Use graphs for smarter AI with Neo4j and Google Cloud Vertex AI
Ben Lackey
Director, Global Cloud Channel Architecture at Neo4j
In this blog post, we’re going to show you how to use two technologies together: Google Cloud Vertex AI, an ML development platform, and Neo4j, a graph database. Together these technologies can be used to build and deploy graph-based machine learning models.
The code underlying this blog post is available in a notebook here.
Why should you use graphs for data science?
Many critical business problems use data that can be expressed as graphs. Graphs are data structures that describe the relationships between data points as much as the data themselves.
An easy way to think about graphs is as analogous to the relationship between nouns and verbs. Nodes, or the nouns, are things such as people, places, and items. Relationships, or the verbs, are how they’re connected. People know each other and items are sent to places. The signal in those relationships is powerful.
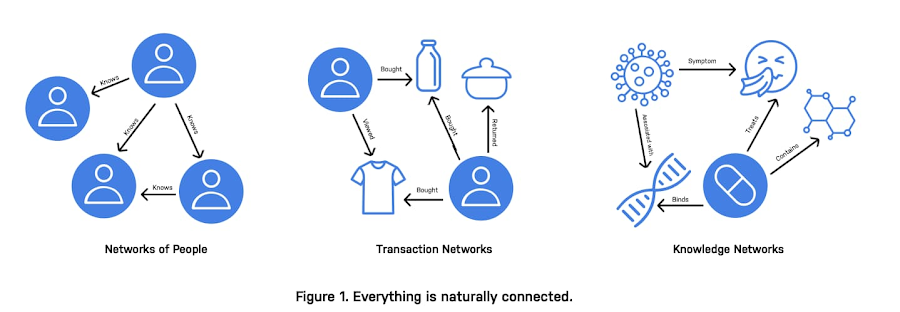
Graph data can be huge and messy to deal with. It is nearly impossible to use in traditional machine learning tasks.
Google Cloud and Neo4j offer scalable, intelligent tools for making the most of graph data. Neo4j Graph Data Science and Google Cloud Vertex AI make building AI models on top of graph data fast and easy.
Dataset - Identify Fraud with PaySim
Graph based machine learning has numerous applications. One common application is combating fraud in many forms. Credit card companies identify fake transactions, insurers face false claims and lenders look out for stolen credentials.
Statistics and machine learning have been used to fight fraud for decades. A common approach is to build a classification model on individual features of a payment and users. For example, data scientists might train an XGBoost model to predict if a transaction is fraudulent using the amount of transaction, its date and time, origin account, target accounts and resulting balances.
These models miss a lot of fraud. By channeling transactions through a network of fraudulent actors, fraudsters can beat checks that look only at a single transaction. A successful model needs to understand the relationships between fraudulent transactions, legitimate transactions and actors.
Graph techniques are perfect for these kinds of problems. In this example, we'll show you how graphs apply in this situation. Then, we’ll show you how to construct an end-to-end pipeline training a complete model using Neo4J and Vertex AI. For this example, we’re using a variation on the PaySim dataset from Kaggle that includes graph features.
Loading Data into Neo4j
First off, we need to load the dataset into Neo4j. For this example, we’re using AuraDS. AuraDS offers Neo4j Graph Database and Neo4j Graph Data Science running as a managed service on top of GCP. It’s currently in a limited preview that you can sign up for here.
AuraDS is a great way to get started on GCP because the service is fully managed. To set up a running database with the Paysim data, all we need to do is click through a few screens and load the database dump file.
Once the data is loaded, there are many ways to explore it with Neo4j. One is to use the Python API in a notebook to run queries.
For instance, we can see the node labels by running the query:
In our notebook, this gives us the following:
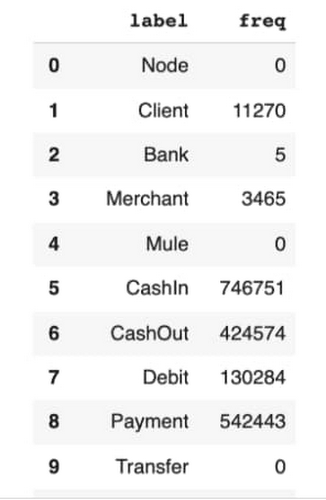
The notebook gives examples of other queries including relationship types and transaction types as well. You can explore those yourself here.
Generating Embeddings with Neo4j
After you’ve explored your data set, a common next step is to use the algorithms that are part of Neo4j Graph Data Science to engineer features that encode complex, high dimensional graph data into values that tabular machine learning algorithms can use.
