Document AI に、ドキュメント処理を効率的に自動化する新しいカスタム ドキュメント スプリッターを導入
Google Cloud Japan Team
※この投稿は米国時間 2023 年 7 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
企業はプロセスの推進や意思決定を行うために、大量のドキュメントの処理に依存しています。このようなドキュメントの多くは、1 つのファイルにまとめられています。ローンの申込書を例にとると、運転免許証、給与明細書、源泉徴収票、銀行明細書といったさまざまな種類のドキュメントが 1 つのファイルに含まれています。1 つのファイル内にある多くの種類のドキュメントを処理する作業は複雑なため、大規模に管理することが難しくなります。
Google Cloud は、ドキュメントの処理と分析のための ML プロダクトを提供する Document AI ソリューション スイートに継続的に投資して、これらの課題の解決に取り組んでいます。Document AI Workbench を使えば、特定のユースケースに合わせてトレーニングされた世界クラスの精度の ML モデルを迅速に構築することが可能です。2023 年 2 月、Google はカスタム ドキュメント エクストラクタ(CDE)の一般提供(GA)を開始し、ユーザーが本番環境のユースケースでドキュメントから構造化データを抽出できるようにしました。2023 年 3 月には、カスタム ドキュメント分類器(CDC)の一般提供を開始し、ドキュメント タイプを自動的に分類できるようになりました。そしてこのたび、Document AI Workbench の最新機能であるカスタム ドキュメント スプリッター(CDS)の一般提供を開始し、1 つのファイル内にある複数のドキュメントを自動的に分割、分類できるようになりました。
CDS はドキュメントの並べ替えや分類を支援することで、お客様に具体的なビジネス価値を提供します。たとえば、企業は申請者の必要ドキュメントがすべて揃っているかどうかを確認できます。さらに、ドキュメントが個別に分類されるので、ドキュメントの種類に応じて適切な保管、分析、処理ステップを選択するなど、ダウンストリーム プロセスを効率的に自動化できます。CDS によって可能になる効率化により、企業はドキュメント処理にかかる時間と費用を削減できます。
