環境でエージェントをスケーリングするためのインフラストラクチャの処理は Agent Engine が行うため、開発者はアプリケーションの作成に注力できます。
Cloud Shell で新しいターミナルタブを開き、次のように my-agents という名前のフォルダを作成します。また、my-agents フォルダに移動する必要があります。
次に、venv を使用して、仮想 Python 環境を作成します。
仮想環境をアクティブにします。
ADK とデータベース向け MCP ツールボックスのパッケージを langchain の依存関係とともにインストールします。
最初のエージェント アプリケーションを作成
これで、adk を使用して、スキャフォールディングを作成する準備が整いました。ここには、adk create コマンドとアプリ名 looker_app を介した、Looker エージェント アプリケーションのフォルダ、環境、基本ファイルが含まれます。
手順に沿って、以下を選択します。
-
ルート エージェントのモデルを選択するための Gemini モデル
-
バックエンド用の Vertex AI
-
デフォルトの Google プロジェクト ID とリージョン
エージェントのデフォルト テンプレートと必要なファイルが作成されたフォルダを確認します。
まず、.env ファイルです。
これらの値は、Google Cloud プロジェクト ID とロケーションのそれぞれの値とともに Vertex AI 経由で Gemini を使用することを示しています。
次に、__init__.py ファイルがあります。このファイルはフォルダをモジュールとしてマークし、agent.py ファイルからエージェントをインポートする単一のステートメントを含んでいます。
最後に、agent.py ファイルを見てみましょう。内容は、以下の例のように編集できます。
ここでハイライト表示されている Cloud Run の URL を挿入します(URL にプロジェクト番号が含まれているものではありません)。

必要に応じて、Cloud Storage バケットを作成します。
[my-agents] ディレクトリにいることを確認します。使用する Cloud Storage バケットで BUCKET_NAME を更新します。