Many users start with basic graph algorithms to identify patterns. You can look at weakly connected components to find disjointed communities of account holders sharing common logins. Louvain methods are useful to find rings of fraudsters laundering money. Page rank can be used to figure out which accounts are most important. However, these techniques require you to know exactly the pattern you’re looking for.
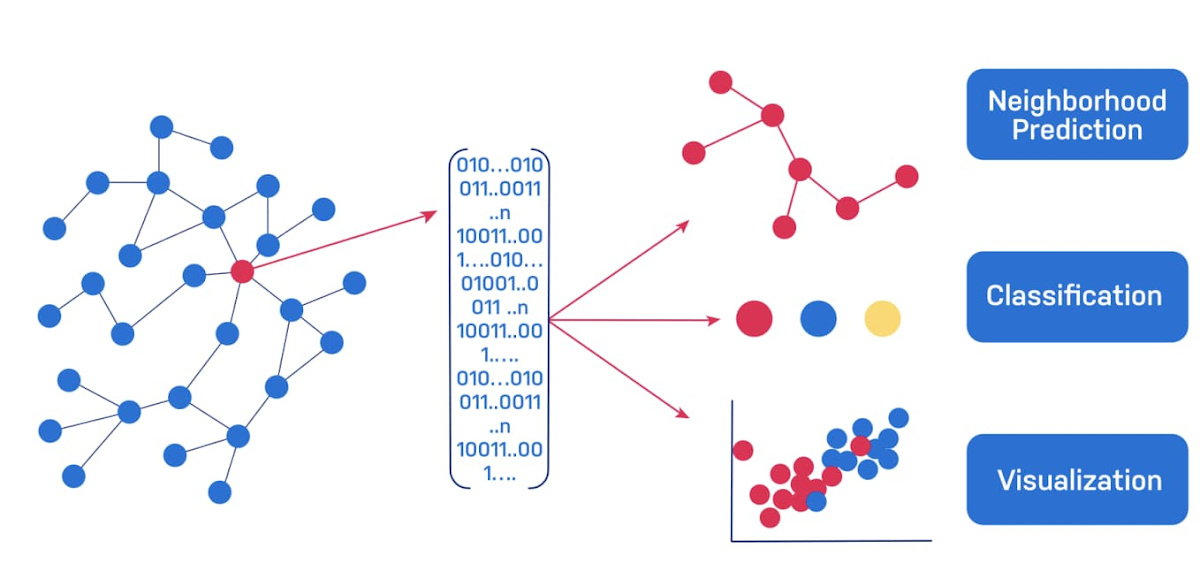
A different approach is to use Neo4j to generate graph embeddings. Graph embeddings boil down complex topological information in your graph into a fixed length vector where related nodes in the graph have proximal vectors. If graph topology, for example who fraudsters interact with and how they behave, is an important signal, the embeddings will capture that so that previously undetectable fraudsters can be identified because they have similar embeddings to known fraudsters.
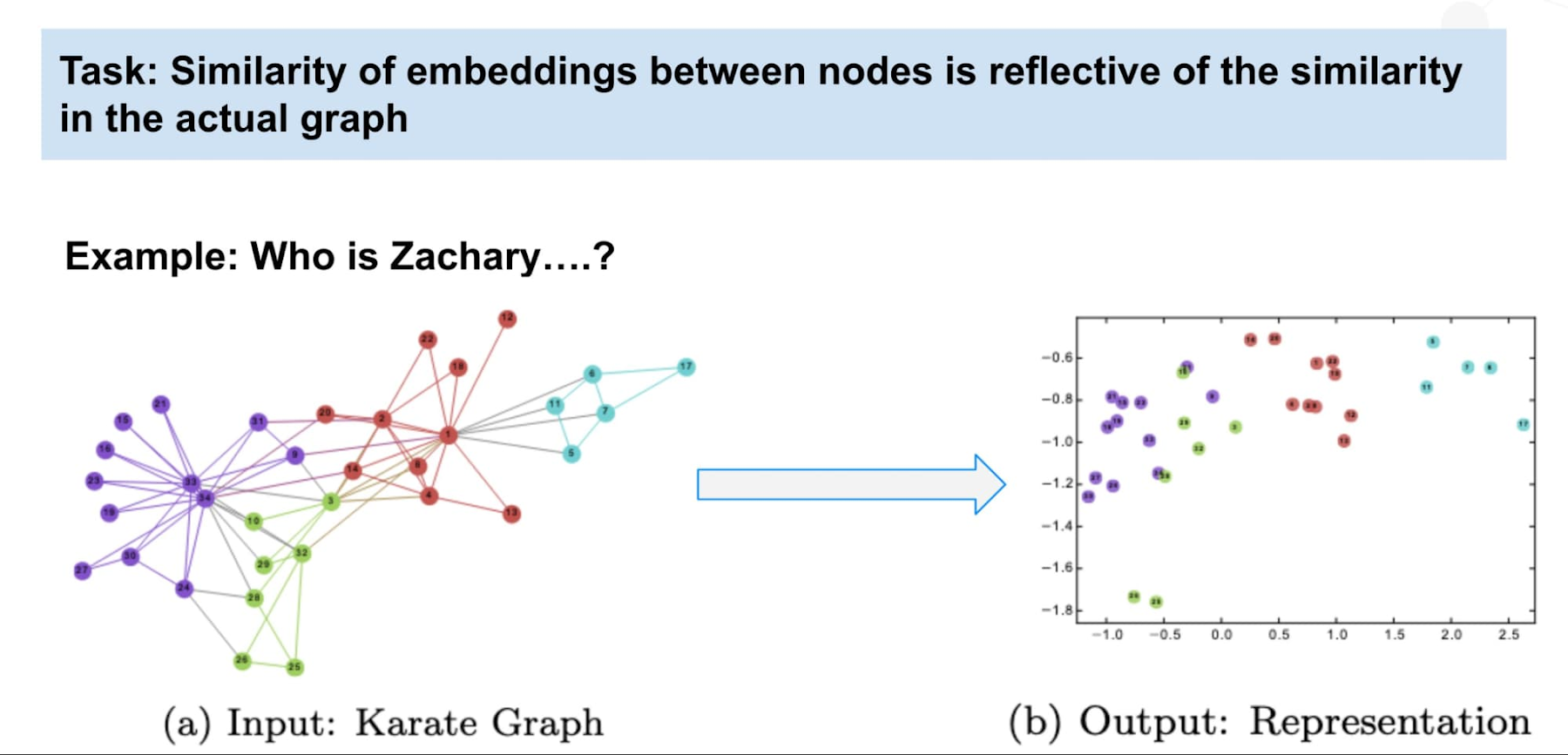
Some techniques make use of the embeddings on their own. For instance, using a t-sne plot to find clusters visually, or computing raw similarity scores. The magic really happens when you combine your embeddings with Google Cloud Vertex AI to train a supervised model.
For our PaySim example, we can create a graph embedding with the following call:
That creates a 16 dimensional graph embedding using the Fast Random Project algorithm. One neat feature in this is the nodeSelfInfluence parameter. This helps us tune how much nodes further out in the graph influence the embedding.
With the embedding calculated, we can now dump it into a pandas dataframe, write that to a CSV and push that to a cloud storage bucket where Google Cloud’s Vertex AI can work with it. As before, these steps are detailed in the notebook here.
Machine Learning with Vertex AI
Now that we’ve encoded the graph dynamics into vectors, we can use tabular methods in Google Cloud’s Vertex AI to train a machine learning model.
First off, we pull the data from a cloud storage bucket and use that to create a dataset in Vertex AI. The Python call looks like this:
With the dataset created, we can then train a model on it. That python call looks like this:
You can view the results of that call in the notebook. Alternatively, you can login to the GCP console and view the results in the Vertex AI’s GUI.