Document AI Workbench の分割および分類モデルのメリット
Document AI Workbench を使用すると、データセットの管理からテスト、デプロイまで、モデルのトレーニングが簡素化されるため、時間と費用を削減できます。CDC によって企業は、費用を削減しながら、より高い自動化率を達成してプロセスをスケールできるようになります。
Zencore のデリバリー サービス部門バイス プレジデントを務める Sean Earley 氏は、次のように述べています。「当社は住宅ローン情報開示法のレポート作成を自動化するために、Document AI Workbench を使用してドキュメントのデータを分割、分類、抽出する大手銀行のプロジェクトを完遂しました。高精度なモデルを構築したことにより、同行は、年間数千件ものエラーを排除すると同時に、ローンに関する報告のカバー率を 20% から 100% に向上させ、コンプライアンス報告手順の運用費用を大幅に削減できると見積もっています。」
Deloitte Consulting GmbH の AI およびデータ部門責任者を務める Fabian Beckmann 氏は、次のように述べています。「Document AI のカスタム ドキュメント スプリッターを活用することで、当社のクライアントである欧州大手のコメルツ銀行は、バックオフィスの要件に合わせて顧客の提出書類を簡単に分割して、余分な手作業による分類やルーティングの必要性を大幅に減らすことができるようになりました。このインテグレーションは、Document AI パイプラインのシームレスな自動化への道を開き、大きなビジネス利益をもたらします。」