注意事項: Cloud Run の起動元ロールをデフォルトのエージェント エンジン サービス アカウント(service-PROJECT_NUMBER@gcp-sa-aiplatform-re.iam.gserviceaccount.com)に付与してください。
ステップ 3: Gemini Enterprise に接続する
次に、Gemini Enterprise アプリを作成します(手順はこちら)。
以下のコマンドを、GCP プロジェクト番号、上記の「deploy agent_engine」コマンドの出力である推論エンジン リソース名、Gemini Enterprise アプリ インターフェースの Gemini Enterprise エージェント ID を使用して実行します。
これで、Looker のデータが Gemini Enterprise アプリ内で利用できるようになります。
この機能にアクセスできない場合は、Google Cloud のアカウント担当者にお問い合わせください。
ビジネスデータのクエリをより簡単に
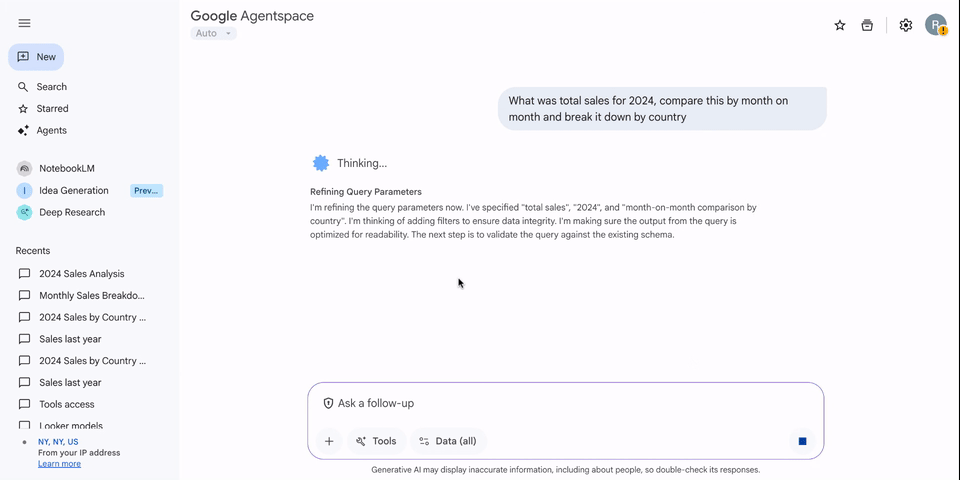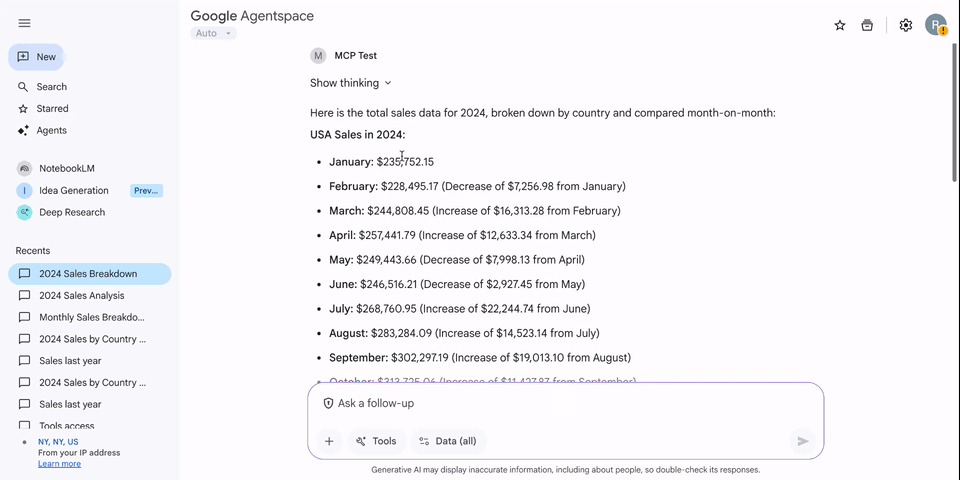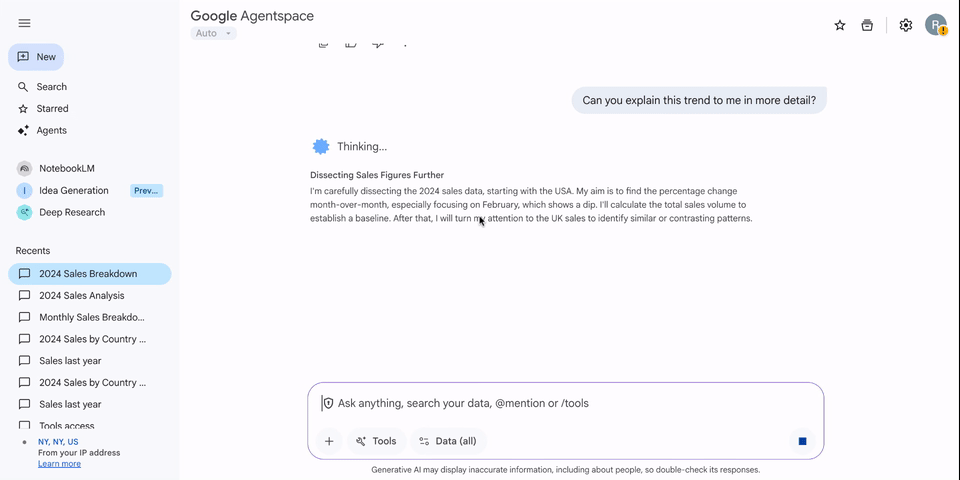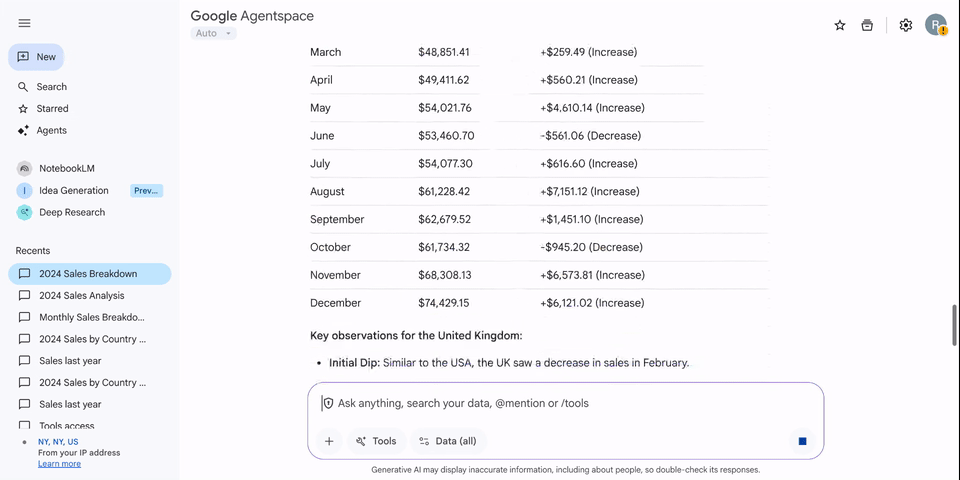
ADK と MCP ツールボックスを介して Looker のセマンティック レイヤを Vertex AI エージェント サービスに接続することは、データ アクセシビリティにとって大きなメリットです。信頼できる Looker モデルと Explore を Gemini Enterprise で公開することで、エンドユーザーは自然言語を使用して複雑なビジネスデータをクエリできるようになります。この統合により、データの分析情報と即時のアクションの間のギャップが解消され、組織のセマンティック レイヤが単なる受動的なレポートのソースではなく、アクティブで会話型の意思決定を促進するアセットになります。
使用を開始するには、GitHub のデータベース向け MCP ツールボックス に接続して Looker との統合を設定します。
-エンタープライズ カスタマー エンジニア、Rob Carr