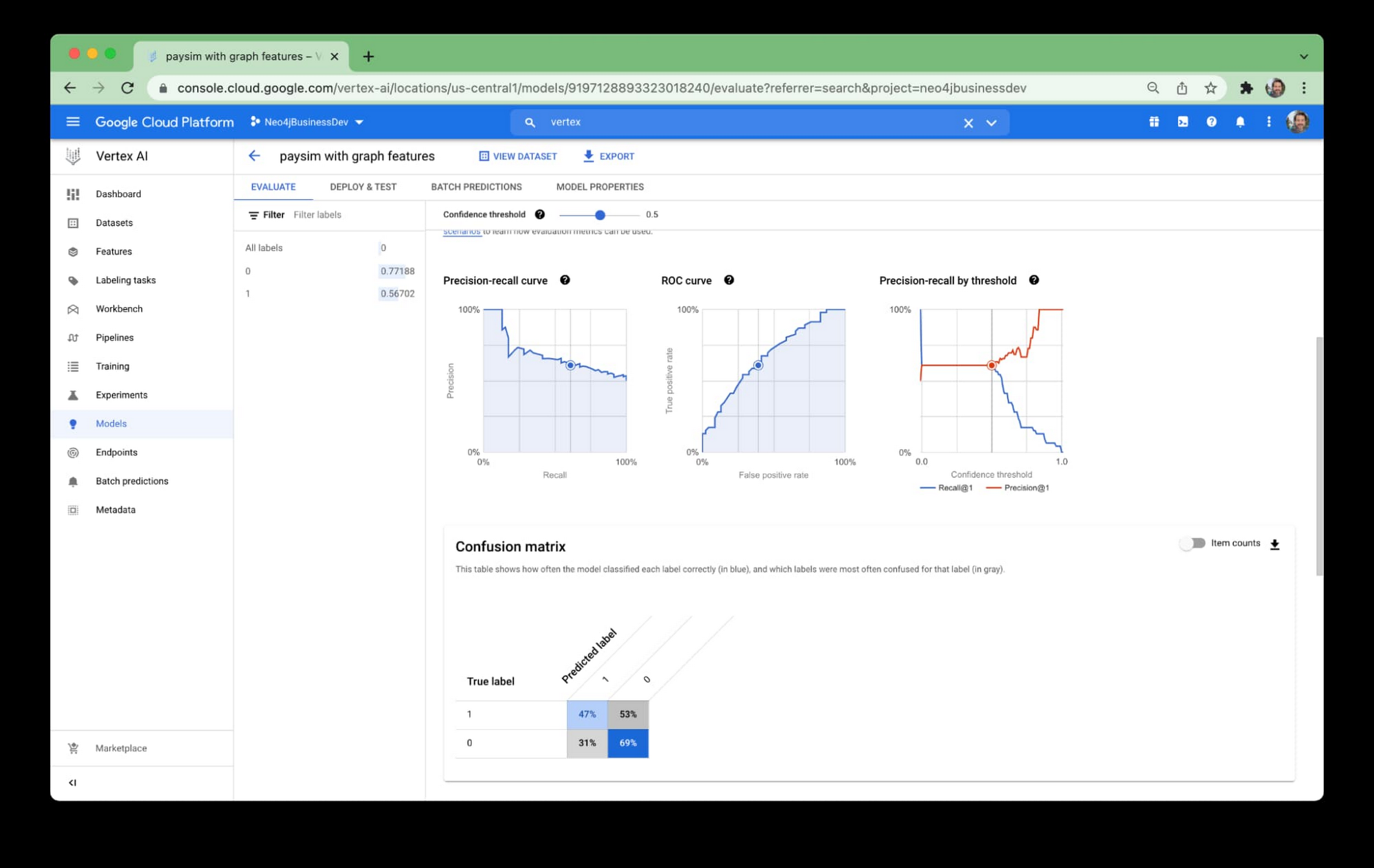
The console view is nice because it includes things like ROC curves and the confusion matrix. These can assist in understanding how the model is performing.
Vertex AI also offers helpful tooling for deploying the trained model. The dataset can be loaded into a Vertex AI Feature Store. Then an endpoint can be deployed. New predictions can be computed by calling that endpoint. This is detailed in the notebook here.
Future Work
Working on this notebook, we quickly realized that there is an enormous amount of potential work that could be done in this area. Machine learning with graphs is a relatively new field, particularly when compared to the study of methods for tabular data.
Specific areas we’d like to explore in future work include:
Improved Dataset - For data privacy reasons, it’s very difficult to publicly share fraud datasets. That led us to use the PaySim dataset in this example. That is a synthetic dataset. From our investigation, both of the dataset and the generator that creates it, there seems to be very little information in the data. A real dataset would likely have more structure to explore.
In future work we’d like to explore the graph of SEC EDGAR Form 4 transactions. Those forms show the trades that officers of public companies make. Many of those people are officers at multiple companies, so we anticipate the graph being quite interesting. We’re planning workshops for 2022 where attendees can explore this data together using Neo4j and Vertex AI. There is already a loader that pulls that data into Google BigQuery here.
Boosting and Embedding - Graph embeddings like Fast Random Projection duplicate the data because copies of sub graphs end up in each tabular datapoint. XGBoost, and other boosting methods, also duplicate data to improve results. Vertex AI is using XGBoost. The result is that the models in this example likely have excessive data duplication. It’s quite possible we’d see better results with other machine learning methods, such as neural networks.
Graph Features - In this example we automatically generated graph features using the embedding. It’s also possible to manually engineer new graph features. Combining these two approaches would probably give us richer features.
Next Steps
If you found this blog post interesting and want to learn more, please sign up for the AuraDS preview here. Learn more about Vertex AI here. The notebook we’ve worked through is here. We hope you fork it and modify it to meet your needs. Pull requests are always welcome!