IT サービス企業 Devoteam の G Cloud 部門で ML チーム テクニカル リーダーを務める Kaïs Albichari 氏は、次のように述べています。「カスタム ドキュメント スプリッター(CDS)は、当社の金融サービス業界のお客様が時間を大幅に削減し、データの精度を向上させるのに役立っています。エンティティ抽出のためにドキュメントの捨てる部分と残す部分を CDS によって識別することで、このお客様のドキュメント処理タスクの自動化が実現しています。この実装により、ワークフローがより効率的かつ合理的になり、従業員が他の業務に専念できるようになりました。Devoteam の G Cloud チームは、このお客様が CDS を実装して、このようなメリットを実現するのをサポートしました。」
Google Cloud 保険ソリューション コンサルタントの Frank Neugebauer は、Fortune 100 に選ばれた保険会社に協力し、CDS を使用して、最大 98% の精度で数百万の保険書類を分割、分類するモデルを作成しました。この情報により、この保険会社は非構造化データの性質をより深く理解してビジネス戦略に役立てることができるようになり、特定のドキュメント タイプのボリュームを抽出作業に反映させたりしています。同社は、200 年以上にわたる会社の歴史のなかで、このレベルの知見を得られた前例はないと考えています。
カスタム ドキュメント スプリッターの使用方法
Google Cloud コンソールのシンプルなインターフェースと公開 API を活用して、トレーニング データの準備、モデルの作成と評価、本番環境へのモデルのデプロイのほか、ドキュメント タイプを分割、分類する API エンドポイントの呼び出しを行うことができます。モデルを作成、トレーニング、評価、デプロイし、予測を行う手順については、ドキュメントをご覧ください。
トレーニング データのインポートと準備
まず、ML モデルのトレーニングと評価のために、ドキュメントをインポートし、ラベルを付けます。
トレーニング データセットをすばやく作成するには、単一ドキュメント(1 ファイルにつき 1 つのドキュメント)をインポートし、関連するドキュメント タイプで一括してラベルを付けます。1 つまたは複数のフォルダを一度にインポートして、フォルダごとに適切なドキュメント タイプを選択できます。次の画像に示すように、1 回のインポートで、200 の銀行明細書が入ったフォルダ、200 の源泉徴収票が入った別のフォルダ、200 の給与明細書が入った別のフォルダなどを、インポートしながら一度にラベル付けできます。最大 30,000 のドキュメントと 100,000 のページをトレーニング用に入力することが可能です。このようにして、1 クラスあたり数百のラベル付きドキュメントを持つトレーニング データセットを数分で構築できます。他のツールを使用してドキュメントにすでにラベルを付けてある場合は、通常どおり、JSON 形式の Document でラベルをインポートします。
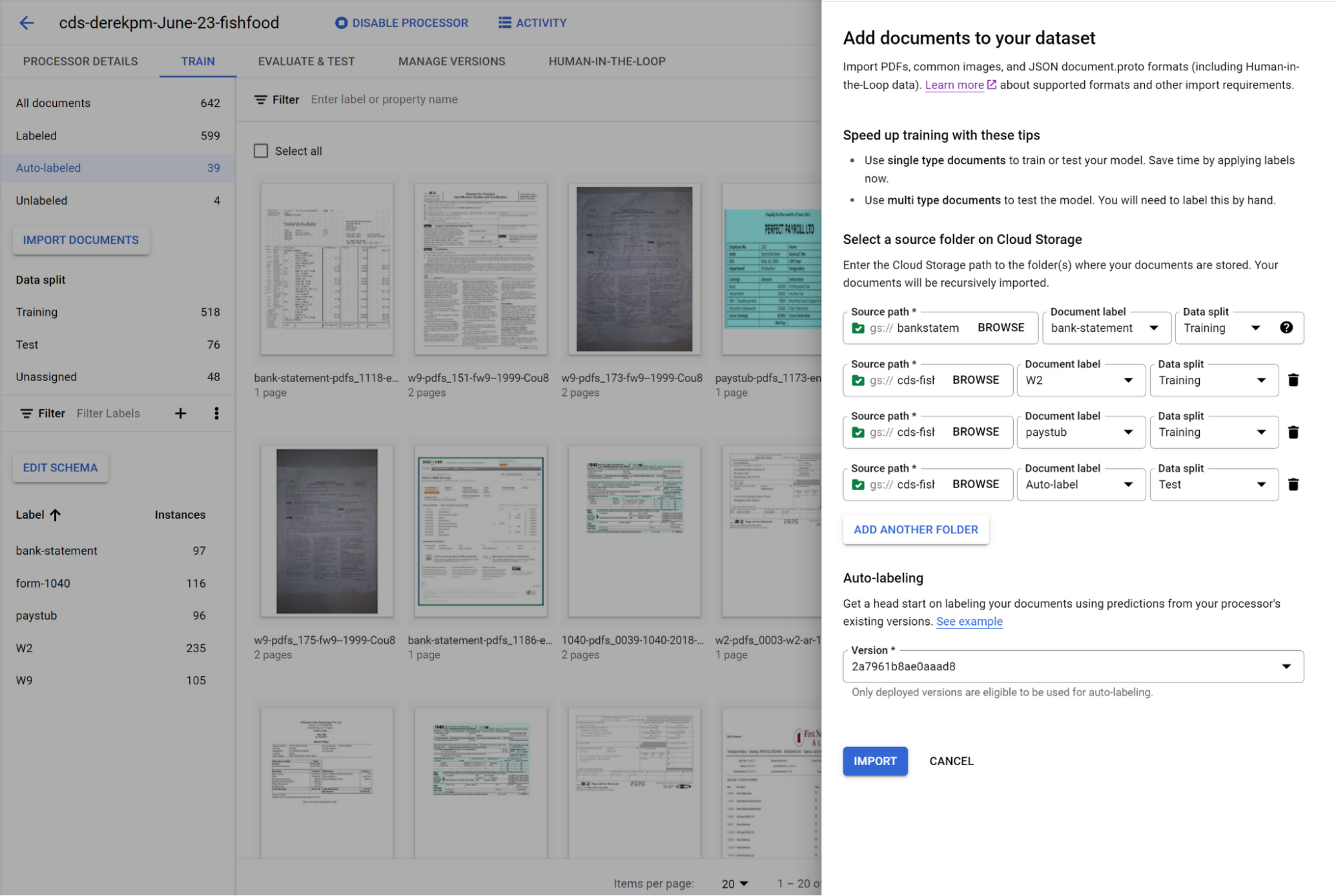
ユーザーは、ボタンをクリックするだけでトレーニングを開始できます。モデルをトレーニングすれば、データセットに追加されたドキュメントに自動的にラベルを付けることができます。これにより、堅牢なテスト データセットやトレーニング データセットをすばやく構築して、モデルのパフォーマンスを評価、改善できます。
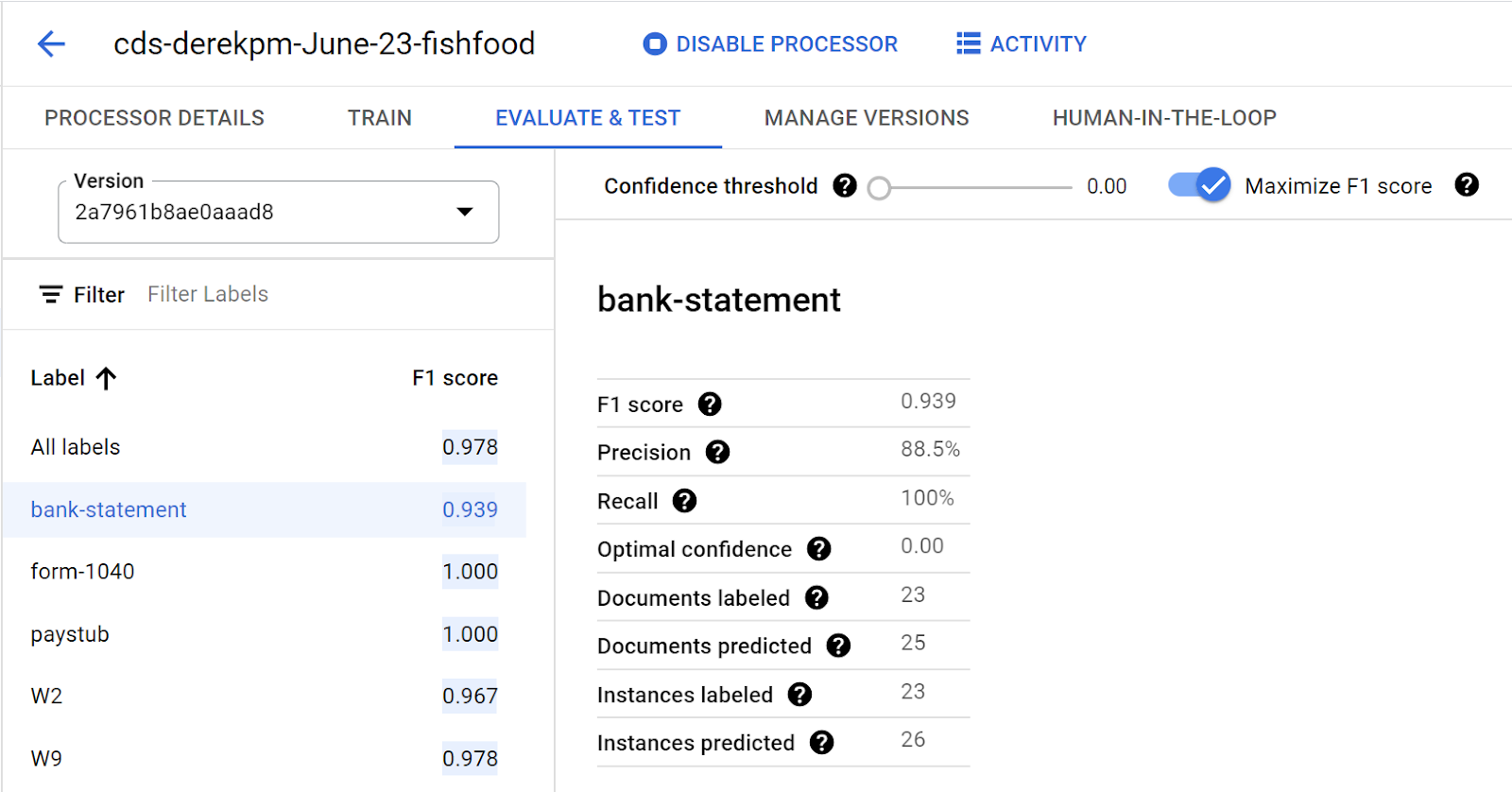
CDS モデルを正確に評価するには、同一ファイル内に複数のドキュメント タイプを含むファイルをインポートし、テスト データセットに割り当てます。その後、シンプルなインターフェースを使用して、ドキュメントの境界とタイプを定義します。

テスト データセットに付けた正解ラベルは、CDS モデルからの分割と分類の予測を評価するために使用されます。
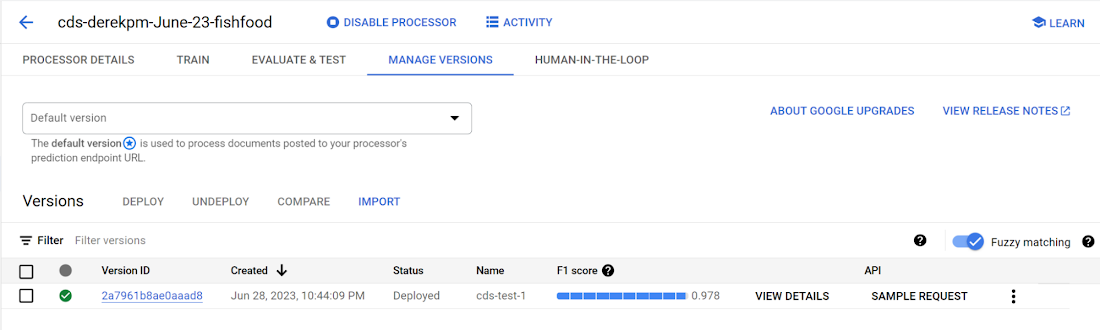
本番環境への移行
モデルが精度目標を満たしたら、本番環境にデプロイし、API エンドポイントを呼び出してドキュメント タイプを分割、分類します。
Document AI Workbench を使ってみる
カスタム ドキュメント スプリッターは一般提供が開始されており、ドキュメントの分割と分類を自動化するために今すぐお役立ていただけます。Document AI Workbench のウェブページや、Document AI Workbench のドキュメントで詳細をご覧いただくか、Google Cloud コンソールでお試しください。



